
- 1线上故障快速排查分析【转】_too many pid
- 2获取Activity的最外层布局_activity的布局文件最外层控件
- 3马哥架构第1周课程作业
- 4上海亚商投顾 财经早餐FM/0830
- 5两个实体相同属性快速映射_C# 数据操作系列 - 6 EF Core 配置映射关系
- 6【一文清晰】单元测试到底是什么?应该怎么做?_一张图看懂单元测试
- 7线性代数在卷积神经网络(CNN)中的体现
- 8django 实战(9): 自定义Student模型(与User模型一对一关系)_django 模型中关联user
- 9java jdbc mysql 8驱动,连接数据库 mysql serverTimezone 问题,时间少了8小时_jdbc驱动包8.x 日期格式化问题,多了一个t
- 10鸿蒙系统几年不卡,华为手机别乱选,这四款机型基本三年不卡,并且可以升级鸿蒙系统...
python 系列 07 - 基于easyocr的ocr识别_python easyocr
赞
踩
OCR,光学文字识别,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。本示例通过easyocr库来演示。easyocr是一个比较流行的库,支持超过80种语言。安装的时候注意会附带安装torch库(一个深度学习框架,大小600多M)。目前还不支持最新版的python3.11.如果你是最新版的pyton。可以对python降级或者安装另一个版本的python。切换python版本详见文末。
1 安装库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple easyocr
- 1
2 中文识别示例
首先准备一张图片如图:
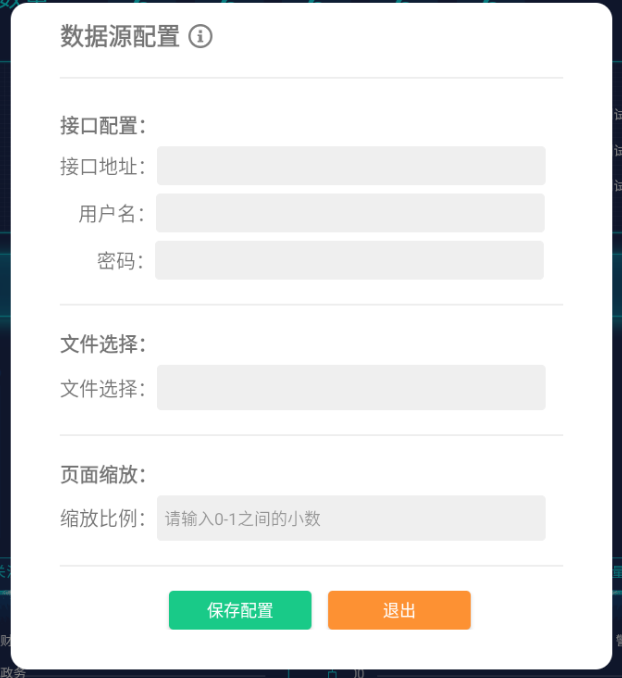
示例代码:
# 导入easyocr
import easyocr
# 创建reader对象,参数为要识别的目标语言的列表,ch_sim代表中文
# 如识别中英文混合,则参数可设置为['ch_sim','en']
reader = easyocr.Reader(['ch_sim'])
# 读取图像
result = reader.readtext('01.png')
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.1 如果出现如下提示
Downloading detection model, please wait. This may take several minutes depending upon your network connection.
Progress: |███-----------------------------------------------| 6.9% Complete
- 1
- 2
表示需要下载语言模型和检测模型,如果你的网络很慢,或者链接中断,可以手动下载这些模型,模型地址:
https://www.jaided.ai/easyocr/modelhub/
- 1
下载检测模型:CRAFT,然后下载 zh_sim_g2(中文语言) 和 english_g2(英文语言)即可,如果你有其它语言需要识别也可下载其它语言。解压后的.pth文件放入/home/user/.EasyOCR/model目录下。
2.2 如果出现如下错误并退出
[W NNPACK.cpp:64] Could not initialize NNPACK! Reason: Unsupported hardware
- 1
说明的计算机不支持NNPACK所需的指令集。你可以安装easyocr的较低的版本如1.3.2等不使用这些指令集的版本。
2.3 如果出现其它错误
查看文末错误汇总,看有没有你碰到的。
2.4 识别结果
上面的demo识别结果:
[([[55, 18], [218, 18], [218, 54], [55, 54]], '数据源配置 @', 0.6604536146884444), ([[56, 112], [152, 112], [152, 142], [56, 142]], '接口配置:', 0.9232571757257206), ([[56, 154], [148, 154], [148, 180], [56, 180]], '接口地址:', 0.9036295025243269), ([[76, 200], [148, 200], [148, 228], [76, 228]], '用户名:', 0.9765614867210388), ([[94, 248], [146, 248], [146, 274], [94, 274]], '密码:', 0.8677780360538662), ([[56, 330], [152, 330], [152, 360], [56, 360]], '文件选择:', 0.9148985481070583), ([[56, 374], [150, 374], [150, 404], [56, 404]], '文件选择:', 0.928823627061566), ([[58, 462], [152, 462], [152, 490], [58, 490]], '页面缩放:', 0.9813329106982849), ([[56, 504], [148, 504], [148, 532], [56, 532]], '缩放比例:', 0.986201483892586), ([[160, 506], [324, 506], [324, 530], [160, 530]], '请输入0-1之间的小数', 0.3022109861905718), ([[204, 598], [276, 598], [276, 622], [204, 622]], '保存配置', 0.9112837910652161), ([[378, 598], [418, 598], [418, 622], [378, 622]], '退出', 0.9667384789164919)]
- 1
识别精度还不错,当然,根据你提供的图片分辨率,分辨率越高,而且干扰元素越少,正确率越高,但识别速度略慢,可能我的环境没有GPU,只能用CPU来执行。用GPU应该会更快一些。
下面对上面的输出结果简单说明:
以上数据是一个标定区域块的数组,数据内包含多个元组,每个元组是标定的每个区域块的数据。每个元组包含三个元素,第一个元组为标定的区域的座标,第二个元素为识别出的文字,第三个元素是识别概率。
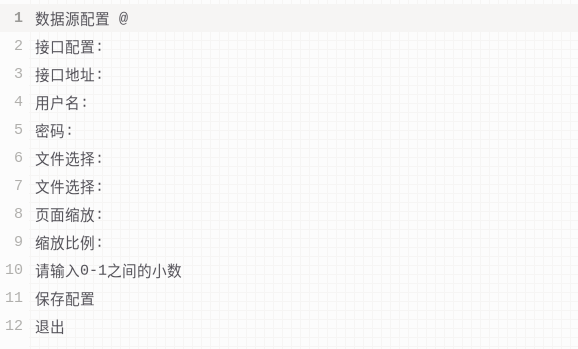
下面通过简单的循环来把所有文本提取出来并写入txt:
# 导入easyocr import easyocr # 创建reader对象,参数为要识别的目标语言的列表,ch_sim代表中文 # 如识别中英文混合,则参数可设置为['ch_sim','en'] reader = easyocr.Reader(['ch_sim']) # 读取图像 result = reader.readtext('01.png') content = '' for area in result: text = area[1] content += text + '\n' f = open('01.txt','w') f.write(content) f.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
写入结果:
3.中英文混合识别
3.1 准备图片
准备一张分辨率较低的图片:

3.2 进行识别
# 导入easyocr
import easyocr
# 创建reader对象,参数为要识别的目标语言的列表,ch_sim代表中文
# 如识别中英文混合,则参数可设置为['ch_sim','en']
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('03.jpg')
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
识别结果:
[([[254, 4], [328, 4], [328, 28], [254, 28]], '参考文献', 0.8226658701896667), ([[17, 57], [97, 57], [97, 73], [17, 73]], '[I]Lastrapes', 0.69268751703223), ([[157, 57], [275, 57], [275, 73], [157, 73]], 'Hleteroskedasticity', 0.5667352767424044), ([[305, 57], [343, 57], [343, 73], [305, 73]], 'Stock', 0.9890904862981488), ([[349, 57], [393, 57], [393, 71], [349, 71]], 'Return', 0.9465216417908011), ([[399, 57], [473, 57], [473, 71], [399, 71]], 'dnta: Volume', 0.4470853061822261), ([[479, 55], [523, 55], [523, 71], [479, 71]], 'Versus', 0.9191125950849435), ([[529, 57], [565, 57], [565, 71], [529, 71]], 'Garch', 0.9873791273496051), ([[17, 77], [65, 77], [65, 91], [17, 91]], 'Effects', 0.7349260169399585), ([[59, 73], [83, 73], [83, 93], [59, 93]], ';[]]', 0.8840106725692749), ([[93, 77], [217, 77], [217, 91], [93, 91]], 'Journal of Finance;', 0.4778455046237064), ([[221, 77], [279, 77], [279, 91], [221, 91]], '1998 (3:', 0.2858050027265414), ([[283, 77], [323, 77], [323, 91], [283, 91]], '21-24.', 0.4554373637279304), ([[17, 105], [139, 105], [139, 121], [17, 121]], '[2]nntulio N Bootio', 0.14424732812093452), ([[147, 103], [567, 103], [567, 121], [147, 121]], 'Federal Reserve Board Vonetary and Financial Varket Mnalysis Section', 0.43462905641690097), ([[23, 123], [49, 123], [49, 139], [23, 139]], '[4]。', 0.20602943003177643), ([[55, 123], [187, 123], [187, 139], [55, 139]], 'Academic Press; 2003', 0.7509114069902773), ([[201, 123], [249, 123], [249, 139], [201, 139]], '214-251', 0.5970671133900244), ([[15, 149], [171, 149], [171, 169], [15, 169]], '[3]黄达。货币银行学 [山]。', 0.12469001948068836), ([[181, 149], [305, 149], [305, 169], [181, 169]], '中围人民大学出版,', 0.3803464118912367), ([[313, 151], [349, 151], [349, 167], [313, 167]], '2000:', 0.9948236855370229), ([[353, 153], [375, 153], [375, 167], [353, 167]], '185', 0.9979106811742814), ([[15, 177], [77, 177], [77, 197], [15, 197]], '[4]张尚学', 0.9675273647448231), ([[85, 177], [285, 177], [285, 197], [85, 197]], '贷而银学 [4]。南开大学出版社。', 0.08337038842991375), ([[289, 179], [403, 179], [403, 197], [289, 197]], '2OOI 年笫一敞; 354', 0.15708182763479275), ([[15, 205], [427, 205], [427, 225], [15, 225]], '[5]大卫I弗里德曼。贷币与银行[4]。北京; 中圜计划出版社 2001: 234。', 0.18551760040425924), ([[15, 235], [77, 235], [77, 253], [15, 253]], '[6]郑迸平', 0.8119106360798195), ([[85, 233], [229, 233], [229, 253], [85, 253]], '龙玮娟。货币银行学原理', 0.2061057527270198), ([[235, 235], [263, 235], [263, 253], [235, 253]], '[w]。', 0.061789486557245255), ([[269, 237], [363, 237], [363, 253], [269, 253]], '2002 年版: 294.', 0.20901156631832898), ([[14, 258], [382, 258], [382, 285], [14, 285]], '[7]吕建藜。中圈汇率政策与贷币政笼的措配研究 [J]。符区经济', 0.00512204089347133), ([[395, 265], [495, 265], [495, 281], [395, 281]], '2008 (1): 59-61', 0.45054786903818533), ([[15, 291], [385, 291], [385, 311], [15, 311]], '[8]付俊文。赵 红。我圈窗口指导货币政策工具的理论与实践 [0', 0.031182130030847348), ([[399, 291], [511, 291], [511, 309], [399, 309]], '中央鼾经大学擘报,', 0.05041427001669892), ([[519, 293], [563, 293], [563, 309], [519, 309]], '2008 年', 0.2104904628177295), ([[23, 315], [49, 315], [49, 329], [23, 329]], '(9);', 0.4151167571544647), ([[53, 315], [89, 315], [89, 329], [53, 329]], '32-33', 0.9119664043023943), ([[16, 335], [292, 335], [292, 360], [16, 360]], '[9]曾雁。中央银行"窗口指导"机制研究 [叨', 0.08059719872422297), ([[303, 339], [387, 339], [387, 359], [303, 359]], '广西大学学报', 0.8053077108426586), ([[395, 341], [475, 341], [475, 357], [395, 357]], '2006(3)25.', 0.47657615675708886), ([[15, 367], [507, 367], [507, 387], [15, 387]], '[10]霍建军。刘 平。改进和捉盲 "窗口指导" 的建议 []。金触参考。2005{10)+115', 0.009912717726994289)]
- 1
对比会发现,多个字符识别错误。
3.3 将扫描的文本块在图片上做标记
将识别出的区块标记在图像上,以便与识别结果做对比。绘制图像库是opencv,pip库名:opencv-python。
# 导入easyocr import easyocr import cv2 reader = easyocr.Reader(['ch_sim','en'],gpu=False) result = reader.readtext('03.jpg') img = cv2.imread('03.jpg') for area in result: top_left = area[0][0] bottom_right = area[0][2] img = cv2.rectangle(img,top_left,bottom_right,(255,0,0),3) cv2.imshow('image',img) cv2.waitKey(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
标记结果:

4 一些简单的应用场景测试
4.1 对于图片验证码的识别
4.1.1 第一种,字符验证码
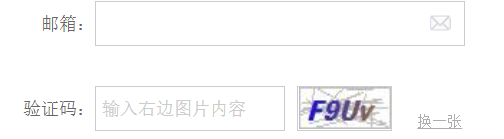
代码demo不再列出,同上,识别结果:
[([[38, 12], [88, 12], [88, 36], [38, 36]], '邮箱:', 0.67093855956966), ([[20, 96], [88, 96], [88, 120], [20, 120]], '验证码:', 0.9571285843849182), ([[98, 96], [248, 96], [248, 122], [98, 122]], '输入右边图片内容', 0.5983784957928567), ([[304, 96], [380, 96], [380, 126], [304, 126]], 'FgUV', 0.9349045753479004), ([[443, 111], [465, 111], [465, 131], [443, 131]], '张', 0.2765016087989949)]
- 1
现在这么清晰可见的验证码不多见了,即便如此,还是识别错了一个字符,带更多干扰码的验证码几乎无法识别。有兴趣可自己尝试。
4.1.2 需要计算的验证码

[([[57, 37], [191, 37], [191, 81], [57, 81]], '输入用户', 0.9178350567817688), ([[57, 159], [193, 159], [193, 201], [57, 201]], '输入密码', 0.8854490518569946), ([[57, 279], [163, 279], [163, 319], [57, 319]], '验证码', 0.9951367245352766), ([[306, 264], [410, 264], [410, 336], [306, 336]], '24', 0.9999937622721186), ([[429, 273], [471, 273], [471, 325], [429, 325]], '8', 0.9997730383920498)]
- 1
可以发现,24和8识别出来了,减号由于干扰码存在,没有识别。
总结起来,就是对于验证码的识别,没有太大作用,示例图片都是还都是比较清晰的图片,识别结果不尽如人意。这也就是为什么现在很多网站费劲心思添加各种验证码和干扰码的原因。需求场景不大,不必强求。把它用做文档识别就好了。对于复杂场景的识别,如果你有条件的话,可以对easyocr的模型进一步的训练,以达到更好的识别某种信息的结果。
5 题外话:安装多个python版本及版本更换
由于pyenv难以安装,所以利用update-alternatives来切换版本.
5.1 安装多个版本python
安装另一个版本的python.利用系统命令即可,我当前版本是3.11,安装3.10:
sudo dnf install python3.10
- 1
5.2 查看python可选项
update-alternatives --display python
- 1
5.3 如果没有可选项就新建
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.10 1
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.11 2
- 1
- 2
- 3
5.4 再次查看版本
update-alternatives --display python
- 1
输出:
python - 状态为自动。
链接当前指向 /usr/bin/python3.11
/usr/bin/python3.10 - 优先度 1
/usr/bin/python3.11 - 优先度 2
当前“最佳”版本是 /usr/bin/python3.11。
- 1
- 2
- 3
- 4
- 5
5.5 切换版本
sudo update-alternatives --config python
- 1
输出:
共有 2 个提供“python”的程序。
选项 命令
-----------------------------------------------
1 /usr/bin/python3.10
*+ 2 /usr/bin/python3.11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
选择1即可。
最后将python3.10 的pip 改名为pip3.10。这个pip文件多半在/home/user/.local/bin下面。如果不在,就whereis命令查找一下,安装easyocr的时候使用pip3.10。
pip3.10 install easyocr
- 1
6 错误汇总
AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline' (most likely due to a circular import)
- 1
降低opencv-python的版本到4.5.5.64.用于适配easyocr1.3.2.
ImportError: cannot import name 'model_urls' from 'torchvision.models.vgg' (/home/eva/.local/lib/python3.10/site-packages/torchvision/models/vgg.py)
- 1
降低torchvision的版本到0.13.用于适配easyocr1.3.2.
以上错误基本是由easyocr降级之后版本不匹配造成的。如果你的机子配置比较高,而且使用了GPU。多半不会有以上问题。如果你降级easyocr到其它版本,请查看官网对应的opencv-python版本和torchvision版本。
- query ...
赞
踩

