
- 1安卓手机部署ubuntu的lxc容器,并安装好dockerd_lxc android
- 2华为Android更改文件位置,华为C8812改变Android手机软件安装位置方法
- 3Error:Unknown host 'services.gradle.org'. You may need to adjust the proxy settings in Gradle. Error
- 4vue路由跳转及其ajax请求,vue路由切换时取消之前的所有请求操作
- 5vue实现文章目录_vue word帮助文档查看 带目录
- 6Sora何时开放使用?付费课程已上线(sora什么时候开放使用 )_sora什么时候能用
- 7ssm-房屋租赁系统_在房屋租赁管理系统中有如下三个关系模式一房屋租户三租赁订单是完成如下查询
- 8「软件」2.0时代已经到来,你需要这样的开发工具_paddle serving paddle inference
- 9华为matePad11平板mate PAD PRO 11无法激活设备怎么解锁忘记的密码重置免拆机解除方法教程步骤_华为平板mate11强制解锁跳过激活锁怎么办
- 10bit-band_bit.band
35、Django进阶:项目多种数据库配置方式和使用(MySQL、PGSQL、ES、MongoDB、InfluxDB)详解_influxdb mariadb
赞
踩
目录
新建的Django初始内置项目的数据库为什么使用SQLite
1. 安装InfluxDB和Python InfluxDB库
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

公众号:CTO Plus
一个有深度和广度的技术圈,技术总结、分享与交流,我们一起学习。 涉及网络安全、C/C++、Python、Go、大前端、云原生、SRE、SDL、DevSecOps、数据库、中间件、FPGA、架构设计等大厂技术。 每天早上8点10分准时发文。
306篇原创内容
原文:35、Django进阶:项目多种数据库配置方式和使用(MySQL、PGSQL、ES、MongoDB、InfluxDB)详解
本文共1万多字,建议关注 和 收藏起来日后慢慢看
![]()
。
在当今互联网时代,数据是应用程序的核心。Django作为一个强大的Web框架,提供了丰富、灵活多样的数据库配置方式,使开发者能够轻松应对不同的数据存储需求。
我们创建的Django项目它默认使用SQLite作为数据库,但在某些情况下,我们可能需要使用其他数据库,如MySQL、PGSQL、ES、InfluxDB和MongoDB等。
本篇文章我将依次介绍如下内容:
1、首先介绍新建的Django项目中为什么一开始使用的是SQLite,以及我为什么不建议生产环境使用自带的SQLite数据库,然后介绍了SQLite的应用场景和优缺点。
2、接着介绍为什么推荐生产环境项目使用MySQL。
然后,依次是详细解析Django中对多种数据库(MySQL、PGSQL、ES、InfluxDB和MongoDB)的支持和配置方式的详解,比如在Django项目中使用MySQL/PGSQL数据库的配置方式和具体应用,在ES、MongoDB和influxdb数据库配置及应用实践中,解析在Django项目中配置并使用Elasticsearch(ES)、MongoDB和fluxdb数据库的步骤和方法。
3、Django配置和使用MySQL。
4、Django配置和使用PostgreSQL。
5、Django配置和使用Elasticsearch。
6、Django配置和使用MongoDB。
7、Django配置和使用InfluxDB。
8、针对ES、MongoDB、InfluxDB这三个非关系型数据的一个简单对比。
并带了一些配套的实战案例的代码演示,读者将掌握不同数据库的配置和应用技巧,以及在实际项目中如何运用这些数据库实现高性能、可扩展和易维护的数据存储和查询。并在文章最后概要分析了下ES、MongoDB和fluxdb数据库的特点、优势和适用场景。让我们一起参加这场Django数据库大乱斗,开辟属于自己的数据之路!
针对数据库方面的介绍,我在公众号CTO Plus前面的文章中,对数据库的作用、分类和特性做了详细介绍,可以阅读这篇文章《数据库介绍》,以及在第二篇文章中针对MySQL、Mariadb、PostgreSQL、MangoDB、Memcached和Redis做了详细介绍以及对比,具体可以参考文章《数据库篇:常见数据库MySQL、Mariadb、PostgreSQL、MangoDB、Memcached和Redis详细介绍》
本篇文章整个介绍下来,你可以看到一个明细的特点,那就是Django在不管你使用的是默认的SQLite、MySQL、PGSQL等数据库,甚至像使用MongoDB这样的文档型数据库,Django基于MVT的开发模式以及ORM的操作基本不变,我们只需要安装下对应的依赖库和稍微一点不一样的配置,就可以轻易的迁移更换我们项目使用的数据库。
扩展阅读:其他完整的Django项目详细配置settings.py项参考:《25、Django开发总结:settings.py设置选项详解》这篇文章对大部分常用的配置全部做了详细注释介绍,包括Redis等。
另外,关于MySQL数据库的特性、性能优化和常见问题解决方案。将在公众号CTO Plus后面的文章做详细介绍,本篇篇幅长了点。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

新建的Django初始内置项目的数据库为什么使用SQLite
当我们使用Django创建一个新的项目时,Django默认情况下使用免费的SQLite数据库,无需进行任何设置开箱即可使用。那么Django为什么会使用SQLite作为项目的数据库。这是因为SQLite是一个轻量级的嵌入式数据库,非常适合Django的学习、开发和测试阶段使用。但是在生产环境中部署正式项目时,应该使用性能更优越的企业级数据库,比如MySQL和PostgreSQL。当然了,如果我们的项目对数据库的需求不需要,Django项目我们也可以移除掉数据库的配置。
db.sqlite3是一个数据库文件,Django默认使用的就是sqlite3,sqlite3是一个进程内的库,实现了自给自足、无服务器、零配置、事务性的SQL数据库引擎。
以下是为什么Django使用SQLite的一些原因:
1. 简单易用:SQLite是一个文件级数据库,数据库文件可以轻松地存储在项目的根目录下。这使得SQLite非常容易设置和使用,不需要任何额外的配置或服务器。同时我们在学习Django时,也不需要另外再去单独的安装一个数据库服务。
2. 零配置:使用SQLite作为默认数据库,Django可以自动处理数据库的创建和迁移。这意味着在开发阶段(适合我们零基础开始学些Django的读者),我们可以专注于应用程序的开发,而不必担心数据库的配置和管理。
3. 跨平台支持:SQLite是一个跨平台的数据库,可以在各种操作系统上使用,包括Windows、Mac和Linux。这使得开发人员可以轻松地在不同的环境中共享和部署项目。
SQLite的应用场景及优缺点
SQLite是一个轻量级的开源免费的数据库。它是一种嵌入式数据库,只是一个.db格式的文件,无需安装,无需配置和启动服务。SQLite试图为单独的应用程序和设备提供本地的数据存储。
接下来,让我们来了解一下SQLite的应用场景、优缺点。
SQLite的应用场景及优点
SQLite常见应用场景包括:
小型项目:SQLite适用于小型项目,特别是那些只需要存储少量数据的应用程序。例如,个人博客、简单的网站或小型移动应用程序(如android、微信)、文件档案管理和桌面程序(exe)文件数据库等。
嵌入式系统:由于SQLite是一个嵌入式数据库,它可以轻松地集成到各种嵌入式系统中,如移动设备、物联网设备等。
测试和开发:SQLite非常适合用于测试和开发阶段,因为它易于设置和使用,不需要额外的配置和服务器。
那么他的优点包括如下:
-
简单易用:SQLite非常容易设置和使用,不需要额外的配置和服务器。
-
零配置:SQLite可以自动处理数据库的创建和迁移,使得开发人员可以专注于应用程序的开发。
-
跨平台支持:SQLite可以在各种操作系统上使用,包括Windows、iOS、Mac和Linux,移植性非常好。
-
SQLite支持多种编程语言(如Python、C等)。
SQLite不适用的场景及缺点
然而,尽管SQLite在开发和测试阶段非常方便,但它不适合在生产环境中使用。SQLite的性能和扩展性相对较差,对于高并发和大规模数据处理来说不是一个理想的选择。在生产环境中,我们通常会使用更强大和可扩展的数据库,如MySQL或PostgreSQL。
以下是sqlite不适用的场景和缺点:
客户端/服务器程序
如果有许多的客户端程序要通过网络访问一个共享的数据库, 应当考虑用一个客户端/服务器数据库来替代SQLite。SQLite可以通过网络文件系统工作, 但是因为和大多数网络文件系统都存在延时, 因此执行效率很差。
高流量网站
SQLite通常情况下用作一个中小型网站(日访问次数少于10万、系统参数配置管理系统等)的后台数据库是完全可以胜任的。但是如果的网站的访问量大到开始考虑采取分布式的数据库部署, 那么应当毫不犹豫的考虑用一个企业级的客户端/服务器数据库来替代SQLite。
超大的数据集
SQLite相对于其他数据库,如MySQL或PostgreSQL,在处理大量数据和高并发请求时性能和扩展性较差。当在SQLite中开始一个事务处理的时候, 数据库引擎将不得不分配一小块内存(文件缓冲页面)来帮助它自己管理回滚操作。每1MB的数据库文件SQLite需要256字节。对于小型的数据库这些空间不算什么, 但是当数据库增长到数十亿字节的时候, 缓冲页面的尺寸就会相当的大了. 如果需要存储或修改几十GB的数据, 应该考虑用其他的数据库引擎。
高并发访问
SQLite在处理并发请求时可能会出现性能问题,因为它使用文件级锁定来处理并发访问。SQLite对于整个数据库文件进行读取/写入锁定, 这意味着如果任何进程读取了数据库中的某一部分, 其他所有进程都不能再对该数据库的任何部分进行写入操作。同样的, 如果任何一个进程在对数据库进行写入操作, 其他所有进程都不能再读取该数据库的任何部分。对于大多数情况这不算是什么问题, 在这些情况下每个程序使用数据库的时间都很短暂, 并且不会独占, 这样锁定至多会存在十几毫秒。但是如果有些程序需要高并发, 那么这些程序就需要寻找其他的解决方案了。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

为什么使用MySQL
尽管Django默认使用SQLite作为数据库,但在生产环境中,我们通常会使用更强大和可扩展的数据库,如MySQL或PostgreSQL。MySQL是最流行的开源免费的关系型数据库,可作为客户端/服务器数据库提供企业级的数据库服务。
以下是我认为为什么生产环境的Django项目要使用MySQL的一些原因:
1. 性能和扩展性:MySQL是一个强大的关系型数据库管理系统,具有优秀的性能和扩展性。它可以处理大量的数据和高并发请求,适合于大型和复杂的应用程序。
2. 数据完整性:MySQL支持事务和外键约束,可以确保数据的完整性和一致性。这对于需要保持数据一致性的应用程序非常重要。
3. 社区支持和生态系统:MySQL有一个庞大的开发者社区和丰富的生态系统,提供了许多工具和插件来支持开发和管理MySQL数据库。
4. 可扩展性:MySQL支持主从复制和分布式架构,可以轻松地扩展到多个服务器,以处理更大的负载。
5. 兼容性:MySQL是一个通用的数据库,被广泛支持和使用。它可以与各种编程语言和框架集成,包括Django。
如果需要开发一个高流量或高并发的网站,SQLite将不能满足需求。同时,如果要开发一个Web APP, 不同用户通过网络对数据库进行读写操作,那么SQLite也将不能胜任(比如分布式数据库)。这时需要考虑企业级的专业数据库了,比如MySQL(MariaDB、PostgreSQL等)。
在Django中,可以使用多种数据库配置方式来连接不同类型的数据库。常见的数据库类型包括MySQL、PostgreSQL、Elasticsearch、MongoDB和InfluxDB等。下面将详细介绍如何配置和使用这些数据库。
另外关于MySQL、PostgreSQL、Elasticsearch、MongoDB和InfluxDB的详细使用介绍,请关注公众号CTO plus,查看数据库系列的内容《MySQL进阶》、《PostgreSQL进阶》、《Elasticsearch进阶》、《MongoDB进阶》、《InfluxDB进阶》。
Django配置和使用MySQL
Django项目中配置使用MySQL一共分四步: 安装MySQL, 创建数据库名和设置用户名密码,通过pip安装第三方库pymysql和修改配置文件settings.py。
安装MySQL
关于Windows和Linux上的PGSQL服务的安装、配置与使用,请关注公众号CTO Plus,参考【MySQL系列】中的文章《MySQL在Linux/Windows上的安装使用与配置详细介绍》
创建数据库名和用户
创建数据库和用户后并给创建的用户授权
CREATE DATABASE database_name charset=utf8
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password'
GRANT ALL PRIVILEGES ON database_name.* TO 'username'@'localhost' IDENTIFIED BY 'password'
database_name.*表示授权操作database_name中所有的表。
安装第三方库pymysql
使用第三方库比如pymysql,Django才能直接访问MySQL数据库,执行下面的命令进行安装:
pip install pymysql mysqlclient
然后在项目文件夹的__init__.py中文件中写入如下两行代码:
import pymysql
pymysql.install_as_MySQLdb()
修改数据库配置文件
在Django的配置文件中,可以通过DATABASES设置来配置MySQL数据库的连接。修改项目文件夹里的settings.py文件,添加创建的数据库和用户信息。
# 配置方式1:直接在settings文件中配置
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 数据库引擎 'NAME': 'database_name', # 要存储数据的库名,事先要创建。 'USER': 'root', # 数据库用户名 'PASSWORD': '123456', # 密码 'HOST': 'localhost', # 默认主机 'PORT': '3306', # 数据库使用的端口 'TEST': { 'CHARSET': 'utf8', 'COLLATION': 'utf8_general_ci' }, }}# 配置方式2:通过配置文件的方式配置
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # 数据库引擎 'OPTIONS': { 'read_default_file': 'my.cnf', } },}创建一个简单模型,使用如下命令,如果能正常生成表没出现错即可
python manage.py makemigrations
python manage.py migrate
Django配置和使用PostgreSQL
PostgreSQL在全球是仅次于MySQL的开源免费的关系型数据库,功能更加强大,是Django首选的关系型数据库。PostgreSQL是一个强大的开源关系型数据库管理系统,具有高度的可扩展性和丰富的功能。这节我将总结下如何在Django中配置和使用PostgreSQL,以实现可靠和高性能的数据存储和查询。
PGSQL的特点
首先我总结下PGSQL的特点:
1. 关系型数据库:PostgreSQL是一种关系型数据库管理系统(RDBMS),支持SQL查询语言和ACID事务。
2. 高度可定制:PostgreSQL提供了丰富的扩展和插件系统,可以根据需要添加自定义数据类型、函数和操作符。
3. 强大的功能集:PostgreSQL支持复杂的查询、视图、触发器、存储过程和复制等功能。
4. 高度可靠: PostgreSQL具有高度可靠性和数据完整性,支持多版本并发控制(MVCC)和故障恢复机制。
5. 开源和活跃的社区支持:PostgreSQL是一个开源项目,有一个活跃的社区提供支持和持续的开发。
6. 水平扩展: PostgreSQL支持通过分片和复制来水平扩展,可以将数据分布在多个节点上,提高吞吐量和可用性。
7. 垂直扩展: PostgreSQL可以通过增加硬件资源(如CPU、内存和存储)来垂直扩展,提高性能和容量。
8. 连接池和负载均衡:可以使用连接池和负载均衡器来管理和分发数据库连接,提高并发处理能力。
9. 性能调优:通过索引优化、查询优化和硬件升级等方式提高数据库性能。
10. 高可用性和故障恢复:使用复制和故障切换来提供高可用性和故障恢复能力。
11. 并发控制和事务管理:使用事务和并发控制机制来处理并发访问和保证数据一致性。
接下来在Django项目中配置和使用PostgreSQL数据库
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

安装与配置PostgreSQL
首先,需要安装PostgreSQL并启动它。可以从PostgreSQL官方网站下载并安装PostgreSQL。
关于Windows和Linux上的PGSQL服务的安装、配置与使用,请关注公众号CTO Plus,参考【PGSQL系列】中的文章《PGSQL在Linux/Windows上的安装、配置与使用详细介绍》
然后,我们创建数据库和用户,并给创建的用户授权。数据库名字,用户名和密码
# 创建名为myapp的数据库
CREATE DATABASE mydb;
# 创建用户名和密码
CREATE USER myuser WITH ENCRYPTED PASSWORD 'mypass';
# 给创建的用户授权
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
# 以下设置可手动进行设置,也可以在postgresql.conf中进行配置
# 设置客户端字符为utf-8,防止乱码
ALTER ROLE myuser SET client_encoding TO 'utf8';
# 事务相关设置 - 推荐
ALTER ROLE myuser SET default_transaction_isolation TO 'read committed';
# 设置数据库时区为UTC - 推荐
ALTER ROLE myuser SET timezone TO 'UTC';
安装第三方库psycopg2
Psycopg2是一个用于连接PostgreSQL数据库的Python驱动程序。在Django开发中,使用Psycopg2可以方便地与PostgreSQL数据库进行交互。可以使用以下命令来安装Psycopg2:
pip install psycopg2==2.9.5
配置文件settings.py
跟MySQL一样,找到settings.py中的DATABASES修改成如下即可:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', # 数据库引擎 'NAME': 'steverocket', # 数据库名,Django不会帮创建,需要自己进入数据库创建。 'USER': 'postgres', # 设置的数据库用户名 'PASSWORD': '123456', # 设置的密码 'HOST': 'localhost', # 本地主机或数据库服务器的ip 'PORT': '5432', # 数据库使用的端口 }}然后指定迁移命令,下面的命令执行成功即可
python manage.py makemigrations
python manage.py migrate
打开PGAdmin即可查看到pgsql迁移生成的表
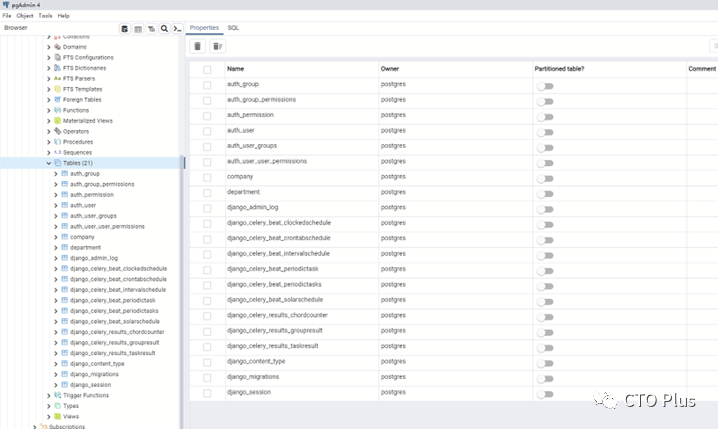
创建数据库表
接下来我们在Django的模型文件(models.py)中,定义一个模型类,并创建数据库表:
from django.db import models
class Article(models.Model): title = models.CharField(max_length=100) content = models.TextField()使用以下命令在数据库中创建模型对应的表格:
python manage.py makemigrations
python manage.py migrate
这将自动创建与Article模型对应的数据库表格。
数据存储和查询
在Django的视图文件(views.py)中,可以使用模型类来存储和查询数据:
from django.shortcuts import renderfrom .models import Article
def create_article(request): if request.method == 'POST': title = request.POST.get('title') content = request.POST.get('content') Article.objects.create(title=title, content=content) articles = Article.objects.all() return render(request, 'articles.html', {'articles': articles})创建模板文件
在Django的模板文件(articles.html)中,展示文章列表:
<h1>Articles</h1><ul>{% for article in articles %} <li>{{ article.title }}</li>{% empty %} <li>No articles found.</li>{% endfor %}</ul>这个实战案例展示了如何在Django中配置和使用PostgreSQL来实现可靠和高性能的数据存储和查询。通过使用PostgreSQL作为数据库引擎,我们可以轻松地创建和管理数据库表,并使用Django的模型和查询API来实现数据的存储和查询。无论是开发一个博客平台还是一个电子商务网站,使用PostgreSQL都可以提供更好的数据管理和查询功能,从而提升应用程序的性能和用户体验。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

Django配置和使用Elasticsearch
在海量数据库上运行搜索引擎的应用程序经常面临这个问题:检索产品信息的时间太长。这反过来又会导致糟糕的用户体验,从而对应用程序作为数字产品的潜力产生负面影响。
Elasticsearch是一个开源的分布式搜索和分析引擎,具有强大的全文搜索和实时数据分析功能, 是一个 NoSQL 分布式数据存储,适用于灵活的面向文档的数据库,以匹配具有实时参与需求的苛刻工作负载应用程序。本章节中,我们将探讨如何在Django中配置和使用Elasticsearch,以实现高效的全文搜索功能。我们将使用Django的模型和视图来索引和搜索数据,并通过Elasticsearch提供的强大的查询功能来实现高性能的搜索。
关于Elasticsearch的详细介绍和使用,可以关注公众号CTO Plus查阅【Elasticsearch系列】的文章,包括安装与配置的使用。
Haystack
Django Haystack是一个用于全文搜索的库(框架),而Elasticsearch是一个强大的开源搜索引擎。连接Django和ES中间的一个框架,Haystack为Django提供模块化搜索。它具有统一的API,允许插入不同的搜索后端(例如Solr、 Elasticsearch、Whoosh、Xapian等),而无需修改代码。结合使用Django Haystack和Elasticsearch可以为Django项目提供高效的全文搜索功能。这个框架其他更多使用我将在公众号CTO Plus后面的文章中再做详细介绍。本章节演示如何在Django项目中使用Haystack和Elasticsearch进行全文搜索。
安装包
通过以下命令安装Python Elasticsearch库:
pip install django-haystack==3.1.1
pip install drf-haystack==1.8.11
pip install elasticsearch==7.17.9
pip install elasticsearch-dsl==7.4.0
注册应用
把haystack当做APP注册到项目里面
配置
在配置文件中配置haystack使用的搜索引擎后端
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine', # 引擎版本需要根据自己的版本进行选择 'URL': 'http://127.0.0.1:9200/', # es的服务地址 'INDEX_NAME': 'steverocket', # 索引的名称,必须是小写 }}本地不同的es,就需要不同的版本

HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
创建Elasticsearch索引
和django里面model一样,因为model里面的每一个类代表一个表,所以需要新建一个文件夹,放es里面的实体类,在Django的模型文件(models.py)中,定义一个模型类,并创建一个Elasticsearch索引:
from django.db import modelsfrom elasticsearch_dsl import Document, Text, Integerfrom elasticsearch_dsl.connections import connections
class Book(Document): title = Text() content = Text() author = Test()
class Index: name = 'articles'
connections.create_connection(hosts=[settings.ELASTICSEARCH_HOST])Article.init()在你的应用程序中,创建一个名为search_indexes.py的文件,并定义一个搜索索引类。例如,如果你的应用程序有一个名为Book的模型,可以创建一个名为BookIndex的搜索索引类:
from haystack import indexesfrom .models import Book
class BookIndex(indexes.SearchIndex, indexes.Indexable): content = indexes.CharField(document=True, use_template=True) title = indexes.CharField(model_attr='title') author = indexes.CharField(model_attr='author')
def get_model(self): return Book
def index_queryset(self, using=None): return self.get_model().objects.all()在上述代码中,content字段用于全文搜索,title和author字段用于过滤和排序。
索引数据
在Django的视图文件(views.py)中,可以使用模型类来索引数据:
from django.shortcuts import renderfrom .models import Article
def index(request): articles = Article.objects.all() for article in articles: Article(title=article.title, content=article.content).save() return render(request, 'index.html')搜索数据
在Django的视图文件(views.py)中,可以使用模型类来搜索数据:
from django.shortcuts import renderfrom haystack.query import SearchQuerySetfrom .models import Article
def search(request): query = request.GET.get('q') articles = Article.search().query("match", title=query).execute() # 或 # results = SearchQuerySet().filter(content=query)return render(request, 'search.html', {'articles': articles})
在上述代码中,query变量获取用户输入的搜索关键字,results变量使用Haystack提供的SearchQuerySet进行搜索。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

Django配置和使用MongoDB
MongoDB是一个流行的NoSQL数据库,以其灵活的数据模型和可扩展性而闻名。在某些应用场景中,如社交媒体应用、大数据分析等,使用MongoDB可以更好地存储和查询非结构化数据。
关于MongoDB的安装配置与详细使用介绍,关注公众号CTO Plus中的【MongoDB系列】文章。
Django操作MongoDB的方法
有三种方法连接Django到MongoDB数据库,如下:
1、PyMongo:PyMongo 是 MongoDB 与Django 交互的标准驱动程序。这是在 Python 中使用MongoDB 的官方和首选方式。 PyMongo 提供了执行所有数据库操作的功能,例如搜索、删除、更新和插入。由于 PyMongo 可与 PyPI 一起使用,可以使用 pip 命令快速安装它。
2、MongoEngine: MongoEngine 是一个 Python 对象文档映射器。它类似于关系数据库中的 Object-Relational-Mapper。 MongoEngine 具有易于学习和使用的声明式 API。
其中,PyMongo和MongoEngine在我的自研产品《威胁情报系统》和《数字化资产脆弱性分析和漏扫系统》中,结合Flask框架就使用到了。
3、Djongo:如果正在使用 SQL 这样的关系型数据库并希望迁移到 MongoDB,那么可以使用 Djongo。在不更改 Django ORM 的情况下,Djongo 将所有 SQL 查询转换为MongoDB 语法查询。
配置settings.py
# MongoDB djongoDATABASES = { 'default': { 'ENGINE': 'djongo', 'NAME': "django4", 'ENFORCE_SCHEMA': False, # 如果希望 Djongo 免迁移,请在的数据库配置中设置 ENFORCE_SCHEMA: False。使用此设置,集合是动态创建的,Djongo 不会将 SQL 语句转换为 MongoDB 命令。 'CLIENT': { 'host': 'mongodb://127.0.0.1:27017/django4', # 'username': '', # 'password': '', # 'authSource': 'admin1', # 'authMechanism': 'SCRAM-SHA-1', } }}
import mongoengine
mongoengine_conn = mongoengine.connect(host="127.0.0.1", port=27017, db="django4")不需要数据库迁移
def user_info(request): UserInfo.objects.create( name="python", age=22, addr="python.org.com", sex=True ) return st_HttpResponse(f"请求路径:{request.path}, 集合总数:{UserInfo.objects.count()}")请求执行完,自动在MongoDB的集合中插入数据
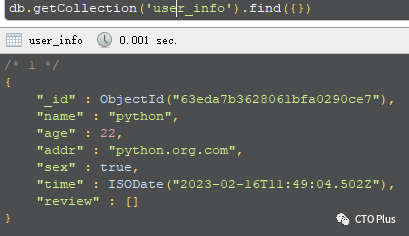
使用Django的ORM功能,可以将数据存储到MongoDB中,并进行查询操作。可以使用MongoDB的查询语言(MongoDB Query Language)来执行查询,并将结果返回给Django视图。
迁移migrate
迁移完成后查看库中生产的集合
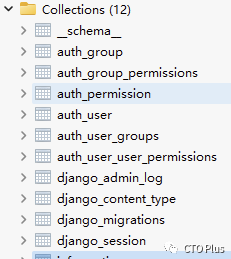
创建MongoDB模型
在Django的模型中,创建一个与MongoDB集合对应的模型类。可以使用Django的ORM功能来定义模型,并在模型中定义字段和索引。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

Django配置和使用Influxdb
InfluxDB是一个开源的时序数据库,专门用于处理时间序列数据。在某些应用场景中,如监控系统、物联网设备数据收集等,使用InfluxDB可以更好地存储和查询时间序列数据。
1. 安装InfluxDB和Python InfluxDB库
首先,需要在系统上安装InfluxDB服务,关于InfluxDB的安装配置与使用,可以参考公众号CTO Plus的【InfluxDB系列】文章。
可以通过以下命令安装InfluxDB和Python InfluxDB库:
$ sudo apt-get install influxdb
$ pip install influxdb
2. 配置Django设置
在Django的设置文件(settings.py)中,需要添加InfluxDB的相关配置,包括数据库连接信息、认证凭证等。
INFLUXDB = { 'host': 'localhost', 'port': 8086, 'username': 'admin', 'password': 'password', 'database': 'monitoring',}3. 创建InfluxDB模型
在Django的模型中,创建一个与InfluxDB数据库表对应的模型类。可以使用Django的ORM功能来定义模型,并在模型中定义字段和标签。
在Django的模型文件(models.py)中,创建一个与InfluxDB数据库表对应的模型类:
from django.db import modelsfrom influxdb import InfluxDBClient
class ServerMetrics(models.Model): time = models.DateTimeField() cpu_usage = models.FloatField() memory_usage = models.FloatField()
@classmethod def insert(cls, cpu_usage, memory_usage): client = InfluxDBClient(**settings.INFLUXDB) point = { "measurement": "server_metrics", "time": datetime.now().isoformat(), "fields": { "cpu_usage": cpu_usage, "memory_usage": memory_usage, } } client.write_points([point])
@classmethod def get_latest(cls): client = InfluxDBClient(**settings.INFLUXDB) query = 'SELECT * FROM server_metrics ORDER BY time DESC LIMIT 1' result = client.query(query) return result.get_points().next()4. 数据存储和查询
这里在使用Django和InfluxDB开发一个实时监控系统,用于监控服务器的性能指标(如CPU使用率、内存使用情况等)。通过定时任务,将服务器的性能数据存储到InfluxDB中,并使用Django的视图和模板来展示实时监控数据。
使用Django的ORM功能,可以将数据存储到InfluxDB中,并进行查询操作,使用InfluxDB的查询语言(InfluxQL)来执行查询,并将结果返回给Django视图,使用模型类来存储和查询数据,代码示例如下:
from django.shortcuts import renderfrom .models import ServerMetrics
def monitor(request): if request.method == 'POST': cpu_usage = float(request.POST.get('cpu_usage')) memory_usage = float(request.POST.get('memory_usage')) ServerMetrics.insert(cpu_usage, memory_usage) latest_metrics = ServerMetrics.get_latest() return render(request, 'monitor.html', {'latest_metrics': latest_metrics})5. 创建模板文件
在Django的模板文件(monitor.html)中,展示实时监控数据:
<h1>Real-time Monitoring</h1><p>CPU Usage: {{ latest_metrics.cpu_usage }}</p><p>Memory Usage: {{ latest_metrics.memory_usage }}</p>
<form method="post"> {% csrf_token %} <label for="cpu_usage">CPU Usage:</label> <input type="text" name="cpu_usage" id="cpu_usage"> <label for="memory_usage">Memory Usage:</label> <input type="text" name="memory_usage" id="memory_usage"> <input type="submit" value="Submit"></form>这个实时监控系统可以通过一个表单来输入CPU和内存使用情况,并将数据存储到InfluxDB中。在展示页面中,会显示最新的CPU和内存使用情况。
更多关于Django的相关技术点,敬请关注公众号:CTO Plus后续的发文,有问题欢迎后台留言交流。

最后
最后,这里简单介绍下关于ES、MongoDB和InfluxDB数据库的特点、优势和适用场景
Elasticsearch(ES)
特点:ES是一个分布式、可扩展的全文搜索和分析引擎,基于Lucene。它具有实时性、高可用性和强大的搜索功能。
优势:ES具有强大的全文搜索和分析功能,支持复杂的查询和聚合操作。它适用于实时数据分析、日志分析、搜索引擎和大规模数据的全文搜索。
ES适用场景:实时数据分析、日志分析、搜索引擎、大规模数据的全文搜索。
MongoDB
特点:MongoDB是一个面向文档的NoSQL数据库,使用JSON样式的文档存储数据。它具有灵活的数据模型和可扩展性。
优势:MongoDB适用于需要灵活的数据模型和高度可扩展性的场景。它支持复制和分片,可以处理大量的并发操作和海量数据。
MongoDB适用场景:需要灵活的数据模型和高度可扩展性的场景,如内容管理系统、用户配置文件和大规模数据存储。
InfluxDB
特点:InfluxDB是一个开源的时间序列数据库,专门用于存储和分析时间序列数据。它具有高性能、高可用性和易于使用的特点。
优势:InfluxDB适用于存储和分析时序数据,如传感器数据、监控数据和日志数据。它支持高精度的时间戳和灵活的数据模型。
InfluxDB适用场景:时间序列数据存储和分析,如传感器数据、监控数据和日志数据的存储和查询。
在某些情况下,使用默认的SQLite数据库可能无法满足我们的需求。通过配置和使用InfluxDB和MongoDB,我们可以在Django中更好地存储和查询时间序列数据和非结构化数据。通过经典的实战案例,我们可以更好地理解如何在Django中配置和使用InfluxDB和MongoDB,并将其应用于实际项目中。无论是开发实时监控系统还是社交媒体应用,使用InfluxDB和MongoDB都可以提供更好的数据存储和查询功能,从而提升应用程序的性能和用户体验。
Python专栏
https://blog.csdn.net/zhouruifu2015/category_5742543
最后,不少粉丝后台留言问加技术交流群,之前也一直没弄,所以为满足粉丝需求,现建立了一个关于Python相关的技术交流群,学习资料、代码和视频等将放在群中,加群验证方式必须为本公众号的粉丝,群号如下:
更多精彩,关注我公号,一起学习、成长

CTO Plus
一个有深度和广度的技术圈,技术总结、分享与交流,我们一起学习。 涉及网络安全、C/C++、Python、Go、大前端、云原生、SRE、SDL、DevSecOps、数据库、中间件、FPGA、架构设计等大厂技术。 每天早上8点10分准时发文。
Django推荐阅读:
代码规范和扫描推荐阅读:
推荐阅读:

