
- 1RISC-V单周期处理器设计(指令和控制器)(二)_基于riscv指令集的单周期处理器
- 2OMACP功能说明以及自己做的一个模拟发送OMACP消息的功能类
- 3Oracle的分页、排序、效率问题_oracle rownumber over效率问题
- 4脚手架搭建微信小程序项目_cli3构建微信小程序
- 5【robots.txt】设置网站不允许被搜索引擎抓取的代码_禁止蜘蛛抓取的代码
- 6uniapp 标签打印 笔记_uniapp打印标签
- 7maven中profile的使用详解_maven profile
- 8notebook显示pyecharts画地图_".add(\"商家a\", [list(z) for z in zip(faker.provinc
- 9VUE3 + TS 使用 Axios(copy可直接使用)_ts对axios响应结果进行处理
- 10webvtt_使用WebVTT章节创建交互式HTML5视频
基于概率的矩阵分解原理详解(PMF)_概率矩阵分解模型使用公式
赞
踩
上一篇博客讲到了推荐系统中常用的矩阵分解方法,
若用户
同理:项目V的特征矩阵满足如下等式:
其中
假设真实值
那么评分矩阵
这里
为什么要转换为这种形式呢?这还要从极大似然估计(
最大似然估计:假设观察数据满足
服从参数为
仔细想想,当前样本数据已知,未知参数只有
求极大似然估计(MLE)的一般步骤是:
由总体分布导出样本的联合概率函数 (或联合密度);
把样本联合概率函数(或联合密度)中自变量看成已知常数,而把参数 看作自变量,得到似然函数L(
θ );- 求似然函数L(
θ ) 的最大值点(常常转化为求ln L(θ )的最大值点) ,即θ 的MLE; - 在最大值点的表达式中, 用样本值代入就得参数的极大似然估计值 .
似然函数:
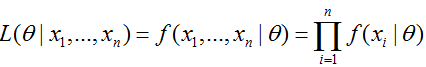
通常取对数(对数似然),以便将乘化为加:
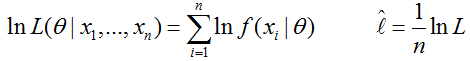
这样,待估计参数就可以表示为如下形式:
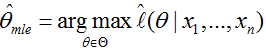
同理若待估计参数有两个,比如样本服从高斯分布,如下式,可以通过求偏导数得到估计值。
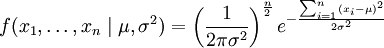
这样,PMF为何要转换为
最大后验概率:
最大后验估计,融入了要估计量的先验分布在其中,也就是说待估计量θ本身也满足某概率分布g(θ)(已知), 称为先验分布。这样根据贝叶斯理论,似然函数有如下表示:(这里f(θ|x)等价l(θ|x)是似然函数,表示已知样本数据x集合,来评估θ的值(条件概率),但后面的等式就只关乎密度函数f了)。
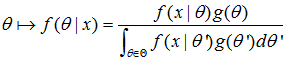
贝叶斯公式大家都懂,这里我就说说分母为啥写成这个形式。此f是关于和θ和x的联合分布密度,不是我么理解的事件ABC,同时发生等。正常来说分母应该是f(x),表示只考虑x这一影响因素,要消除θ的影响,那么我么是通过对θ积分来消除θ,分母的结果最终是等于f(x)的,分子是等于f(θ,x)的。最终,待估参数表达为:
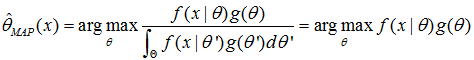
分母的积分结果得到关于f(x)的密度函数,已知的对不。这样,最大后验概率的待估参数就是在最大似然估计的结果后面多乘了个待估参数的先验分布。写到这,大家就该懂了为啥等式右边是那种形式了,在最大似然估计的基础上要添加
将
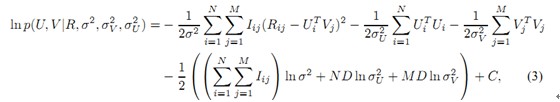
最大化后验概率U和V(最大可能性),等价于求下式的最小值:
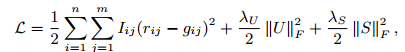
其中:
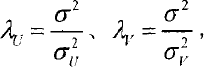
解传统矩阵分解可以采用各种优化方法,对于概率分解,由于最后求的是参数U和V的最大似然估计,因此可以用最大期望法(EM)和马尔可夫链蒙特卡罗算法(MCMC)。这里就不多说了。
PMF也有改进的地方,它没有考虑到评分过程中用户的个人信息,比如有的用户就是喜欢打低分,有的项目(电影)质量就是不高,分肯定高不了等,这样可以采用加入偏置的概率矩阵分解(贝叶斯概率矩阵分解BPMF),将在后面的博客中写出,会给出链接。
补充:联合分布f(x,y),其中x和y无必然联系,x可以理解为老师课讲得好,y理解为课开在周六,那么f表示这节课选课的人数的概率密度,联合分布的概率跟f(x)一样,也是通过积分来求,f(x)求面积,而f(x,y)是求体积。
最大似然估计和最大后验概率是参考了这两篇篇博客:
http://blog.csdn.net/upon_the_yun/article/details/8915283
http://wiki.mbalib.com/wiki/%E6%9C%80%E5%A4%A7%E4%BC%BC%E7%84%B6%E4%BC%B0%E8%AE%A1

