
热门标签
热门文章
- 1AndroidStudio无法新建Java工程解决办法_android studio无法创建java
- 2NLP进化史系列之意图识别_nlp 意图识别
- 3【鸿蒙】HarmonyOS认证学习资料整理_一次开发多端部署的三个层次有哪些
- 4PostgreSQL - 如何杀死被锁死的进程_pg怎么杀进程
- 5#今日论文推荐#AAAI 2022 | 车辆重识别全新方向,解决恶劣天气下的车辆重识别,有效提升真实世界可行性,训练代码以及预训练模型皆以开源_车辆重识别全新方向!解决恶劣天气下的车辆重识别!
- 6【报告分享】“轻地图”方案之下,主机厂与图商的关系可能会更加紧密
- 7【三维语义分割】PointNet详解(一)_pointnet 语义分割
- 8用wifi连接adb_termux使用adb
- 9【C++】数据结构与算法_c++数据结构与算法
- 10【安全】LNMP环境搭建&&生成Nginx的ssl证书
当前位置: article > 正文
经典卷积神经网络Python,TensorFlow全代码实现_卷积神经网络python代码
作者:AllinToyou | 2024-03-18 08:27:45
赞
踩
卷积神经网络python代码
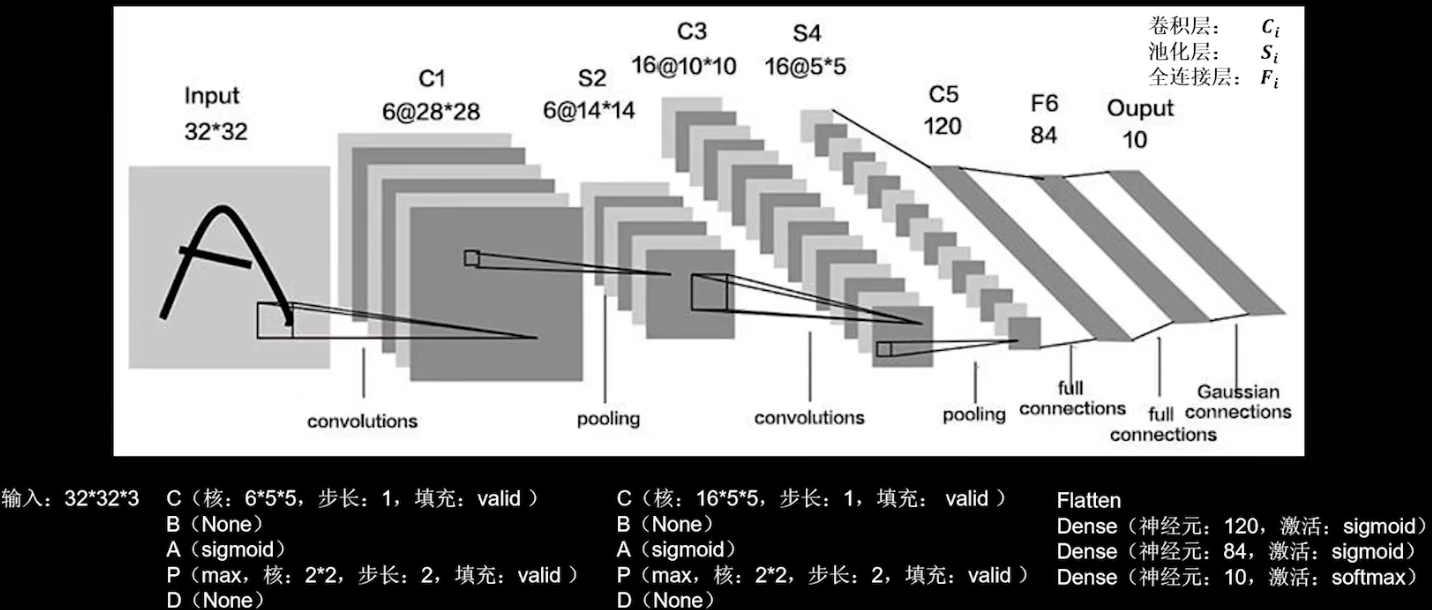
LeNet
class LeNet5(Model): def __init__(self): super(LeNet5, self).__init__() self.c1 = Conv2D(filters=6, kernel_size=(5, 5), activation='sigmoid') self.p1 = MaxPool2D(pool_size=(2, 2), strides=2) self.c2 = Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid') self.p2 = MaxPool2D(pool_size=(2, 2), strides=2) self.flatten = Flatten() self.f1 = Dense(120, activation='sigmoid') self.f2 = Dense(84, activation='sigmoid') self.f3 = Dense(10, activation='softmax') def call(self, x): x = self.c1(x) x = self.p1(x) x = self.c2(x) x = self.p2(x) x = self.flatten(x) x = self.f1(x) x = self.f2(x) y = self.f3(x) return y #model = LeNet5() #model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy']) #model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) #model.summary()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
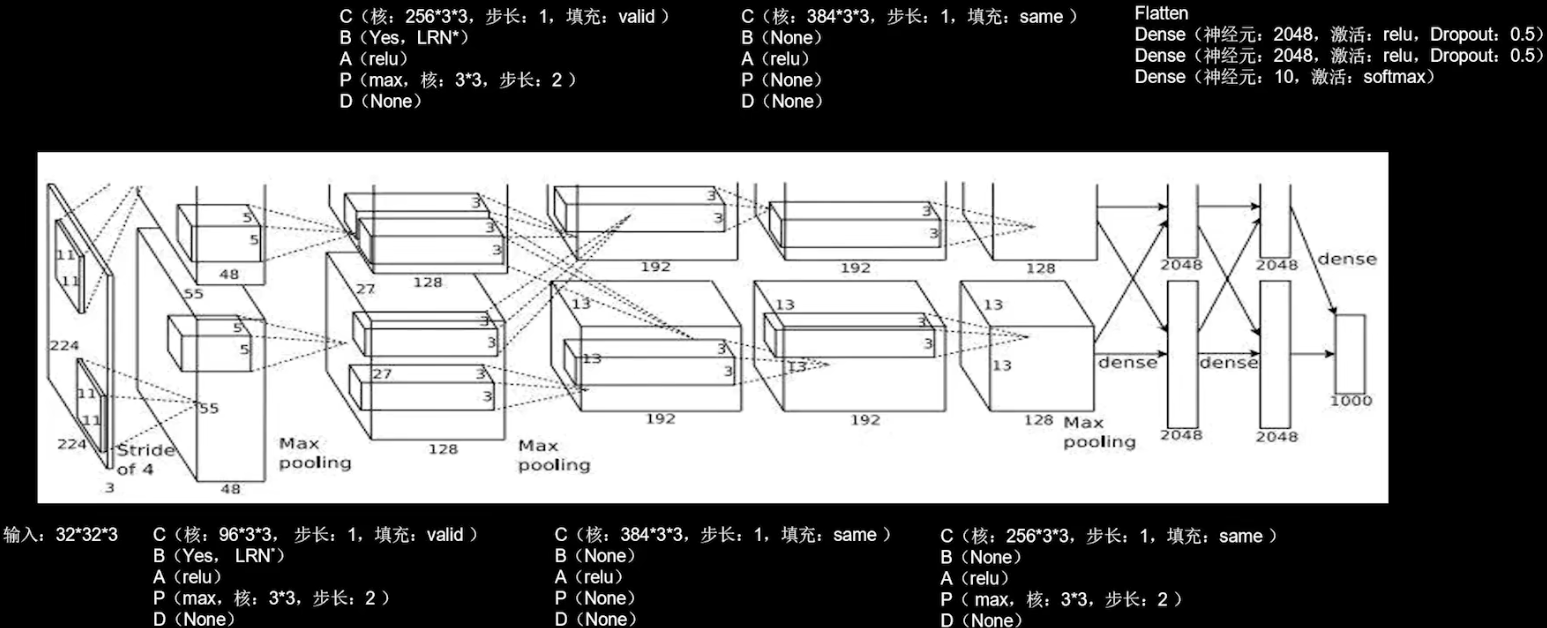
AlexNet
class AlexNet8(Model): def __init__(self): super(AlexNet8, self).__init__() self.c1 = Conv2D(filters=96, kernel_size=(3, 3)) self.b1 = BatchNormalization() self.a1 = Activation('relu') self.p1 = MaxPool2D(pool_size=(3, 3), strides=2) self.c2 = Conv2D(filters=256, kernel_size=(3, 3)) self.b2 = BatchNormalization() self.a2 = Activation('relu') self.p2 = MaxPool2D(pool_size=(3, 3), strides=2) self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same', activation='relu') self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu') self.p3 = MaxPool2D(pool_size=(3, 3), strides=2) self.flatten = Flatten() self.f1 = Dense(2048, activation='relu') self.d1 = Dropout(0.5) self.f2 = Dense(2048, activation='relu') self.d2 = Dropout(0.5) self.f3 = Dense(10, activation='softmax') def call(self, x): x = self.c1(x) x = self.b1(x) x = self.a1(x) x = self.p1(x) x = self.c2(x) x = self.b2(x) x = self.a2(x) x = self.p2(x) x = self.c3(x) x = self.c4(x) x = self.c5(x) x = self.p3(x) x = self.flatten(x) x = self.f1(x) x = self.d1(x) x = self.f2(x) x = self.d2(x) y = self.f3(x) return y #model = AlexNet8() #model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy']) #model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) #model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
VGGNet
class VGG16(Model): def __init__(self): super(VGG16, self).__init__() self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same') # 卷积层1 self.b1 = BatchNormalization() # BN层1 self.a1 = Activation('relu') # 激活层1 self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', ) self.b2 = BatchNormalization() # BN层1 self.a2 = Activation('relu') # 激活层1 self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d1 = Dropout(0.2) # dropout层 self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same') self.b3 = BatchNormalization() # BN层1 self.a3 = Activation('relu') # 激活层1 self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same') self.b4 = BatchNormalization() # BN层1 self.a4 = Activation('relu') # 激活层1 self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d2 = Dropout(0.2) # dropout层 self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b5 = BatchNormalization() # BN层1 self.a5 = Activation('relu') # 激活层1 self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b6 = BatchNormalization() # BN层1 self.a6 = Activation('relu') # 激活层1 self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same') self.b7 = BatchNormalization() self.a7 = Activation('relu') self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d3 = Dropout(0.2) self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b8 = BatchNormalization() # BN层1 self.a8 = Activation('relu') # 激活层1 self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b9 = BatchNormalization() # BN层1 self.a9 = Activation('relu') # 激活层1 self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b10 = BatchNormalization() self.a10 = Activation('relu') self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d4 = Dropout(0.2) self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b11 = BatchNormalization() # BN层1 self.a11 = Activation('relu') # 激活层1 self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b12 = BatchNormalization() # BN层1 self.a12 = Activation('relu') # 激活层1 self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same') self.b13 = BatchNormalization() self.a13 = Activation('relu') self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') self.d5 = Dropout(0.2) self.flatten = Flatten() self.f1 = Dense(512, activation='relu') self.d6 = Dropout(0.2) self.f2 = Dense(512, activation='relu') self.d7 = Dropout(0.2) self.f3 = Dense(10, activation='softmax') def call(self, x): x = self.c1(x) x = self.b1(x) x = self.a1(x) x = self.c2(x) x = self.b2(x) x = self.a2(x) x = self.p1(x) x = self.d1(x) x = self.c3(x) x = self.b3(x) x = self.a3(x) x = self.c4(x) x = self.b4(x) x = self.a4(x) x = self.p2(x) x = self.d2(x) x = self.c5(x) x = self.b5(x) x = self.a5(x) x = self.c6(x) x = self.b6(x) x = self.a6(x) x = self.c7(x) x = self.b7(x) x = self.a7(x) x = self.p3(x) x = self.d3(x) x = self.c8(x) x = self.b8(x) x = self.a8(x) x = self.c9(x) x = self.b9(x) x = self.a9(x) x = self.c10(x) x = self.b10(x) x = self.a10(x) x = self.p4(x) x = self.d4(x) x = self.c11(x) x = self.b11(x) x = self.a11(x) x = self.c12(x) x = self.b12(x) x = self.a12(x) x = self.c13(x) x = self.b13(x) x = self.a13(x) x = self.p5(x) x = self.d5(x) x = self.flatten(x) x = self.f1(x) x = self.d6(x) x = self.f2(x) x = self.d7(x) y = self.f3(x) return y #model = VGG16() #model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy']) #model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) #model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
InceptionNet (GoogleNet)
class ConvBNRelu(Model): def __init__(self, ch, kernelsz=3, strides=1, padding='same'): super(ConvBNRelu, self).__init__() self.model = tf.keras.models.Sequential([ Conv2D(ch, kernelsz, strides=strides, padding=padding), BatchNormalization(), Activation('relu') ]) def call(self, x): x = self.model(x, training=False) #在training=False时,BN通过整个训练集计算均值、方差去做批归一化,training=True时,通过当前batch的均值、方差去做批归一化。推理时 training=False效果好 return x class InceptionBlk(Model): def __init__(self, ch, strides=1): super(InceptionBlk, self).__init__() self.ch = ch self.strides = strides self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1) self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides) self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1) self.p4_1 = MaxPool2D(3, strides=1, padding='same') self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides) def call(self, x): x1 = self.c1(x) x2_1 = self.c2_1(x) x2_2 = self.c2_2(x2_1) x3_1 = self.c3_1(x) x3_2 = self.c3_2(x3_1) x4_1 = self.p4_1(x) x4_2 = self.c4_2(x4_1) # concat along axis=channel x = tf.concat([x1, x2_2, x3_2, x4_2], axis=3) return x class Inception10(Model): def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs): super(Inception10, self).__init__(**kwargs) self.in_channels = init_ch self.out_channels = init_ch self.num_blocks = num_blocks self.init_ch = init_ch self.c1 = ConvBNRelu(init_ch) self.blocks = tf.keras.models.Sequential() for block_id in range(num_blocks): for layer_id in range(2): if layer_id == 0: block = InceptionBlk(self.out_channels, strides=2) else: block = InceptionBlk(self.out_channels, strides=1) self.blocks.add(block) # enlarger out_channels per block self.out_channels *= 2 self.p1 = GlobalAveragePooling2D() self.f1 = Dense(num_classes, activation='softmax') def call(self, x): x = self.c1(x) x = self.blocks(x) x = self.p1(x) y = self.f1(x) return y #model = Inception10(num_blocks=2, num_classes=10) #model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy']) #model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) #model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
ResNet
class ResnetBlock(Model): def __init__(self, filters, strides=1, residual_path=False): super(ResnetBlock, self).__init__() self.filters = filters self.strides = strides self.residual_path = residual_path self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False) self.b1 = BatchNormalization() self.a1 = Activation('relu') self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False) self.b2 = BatchNormalization() # residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加 if residual_path: self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False) self.down_b1 = BatchNormalization() self.a2 = Activation('relu') def call(self, inputs): residual = inputs # residual等于输入值本身,即residual=x # 将输入通过卷积、BN层、激活层,计算F(x) x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.c2(x) y = self.b2(x) if self.residual_path: residual = self.down_c1(inputs) residual = self.down_b1(residual) out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数 return out class ResNet18(Model): def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层 super(ResNet18, self).__init__() self.num_blocks = len(block_list) # 共有几个block self.block_list = block_list self.out_filters = initial_filters self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False) self.b1 = BatchNormalization() self.a1 = Activation('relu') self.blocks = tf.keras.models.Sequential() # 构建ResNet网络结构 for block_id in range(len(block_list)): # 第几个resnet block for layer_id in range(block_list[block_id]): # 第几个卷积层 if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样 block = ResnetBlock(self.out_filters, strides=2, residual_path=True) else: block = ResnetBlock(self.out_filters, residual_path=False) self.blocks.add(block) # 将构建好的block加入resnet self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍 self.p1 = tf.keras.layers.GlobalAveragePooling2D() self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2()) def call(self, inputs): x = self.c1(inputs) x = self.b1(x) x = self.a1(x) x = self.blocks(x) x = self.p1(x) y = self.f1(x) return y #model = ResNet18([2, 2, 2, 2]) #model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),metrics=['sparse_categorical_accuracy']) #model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) #model.summary()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
总结
LeNet (1998)
卷积网络开篇之作,通过空间卷积核共享,减少了待训练的参数。
AlexNet (2012)
使用了relu激活函数,提升了训练速度;使用了Dropout,缓解了过拟合。
VGGNet (2014)
使用小尺寸卷积核减少待训练参数和计算量,它的网络结构非常规整,适合硬件并行加速。

InceptionNet (2014)
在同一层中使用了不同尺寸的卷积核,提升了模型的感知力;使用了批标准化(batch normalization),缓解了梯度消失。


ResNet (2015)
通过层间残差跳连,引入了前方信息,缓解了模型退化,使神经网络层数加深成为可能。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/261687
推荐阅读
相关标签

