
热门标签
热门文章
- 1一文搞懂业务中台、数据中台、AI中台区别及联系_业务中台与数据中台的区别
- 2【打工日常】使用docker部署轻量的运维监控工具
- 3自动驾驶汽车的规划与控制_汽车根据从环境能够获得路径信息的多少把路径规划分为什么和什么
- 4使用scrapy-redis构建简单的分布式爬虫_scrapy redis 使用
- 5CNN(六):ResNeXt-50实战_resnext50
- 6在k8s上部署dolphinscheduler_dolphinscheduler on k8s
- 7LeetCode 215. 数组中的第K个最大元素——Python实现(堆排序、快速排序)_数组中的第k个最大元素 leetcode python
- 8Linux——进程再识,进程状态、创建与写实拷贝_进程状态状态复制
- 9java1.8 HashMap 红黑树解析_hashmap1.8红黑树
- 10年度总结 | 2020年度有孚网络获誉总览_pdf有孚网络研究报告
当前位置: article > 正文
stable diffusion的额外信息融入方式_stable diffusion 加condition方法
作者:AllinToyou | 2024-03-12 20:44:16
赞
踩
stable diffusion 加condition方法
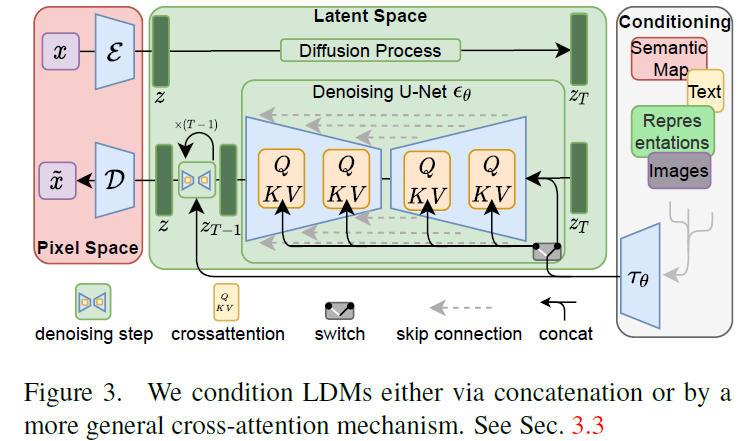
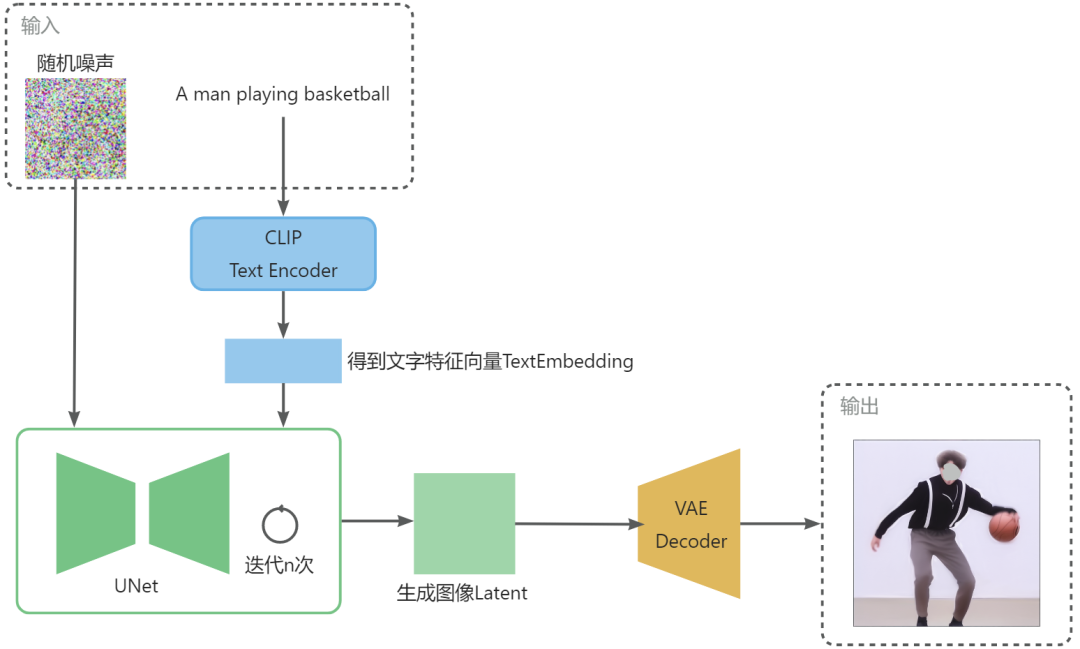
conditioning怎么往sd中添加,一般有三种,一种是直接和latent拼一下,另外很多是在unet结构Spatialtransformers上加,和文本特征一样,通过cross-attention往unet上加,这里还需要注意一点,在文本嵌入时,q是可学习的,k和v都是文本embedding。第三种就是类似controlnet这种,adapter设计。
1.sd img2img
sd的img2img的图像输入是通过VAE将图像转成image latent和latent一起拼的,将512x512的图转成64x64.
- init_latent = sd_model.get_first_stage_encoding(sd_model.encode_first_stage(image))
- image_conditioning = img2img_image_conditioning(image, init_latent, image_mask)
1.ip-adapter

通过解耦cross-attention的方式,clip提取图像特征,文本输入一个crossattention,图像输入一个cross-attention。
3.controlnet
stable diffusion使用和vq-gan相似的预处理方法,将512x512图像转成64x64的潜在图像,controlnet将image-based condition(就是从图像中获取线框图)转成64x64,我们使用4个4x4核和2x2strides的卷积层(后接relu,通常数分别是16,32,64,128,Guassian weights)将image-space condition转成特征图。

4.powerpaint
输入由latent+masked_image+mask concat组合,text侧还是clip编码之后送入unet进行cross-attention。

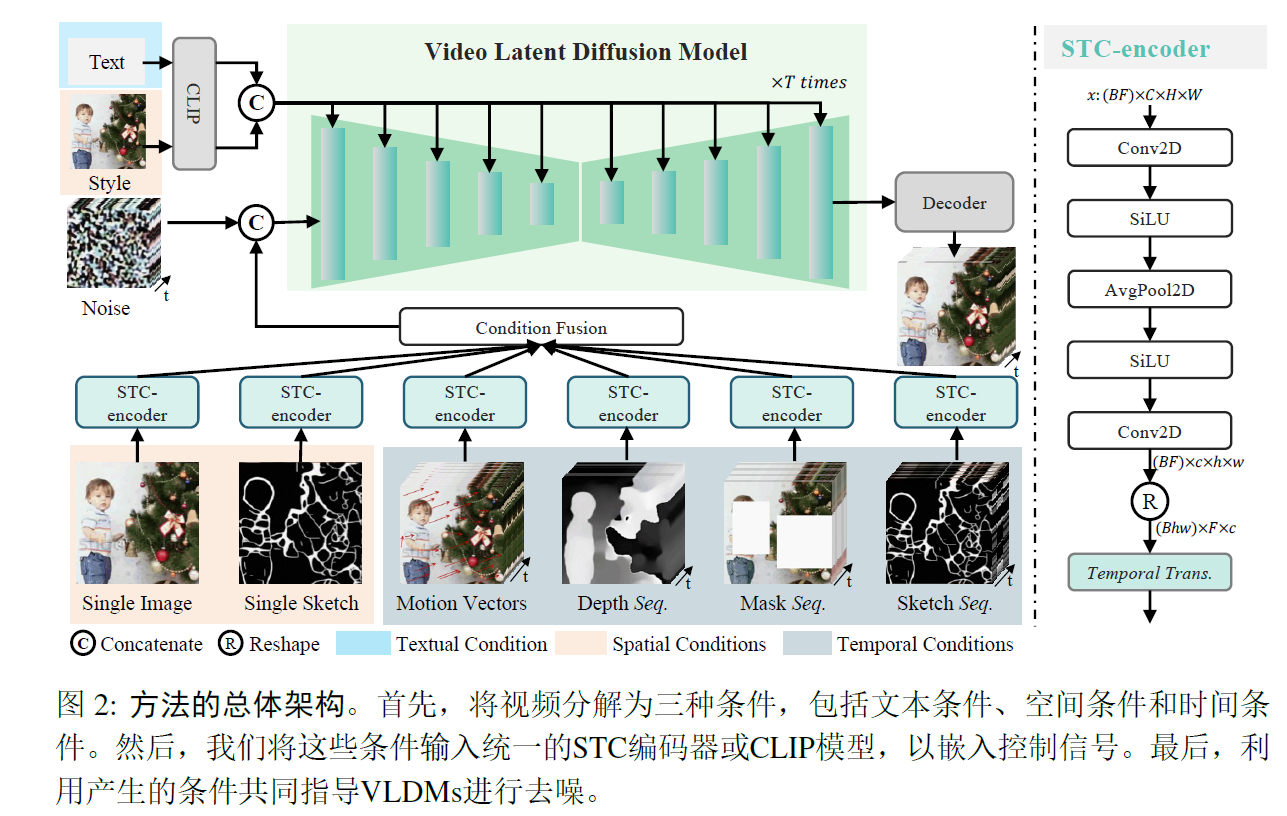
5.VideoComposer
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/225748
推荐阅读
相关标签

