
- 1【通俗易懂】vue实现tagsview标签导航栏切换菜单功能【详细注释,都能看的懂】
- 2微信小程序 ---- 通过 URLScheme 或 URLLink 从短信、邮件、微信外网页等场景打开小程序_微信小程序url link
- 3vue回车登录,登录完销毁回车事件_vue3销毁事件
- 4微信公众平台开发简介
- 5HarmonyOS鸿蒙基于Java开发: 传感器开发
- 6嵌入式学习笔记——STM32硬件基础知识_stm32主频
- 7【编译器】VSCode配置Go语言开发环境_vscode配置go开发环境
- 8数据科学家路线图_成为数据科学家的路线图
- 9MySQL MHA故障切换
- 10带约束条件:NSGA-Ⅱ多目标约束优化(Matlab代码+中文注解)_nsga-ii matlab
从入门到精通的Android进阶学习笔记整理,实战篇_android 学习资料
赞
踩
一、认识鸿蒙
鸿蒙 微内核是基于微内核的全场景分布式OS,可按需扩展,实现更广泛的系统安全,主要用于物联网,特点是低时延,甚至可到毫秒级乃至亚毫秒级。
鸿蒙OS实现模块化耦合,对应不同设备可弹性部署,鸿蒙OS有三层架构,第一层是内核,第二层是基础服务,第三层是程序框架 。可用于手机、平板、PC、汽车等各种不同的设备上。还可以随时用在手机上,但暂时华为手机端依然优先使用安卓、华为电脑端依然优先使用windows和Linux。
华为对于鸿蒙系统的定位完全不同于安卓系统,**它不仅是一个手机或某一设备的单一系统,而是一个可将所有设备串联在一起的通用性系统,**就是多个不同设备比如手机、智慧屏、平板电脑、车载电脑等等,都可使用鸿蒙系统。
二、显示系统基础知识
在一个典型的显示系统中,一般包括CPU、GPU、Display三个部分, CPU负责计算帧数据,把计算好的数据交给GPU,GPU会对图形数据进行渲染,渲染好后放到buffer(图像缓冲区)里存起来,然后Display(屏幕或显示器)负责把buffer里的数据呈现到屏幕上。如下图:
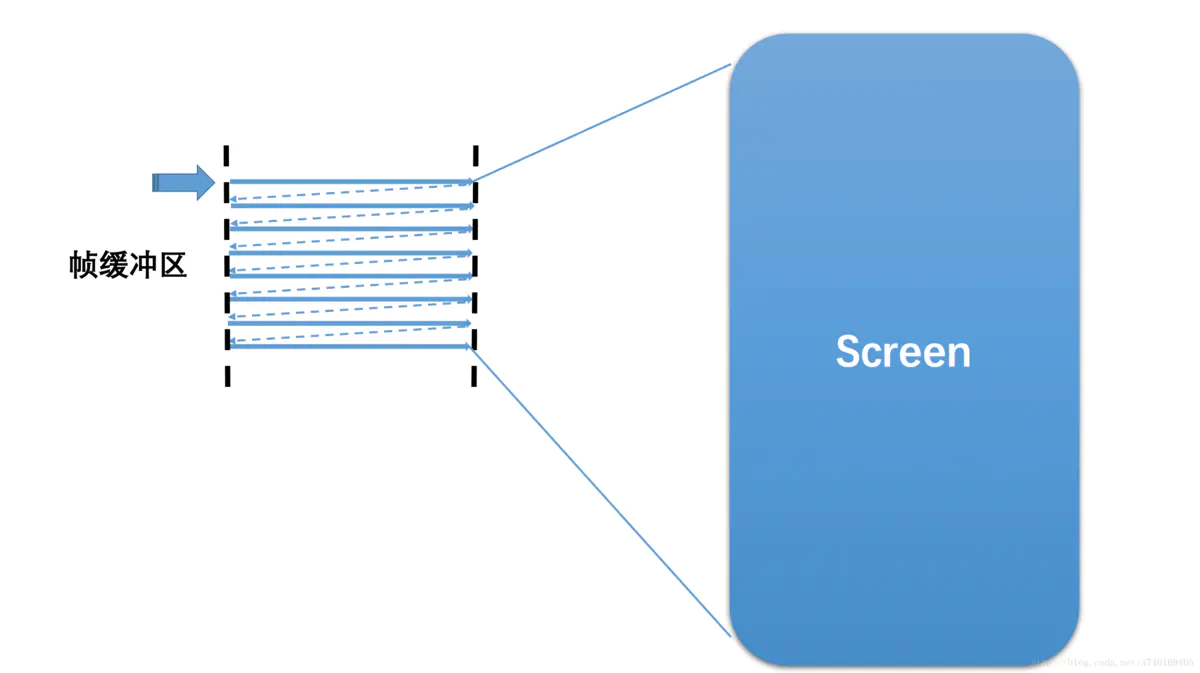
2.1 基础概念
-
屏幕刷新频率 一秒内屏幕刷新的次数(一秒内显示了多少帧的图像),单位 Hz(赫兹),如常见的 60 Hz。刷新频率取决于硬件的固定参数(不会变的)。
-
逐行扫描 显示器并不是一次性将画面显示到屏幕上,而是从左到右边,从上到下逐行扫描,顺序显示整屏的一个个像素点,不过这一过程快到人眼无法察觉到变化。以 60 Hz 刷新率的屏幕为例,这一过程即 1000 / 60 ≈ 16ms。
-
帧率 (Frame Rate) 表示 GPU 在一秒内绘制操作的帧数,单位 fps。例如在电影界采用 24 帧的速度足够使画面运行的非常流畅。而 Android 系统则采用更加流程的 60 fps,即每秒钟GPU最多绘制 60 帧画面。帧率是动态变化的,例如当画面静止时,GPU 是没有绘制操作的,屏幕刷新的还是buffer中的数据,即GPU最后操作的帧数据。
-
画面撕裂(tearing) 一个屏幕内的数据来自2个不同的帧,画面会出现撕裂感,如下图

2.2 双缓存
2.2.1 画面撕裂 原因
屏幕刷新频是固定的,比如每16.6ms从buffer取数据显示完一帧,理想情况下帧率和刷新频率保持一致,即每绘制完成一帧,显示器显示一帧。但是CPU/GPU写数据是不可控的,所以会出现buffer里有些数据根本没显示出来就被重写了,即buffer里的数据可能是来自不同的帧的, 当屏幕刷新时,此时它并不知道buffer的状态,因此从buffer抓取的帧并不是完整的一帧画面,即出现画面撕裂。
简单说就是Display在显示的过程中,buffer内数据被CPU/GPU修改,导致画面撕裂。
2.2.2 双缓存
那咋解决画面撕裂呢? 答案是使用 双缓存。
由于图像绘制和屏幕读取 使用的是同个buffer,所以屏幕刷新时可能读取到的是不完整的一帧画面。
双缓存,让绘制和显示器拥有各自的buffer:GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Frame Buffer,当屏幕刷新时,Frame Buffer 并不会发生变化,当Back buffer准备就绪后,它们才进行交换。如下图:

2.2.3 VSync
问题又来了:什么时候进行两个buffer的交换呢?
假如是 Back buffer准备完成一帧数据以后就进行,那么如果此时屏幕还没有完整显示上一帧内容的话,肯定是会出问题的。看来只能是等到屏幕处理完一帧数据后,才可以执行这一操作了。
当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时有一段时间空隙,称为VerticalBlanking Interval(VBI)。那,这个时间点就是我们进行缓冲区交换的最佳时间。因为此时屏幕没有在刷新,也就避免了交换过程中出现 screen tearing的状况。
VSync(垂直同步)是VerticalSynchronization的简写,它利用VBI时期出现的vertical sync pulse(垂直同步脉冲)来保证双缓冲在最佳时间点才进行交换。另外,交换是指各自的内存地址,可以认为该操作是瞬间完成。
所以说V-sync这个概念并不是Google首创的,它在早年的PC机领域就已经出现了。
三、Android屏幕刷新机制
3.1 Android4.1之前的问题
具体到Android中,在Android4.1之前,屏幕刷新也遵循 上面介绍的 双缓存+VSync 机制。如下图:

以时间的顺序来看下将会发生的过程:
- Display显示第0帧数据,此时CPU和GPU渲染第1帧画面,且在Display显示下一帧前完成
- 因为渲染及时,Display在第0帧显示完成后,也就是第1个VSync后,缓存进行交换,然后正常显示第1帧
- 接着第2帧开始处理,是直到第2个VSync快来前才开始处理的。
- 第2个VSync来时,由于第2帧数据还没有准备就绪,缓存没有交换,显示的还是第1帧。这种情况被Android开发组命名为“Jank”,即发生了丢帧。
- 当第2帧数据准备完成后,它并不会马上被显示,而是要等待下一个VSync 进行缓存交换再显示。
所以总的来说,就是屏幕平白无故地多显示了一次第1帧。
原因是 第2帧的CPU/GPU计算 没能在VSync信号到来前完成 。
我们知道,双缓存的交换 是在Vsyn到来时进行,交换后屏幕会取Frame buffer内的新数据,而实际 此时的Back buffer 就可以供GPU准备下一帧数据了。 如果 Vsyn到来时 CPU/GPU就开始操作的话,是有完整的16.6ms的,这样应该会基本避免jank的出现了(除非CPU/GPU计算超过了16.6ms)。 那如何让 CPU/GPU计算在 Vsyn到来时进行呢?
3.2 drawing with VSync
为了优化显示性能,Google在Android 4.1系统中对Android Display系统进行了重构,实现了Project Butter(黄油工程):系统在收到VSync pulse后,将马上开始下一帧的渲染。即一旦收到VSync通知(16ms触发一次),CPU和GPU 才立刻开始计算然后把数据写入buffer。如下图:

CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
一句话总结,VSync同步使得CPU/GPU充分利用了16.6ms时间,减少jank。
问题又来了,如果界面比较复杂,CPU/GPU的处理时间较长 超过了16.6ms呢?如下图:

- 在第二个时间段内,但却因 GPU 还在处理 B 帧,缓存没能交换,导致 A 帧被重复显示。
- 而B完成后,又因为缺乏VSync pulse信号,它只能等待下一个signal的来临。于是在这一过程中,有一大段时间是被浪费的。
- 当下一个VSync出现时,CPU/GPU马上执行操作(A帧),且缓存交换,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的“Jank”。
为什么 CPU 不能在第二个 16ms 处理绘制工作呢?
原因是只有两个 buffer,Back buffer正在被GPU用来处理B帧的数据, Frame buffer的内容用于Display的显示,这样两个buffer都被占用,CPU 则无法准备下一帧的数据。 那么,如果再提供一个buffer,CPU、GPU 和显示设备都能使用各自的buffer工作,互不影响。
3.3 三缓存
三缓存就是在双缓冲机制基础上增加了一个 Graphic Buffer 缓冲区,这样可以最大限度的利用空闲时间,带来的坏处是多使用的一个 Graphic Buffer 所占用的内存。

-
第一个Jank,是不可避免的。但是在第二个 16ms 时间段,CPU/GPU 使用 第三个 Buffer 完成C帧的计算,虽然还是会多显示一次 A 帧,但后续显示就比较顺畅了,有效避免 Jank 的进一步加剧。
-
注意在第3段中,A帧的计算已完成,但是在第4个vsync来的时候才显示,如果是双缓冲,那在第三个vynsc就可以显示了。
三缓冲有效利用了等待vysnc的时间,减少了jank,但是带来了延迟。 所以,是不是 Buffer 越多越好呢?这个是否定的,Buffer 正常还是两个,当出现 Jank 后三个足以。
以上就是Android屏幕刷新的原理了。
总结
Android架构学习进阶是一条漫长而艰苦的道路,不能靠一时激情,更不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!
上面分享的字节跳动公司2020年的面试真题解析大全,笔者还把一线互联网企业主流面试技术要点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。详情可以点击我的【Github】
如果你熟练掌握【腾讯文档】中列出的知识点,相信将会大大增加你通过前两轮技术面试的几率!这些内容都供大家参考,互相学习。
就先写到这,码字不易,写的很片面不好之处敬请指出,如果觉得有参考价值的朋友也可以关注一下我
①「Android面试真题解析大全」PDF完整高清版+②「Android面试知识体系」学习思维导图压缩包——————可以在我的【Github】阅读下载,最后觉得有帮助、有需要的朋友可以点个赞

[外链图片转存中…(img-2CS4yO2s-1621920682055)]
[外链图片转存中…(img-Xf2xJEBd-1621920682056)]
[外链图片转存中…(img-srojaqEg-1621920682057)]

