
- 1数据结构之单链表详解(C语言手撕)
- 2决策树剪枝python实现_决策树及其python实现
- 3Mac下编写C或C++_mac c++
- 4Android中SharedPreferences的理解_android sharepreference 创建了重复名字
- 5request.getParameter()、request.getInputStream()和request.getReader()
- 6Shell入门之二_for cls, ids in :
- 7girdview分组,统计,排序的解决方案_dev gridveiw 按字段分组后,按其他字段排序
- 8《HarmonyOS开发 – OpenHarmony开发笔记(基于小型系统)》第1章 OpenHarmony与Pegasus物联网开发套件简介_pegasus智能家居开发套件
- 9一站式在线协作开源办公软件ONLYOFFICE,协作更安全更便捷_在线office 开源
- 10临近秋招了,讲讲大家关心的问题_嵌入式秋招要刷leetcode吗
本地部署清华大模型 ChatGLM3_chatglm本地部署
赞
踩

ChatGLM 是一个开源的、支持中英双语的对话语言模型,由智谱 AI 和清华大学 KEG 实验室联合发布,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM3-6B 更是在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上增加了更多特性。
虽然,目前 ChatGLM 比 GPT 稍有逊色,但是,在部署后可以完全本地运行,完全由自己掌控!本文介绍怎么在 Linux 服务上部署 ChatGLM3 服务,并通过多种方式使用本地部署地大模型。
01 环境准备
1.1 安装 Python 环境
Linux 环境通常自带 Python,但是版本通常比较低,ChatGLM 要求 Python 版本 3.7+,所以大多数情况下需要在安装 Python 环境,但是如果你的系统已经满足这个条件,直接跳过本节。
Python 安装可以自行下载 tar 编译安装,但是为了方便安装 pytorch 和不把系统搞崩,建议直接使用 anaconda 安装 python
# 下载 conda 安装包
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
# 安装 conda 注意安装过程中指定安装路径
bash Anaconda3-2023.03-1-Linux-x86_64.sh
# 配置软连接
ln -s /[your-install-path]/anaconda3/condabin/conda /usr/bin/conda
- 1
- 2
- 3
- 4
- 5
- 6
1.2 安装 Git LFS
ChatGLM 完整的模型实现可以在 Hugging Face Hub 上获取,如果先将模型下载到本地,然后从本地加载,这样响应效率更高;但是这个预训练模型有十几个 GB 很大 ,所以从 Hugging Face Hub 下载模型需要先安装 Git LFS。
sudo yum install git -y
git --version
sudo yum install git-lfs -y
- 1
- 2
- 3
02 模型安装
2.1 下载 ChatGLM3
首先,需要从 Github 下载 ChatGLM3 仓库,然后进入仓库目录使用 pip 安装依赖,
依赖环境,官方建议 transformers 库版本为 4.30.2,torch 使用 2.0 及以上的版本,以获得最佳的推理性能。
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
# conda 创建虚拟环境
conda create -n torch python=3.10
# 激活环境 # 退出环境 conda deactivate
conda activate torch
# 下载依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 下载预训练模型
下面我们用 Git LFS 从 Hugging Face Hub 将模型下载到本地,从本地加载模型响应速度更快
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
- 1
- 2
如果从你从 HuggingFace 下载比较慢,也可以从 ModelScope 中下载(亲测,飞一般地感觉~~)
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
- 1
- 2
03 模型使用
把下载好的 THUDM/chatglm3-6b 预训练模型文件放到 ChatGLM3 仓库目录下,如果是从 ModelScope 下载的话注意目录层级,模型加载需要修改本地模型路径;
ChatGLM3 提供了三种使用方式:命令行 Demo,网页版 Demo 和 API 部署;在启动模型之前,需要找到对应启动方式的 python 源码文件 cli_demo.py,web_demo.py,openai_api.py 中修改下面这一行代码
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
- 1
修改两个地方:(1)本地模型的存放路径 THUDM/chatglm3-6b;(2)根据自己的硬件环境参考 DEPLOYMENT.md 选择模型加载方式,float() CPU 部署,cuda() GPU 部署
3.1 命令行版 cli_demo.py
命令行启动方式,首先找到 ChatGLM3 目录下的 cli_demo.py 文件,修改代码如下:

修改完成之后,到 ChatGLM3 目录下运行 python cli_demo.py 启动服务
程序会在命令行中进行交互式的对话,在命令行中通过 用户: 进行输入指示,直接输入问题回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
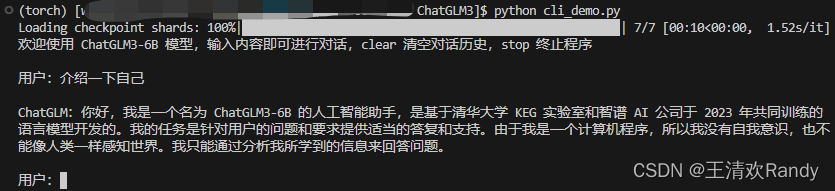
3.2 网页版 web_demo.py
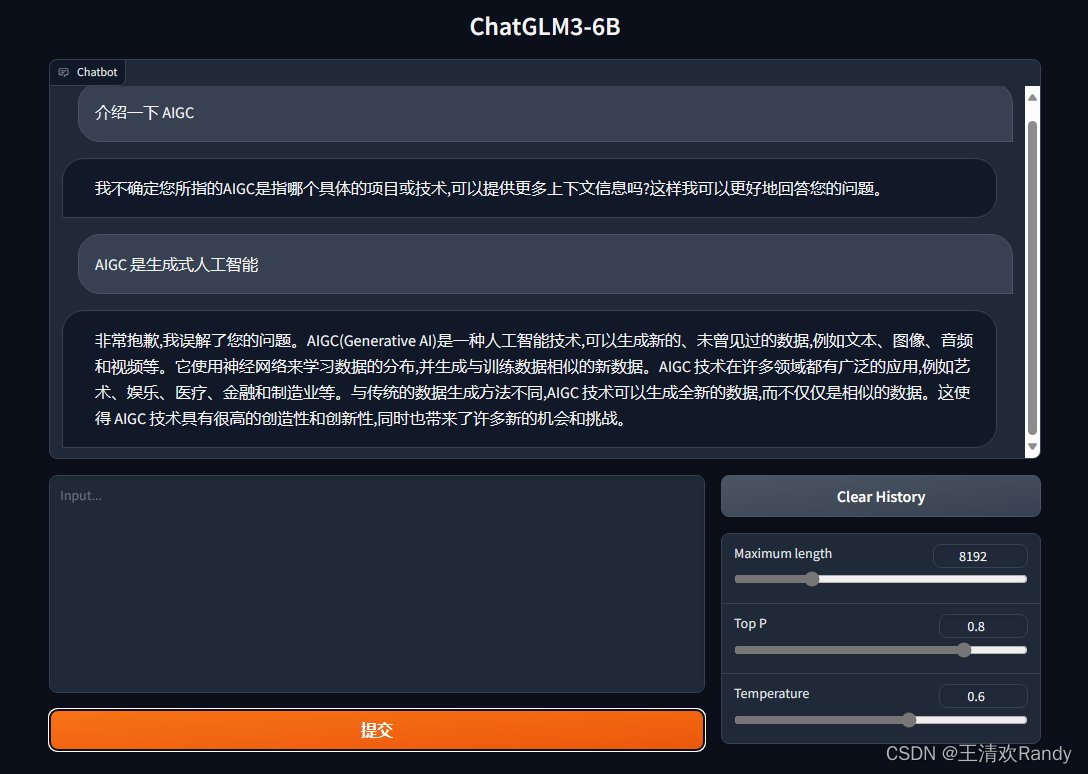
网页版和命令行相似,但是提供了更加友好交互页面,找到 ChatGLM3 目录下的 web_demo.py 文件,做出相同的代码修改,
然后,到 ChatGLM3 目录下运行 python web_demo.py 启动服务

程序会运行一个 Web Server,并输出一个访问地址,在浏览器中打开输出的地址即可使用。
3.3 API 部署 openai_api.py
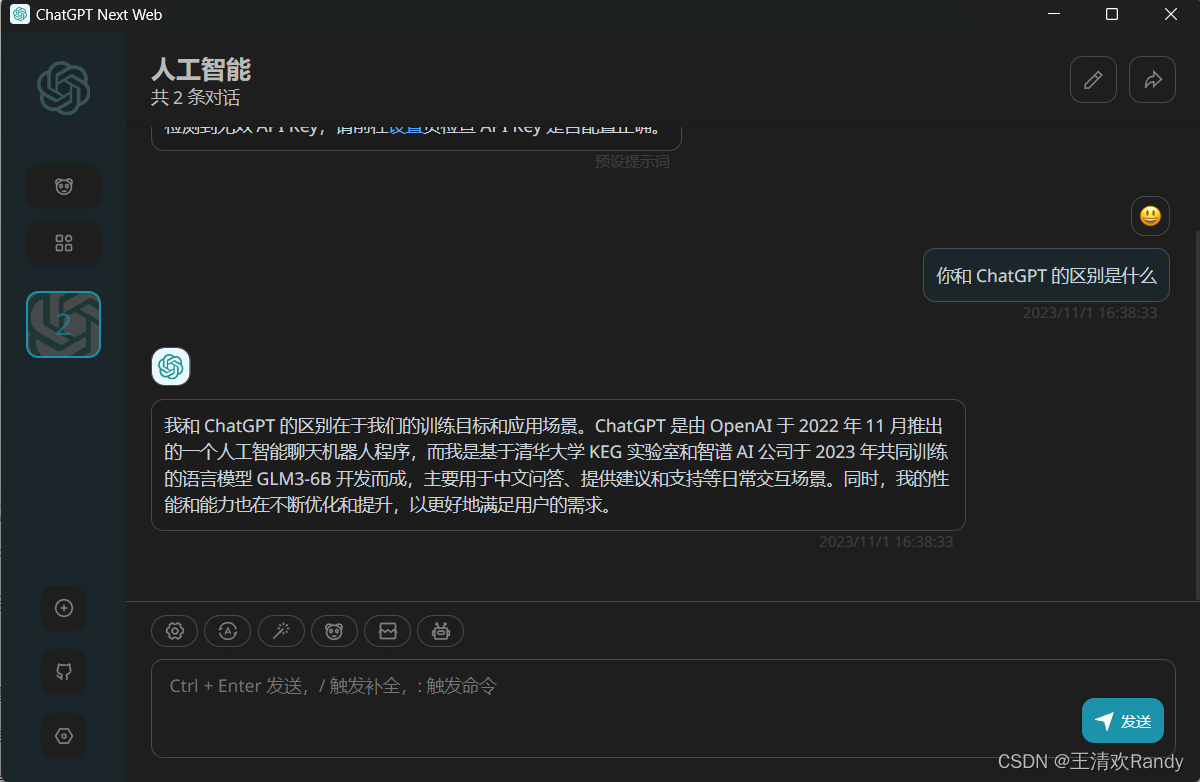
最后,介绍 API 部署方式,也是笔者最推荐的方式,结合 ChatGPT-Next-Web 使用
ChatGLM3 实现了 OpenAI 格式的流式 API 部署,可以作为任意基于 ChatGPT 的应用的后端,这里以 ChatGPT-Next-Web 为例介绍使用方法
首先,需要移步 https://github.com/Yidadaa/ChatGPT-Next-Web/releases 下载 ChatGPT-Next-Web,这个交互页面很轻量级。
然后,到 ChatGLM3 目录下找到 openai_api.py 源码文件,和上面方式一样,修改本地模型路径和部署方式,还有根据自己需要修改最后一行代码中定义的 Host 和 Port,这是 ChatGPT 应用的访问 URL
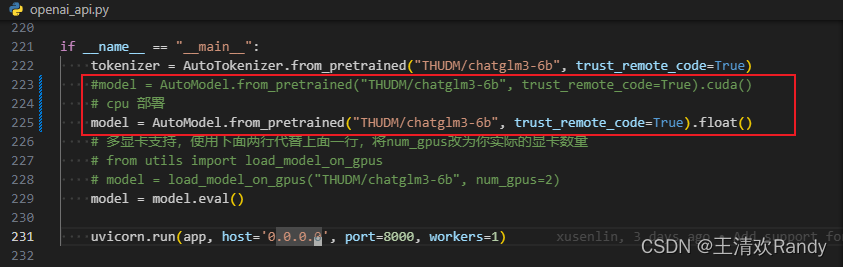
接着,在仓库目录下执行 python openai_api.py 启动模型服务

然后将日志打印出的接口地址 http://localhost:8000/ 写入 ChatGPT-Next-Web 的设置中,并添加自定义模型 chatglm3
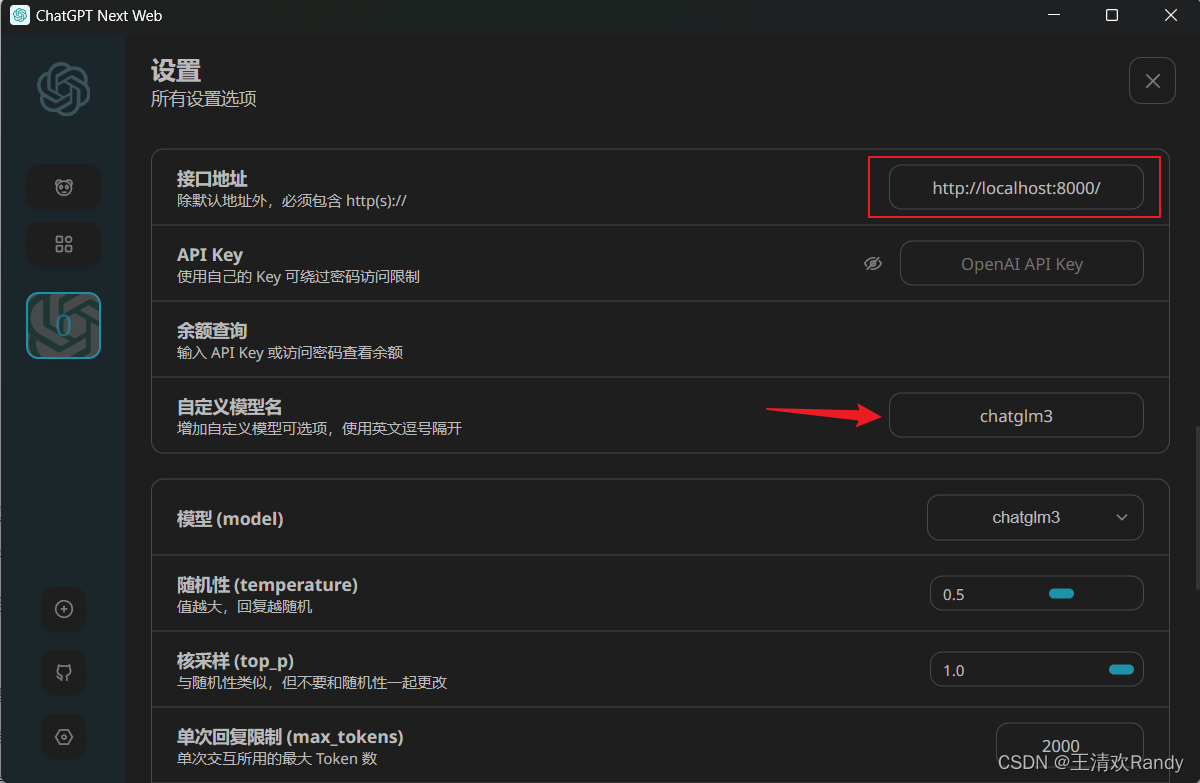
完成设置之后,就大功告成了
如果文章对你有帮助,欢迎一键三连
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

