
- 1uni.chooseImage失效_uni.chooseimage不生效
- 2Python [sortedcontainers]有序容器库使用不完全指南
- 3ORACLE ASM空间增加(分区盘做法)_asm分区
- 4论前端开发的红颜知己-------饿了么UI_饿了么ui,分页组件中哪几个参数必传
- 5[Win10] 代理服务器出现问题或地址有误_代理服务器有问题或者地址有误
- 6幻兽帕鲁联机失败、无法加入服务器解决方法:3步操作30秒完成搭建幻兽帕鲁服务器_幻兽帕鲁127.0.0.1:7777
- 7C/S 和 P2P_c/s和p2p
- 8PyCharm 配置 PySide6 到工具栏_pyside 工具条
- 9Linux中ls -l命令详解_linux ls -l
- 10文心一格聚焦AIGC创作与商业化,打造内容生产创新引擎
fork()函数详解_fork函数
赞
踩
目录
1.多线程中某个线程调用 fork(),子进程会有和父进程相同数量的线程吗?
2.父进程被加锁的互斥锁 fork 后在子进程中是否已经加锁?
1.基本了解:
一个进程,包括代码、数据和分配给进程的资源。fork 函数会新生成一个进程,调用 fork 函数的进程为父进程,新生成的进程为子进程。在父进程中返回子进程的 pid,在子进程中返回 0,失败返回-1。
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
2.fork函数的了解:
pid_t fork(void);
函数返回类型 pid_t 实质是 int 类型,Linux 内核 2.4.0 版本的定义是:
typedef int _kenrnel_pid_t;
typedef _kenrnel_pid_t pid_t;
fork 函数会新生成一个进程,调用 fork 函数的进程为父进程,新生成的进程为子进程。
在父进程中返回子进程的 pid,在子进程中返回 0,失败返回-1(此时才能更好理解他的返回值)。
举个例子:
- 1 #include <stdio.h>
- 2 #include <stdlib.h>
- 3 #include <unistd.h>
- 4 #include <string.h>
- 5 #include <assert.h>
- 6
- 7 int main()
- 8 {
- char * s = NULL;
- 9 int n = 0;
- 10
- 11 pid_t pid = fork();
- 12 assert( pid != -1 );
- 13 if ( pid == 0 )
- 14 {
- 15 s = "child";
- 16 n = 4;
- 17 }
- 18 else
- 19 {
- 20 s = "parent";
- 21 n = 10;
- 22 }
- 23
- 24 int i = 0;
- 25
- 26 for(; i < n; i++ )
- 27 {
- 28 printf("pid=%d,s=%s\n",getpid(),s);
- 29 sleep(1);
- 30 }
- 31
- 32 exit(0);
- 33 }
来看看运行结果:
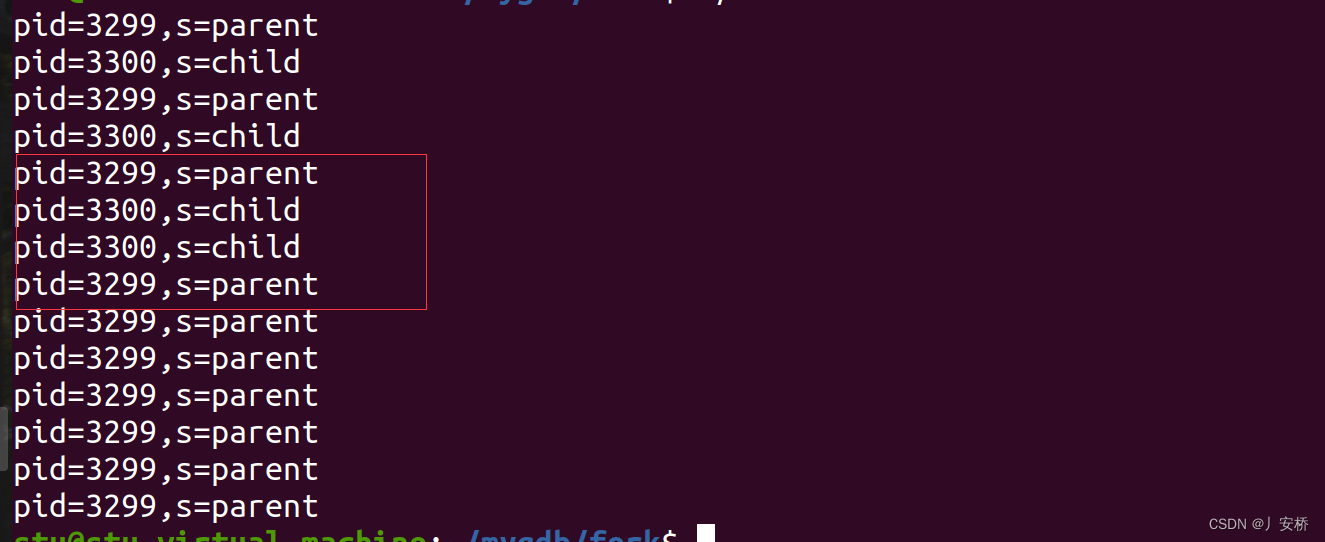
共打印了4次child,10次parent。fork()产生的子进程打印了4次child.
此时还应注意fork()产生的子进程和父进程之间的并发问题。
3.僵死进程:
(1) 僵死进程概念:子进程先于父进程结束,父进程没有调用 wait 获取子进程退出码。
(2)僵死进程的危害:
- 僵死进程的PID还占据着,意味着海量的子进程会占据满进程表项,会使后来的进程无法fork.
- 僵尸进程的内核栈无法被释放掉,为啥会留着它的内核栈,因为在栈的最低端,有着thread_info结构,它包含着 struct_task 结构,这里面包含着一些退出信息
(3)如何处理僵死进程:父进程通过调用 wait()完成。
wait函数:
pid_t wait(int *status);
进程一旦调用了wait,就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
下面看例子:
- 1 #include <stdio.h>
- 2 #include <stdlib.h>
- 3 #include <unistd.h>
- 4 #include <string.h>
- 5 #include <assert.h>
- 6 #include <sys/wait.h>
- 7 int main( int argc, char* argv[], char* envp[])
- 8 { char * s = NULL;
- 9 int n = 0;
- 10
- 11 pid_t pid = fork();
- 12 assert( pid != -1 );
- 13 if ( pid == 0 )
- 14 {
- 15 s = "child";
- 16 n = 4;
- 17 }
- 18 else
- 19 {
- 20 s = "parent";
- 21 n = 10;
- 22
- 23 int val = 0;
- 24 int id = wait(&val);
- 25
- 26 if ( WIFEXITED(val) )
- 27 {
- 28 printf("id=%d,val=%d\n",id,WEXITSTATUS(val));
- 29 }
- 30 }
- 31 int i = 0;
- 32
- 33 for(; i < n; i++ )
- 34 {
- 35 printf("pid=%d,s=%s\n",getpid(),s);
- 36 sleep(1);
- 37 }
- 38
- 39 exit(0);
- 40 }
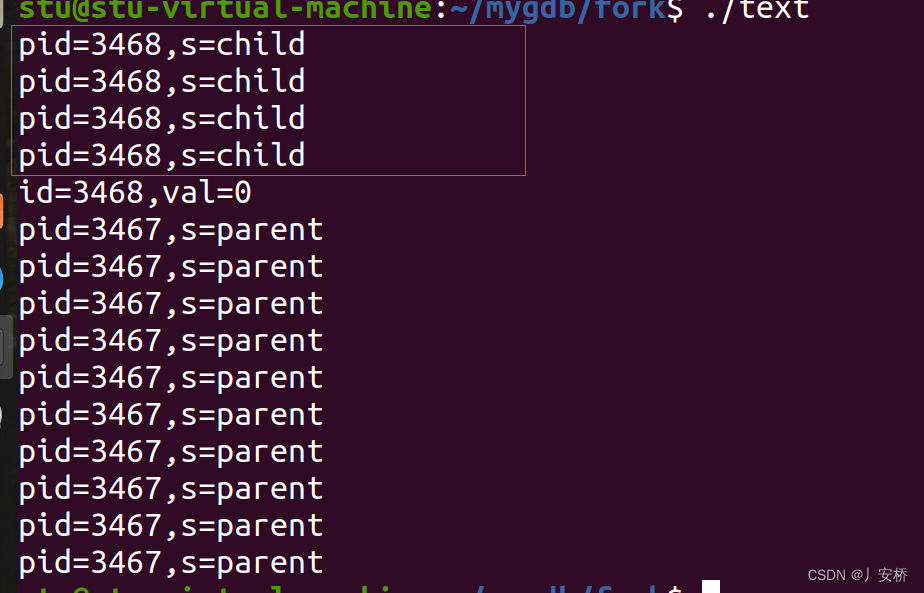
运行结果如图:
引入wait函数可以使先处理完子进程,再去处理父进程。可以有效避免僵死进程。
4. fork和多线程:
1.多线程中某个线程调用 fork(),子进程会有和父进程相同数量的线程吗?
在Linux中,fork的时候只复制当前线程到子进程,也就是说除了调用fork的线程外,其他线程在子进程中“蒸发”了。
2.父进程被加锁的互斥锁 fork 后在子进程中是否已经加锁?
调用fork的时候,会复制父进程的所有锁到子进程中。
假设在fork之前,一个线程对某个锁进行的lock操作,即持有了该锁,然后另外一个线程调用了fork创建子进程。可是在子进程中持有那个锁的线程却"消失"了,从子进程的角度来看,这个锁被“永久”的上锁了,因为它的持有者“蒸发”了。
5.写时拷贝:
传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据也许并不共享,更糟的情况是,如果新进程打算立即执行一个新的映像,那么所有的拷贝都将前功尽弃。Linux的fork()使用写时拷贝(copy-on-write)页实现。
写时拷贝是-一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享同一个拷贝。只有在需要写入的时候,数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下——举例来说,fork()后立即调用exec()—-它们就无需复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建惟一的进程描述符。在一般情况下,进程创建后都会马上运行一个可执行的文件,这种优化可以避免拷贝大量根本就不会被使用的数据(地址空间里常常包含数十兆的数据)。由于Unix强调进程快速执行的能力,所以这个优化是很重要的。

