
- 1月球绘画软件测试,宇宙飞船简笔画:第一个登上月球的宇航员
- 2东方终焉组引导页自适应html源码 视频背景炫酷_博客引导页源码 源码
- 3Vue3+AntdesignVue3/ElementPlus a-upload实现上传(上传前控制类型,数量,多文件限制大小自动拦截)、预览、单个下载、删除(删除前确认)、批量下载(压缩包)(终极版)_ant design vue3上传大文件
- 4.net百度编辑器的使用
- 5Mysql数据库的高级应用(存储过程,触发器、索引,视图,函数)_mysql数据库高级应用
- 6低代码开发大势所趋,这款无代码开发平台你值得拥有_ivx编辑器
- 7数字化运营在教育行业的技术架构实践总结
- 8Android : Broadcast_broadcast of intent
- 9吃饭睡觉打豆豆_用java编写小明吃饭睡觉打豆豆
- 10Linux中的vi/vim编译(一)_linux对vi程序编译
CAS-KG——知识图谱概述_kg知识图谱
赞
踩
说明:CAS是国科大的简称,KG是知识图谱的缩写,这个栏目之下是我整理的国科大学习到的知识图谱的相关笔记。
课程目标
- 了解以知识图谱为代表的大数据知识工程的基本问题和方法
- 掌握基于知识图谱的语义计算关键技术
- 具备建立小型知识图谱并据此进行数据分析应用的能力
教学安排
详情请见博客:CAS-KG——课程安排
1. 什么是知识图谱
首先,知识图谱肯定是属于AI的重要研究方向,所以先来介绍一下人工智能。
人工智能的三个阶段
- 计算智能
- 运算和存储能力
- 感知智能
- 感知是人和动物通过感觉器官与自然界进行交互的能力
- 视觉、听觉、触觉等
- 认知智能
- 特指人在感知世界以及人与人互动的过程中形成的、对世界万物的理性认识,包括记忆、概括、推理等。
- 与知识密不可分
什么是知识
- Plato:是永恒不变的且适用于世间万物的真理。
- Davenportr:是与经验(Experience)、背景(Context ) 、 解 释 ( Interpretation ) 和 思 考 (reflection)结合在一起的信息,是一种可以随时帮助人们决策与行动的高价值信息。
- Harris:是信息、文化脉络及经验的组合。
- Feigenbaum:是经过消减、塑造、解释和转换的信息,即知识就是经过加工的信息。
- Bernstein:由特定领域的描述、关系和过程组成。
- Hayes-Roth:是事实、信念和启发式规则。
- Nonaka:分为两种,其中显式知识指可以用正式、系统化的语言传输的知识;而隐性知识拥有个性化的特征,很难进行形式化描述和分享。
数据,信息和知识
- 数据
- 反映客观事物运动状态的感知信号,可以是符号、文字、数字、语音、图像、视频等,是人脑感知的最原始的记录,未经加工和解释,与其他数据没有联系,因此不具有语义,不能回答任何问题。
- 信息
- 经过加工和解释,通过某种关联而具有含义的数据。
- 知识
- 经过挑选、改造形成的、可以用于决策的、系统化的信息
知识工程:数据和信息 → 知识
知识的类型:陈述性、过程性
-
陈述性知识:描述客观事物的性状和关系等静态信息,主要分为事物、概念、命题三个层次。
- 事物:指特定的事或物。
- 概念:指对一类事物本质特征的反映。
- 命题:对事物之间关系的陈述。
- 非概括性命题:表示特定事物之间关系
- 概括性命题:描述概念之间的普遍关系
-
过程性知识:描述问题如何求解等动态信息。
- 规则:描述事物的因果关系
- 控制结构:描述问题的求解步骤
什么是知识库
- 在对各种知识进行收集和整理的基础上,进行形式化表示,按照一定方法存储,并提供相应的知识查询手段,就形成知识库。
- 知识共享和应用的基础。
- 知识图谱是知识库的一种形式。
知识工程
1977年,在第五届国际人工智能会议上,美国斯坦福大学计算机科学家费根鲍姆教授
(E.A.Feigenbaum) 发表特约文章“人工智能的艺术:知识工程课题及实例研究”,系统地阐述了“专家系统”的思想,并提出了“知识工程”的概念,确定了知识在人工智能中的重
要地位。
依赖专家构建知识,在受限领域的专家系统中取得成功。
- 泛化性不强
大数据知识工程
-
大数据时代,信息无法得到有效利用
- 全球数据以每年 58% 的速度增长
- 包括互联网大数据,行业大数据(金融、医疗、司法、电商等等)
- 大数据中,信息以多种形式存在
- 图片、声音、文字、视频
- 结构化、半结构化、非结构化
-
其中约 80% 是非结构化数据
-
23%的有用数据,3%的数据具有标注信息,0.5%的数据被利用
-
大数据中蕴含丰富的知识,迫切需要对大数据进行知识化,转化为大知识
- 目的:让计算机更加有效地管理和利用信息
- 知识化:
- 结构化:挖掘非结构化数据蕴含的语义,转换成结构化形式
- 关联化:刻画知识单元之间的多层次、多维度的关联
总结一下:大数据知识工程——大规模、开放域、多维度、自学习
那么知识图谱就是大数据知识工程的一种非常典型的形态。
知识图谱:源起
- Google公司的知识图谱项目,体现在:
- 使用Google搜索引擎时,出现于搜索结果右侧的相关知识展示。
- Q:亚里士多德哪年结婚?
- A:公元前326年

- 2016年底,Google知识图谱中的知识数量已经达到了600亿条,包括1500个类别
的5.7亿个实体,以及它们之间的3.5万种关系。
知识图谱:图的结构
-
以结构化三元组的形式存储现实世界中的实体及其关系,表示为 G = ( ε , R , S ) G = (\varepsilon ,R,S) G=(ε,R,S),三元组通常描述了一个特定领域中的事实,由头实体、尾实体和描述这两个实体之间的关系组成。
- 实体集合: ε = { e 1 , e 2 , . . . , e ε } \varepsilon = \{ {e_1},{e_2},...,{e_\varepsilon }\} ε={e1,e2,...,eε}
- 关系集合: R = { r 1 , r 2 , . . . , r ∣ R ∣ } R = \{ {r_1},{r_2},...,{r_{|R|}}\} R={r1,r2,...,r∣R∣}
- 三元组的集合: S ⊆ R × ε × ε S \subseteq R \times \varepsilon \times \varepsilon S⊆R×ε×ε
-
关系有时也称为属性,尾实体被称为属性值。
-
从图结构的角度看,实体是知识图谱中的节点,关系是连接两个节点的有向边。
知识图谱示例
- WikiData
- 知识结构
- <physicist, subclass of, scientist>
- <place of birth, value type constraint, geographical object>
- <place of birth, subproperty of, location>
- 知识结构
- 实例数据
- <Max Planck, instance of, human>
- <Max Planck, occupation, physicist>
- <Max Planck, place of birth, Kiel>

知识图谱:大数据知识工程的高效模型
- 结构化:图是一种能有效表示数据之间结构的表达形式,因此,知识图谱可以很好地建模大数据中蕴含的知识结构。
- 关联化:可以通过图中节点的关联和边的关联把多个来源的知识图谱自然地关联起来,从而实现知识融合。
- 规范化:结构化和关联化都采用统一的知识描述框架——语义网框架,便于知识的分享与利用。
知识图谱:人工智能的重要基础设施
- 知识图谱以丰富的语义表示能力和灵活的结构构建了在计算机世界中表示认知世界和物理世界中信息和知识的有效载体。

2. 知识图谱发展历程






- 人工智能:知识的数据化——让计算机表示、组织和存储人类的知识
- 人工智能的研究目标是使计算机更智能,让计算机能够完成一些人脑才能完成的任务,例如推理、分析、预测、思考等高级思维活动。人们希望借助知识库完成该目标,即把人类的知识用计算机进行表示和组织,并设计相应算法完成推理、预测等任务。
- 语义网:数据的知识化——让数据支持推理等智能任务
- 随着互联网的发展,虽然存储和检索海量数据的能力日益提高,但是没有推理、预测等完成复杂任务的功能,不能有效支持行业智能等决策任务。人们希望通过引入知识,使得原始数据能够支撑推理、问题求解等复杂任务(如多维数据分析),这个目标就是语义网。


3. 知识图谱的类型和代表性知识图谱
词语、实体、关系、属性
- 实体:entity,客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念。
- 关系:relation,不同的实体之间各种联系。
- Taxonomic Relation
- Hypernym-Hyponym
- is-a
- Non-taxonomic Relation
- Meoronymy部分整体
- Thematic roles 论旨角色
- Attribute属性
- Possession 领属
- Casuality因果,等等
- Taxonomic Relation
- 词语:word and phrases,用于描述实体、关系这些认知单元的语言单位。实体和关系是有确切含义的;词语是有歧义的,在不同的语境中指称不同的实体或关系。
Ontology(本体)vs.Knowledge Base(知识库) vs.Database(数据库)
- Ontology:本体,一套对客观世界进行描述的共享概念化体系。它对特定领域中概念(事物的类型)及其相互关系进行形式化表达,重点是对数据的定义进行描述,而不是描述具体事物的实例数据。
- 涉及概念、关系和公理三个要素
- 比如:运动员就是一个本体,而姚明是一个实例。
- Knowledge Base:知识库,服从于ontology 控制的知识实例及其载体。
- 比如说:姚明多少岁,属于某个球队 就是实例数据。
- Database:数据库,计算机科学家为了用电脑表示和存储计算机应用中所需要的数据所设计开发的产品。
举个例子来说:比如做蛋糕的时候,做蛋糕的模具就是 本体,做好的蛋糕就是 知识库,装蛋糕的盒子就是 数据库。
Formal Ontology(形式化的本体) vs. Lightweight Ontology(轻量级的本体)
- Formal Ontology: 大量使用公理【严格的本体】
- Lightweight Ontology: 不用或很少使用公理
Ontology(本体) vs.Taxonomy(层及分类体系) vs. Folksonomy(社会分类法)
- Taxonomy:分类法,或称分类体系,是由专家编制的专业层次类别体系,如中图分类体系(中国图书)等。也有一些不严格的分类体系,通常由一些组织为了自身需要而编制,如Yahoo分类目录等。
- Ontology:本体,共享概念的规范。Ontology通常涵盖概念之间的分类体系,但是除此之外,更重要的是它还有概念之间的相关关系,如反向、传递、对称等,以及在此基础上建立的推理规则,从而支持复杂推理。由于具有严格的规范,一般用户难以构建。
- Folksonomy:社会分类法,是由用户的自由标签自动形成的一种分类法,在对同一事物进行标签的所有标签中,取出高频标签作为分类标签。严格讲,是一种标签方法,并不一定构成一个分类体系。另一方面,标签具有随意性(歧义性)。
知识的类型
- 语言知识:语言层面上的知识,例如:Microsoft 的缩写是MS;乔丹和佐敦具有同指关系;减肥和瘦身是同义词等。
- 百科知识:涵盖各个行业、领域的通用知识,例如:人物、机构、地点等。
- 领域知识:某个领域内特有的专业知识,例如:法律知识、金融知识等。
- 场景知识:某个特定场景下或者需要完成某项任务时所需要的知识,例如:在订机票过程中需要提供的信息;盖房子的步骤等。
- 常识知识:那些大家都认可的知识,例如:狗有四条腿、鸟会飞等。
知识图谱的类型:知识类型
- 语言知识图谱:
- WordNet
- 常识知识图谱:
- Cyc、ConceptNet、HowNet
- 百科知识图谱:
- DBpedia、Freebase、Google KG、Wikidata
- 语言+百科知识图谱:
- YAGO、BabelNet
- 领域知识图谱:
- 医学知识图谱SIDER(Side Effect Resource)
- 电影知识图谱IMDB (Internet Movie Database)
- 音乐知识图谱MusicBrainz
代表性的知识图谱

KG介绍—— Cyc
- 介绍:
Douglas Lenat于1984 年创建,最初的目标是依靠专家将上百万条人类常识编码为机器可处理的形式,建立最大的常识知识库,从而支持复杂的机器推理任务。
例如:“每棵树都是植物”、“植物最终都会死亡”。
当提出“树是否会死亡”的问题时,推理引擎可以得到正确的结论,并回答该问题。
采取CycL语言来进行描述,该语言基于谓词逻辑,语法上与Lisp程序设计语言类似。
主要由术语Terms和断言Assertions组成。
Terms:包含实体、概念和关系的定义。
Assertions:用来建立Terms之间的关系,不仅包含大量事实Facts,还包含用于推理的常识规则Rules。
在此基础上提供多种推理引擎,支持演绎推理和归纳推理,同时也提供扩展推理机制的模块。
- Cyc:断言(事实)
-
(#$isa#$BillClinton#$UnitedStatesPresident)
- 表示:“Bill Clinton属于美国总统集合”
-
(#$genls#$Tree-ThePlant#$Plant)
- 表示:“所有的树都是植物”
-
(#$capitalCity#$France #$Paris)
- 表示“巴黎是法国的首都”
- Cyc:断言(规则)
- 一条与 #$isa 谓词有关的一条规则
(#$implies
(#$and
(#$isa?OBJ ?SUBSET)
(#$genls?SUBSET ?SUPERSET))
(#$isa?OBJ ?SUPERSET))
解释为:"若OBJ为集合SUBSET中的一个实例,并且SUBSET是SUPERSET的子集,则OBJ是集合SUPERSET的一个实例。
- 另一条规则
(#$relationAllExists #$biologicalMother #$ChordataPhylum #$FemaleAnimal)
解释为:
对于脊索动物(chordate)集合#$ChordataPhylum中的所有实例,都存在一个母性动物(为#$FemaleAnimal的实例)作为其母亲(通过谓词#$biologicalMother描述)。
-
Cyc Ontology

-
Cyc:局限性
- 基于形式化的一阶谓词逻辑表示方法刻画知识,优势是可以支持复杂的逻辑推理。但是过分严格的形式化也导致知识库的扩展性和应用的灵活性不够。
- 由专家构建,虽然准确,但是费时费力,规模和范围远远不够。因此,近年来Cyc 也开始使用一些自动构建的方法从非结构化文本中自动抽取知识。从2008 年开始,Cyc 开始将其资源与Wikipedia、DBpedia等资源进行关联,建立它们之间的链接。
KG介绍——WordNet
- 介绍
1985年,Princeton 大学建立的英文词汇语义知识库(英文词汇知识图谱)。
理论基础:德国学者特雷尔的现代语义学理论——语义场理论。- 语言中的词汇在语义上是相互联系的,共同构成一个完整的词汇系统。通过分析、比较词与词之间的语义关系,才能确定其真实含义。
- 语义场根据词语关系的不同,可以归为四类:上下义义场、整体与部分义场、同义义场、反义义场
采用人工标注方法,将英文单词按照其语义组成一个大的概念网络。
词语被聚类成同义词集(Synset),每个同义词集表示一个基本的词汇语义概念。
词集之间的语义关系包括同义关系、反义关系、上位关系、下位关系、整体关系、部分关系、蕴含关系、因果关系、近似关系等。
1991 年,WordNet1.0 版本正式公布,目前WordNet 包含146,350 个单词, 111,223 个同义词集。
-
WordNet组织示例:上下位、同义

如上图:{equipment} 和 {camera} 是上下位的关系,而camera 和 photographic camera 是同义的关系。 -
WordNet组织示例:近义、反义

KG介绍—— FrameNet
- 介绍
语义框架库(与Wordnet不同,WordNet描述的是词汇之间的聚合语义,而FrameNet 描述的是词语之间的组合予语义)
1997年开始,由Berkeley构建的词汇语义知识库。
理论基础:美国语言学家Fillmore的框架语义学理论
语义框架:对词语蕴含概念的知识预设,是人类长期实践中形成并用于组织和解释经验的知识架构和概念工具。
——————————————————————
“烹饪”这一概念的框架通常包括:烹饪的发起者(厨师)、烹饪的对象(食物)、烹饪的工具(容器)和加热的来源(加热设备)等等。
框架名称:烹饪
框架元素:厨师、食物、容器和加热设备
词语单元:最能指示该框架发生的词,例如烘焙、油炸、蒸煮等。
——————————————————————
Frame具有层级的组织结构,位于最上层的节点表示框架,框架之间的边表示框架间的关系。
框架间的关系 继承、视角、子框架、前置、始动、因果、使用、参考等八种
FrameNet规模 1000+ 框架 10000+ 词法单元 150000+ 标注例句

KG介绍—— 知网:HowNet
-
介绍
知网是对概念与概念之间的关系以及概念的属性与属性之间的关系进行描述而形成的一个网状的知识系统。
区别于Wordnet,HowNet并不是将所有概念归结到一个树状的概念层次体系中,而是试图用一系列的义原对每一个概念进行描述,义原之间通过义原关系进行关联,从而使得HowNet是一个网状的知识系统。
概念:对词汇语义的一种描述。一个词可以表达多个概念,一个概念也可以用多个词表示。
在知网中,概念是用一种“知识表示语言”来描述的,这种“知识表示语言”所用的词汇叫做义原。
义原是用于描述一个概念的最小意义单位。 -
知网:义原体系
知网总共有1500多个义原,分为以下大类:

-
知网:义原关系
义原之间的关系:
上下位关系
同义关系
反义关系
对义关系
属性-宿主关系
部件-整体关系
材料-成品关系
事件-角色关系
义原之间通过这些关系组成一个复杂的网状结构。 -
知网:符号体系
除了义原之外,知网还用了一些符号来对概念的语义进行描述。
表示语义描述式之间的逻辑关系:~ ^
表示概念之间的语义关系:包括以下几个符号:# % $ * + & @ ? !
特殊符号:{} () []

-
知网:知识表示语言
利用基于义原和符号的知识表示方式,对概念与概念之间的关系以及概念的属性与属性之间的关系进行描述而形成的一个网状的知识系统。
男士:DEF=human|人,male|男
洗衣机:DEF=tool|用具,* wash|洗涤,#clothing|衣物
* 表示洗涤为用具的功能
# 表示衣物为洗涤的受事
KG介绍—— ConceptNet
-
ConceptNet是由描述概念及其关系的常识构成的一个开放的、多语言的常识知识图谱。
-
最早起源于MITMediaLab 的一个知识工程项目:Open Mind Common Sense(OMCS),该项目由人工智能之父、框架理论的创立者Marvin Minsky于1999年建议创立,致力于帮助计算机理解人们日常使用的单词的意义。
-
ConceptNet5包含8百万节点,2100万关系描述。主要通过专家构建、互联网众包和游戏三种方式构建。新版本导入了大量开放的结构化数据:DBPedia,Wikinary,Cyc,WordNet等。
-
与Cyc是一个基于谓词逻辑的常识本体相比,ConceptNet采用词语关系三元组描述,形式较为简单。
-
与DBPedia和GoogleKnowledgeGraph重点描述实体关系相比,ConceptNet侧重于自然语言中普通词的常识意义(Common-sensemeaning)。
-
更加接近于WordNet,但是包含的关系类型更多。
-
ConceptNet的节点是词语,有些词语的歧义通过词性、类别等进行消除。

-
ConceptNet的关系是专门制定的语义类别,具有确切含义。
-
36个核心关系类别


前面几个知识图谱都是需要借助大量人工构建的,下面几个是主要是依靠机器自动构建的。
KG介绍—— 基于Wikipedia的知识库
- 介绍
基于Wikipedia的知识库都基于几乎相同的思路:
从Wikipedia丰富的半结构化信息中挖掘知识
包括:Infobox,Category,超链接,Table,List…
不同之处在于
如何为知识库的每个节点确定唯一的ID
如何处理有歧义的属性映射
如何构建知识库的Taxonomy

- 基于Wikipedia知识库的构建策略
通过页面的Title、超链接词汇等确定知识库的实体集合
猫王、李世民、赵高、唐朝、分封制…
实体被划分到不同的类别中
歌手(猫王),皇帝(李世民),朝代(唐朝),制度(分封制)
类别通过上下位等关系相互关联
SubClassOf(歌手,人),SubClassOf(皇帝,人)
实体和类别都通过属性和相互之间的关系来描述
BirthDate(李世民,598年),Has(歌手,歌曲)
关系可以通过蕴含关系来进行推理
歌曲 → \to →作品,收购 → \to →持有
KG介绍—— DBPedia
-
介绍
2007年开始,其主要目标是构建一个社区,通过社区成员来定义和撰写准确的抽取模板,从维基百科中抽取结构信息,并将其发布到Web上。
DBPedia 总共包含95 亿事实三元组
13 亿数据抽取自英文版维基百科
50 亿数据抽取自其他语言的维基百科
32 亿抽取自Wikidata 数据 -
Dbpedia的抽取方法
社区通过人工的方式构建了Ontology
280个类别
覆盖约50%的维基百科实体
DIEF -DBpedia Information Extraction Framework
目标:抽取Wikipedia中的结构化信息
方法:基于属性mapping的Infobox抽取,Raw Infobox Extraction, Feature Extraction, Statistical Extraction
编程语言:Scala & Java
DBPediaLive:持续保持与Wikipedia的同步
2013年六月,英语维基百科有将近330万次编辑(每分钟越77次) -
抽取框架图

KG介绍—— YAGO
德国马普研究所从2007年开始的一个项目
YAGO基于WordNet的知识体系,将Wikipedia中的类别与WordNet 中的类别进行关联,同时将Wikipedia 中的条目挂载到WordNet 的体系下。
通过语言本体和世界知识的融合,一方面扩充了语言知识库,另一方面对海量的世界知识进行了组织和整理。

使用RDFs(RDF Schema )语言与OWL(OntologyWebLanguage)语言描述,构成一个具有清晰完整逻辑定义的知识系统。
YAGO2在2017 年人工智能国际顶级学术会议IJCAI2017 上获得由Artificial Intelligence Journal(AIJ) 颁发的卓越论文奖(Prominent Paper Award)。
KG介绍—— BabelNet
多语言词汇语义网络和本体,由罗马萨皮恩扎大学创建。
与YAGO类似,BabelNet也是将维基百科链接到WordNet 上。但是BabelNet加入了多语言支持,目前覆盖了271种语言,包栝全部的欧洲语言、大多数亚洲语言及拉丁语。
包含大约1400 万个同义词集和7.46 亿个词义。
BabelNet同YAGO一起,在IJCAI2017上获得卓越论文奖。
KG介绍 —— Freebase
从Wikipedia和其他数据源(如IMDB、MusicBrainz)中导入知识
核心想法:
在Wikipedia中,人们编辑文章
在Freebase中,人们编辑结构化知识
Metaweb公司2000年开始构建
基于维基百科、使用群体智能方法建立的完全结构化的知识资源。
是公开可获取的规模最大的知识图谱之一。
包含4726 万实体、19亿个实体关系三元组
2010年被谷歌收购并纳入到谷歌知识图谱中。
2015 年,谷歌关闭了Freebase,并把数据全部迁移到Wikidata。
用户构建知识的步骤

KG介绍 —— Google:Knowledge Vault
2014年创建的一个大规模知识图谱。
相较于Google之前基于Freebase的知识图谱版本,KnowledgeVault不再采用众包方式进行图谱构建,而是通过机器学习方法自动搜集网上信息,并与已有的结构化数据进行融合,构建知识图谱。
集成和融合YAGO、Freebase、网页中的表格数据等
目前,KnowledgeVault已经收集了16亿个事实
2.71亿事实具有高置信度,准确率在90%左右。
KG介绍 —— KnowItAll
华盛顿大学图灵中心的开放信息抽取项目
目标:让机器自动阅读互联网文本内容,从大量非结构化文本中抽取结构化的实体关系三元组信息。
区别于传统的文本信息抽取系统,这里要抽取的关系(Predicate)不是预定义的,是开放性的;但是头实体Subject和尾实体Object是确定性的(利用Freebase的实体消歧工具进行消歧)。
KnowItAll:TextRunner& ReVerb
TextRunner和Reverb系统是KnowItAll项目中的两个代表系统。
主要功能:
从文本中通过识别句子的谓词抽取所有的二元关系
利用网络数据的冗余信息,对初步认定可信的信息进行评估。
可以在系统中直接查询知识(实体关系三元组)
KG介绍 —— NELL
卡内基梅隆大学基于Read the Web项目开发的一套“永不停歇的语言学习”系统。
Never-Ending Language Learning
系统每天不间断地执行两项任务:阅读和学习
阅读任务从Web文本中获取三元组知识,并添加到内部知识库
学习任务目标是提升机器学习算法的性能
区别于KnowItAll,NELL抽取的实体类别和关系类别都是确定的。
实体:300多类;关系:900多类
目前规模:三元组5000万,高质量的280万
通用知识图谱vs. 领域知识图谱



4. 知识图谱的生命周期
知识图谱的生命周期
知识图谱建模的6个阶段可以分为:
- 知识本体构建
也叫知识建模
建模领域知识结构 - 知识获取和验证
获取领域内的事实知识
估计知识的可信度 - 知识融合
也叫知识集成
将碎片知识组装成知识网络 - 知识存储和查询
采用何种方式对知识图谱进行存储
采用何种方式对知识图谱进行查询 - 知识推理
发现已有知识中隐含的知识 - 知识应用
提供高性能知识服务
知识本体构建(知识建模)
指采用什么样的方式表达知识,其核心是构建一个本体对目标知识进行描述。该本体需要:
-
定义出知识的类别体系
-
每个类别下所属的实体和概念
-
某类概念和实体所具有的属性以及概念之间、实体之间的语义关系
-
定义在这个本体上的一些推理规则
——————————————————————
比如 :
Freebase的知识体系
定义了超过1.5 万个概念类别和4,000 个属性
对每个类别定义了若干关系,并制定关系的值域约束其取值。
—————————————————————— -
输入:
领域(医疗、金融…)
应用场景 -
输出:领域知识本体
领域实体类别体系
实体类别的属性
类别之间的语义关系
语义关系之间的关系 -
关键技术:
Ontology Engineering(本体工程)
作为语义网的应用,知识图谱的知识建模采用语义网的知识建模方式,分为概念、关系、概念关系三元组三个层次,并利用“资源描述框架(RDF)”进行描述。
RDF 的基本数据模型包括了三个对象类型:
- 资源(Resource)
能够使用RDF 表示的对象称之为资源,包括互联网上的实体、事件和概念等。 - 谓词(Predicate)
主要描述资源本身的特征和资源之间的关系。每一个谓词可以定义元知识,例如,谓词的头尾部数据值的类型(如定义域和值域)、谓词与其他谓词的关系(如逆关系)。 - 陈述(Statements)
一条陈述包含三个部分,通常称之为RDF 三元组< 主体(subject),谓词(predicate),宾语(object)>。其中主体是被描述的资源,谓词可以表示主体的属性,也可以表示主体和宾语之间关系。当表示属性时,宾语就是属性值;当表示关系时,宾语也是一个资源。
知识获取
-
输入:
领域知识本体
海量数据:文本、垂直站点、百科 -
输出:实例知识
实体集合
实体关系/属性 -
主要技术:
信息抽取
文本挖掘
————————————————————————————————
举个例子说明知识获取:
2011年4月11日17点16分,日本东北部的福岛和茨城地区发生里氏7.0级强烈地震(震中北纬36.9度、东经140.7度,即福岛西南30公里左右的地方,震源深度10公里,属于浅层地震)当局已经发布海啸预警震后约30分钟后在日本海地区发生巨型海啸,同时造成福岛核电站出现核泄漏震后第十天,国际原子能机构对于日本政府反应迟钝进行了谴责。

知识融合
-
输入:
抽取出来的知识
知识本体
现有知识库 -
输出:
统一知识库
知识置信度 -
Ontology Matching
Entity Linking
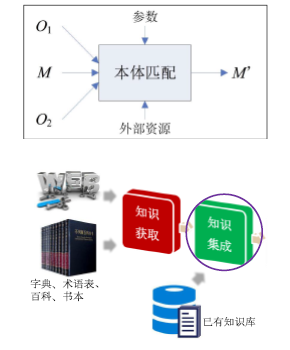
- 任务:对不同来源、不同语言或不同结构的知识进行融合,从而对于已有知识图谱进行补充、更新和去重。
- YAGO:对专家构建的高质量语言知识图谱WordNet 和网民协同构建的大规模实体知识图谱Wikipedia 进行融合而形成的,实现质量和数量的互补;
- BabelNet:融合不同语言的知识图谱,实现跨语言的知识关联和共享。
- 从融合的对象看,可以分为知识本体融合和知识实例融合。
知识本体融合:两个或多个异构知识体系进行融合,即对相同的类别、属性、关系进行映射。
知识实例融合:对于两个不同知识图谱中的实例(实体实例、关系实例)进行融合,包括不同知识本体下的实例、不同语言的实例等 - 从融合的知识图谱类型看,可以分为:竖直方向的融合和水平方向的融合。
竖直方向的融合:融合(较)高层通用本体与(较)底层领域本体或实例数据,【上下位的挂接】
融合Wordnet 和Wikipedia
水平方向的融合:融合同层次的知识图谱,实现实例数据的互补。
融合Freebase 和DBpedia
知识存储和查询
-
输入:
大规模知识图谱 -
输出:
知识库存储结构
查询服务 -
主要技术:
知识表示
知识查询语言
存储/检索引擎
存储模型(1)—— RDF图模型
RDF三元组:以文本的形式逐行存储
Google 开放的Freebase 知识图谱


RDF图查询语言:SPARQL

上面是以文本形式存储的RDF图,中间是查询形式,下面是查询结果。
存储模型(2)—— 属性图模型
-
属性图G是5元组:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/227070
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

