
- 1Could not create the Java Virtual Machine 【为eclipse分配的内存不足】_ecplice could not create virtual machine
- 2pscp+psftp+putty的使用_psftp使用putty session
- 3讯飞语音——唤醒_讯飞语音遥控器 csdn
- 4基于微信小程序在线订餐外卖系统 (后台java+Springboot框架)答辩常规问题和如何回答(答辩指导)
- 5mac 查看本机 ip_mac查询ip地址命令
- 6Go | 限流器实现_go queue ratelimiter
- 7鸿蒙对象关系映射数据库_鸿蒙 orm框架
- 8鸿蒙应用开发之数据请求_鸿蒙js开发模式下请求接口封装
- 9CMU15445 fall 2022/spring 2023 项目环境搭建+选择合适的版本_配置15445的环境
- 10从0到1搭建数据仓库流程_数据仓库搭建
一文解决图片数据集太少的问题:详解KerasImageDataAugmentation各参数
赞
踩

作者 | Professor ho
本文转自Professor ho的知乎专栏
图像深度学习任务中,面对小数据集,我们往往需要利用Image Data Augmentation图像增广技术来扩充我们的数据集,而keras的内置ImageDataGenerator很好地帮我们实现图像增广。但是面对ImageDataGenerator中众多的参数,每个参数所得到的效果分别是怎样的呢?本文针对Keras中ImageDataGenerator的各项参数数值的效果进行了详细解释,为各位深度学习研究者们提供一个参考。
我们先来看看ImageDataGenerator的官方说明(https://keras.io/preprocessing/image/)
keras.preprocessing.image.ImageDataGenerator(featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-6,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode='nearest',
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=K.image_data_format())
官方提供的参数解释因为太长就不贴出来了,大家可以直接点开上面的链接看英文原介绍,我们现在就从每一个参数开始看看它会带来何种效果。
我们测试选用的是kaggle dogs vs cats redux 猫狗大战的数据集,随机选取了9张狗狗的照片,这9张均被resize成224×224的尺寸,如图1:

图1
1. featurewise
datagen = image.ImageDataGenerator(featurewise_center=True,
featurewise_std_normalization=True)
featurewise_center的官方解释:"Set input mean to 0 over the dataset, feature-wise." 大意为使数据集去中心化(使得其均值为0),而samplewise_std_normalization的官方解释是“ Divide inputs by std of the dataset, feature-wise.”,大意为将输入的每个样本除以其自身的标准差。这两个参数都是从数据集整体上对每张图片进行标准化处理,我们看看效果如何:

图2
与图1原图相比,经过处理后的图片在视觉上稍微“变暗”了一点。
2. samplewise
datagen = image.ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True)
samplewise_center的官方解释为:“ Set each sample mean to 0.”,使输入数据的每个样本均值为0;samplewise_std_normalization的官方解释为:“Divide each input by its std.”,将输入的每个样本除以其自身的标准差。这个月featurewise的处理不同,featurewise是从整个数据集的分布去考虑的,而samplewise只是针对自身图片,效果如图3:
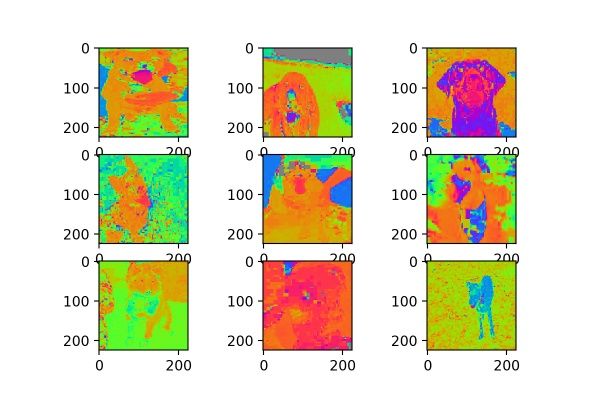
图3
看来针对自身数据分布的处理在猫狗大战数据集上没有什么意义,或许在mnist这类灰度图上有用?读者可以试试。
3. zca_whtening
datagen = image.ImageDataGenerator(zca_whitening=True)
zca白化的作用是针对图片进行PCA降维操作,减少图片的冗余信息,保留最重要的特征,细节可参看:Whitening transformation--维基百科(https://en.wikipedia.org/wiki/Whitening_transformation),Whitening--斯坦福(http://ufldl.stanford.edu/wiki/index.php/Whitening)。
很抱歉的是,本人使用keras的官方演示代码(https://keras.io/preprocessing/image/),并没有复现出zca_whitening的效果,当我的图片resize成224×224时,代码报内存错误,应该是在计算SVD的过程中数值太大。后来resize成28×28,就没有内存错误了,但是代码运行了一晚上都不结束,因此使用猫狗大战图片无法复现效果,这里转发另外一个博客使用mnist复现出的结果,如下图4。针对mnist的其它DataAugmentation结果可以看这个博客:Image Augmentation for Deep Learning With Keras(https://machinelearningmastery.com/image-augmentation-deep-learning-keras/),有修改意见的朋友欢迎留言。

图4
4. rotation range
datagen = image.ImageDataGenerator(rotation_range=30)
rotation range的作用是用户指定旋转角度范围,其参数只需指定一个整数即可,但并不是固定以这个角度进行旋转,而是在 [0, 指定角度] 范围内进行随机角度旋转。效果如图5:

图5
5. width_shift_range & height_shift_range
datagen = image.ImageDataGenerator(width_shift_range=0.5,height_shift_range=0.5)
width_shift_range & height_shift_range 分别是水平位置评议和上下位置平移,其参数可以是[0, 1]的浮点数,也可以大于1,其最大平移距离为图片长或宽的尺寸乘以参数,同样平移距离并不固定为最大平移距离,平移距离在 [0, 最大平移距离] 区间内。效果如图6:

图6
平移图片的时候一般会出现超出原图范围的区域,这部分区域会根据fill_mode的参数来补全,具体参数看下文。当参数设置过大时,会出现图7的情况,因此尽量不要设置太大的数值。

图7
6. shear_range
datagen = image.ImageDataGenerator(shear_range=0.5)
shear_range就是错切变换,效果就是让所有点的x坐标(或者y坐标)保持不变,而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比。
如图8所示,一个黑色矩形图案变换为蓝色平行四边形图案。狗狗图片变换效果如图9所示。
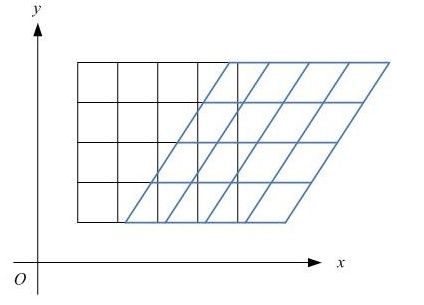
图8
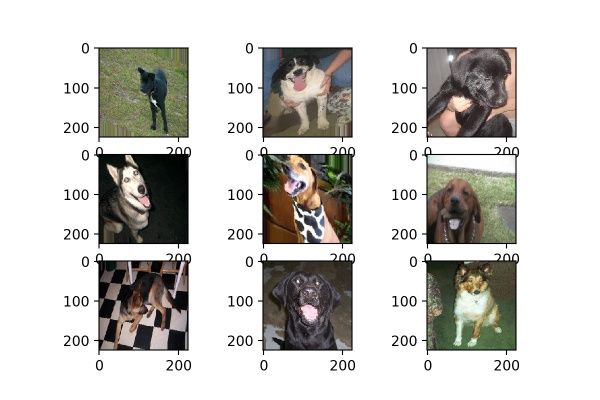
图9
7. zoom_range
datagen = image.ImageDataGenerator(zoom_range=0.5)
zoom_range参数可以让图片在长或宽的方向进行放大,可以理解为某方向的resize,因此这个参数可以是一个数或者是一个list。当给出一个数时,图片同时在长宽两个方向进行同等程度的放缩操作;当给出一个list时,则代表[width_zoom_range, height_zoom_range],即分别对长宽进行不同程度的放缩。而参数大于0小于1时,执行的是放大操作,当参数大于1时,执行的是缩小操作。
参数大于0小于1时,效果如图10:

图10
参数等于4时,效果如图11:

图11
8. channel_shift_range
datagen = image.ImageDataGenerator(channel_shift_range=10)
channel_shift_range可以理解成改变图片的颜色,通过对颜色通道的数值偏移,改变图片的整体的颜色,这意味着是“整张图”呈现某一种颜色,像是加了一块有色玻璃在图片前面一样,因此它并不能单独改变图片某一元素的颜色,如黑色小狗不能变成白色小狗。当数值为10时,效果如图12;当数值为100时,效果如图13,可见当数值越大时,颜色变深的效果越强。

图12

图13
9. horizontal_flip & vertical_flip
datagen = image.ImageDataGenerator(horizontal_flip=True)
horizontal_flip的作用是随机对图片执行水平翻转操作,意味着不一定对所有图片都会执行水平翻转,每次生成均是随机选取图片进行翻转。效果如图14。
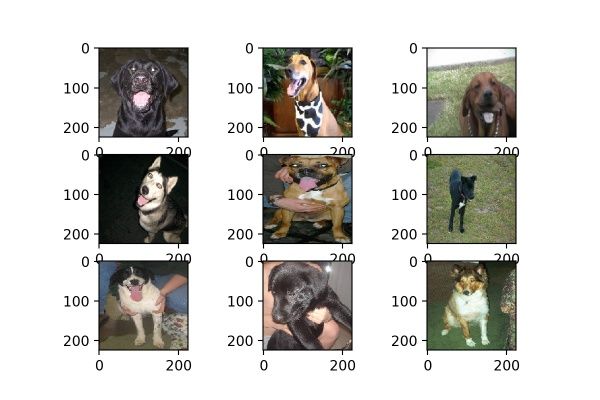
图14
datagen = image.ImageDataGenerator(vertical_flip=True)
vertical_flip是作用是对图片执行上下翻转操作,和horizontal_flip一样,每次生成均是随机选取图片进行翻转,效果如图15。
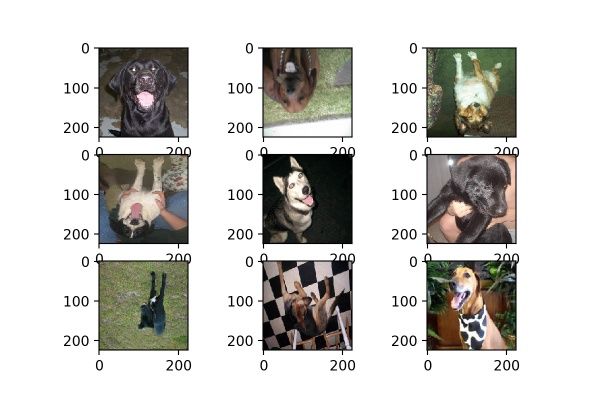
图15
当然了,在猫狗大战数据集当中不适合使用vertical_flip,因为一般没有倒过来的动物。
10. rescale
datagen = image.ImageDataGenerator(rescale= 1/255, width_shift_range=0.1)
rescale的作用是对图片的每个像素值均乘上这个放缩因子,这个操作在所有其它变换操作之前执行,在一些模型当中,直接输入原图的像素值可能会落入激活函数的“死亡区”,因此设置放缩因子为1/255,把像素值放缩到0和1之间有利于模型的收敛,避免神经元“死亡”。
图片经过rescale之后,保存到本地的图片用肉眼看是没有任何区别的,如果我们在内存中直接打印图片的数值,可以看到以下结果:
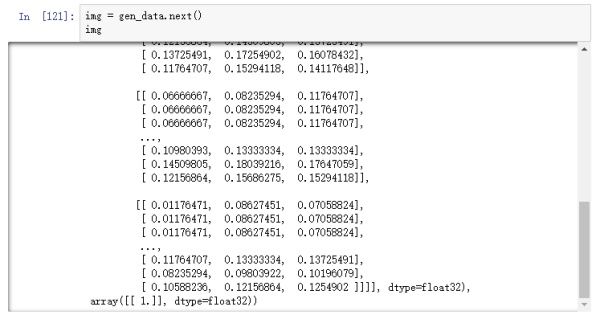
图16
可以从图16看到,图片像素值都被缩小到0和1之间,但如果打开保存在本地的图片,其数值依然不变,如图17。
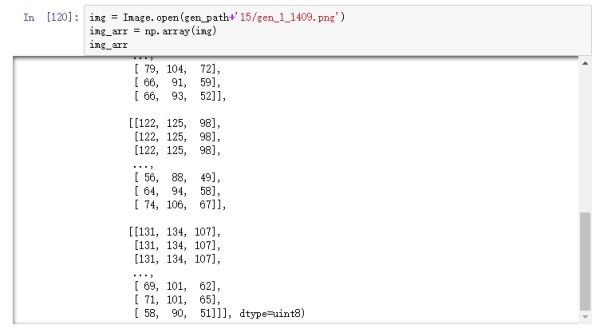
图17
应该是在保存到本地的时候,keras把图像像素值恢复为原来的尺度了,在内存中查看则不会。
11. fill_mode
datagen = image.ImageDataGenerator(fill_mode='wrap', zoom_range=[4, 4])
fill_mode为填充模式,如前面提到,当对图片进行平移、放缩、错切等操作时,图片中会出现一些缺失的地方,那这些缺失的地方该用什么方式补全呢?就由fill_mode中的参数确定,包括:“constant”、“nearest”(默认)、“reflect”和“wrap”。这四种填充方式的效果对比如图18所示,从左到右,从上到下分别为:“reflect”、“wrap”、“nearest”、“constant”。
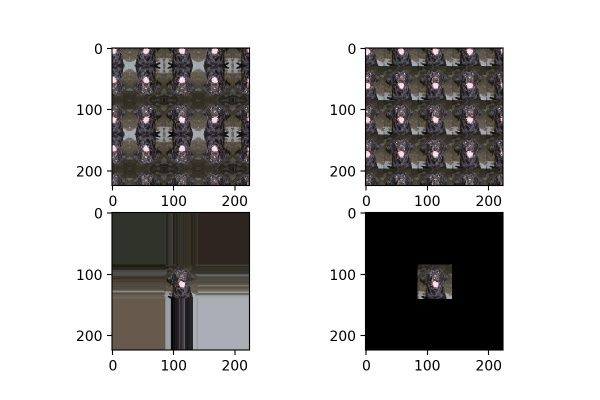
图18
当设置为“constant”时,还有一个可选参数,cval,代表使用某个固定数值的颜色来进行填充。图19为cval=100时的效果,可以与图18右下角的无cval参数的图对比。

图19
自己动手来测试?
这里给出一段小小的代码,作为进行这些参数调试时的代码,你也可以使用jupyter notebook来试验这些参数,把图片结果打印到你的网页上。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
from keras.preprocessing import image
import glob
# 设置生成器参数
datagen = image.ImageDataGenerator(fill_mode='wrap', zoom_range=[4, 4])
gen_data = datagen.flow_from_directory(PATH,
batch_size=1,
shuffle=False,
save_to_dir=SAVE_PATH,
save_prefix='gen',
target_size=(224, 224))
# 生成9张图
for i in range(9):
gen_data.next()
# 找到本地生成图,把9张图打印到同一张figure上
name_list = glob.glob(gen_path+'16/*')
fig = plt.figure()
for i in range(9):
img = Image.open(name_list[i])
sub_img = fig.add_subplot(331 + i)
sub_img.imshow(img)
plt.show()
结语
面对小数据集时,使用DataAugmentation扩充你的数据集就变得非常重要,但在使用DataAugmentation之前,先要了解你的数据集需不需要这类图片,如猫狗大战数据集不需要上下翻转的图片,以及思考一下变换的程度是不是合理的,例如把目标水平偏移到图像外面就是不合理的。多试几次效果,再最终确定使用哪些参数。上面所有内容已经公布在我的github上面,附上了实验时的jupyter notebook文件,大家可以玩一玩,have fun!
原文地址
https://zhuanlan.zhihu.com/p/30197320
AI科技大本营目前招聘资深AI采编。AI时代,和我们一起做最贴近AI的媒体!详细职位要求和简历投递方式请见☟☟☟(向下滑动详情)。
要求:
1.熟悉AI领域,对大公司、AI大牛的动态有极强敏感性,且有深度剖析的楞劲儿。
2.英语能力六级以上,看得懂文章,做得了编译,听得懂外文,做得了采访。
3.对AI相关的技术有一定的理解,能追踪最新的技术热点。
4.写稿、编译速度快,快速成稿能力非常重要。
5.语言能力强,行文流畅,写作风格不僵化不生硬。
6.相关媒体经验2年以上。
7.有过重磅深度稿件者优先。
8.对自己极高的要求,工作有极大热情,对成长有极强的动力。
9.时刻保持谦虚,能随时调整状态,跟团队目标紧密配合。
有意者,请将简历投至puge@ai100.ai,标题注明:姓名+手机号+AI采编。有疑问请加微信greta1314。

☞点击阅读原文,查看详细课程信息。

