
- 1获取val值 赋给html,JQuery TextArea的val()、html()、text()取值与赋值问题
- 2[PCL]5 ICP算法进行点云匹配
- 3Unity小功能之—利用Pivot中心点-实现Image图片的从不同角度的放大缩小_unity 实现局部放大动画
- 4unity 中音乐播放器_unity musicplayer
- 5AlexNet 网络详解及Tensorflow实现源码
- 6Unity中的优化问题_unity中ui图片纹理的maxsize属性是干啥的
- 7Git的远程仓库_git远程仓库地址是什么
- 8离线AI聊天清华大模型(ChatGLM3)本地搭建
- 9IDEA插件开发
- 10【爱心弹幕----使用HTML+CSS+JS等实现(效果+源码)】| 系统架构师 面试题:在进行系统架构设计时,如何选择适合的技术栈和编程语言?_爱心弹屏代码
OpenVINO2023使用简介_pip安装openvino
赞
踩
1 下载安装OpenVINO开发工具
先在anaconda中创建一个虚拟环境,该环境的python版本为3.7,之所以使用python3.7,是因为我在3.9上安装过程中出现不少bug,后面新建了一个3.7的环境才解决,我不知道是否由于和我已有环境中某些包不兼容,还是python3.9版本的问题,总是折腾了很久都没解决,最后新建了一个虚拟环境。
地址

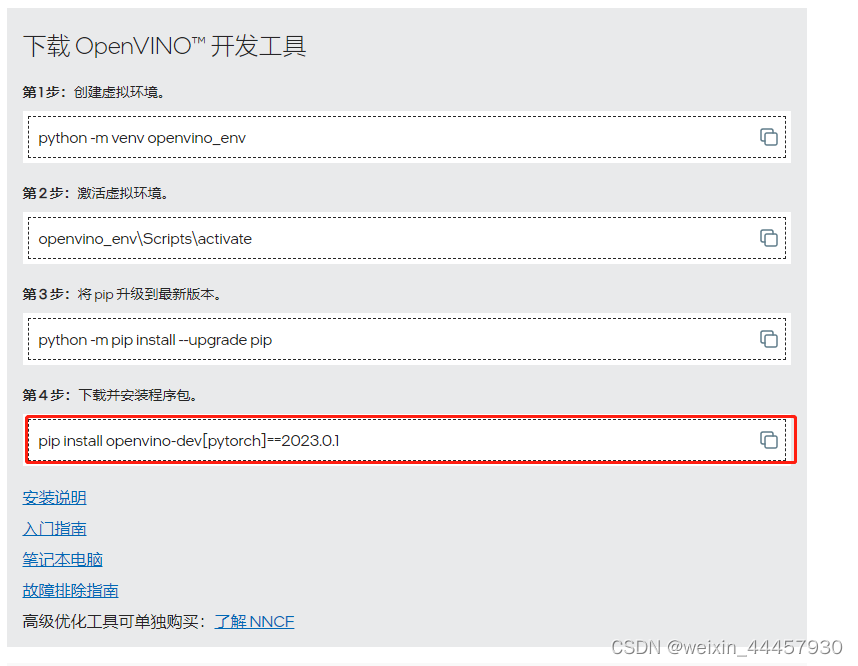
实际上就是下面这条命令:
pip install openvino-dev[pytorch]==2023.0.1
- 1
这里可以使用清华镜像或者阿里镜像
接下来使用下面这串代码,测试是否安装成功,如果没有报错,说明OpenVINO安装成功
python -c "from openvino.runtime import Core"
- 1
2 查看可用设备
下面是查看本地可用设备
from openvino.runtime import Core
core = Core()
devices = core.available_devices
for device in devices:
device_name = core.get_property(device, "FULL_DEVICE_NAME")
print(f"{device}: {device_name}")
- 1
- 2
- 3
- 4
- 5
- 6
输出:
CPU: Intel(R) Core(TM) i7-10870H CPU @ 2.20GHz
GPU.0: Intel(R) UHD Graphics (iGPU)
GPU.1: NVIDIA GeForce RTX 3060 Laptop GPU (dGPU)
- 1
- 2
- 3
这里有两个GPU,一个是集显,一个是独显。
3 模型的中间表示
在OpenVINO的使用过程中,经常可以听见一个词叫IR,它的全程叫Intermediate Representation,即模型的中间表示,主要包括.xml文件和.bin文件,前者用于描述网络拓扑(即网络结构),后者则是包含了网络中的权重和偏置的二进制数据文件,IR是OpenVINO中模型的专有格式。
由于模型的部署环境通常不会安装PyTorch、TensorFlow这些深度学习框架,因此在训练完成之后,一般是将模型导出为onnx文件,这样可以摆脱对框架和模型所属类的依赖。ONNX定义了一组与环境和平台无关的标准格式,为AI模型的互操作性提供了基础,使AI模型可以在不同框架和环境下交互使用。硬件和软件厂商可以基于ONNX标准优化模型性能,让所有兼容ONNX标准的框架受益,简单来说,ONNX就是模型转换的中间人。
在一些比较老的教程中,是拿到onnx文件后,将其转化为IR,然后OpenVINO再读取IR文件,并将其编译到硬件上面进行推理,这是之前OpenVINO推荐的部署流程,代码如下(只显示转化成IR的代码):
from openvino.tools import mo
from openvino.runtime import serialize # pycharm可能会提示找不到serialize,但实际能执行,IDE有bug
ov_model = mo.convert_model(onnx_path) # onnx_path是onnx文件的路径,ov_model是OpenVINO模型
serialize(ov_model, xml_path) # xml_path是IR中xml文件的路径
- 1
- 2
- 3
- 4
- 5
serialize方法不但会生成xml文件,还会在相同目录下生成bin文件,mo.convert_model可以完成模型的压缩、剪枝、前处理、设置输入等操作,这个能力很加分,但本文的目的是了解OpenVINO的大致使用流程,关于模型的压缩剪枝等操作暂时不展开,可以看官方手册详细了解mo.conver_model的功能链接
如果在训练环境中安装了OpenVINO2023,那么可以在训练结束后,跳过ONNX,直接将模型转化为OpenVINO的IR,代码如下:
from openvino.tools import mo
from openvino.runtime import serialize
ov_model = mo.convert_model(net) # net是PyTorch模型,ov_model是OpenVINO模型
serialize(ov_model, xml_path)
- 1
- 2
- 3
- 4
- 5
注意:将PyTorch模型直接转换成OpenVINO模型,这项功能仅仅是OpenVINO 2023.0 release才开始有的,在OpenVINO 2022之前都不支持,另外,因为这项功能比较新,因此并不是所有模型都能这么转,假如转换失败,还能老老实实先转ONNX,再转IR。
4 模型推理
得到IR之后(IR既可以在训练环境直接右PyTorch模型得到,也可以在部署环境中通过ONNX文件得到),将其读取到OpenVINO模型,然后编译到指定设备,就可以进行推理了,代码如下(省略了输入数据预处理的操作,比如图像缩放、数据压缩到0-1等):
from openvino.runtime import Core
# 创建推理核
core = Core()
# 读取IR文件
ov_model = core.read_model(model=ir_path) # ir_path是IR中xml文件的路径
# 编译到指定设备
compiled_model = core.compile_model(ov_model, 'CPU') # 'CPU'可以改成'GPU.0'、'GPU.1'或'AUTO'
# res是推理结果
res = compiled_model(input_data)[0] #
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
设备除了CPU之外,还可以是GPU.0或GPU.1,也可以让系统自动选择(AUTO),看自己的电脑上有什么设备,可以使用core.available_devices,详见第2节;推理时,input_data,既可以是torch的tensor,也可以是numpy的array;
上面的流程是标准流程,实际上,自从OpenVINO2020R04之后,core.read_model可以直接读onnx文件,这使得我们可以跳过IR那一步(但据说OpenVINO加载onnx文件会比加载IR文件更慢,不过对推理速度无影响,可以做个实验验证一下),代码如下:
from openvino.runtime import Core
core = Core()
# 读取onnx文件
ov_model = core.read_model(model=onnx_path) # onnx_path是onnx文件的路径
# 编译到指定设备
compiled_model = core.compile_model(ov_model, 'CPU')
# res是推理结果
res = compiled_model(input_data)[0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其实,也可以使用mo.convert_model将onnx模型转成OpenVINO模型后编译到指定设备,但这需要部署环境中有OpenVINO开发工具(即openvino.tools),而一般情况下,部署环境中没这个,只有runtime(即openvino.runtime),所以这种方式用的不多。
5 根据IR或ONNX文件获取模型的输入输出尺寸和数据类型
在很多大公司中,算法模型的研发与部署不是同一批人做,部署人员拿到 IR/ONNX 文件之后,需要知道模型的输入shape是什么,数据类型是什么,OpenVINO中可以根据模型文件获得相关信息。
我们先创建一个ONNX文件,程序如下:
import torch
from torchvision import models
# 定义模型并下载权重
model = models.resnet18(pretrained=True, num_classes=1000)
# 导出ONNX文件
model.eval()
dummy_input = torch.randn(1, 3, 228, 228)
torch.onnx.export(model, (dummy_input), 'resnet18.onnx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
此时,当前目录下会有一个名为resnet18.onnx的模型文件,假设这是别人给你的,你不知道它的输入输出信息,你想获得它的输入输出,可以使用如下程序:
from openvino.runtime import Core # 创建推理核 core = Core() # 读取ONNX文件并编译到指定设备 ov_model = core.read_model(model='resnet18.onnx') compiled_model = core.compile_model(ov_model, 'CPU') # 获取模型的输入输出信息 input_key = compiled_model.input(0) output_key = compiled_model.output(0) # 如果获得了output_key,推理时可以写成compiled_model(input_data)[output_key] # 打印输入输出信息 print('input_key:', input_key) print('output_key:', output_key) print('input_key.shape:', input_key.shape) print('output_key.shape:', output_key.shape)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
打印如下:
input_key: <ConstOutput: names[input.1] shape[1,3,228,228] type: f32>
output_key: <ConstOutput: names[191] shape[1,1000] type: f32>
input_key.shape: [1,3,228,228]
output_key.shape: [1,1000]
- 1
- 2
- 3
- 4
好的,我们可以看到该ONNX文件对应的模型,其输入的shape为(1,3,228,228),数据类型为f32(即单精度浮点型),输出的shape为(1, 1000),数据类型为f32。
6 总结
本文介绍了如何使用OpenVINO部署PyTorch模型,主要内容可以用下面几幅图表示
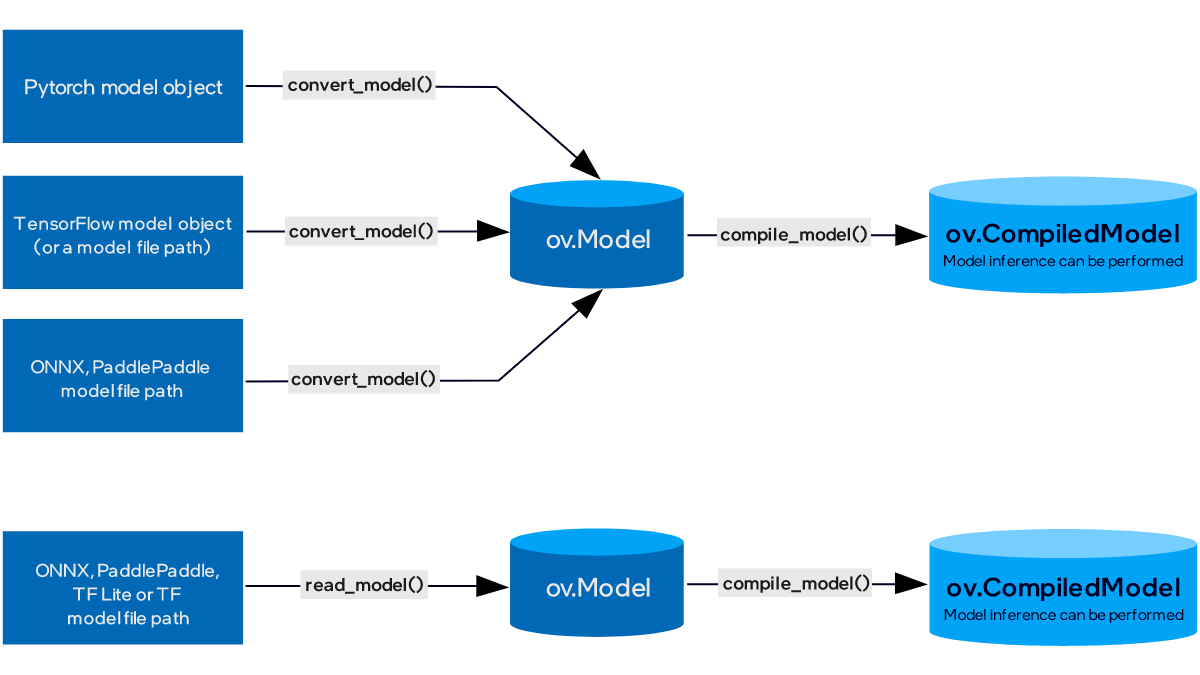
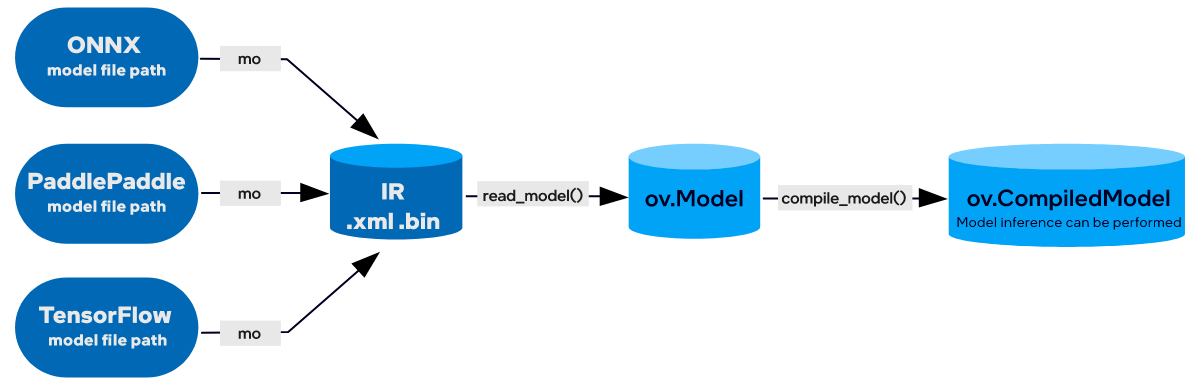
好了,至此,当我们得到一个PyTorch模型后,已经可以将其部署到OpenVINO上去了,当然,由于篇幅所限,还有很多细节没有展开,我们今天先把Pipeline打通,日后会具体介绍。
https://docs.openvino.ai/2023.0/notebooks/102-pytorch-to-openvino-with-output.html
https://docs.openvino.ai/2023.0/notebooks/102-pytorch-onnx-to-openvino-with-output.html
https://docs.openvino.ai/2023.0/openvino_docs_model_processing_introduction.html
https://mp.weixin.qq.com/s?__biz=MzU2NjU3OTc5NA==&mid=2247560125&idx=2&sn=001988bca941a9404ac8fe7a351b514d&chksm=fca9ec80cbde659689922250b3138e752cfccf50fde18f07016b7673bf1289bb8bd25bb4f636&scene=27

