
- 1如何root安卓手机_超级神器——安卓端的手机虚拟机,手机中的手机(支持root,xp框架)...
- 2Android Studio Design界面不显示layout控件_visual studio创建没有layout
- 3浏览器查看Base64格式的图片_data:image/jpg;base64
- 4电脑没有ps怎么改照片dpi_零基础PS的自学教程,新手收藏
- 5教你如何批量查询快递单号,及时跟踪快递状态,马上学会
- 6操作系统——操作系统基础知识
- 7Android Q 限制后台启动Activity_background activity start
- 8最新ChatGPT GPT-4 NLU应用之实体分类识别与模型微调(附ipynb与python源码及视频)——开源DataWhale发布入门ChatGPT技术新手从0到1必备使用指南手册(六)
- 9四款AI视频翻译产品横评_ch?q=哪款软件可以和rask.ai媲美
- 10关于avd manager取用什么样的虚拟机(及genymotion的安装与设置)
论文阅读_解释大模型_语言模型表示空间和时间
赞
踩
英文名称: LANGUAGE MODELS REPRESENT SPACE AND TIME 中文名称: 语言模型表示空间和时间 链接: https://www.science.org/doi/full/10.1126/science.357.6358.1344 https://arxiv.org/abs/2310.02207 作者: Wes Gurnee & Max Tegmark 机构: 麻省理工学院 日期: 2023-10-03 引用次数: 81 |
1 读后感
作者想要研究的是:模型是只学习字面意思,还是能够学习到更深层次的知识。比如人名、地名以及与时间和空间相关的位置。为了实现这一目标,作者使用了 llama-2 模型,输入数据集中的名称,然后,对每一层的输出进行线性变换,以预测其所属的时间和空间类别。实验证明,在模型的低层就开始构建了关于时间和空间的表示。而在模型中间层达到饱和点时,参数已经学习到了实体相关的时空信息。
2 摘要
目标:分析模型是只学习字面意思,还是能够学习到更深层次的知识。
方法:通过分析 Llama-2 系列模型对三个空间数据集(世界、美国、纽约地点)和三个时间数据集(历史人物、艺术品、新闻头条)的学习表示来寻找的证据。
结论:分析表明,现代大型语言模型(LLMs)能够获取关于空间和时间等基本维度的结构化知识,这支持了它们不仅仅学习表面的统计数据,而是真正学习了世界模型的观点。
3 引言
一种假设是,LLMs 学习大量相关性。但在仅接受文本训练的情况下,它们缺乏对基础数据生成过程的“理解”。另一种假设是,LLMs 在压缩数据时,会学习训练数据基础的生成过程,并生成更紧凑、连贯和可解释的世界模型。
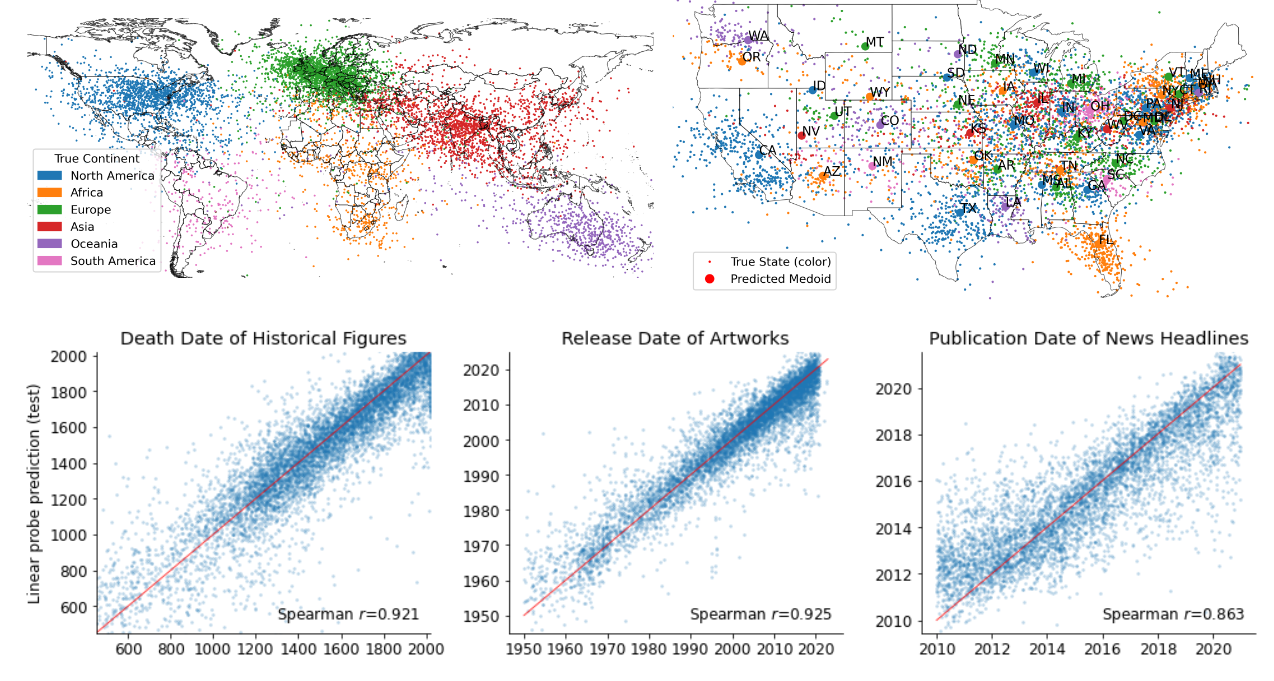
图 1:Llama-2-70b 的时空世界模型。每个点对应于投射到学习的线性探针方向上的位置或事件的最后一个 token 的第 50 层激活。所描述的所有点都来自测试集。
使用 Llama-2 模型训练线性回归探测器,以预测地点和事件名称的内部激活在真实世界中的位置或时间。实验结果表明,模型在早期层次中构建了空间和时间的表示,并在模型的一半左右达到饱和点。较大的模型始终表现优于较小的模型。此外,研究还展示了这些表示是线性的,因为非线性探测器并不能取得更好的效果。同时,这些表示对于提示变化非常稳健,并且在不同类型的实体(如城市和自然地标)之间是统一的。
4 实证概述
4.1 数据集
构建了六个名称数据集,分别包括人物、地点、事件等。这些数据集涵盖了跨越多个时空尺度的地点或事件名称,并提供相应的空间或时间坐标。其中包括全球范围内的地点、美国和纽约市,以及历史人物过去 3000 年的死亡年份、自 1950 年代以来艺术和娱乐作品的发布日期,以及 2010 年至 2020 年新闻头条的发布日期。
4.2 模型和方法
所有的实验都使用基础的 Llama-2 语言模型进行,该模型的参数范围从 70 亿到 700 亿。对于每个数据集,通过模型处理每个实体名称,可能在之前加上一个简短的提示,并保存最后一个实体标记在每个层上的隐藏状态激活。
在网络激活上拟合了一个简单的模型,用于预测与标记输入数据相关的目标标签。给定一个激活数据集和包含时间或二维纬度和经度坐标的目标
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

