
- 1Claude 3是什么?与GPT-4相比有什么优势?
- 2前端开发基础(3)—JavaScript_什么是javascript,它在前端开发中的角色是什么?
- 3USB驱动之Android usb鼠标驱动_安卓鼠标驱动
- 4鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Column)
- 5微信小程序如何跳转视频号直播间_小程序能跳转视频号吗
- 6在html中列表是块元素还是,HTML基础知识4-列表及表单的写法、块级元素和内联(行内)元素的区别...
- 7Spring 常用依赖以及使用demo_org.springframework.stereotype.service
- 8Nodejs 应用编译构建提速建议 | 京东云技术团队_node turbo
- 9将Linux curl命令转换为windows平台的Python代码
- 10VIM配置攻略(最强干货!!!!)_spacevim作者
ChatGLM学习
赞
踩
- GLM paper:https://arxiv.org/pdf/2103.10360.pdf
- chatglm 130B:https://arxiv.org/pdf/2210.02414.pdf
前置知识补充
双流自注意力
Two-stream self-attention mechanism(双流自注意机制)是一种用于自然语言处理任务的注意力机制。它是基于自注意力机制(self-attention)的扩展,通过引入两个独立的注意力流来处理不同类型的信息。
-
在传统的自注意力机制中,输入序列中的每个位置都会计算一个注意力权重,用于对其他位置的信息进行加权聚合。而在双流自注意力机制中,会引入两个注意力流,分别用于处理不同类型的信息。
-
双流自注意力,一个注意力流用于处理位置信息(position-based),另一个注意力流用于处理内容信息(content-based)。位置信息可以帮助模型捕捉序列中的顺序和结构,而内容信息可以帮助模型理解不同位置的语义关联。
- 具体来说,双流自注意力机制会为每个注意力流维护一个独立的注意力矩阵,用于计算注意力权重。然后,通过将两个注意力流的输出进行加权融合,得到最终的注意力表示。
- 通过引入两个注意力流,双流自注意力机制可以更好地捕捉不同类型信息之间的关系,提高模型在语义理解和推理任务中的性能。它在机器翻译、文本分类、问答系统等任务中都有应用,并取得了一定的效果提升。
Transformer修改
-
层归一化是一种归一化技术,用于在网络的每一层对输入进行归一化处理。它可以帮助网络更好地处理梯度消失和梯度爆炸问题,提高模型的训练效果和泛化能力。
-
残差链接是一种跳跃连接技术,通过将输入直接添加到网络的输出中,使得网络可以学习残差信息。这有助于网络更好地传递梯度和学习深层特征,提高模型的训练效果和收敛速度。
在一般情况下,层归一化应该在残差链接之前应用。这是因为层归一化对输入进行归一化处理,而残差链接需要将输入直接添加到网络的输出中。如果将残差链接放在层归一化之前,会导致输入的归一化被破坏,从而影响模型的训练和性能。
- 激活函数的修改:GeLU,SwishGLU
MLM:MaskLM任务具有条件独立性假设,预测每个mask的时候是并行的,没有考虑mask之间的关系
Mask:一个单词一个mask,mask可以知道长度信息
Span:几个单词(或者更多个)一起mask掉,span不知道长度信息
把标签映射成词语,进行分类:
- 标成mask,放在最后一个位置,X和Y可以形成一个流畅的语句,接近于自然语言
模型概述
- Decoder Only(GPT):Decoder单向注意力,擅长生成任务,但没有捕获上下文信息,不擅长NLU任务;核心任务是Next Token Predict(自回归填充)
- Encoder Only(Bert):encoder双向注意力,擅长提取文本表征做NLU任务,但没有Decoder不擅长生成任务;核心任务是MLM
- Encoder-Decoder(T5):Encoder双向注意力,Decoder单向注意力,以上二者的中和,擅长NLU和条件生成任务;核心任务是输入文本,输出文本(mask和非mask互换预测)
- UniLM:
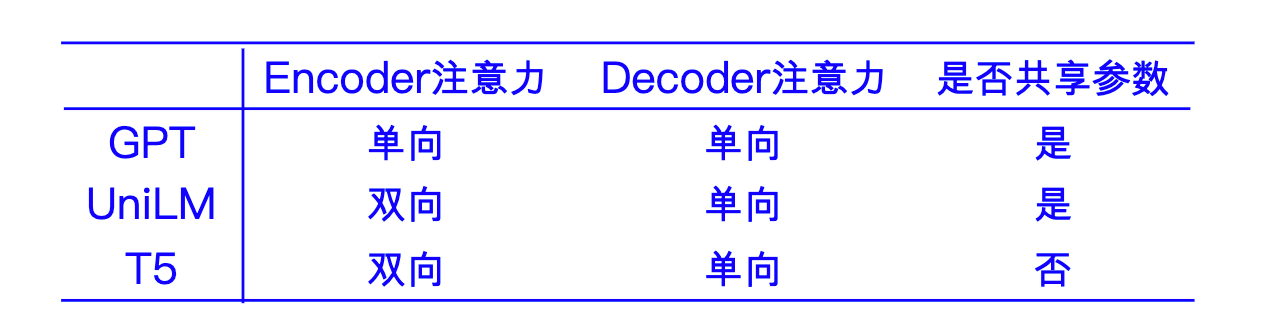
于是GLM打算博采众长,集成上面的三个核心任务,并做出改进:
- span shuffling
- 2D positional encoding
GLM模型基本原理
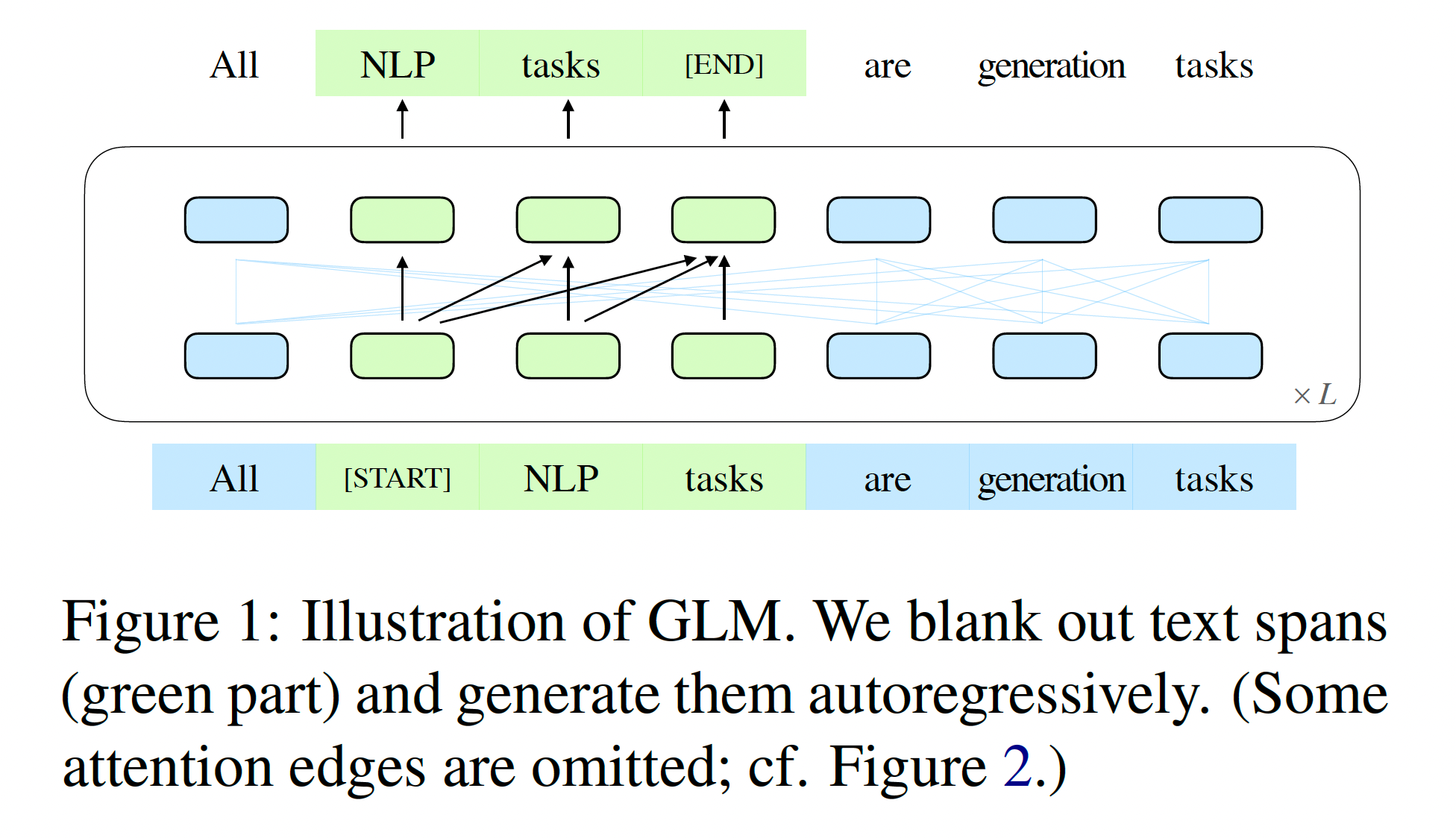
预训练任务1: Autoregressive Blank Infilling
Mask的token方面:
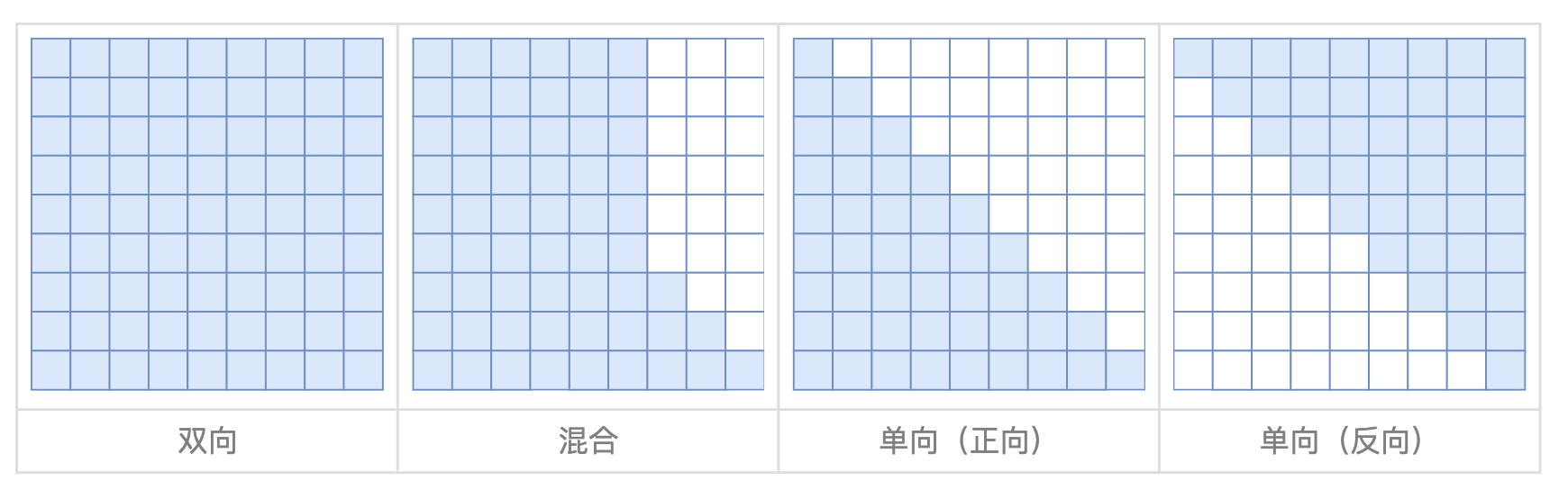
- 一个句子随机抽连续的几个token出来,用一个Span盖住,再把Span随机打乱(为了充分捕捉不同Span之间的相互依赖关系,我们随机排列跨度的顺序,类似于排列语言模型)
Mask的注意力方面:
-
被mask的部分:
- 单向注意力(只能前面预测后面)
- 不参与预测没有被Mask的部分
-
没有被Mask的部分:
- 双向注意力(前后双向预测)
-
有两点很关键:
前面的Span会参与后面的Span的预测中,考虑了Span和Span之间的关系 -
Span内部的长度未知

-
A是原始序列,B是被Span的序列
-
A上是双向注意力(Encoder),B上单向注意力(Decoder)
预训练任务2:多任务学习
- Document level (Span的长度为文章长度的50%-100%)
- Sentence level:一整句的长度
2D Positional Encoding
- 第一个位置编码上表示被Span的原始文本
- 第二个位置编码表示Span内部的文本
归一化
- 使用DeepNet的Post-LN
在GLM-130B中,我们决定使用Post-LN,并使用新提出的DeepNorm来克服不稳定性。DeepNorm的重点是改进初始化,可以帮助Post-LN变换器扩展到1000层以上。在我们的初步实验中,模型扩展到130B,Sandwich-LN的梯度在大约2.5k步时就会出现损失突变(导致损失发散),而带有DeepNorm的Post-Ln则保持健康并呈现出较小的梯度大小(即更稳定)
门控单元
-
采用GeGLU,比GAU稳定,比GLU效果好
-
三个投影矩阵,隐藏层维度降低了2/3

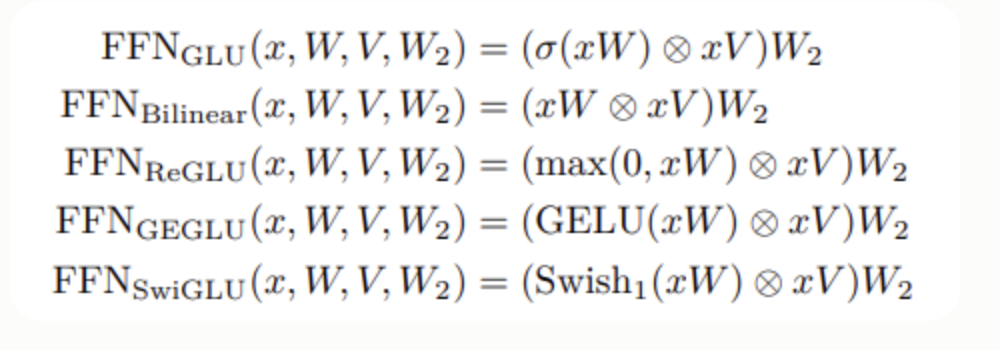
梯度缩减
- BLOOM汇报了使用嵌入归一化(我们也发现它能稳定训练),但同时,其牺牲了相对较大的下游性能。
word_embedding = word_embedding * α + word_embedding.detach() * (1 - α)
- 1
ChatGLM2
在GLM一代的版本上做了如下优化
-
更强大的性能:ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了
1.4T 中英标识符的预训练与人类偏好对齐训练。 -
更长的上下文:
基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。- 但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
-
更高效的推理:
基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%- INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
ChatGLM3
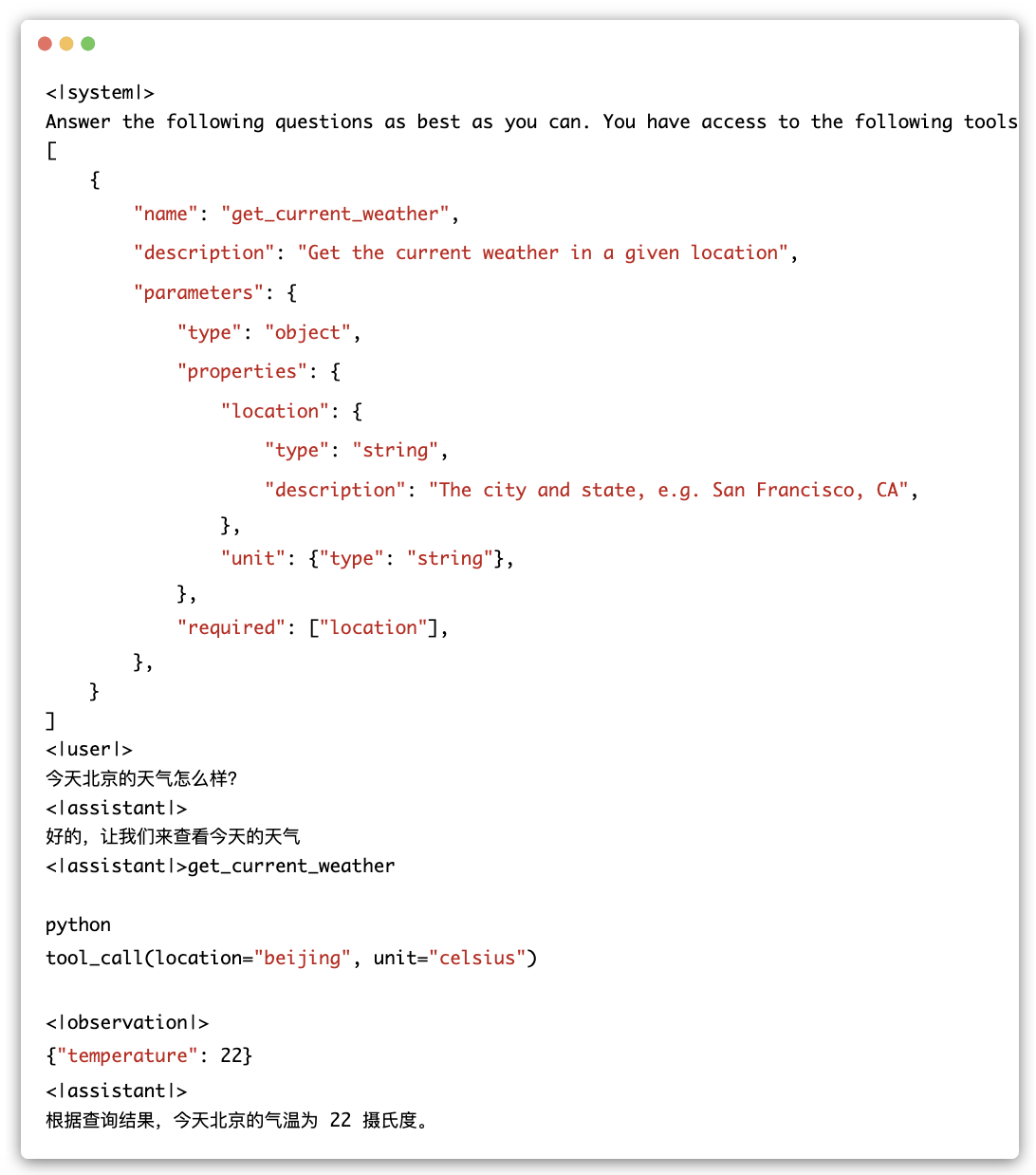
工具调用
-
Name, Description, Parameters:「type,限制条件」, Required: 「需要返回的类型」

2)置于history上下文,送入模型进行问答

3)调用工具执行接口,完成查询

4)将输出结果送入模型进行回答 -
role="observation"表示输入的是工具调用的返回值而不是用户输入,不能省略。

2、全新设计的Prompt格式
- 更改prompt格式的初衷在于为了避免用户输入的注入攻击,以及统一Code Interpreter,Tool&Agent等任务的输入,采用了全新的对话格式。

<|system|>:系统信息,设计上可穿插于对话中,但目前规定仅可以出现在开头
<|user|>:用户
不会连续出现多个来自 <|user|> 的信息
<|assistant|>:AI 助手
在出现之前必须有一个来自 <|user|> 的信息
<|observation|>:外部的返回结果
必须在 <|assistant|> 的信息之后
- 1
- 2
- 3
- 4
- 5
- 6
- 7
垂直领域微调
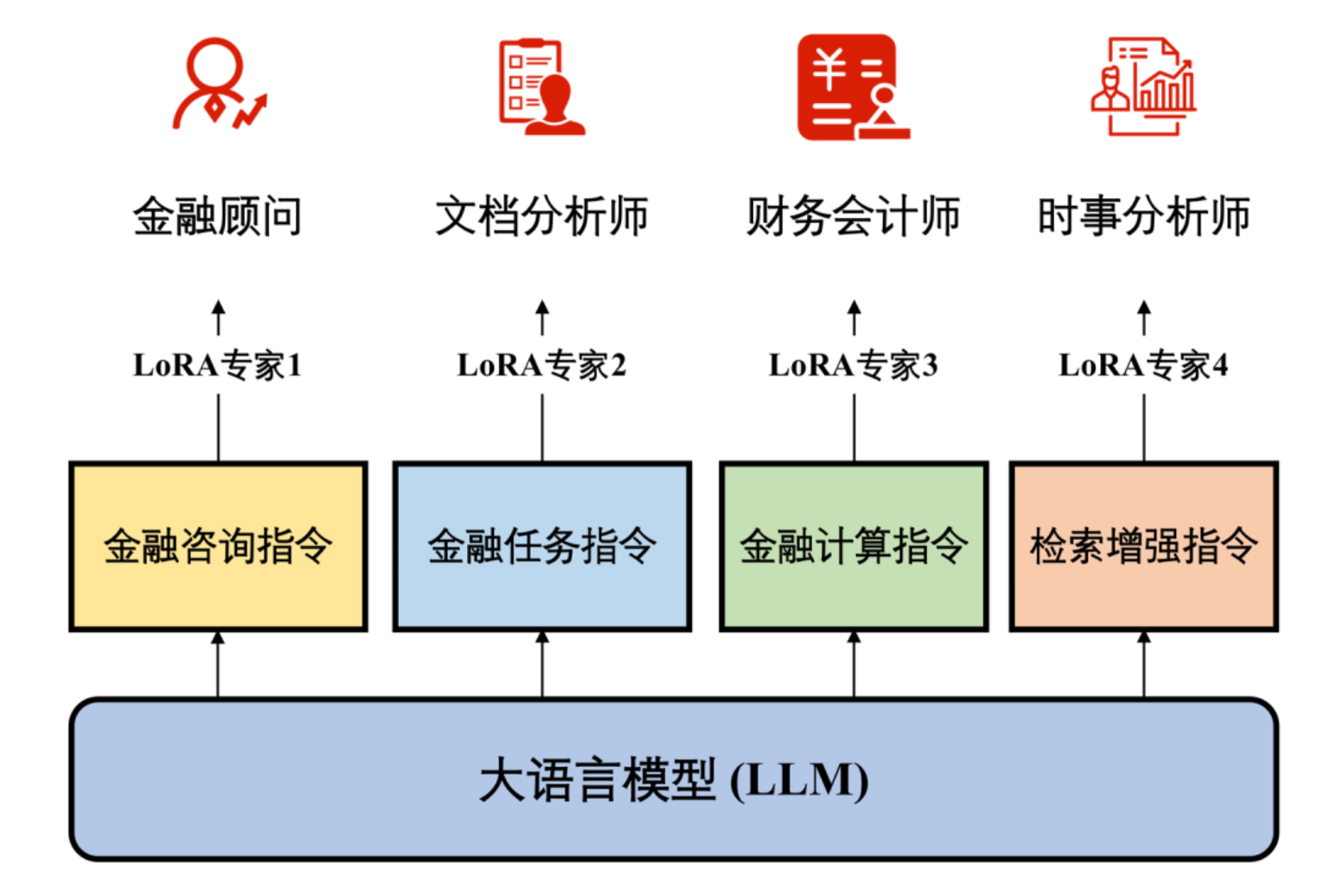
- 数据构造方式
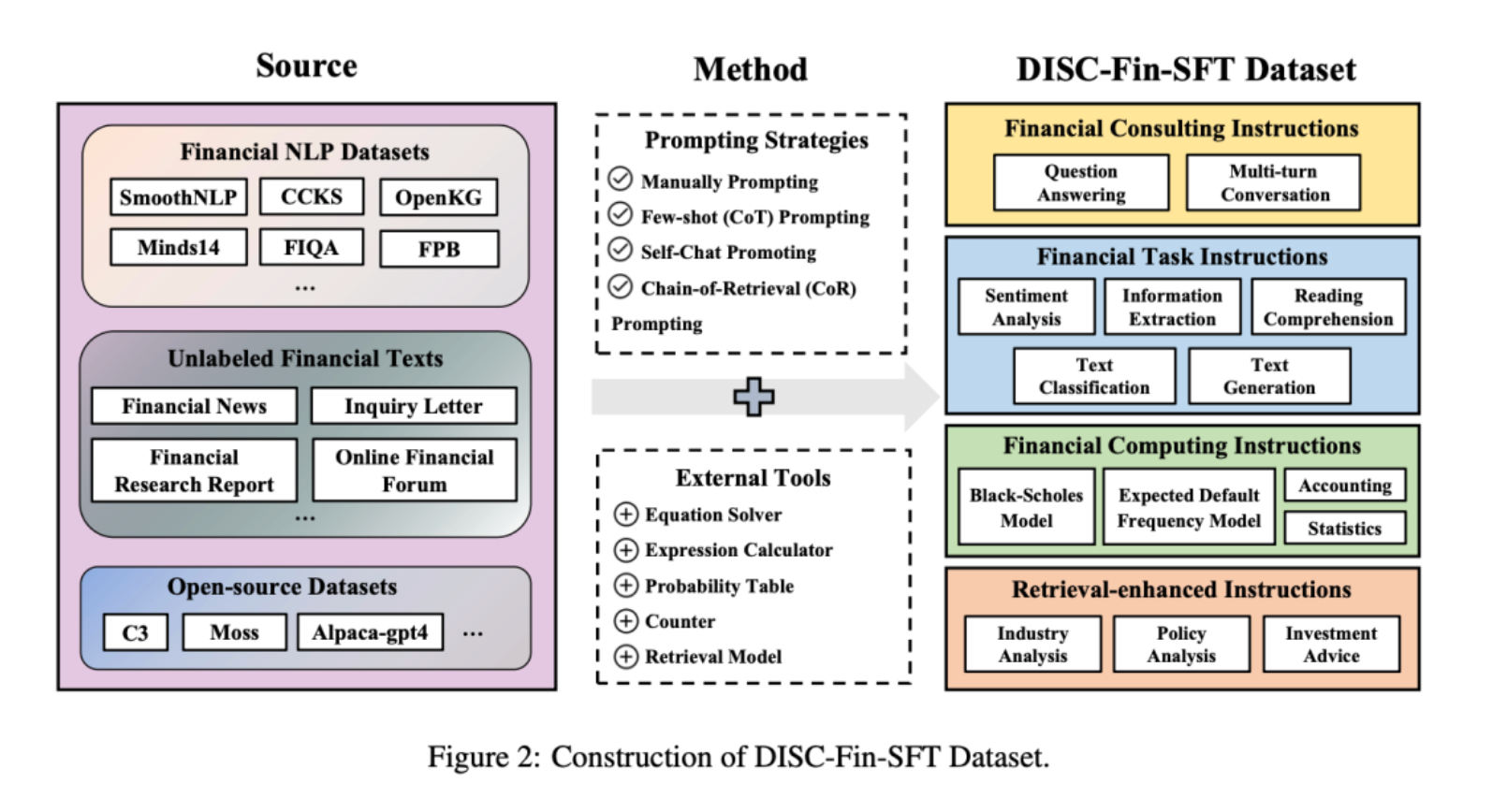
- Prompt数据集
- 使用GPT4进行构造数据:

GLM130B
1)架构选择
通用语言模型GLM
组件改进:旋转位置编码、DeepNorm、GeGLU
2)工程实现
并行策略:数据、张量、流水线3D并行
多平台高效适配
3)训练策略改进
梯度爆炸的问题,采用了嵌入层梯度缩减策略
解决注意力数值溢出问题,采用了FP32的softmax计算策略,训练稳定性有提升
GLM是一种基于Transformer的语言模型,它以自回归空白填充为训练目标。
对于一个文本序列 x = [ x 1 , ⋅ ⋅ ⋅ , x n ] x=[x1, · · · ,xn] x=[x1,⋅⋅⋅,xn],从其中采样文本span{s1,· · ·,sm},其中每个si表示连续令牌的跨度,并用单个掩码替换si,要求模型对它们进行自回归恢复。
与GPT类模型不同的是,它在不Mask的位置使用双向注意力,因此它混合了两种Mask,以支持理解和生成:
[MASK]:句子中的短空白,长度加总到输入的某一部分
[MASK]根据泊松分布 (λ=3)对输入中标识符进行短跨度的采样,主要服务对文本的理解能力目标
- 将长度相加达到输入的一定部分的句子中的短空白填充。
[gMASK]:随机长度的长空白,加在提供前缀上下文的句子末尾
掩盖一个长的跨度,从其位置到整个文本的结束,主要服务对文本的生成目标能力目标。
- 在提供前缀上下文的句子末尾填充随机长度的长空白。
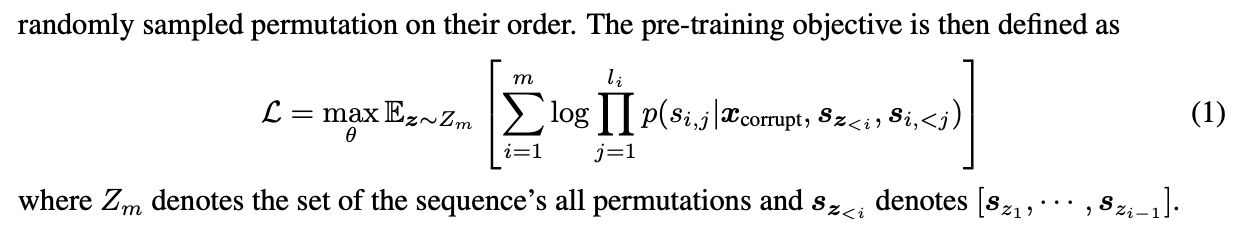
关于LN:
pre-LN(数百亿,混合多模态也不稳定),post-LN(容易发散),SandWish-LN 都在GLM上表现不稳定,所以采用了DeepNorm
D
e
e
p
L
a
y
e
r
(
x
)
=
L
a
y
e
r
N
o
r
m
(
α
∗
x
+
N
e
t
w
o
r
k
(
x
)
)
DeepLayer(x) = LayerNorm(\alpha*x + Network(x))
DeepLayer(x)=LayerNorm(α∗x+Network(x))
关于编码:
1)当序列长度增长时,RoPE的实现速度更快。
2)RoPE对双向注意力更友好,在下游微调实验中效果更好
关于mask:
- 【mask】30% 的training token,占总输入的15%
- 对于其他70%的标记,每个序列的前缀被保留为上下文,并使用[gMASK]来屏蔽其余部分。
FFN改成GLU:
GLM-130B中改进transformer结构中的前馈网络(FFN),用GLU(在PaLM中采用)取代它,实验效果表明选择带有GeLU激活的GLU训练更稳定.(对比了另一个新提出的门控单元GAU)
- GeGLU需要三个投影矩阵;为了保持相同数量的参数,与只利用两个矩阵的FFN相比,我们将其隐藏状态减少到2/3
参考文章:
- https://hub.baai.ac.cn/view/32100

