
- 1yolov5模型(.pt)在RK3588(S)上的部署(实时摄像头检测)_rk3588摄像头实时推理显示
- 2第四期:云数据库入门指南_在云数据库中,复合主键最多包含多少个字段?
- 3element切换主题颜色_element color
- 4Spring用到了哪些设计模式?
- 5网络安全自学笔记01 - Windows基础_windows网络安全学习
- 6java实现spectrogram函数_梅尔频谱(mel-spectrogram)提取,griffin_lim声码器【python代码分析】...
- 7ArkTS编译时遇到arkts-no-obj-literals-as-types错误【Bug已解决-鸿蒙】_object literals cannot be used as type declaration
- 8玩客云刷机(2022-3-19亲测)
- 9利用python中GDAL读写tif文件_python gdal 读取 超大图片
- 10LSTM实现时间序列预测(PyTorch版)_pytorch lstm预测时间序列实战-准备数据
最强英文开源模型Llama2架构与技术细节探秘_llama decoder架构
赞
踩
prerequisite: 最强英文开源模型LLaMA架构探秘,从原理到源码
Llama2
Meta AI于2023年7月19日宣布开源LLaMA模型的二代版本Llama2,并在原来基础上允许免费用于研究和商用。
作为LLaMA的延续和升级,Llama2的训练数据扩充了40%,达到2万亿token,并且可处理的上下文增倍,达到4096个token。整体finetuning过程使用了1百万人工标记数据。开源的基座模型包括7B、13B、70B3个版本,并提供了对话增强版本的Llama chat和代码增强版本的Code Llama,供开发者和研究人员使用。
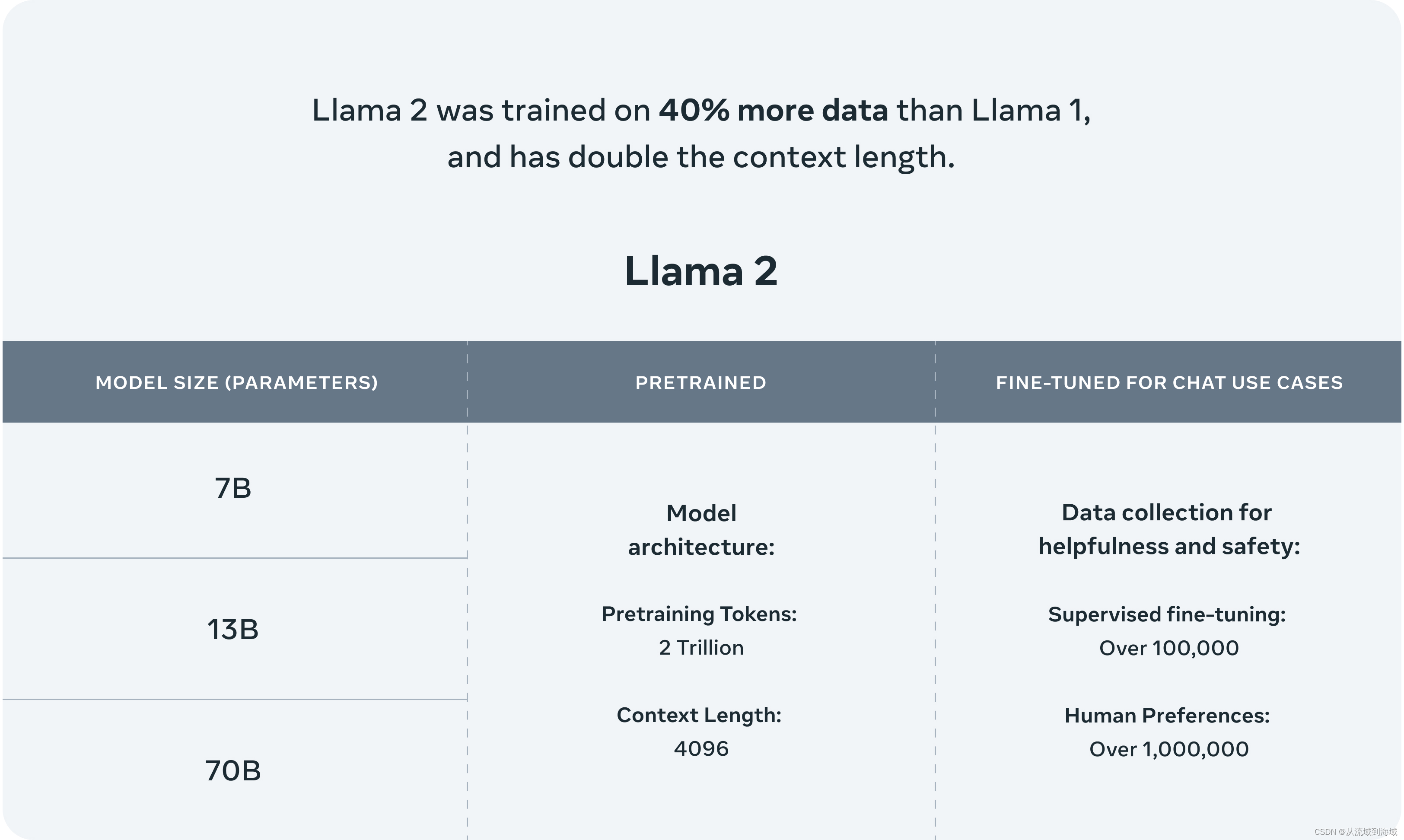
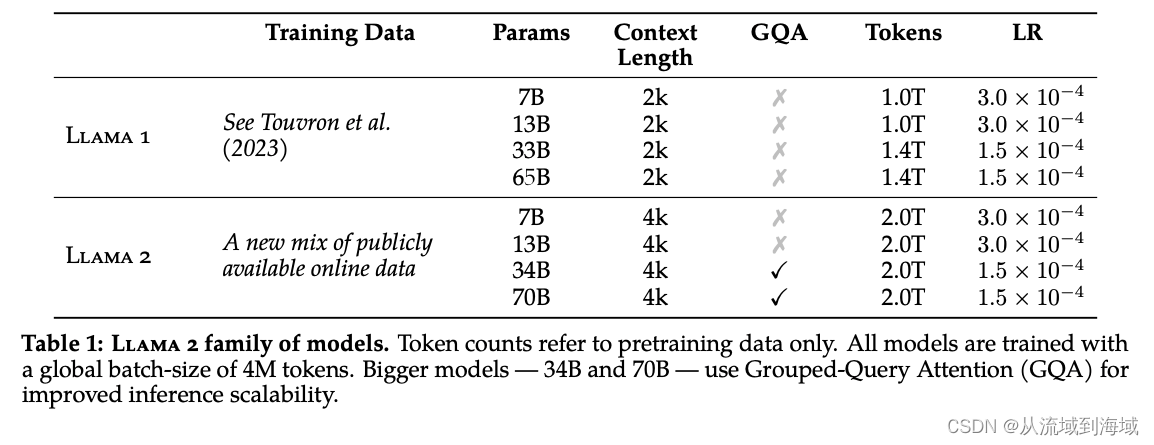
两代模型架构区别
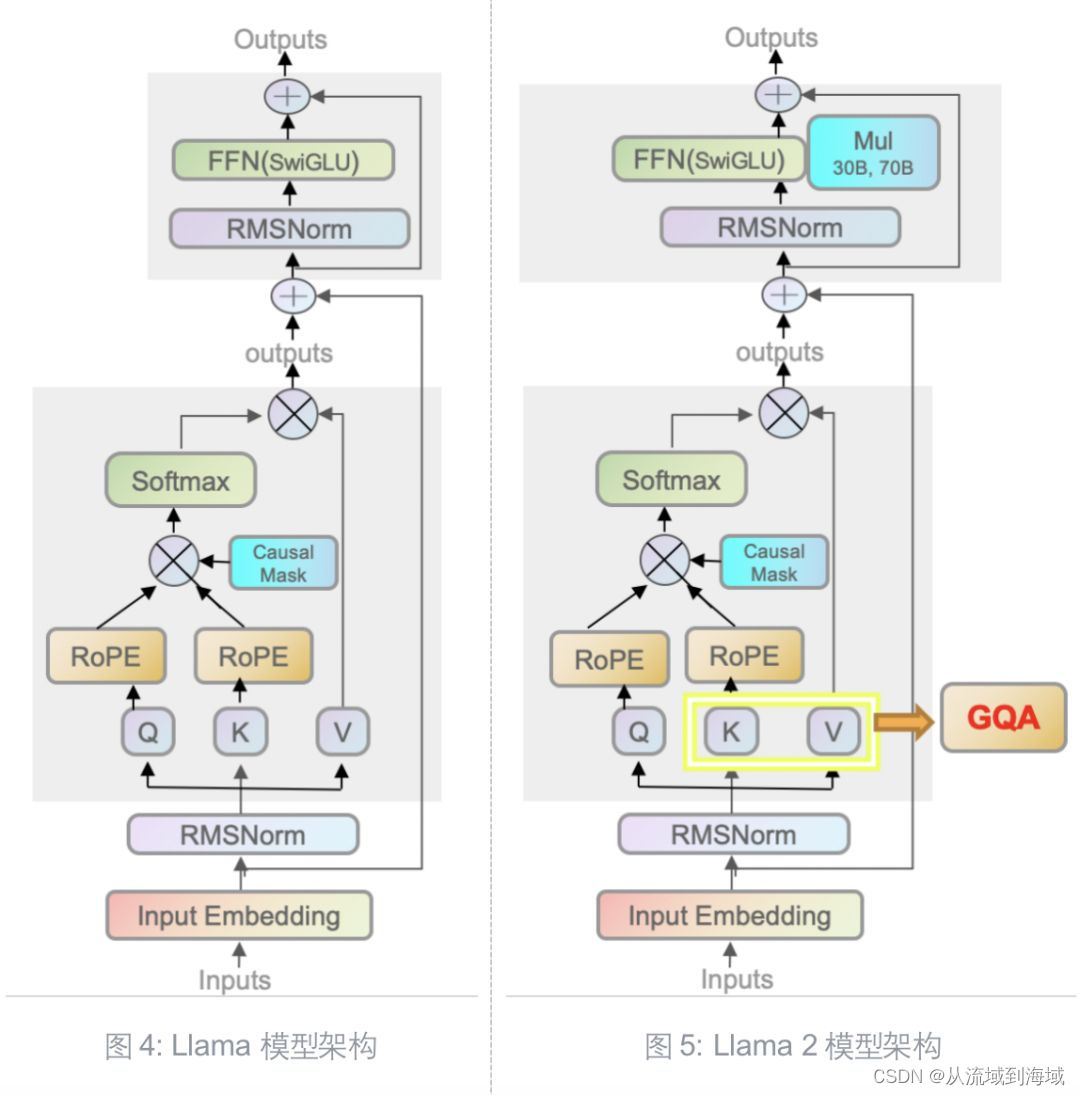
Llama 2和初代模型相比,仍然延续Transformer’s decoder-only架构,仍然使用Pre-normalization、SwiGLU激活函数、旋转嵌入编码(RoPE),区别仅在于前述的40%↑的训练数据、更长的上下文和分组查询注意力机制(GQA, Grouped-Query Attention)。
Group-Query Attention
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
引入GQA的主要目的是提升推理速度,这种注意力机制由transformer的Multi-head Attention简化而来,再辅以KV cache的checkpoint机制进一步提速。
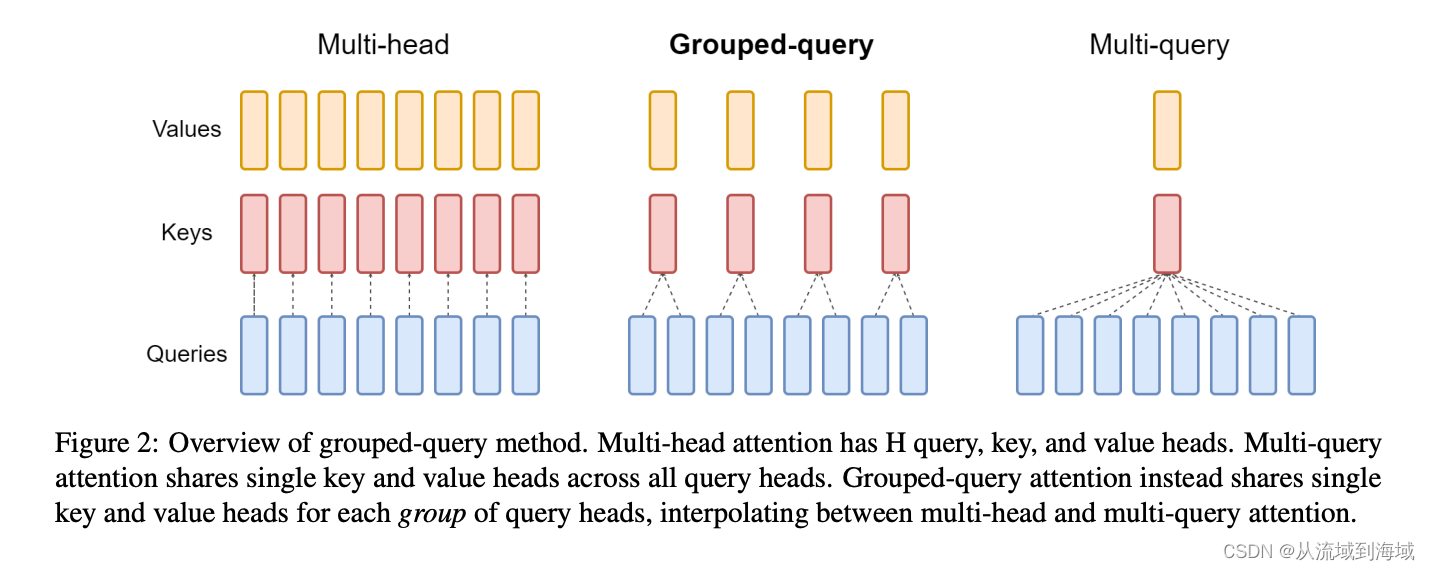
如上图:
- 左边是transformer原始的Multi-head Attention,它有H个query,key,value,即每个query单独配一个key和value
- 右边是其他研究者提出的Multi-query Attention,它在多个query共享同一个key和value
- 中间则是折中的Grouped-query Attention,它将query进行了分组,仅在组内共享同一个key和value
具体而言,Llama2使用了8组KV映射,即GQA-8,实测效果上接近MHA,推理速度上接近MQA,尽可能做到了效果和速度兼得。
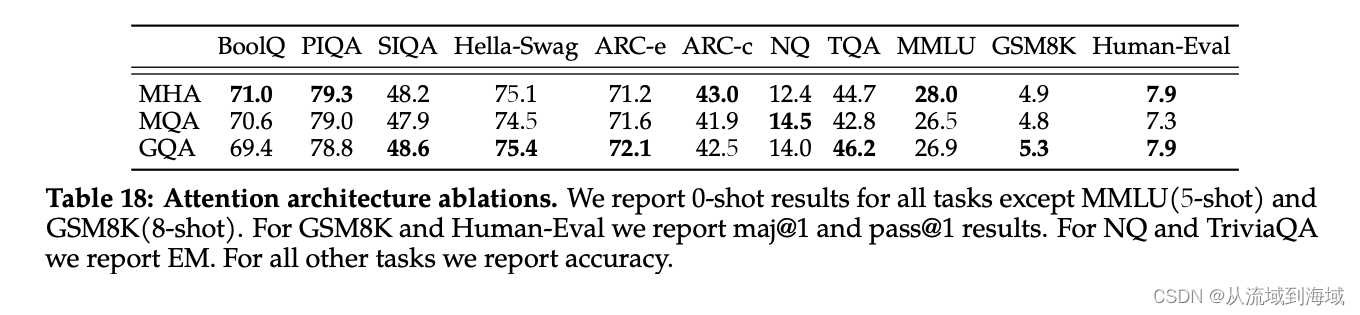
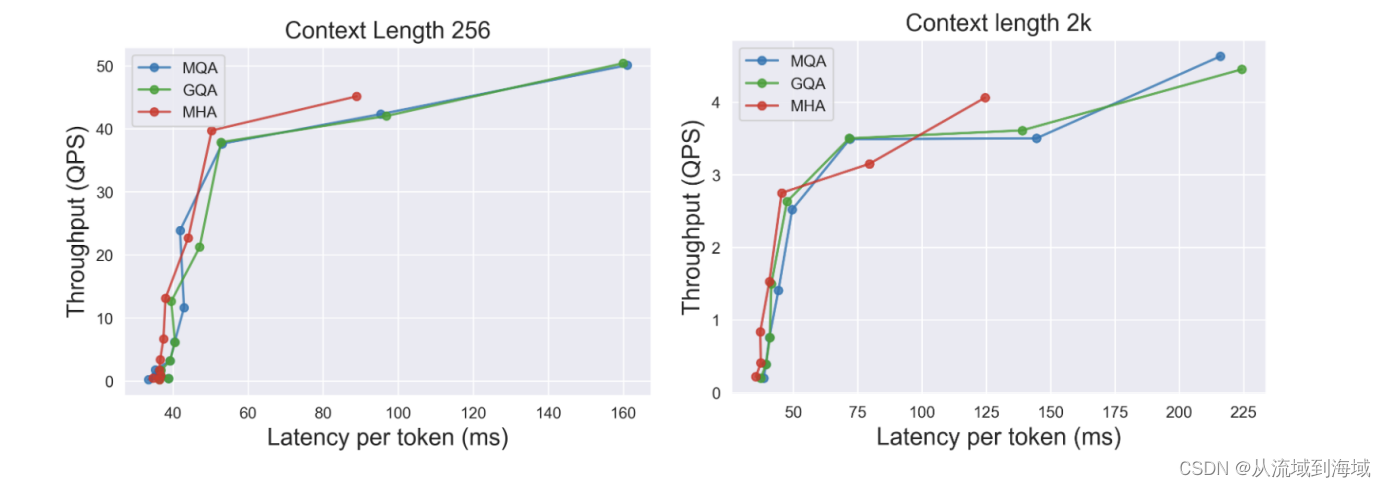
对比其他模型
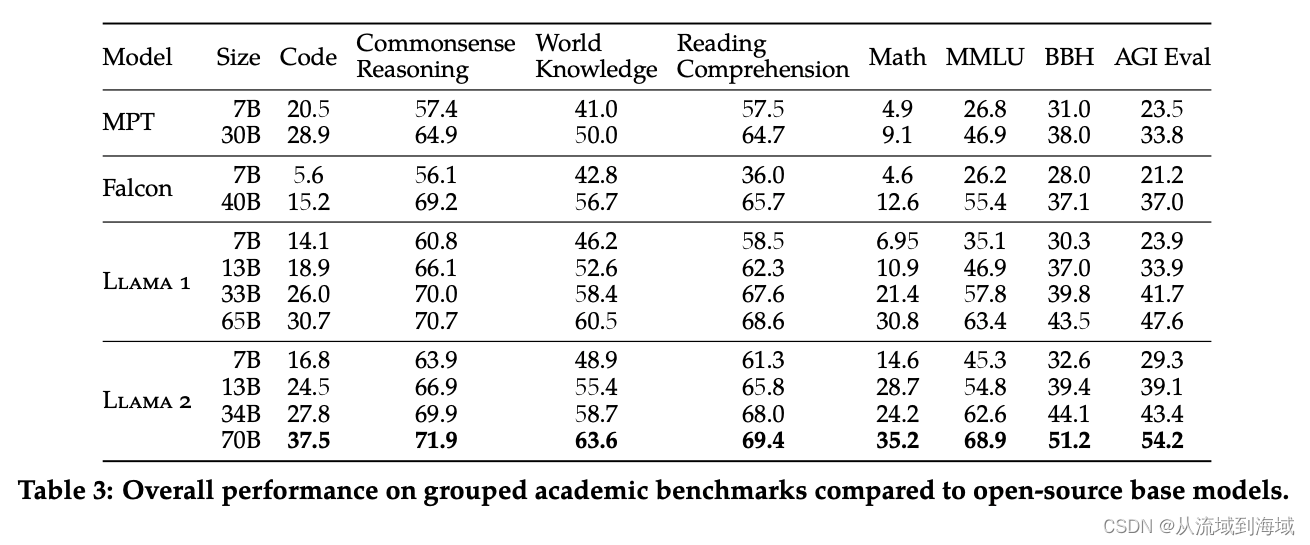
Llama2在一众开源模型中遥遥领先。
笔者注:模型架构没有太大变化,GQA只是推理加速,但效果提升,那也就是说明主要得益于新增的那40%的数据。坦白讲,大模型阶段模型架构已经不那么重要了,可以保证一定的推理速度即可,效果上dataset is all you need。
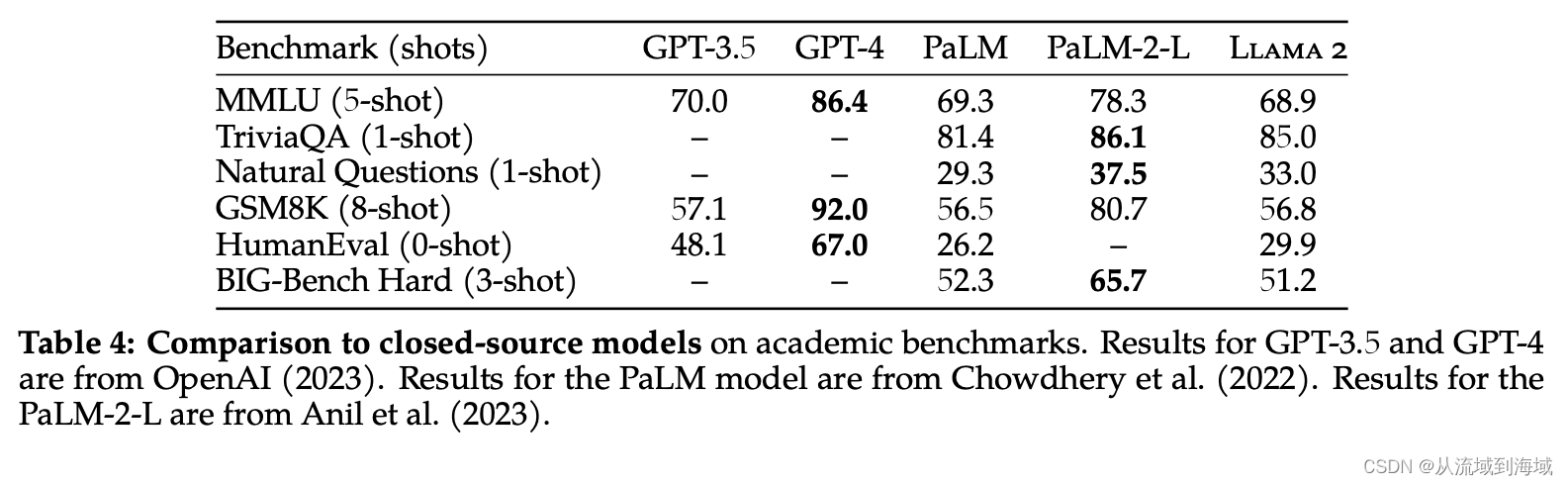
但在闭源模型的比较上,Llama2仅领先PaLM,且仅能做到在MMLU和GSM8K两个数据集上接近GPT3.5,与PaLM-2-L和GPT-4相比,仍然落后不少。
Llama-chat训练流程

下面我们来聊一聊llama-chat的训练流程,详见原技术论文,以下仅做流程概述:
- 自监督预训练
- 监督精调
- RLHF
a. 自人类偏好数据集中训练2个奖励模型,分别是Safety Reward Model和Helpful Reward Model,一个用于对人类偏好进行奖励建模,一个对安全合规进行奖励建模
b. 先使用Helpful Reward模型进行RLHF,基于Rejection Sampling和PPO
c. 在helpful的基础上进一步提升安全性,使用Safety Reward Model进行RLHF,也是基于Reject Sampling和PPO,实验证明,Safety RLHF能在不损害helpfulness的前提下有更好的长尾safety棒性
重要的细节上:
- PPO(Proximal Policy Optimization),即标准的RLHF使用的方法
- Rejection Sampling fine-tuning(拒绝采样微调):采样模型的k个输出,并选择奖励模型认为最好的样本作为输出进行梯度更新
两种RL算法的区别是:
- 广度上:PPO仅进行一次生成;Reject Sampling会生成k个样本,从中选取奖励最大化的样本
- 深度上:PPO的第t步训练过程的样本是t-1步更新的模型策略函数;Reject Sampling的训练过程相当于对模型当前策略下的所有输出进行采样,相当于是构建了一个新的数据集,然后在进行类似于SFT的微调
Meta仅在最大的Llama2 70B使用了Reject Sampling,其余模型仅使用了PPO。
Code-Llama
2023年8月24日,Meta推出了面向代码的可商用代码大模型Code Llama,开源了3个版本7B/13B/34B。支持多种编程语言,包括Python、C++、Java、PHP、Typescript (Javascript)、C#和Bash。
训练流程如下图:
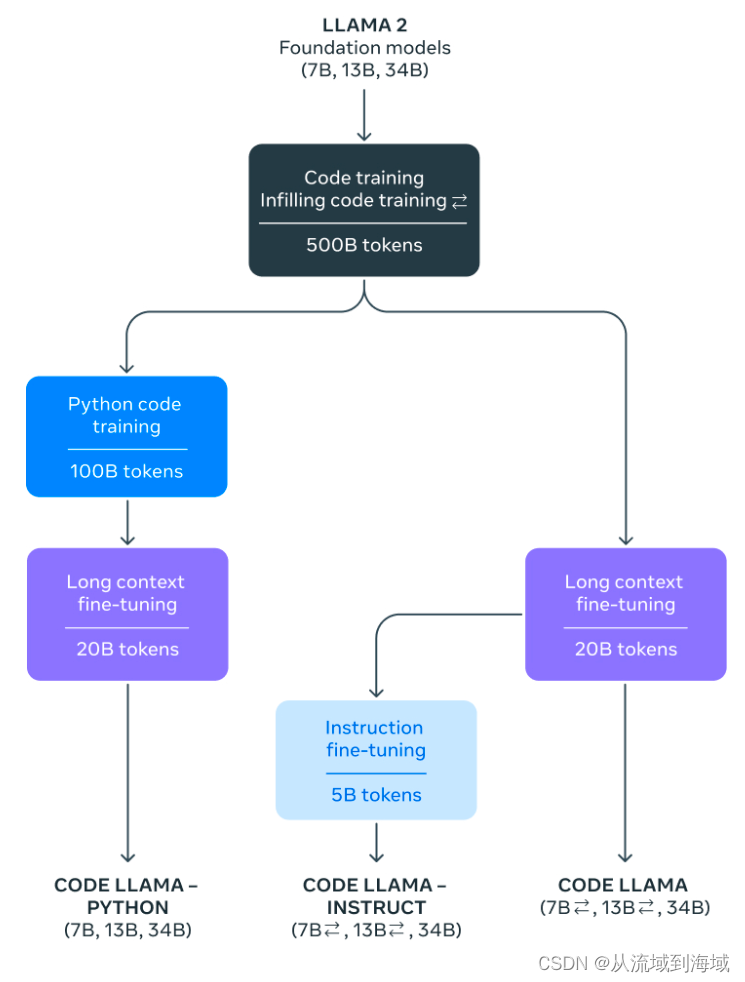
如图所示,包含3个分支模型,每个分支模型的第一步都是使用500B的token进行Code Training和Infilling code training
- Code Llama-Python(面向python语言的代码模型),第一步之后先用100B token的python代码进行训练,然后再使用20B的token在长上下文的场景上进行finetuning得到最终模型
- Code Llama(通用代码模型),第一步之后使用20B的token在长上下文的场景上进行finetuning得到最终模型
- Code Llama-Instruct(面向对话的代码模型),第一步之后同Code Llama使用20B的token在长上下文的场景上进行finetuning,然后再在5B的token上进行指令精调
训练集详情如下:
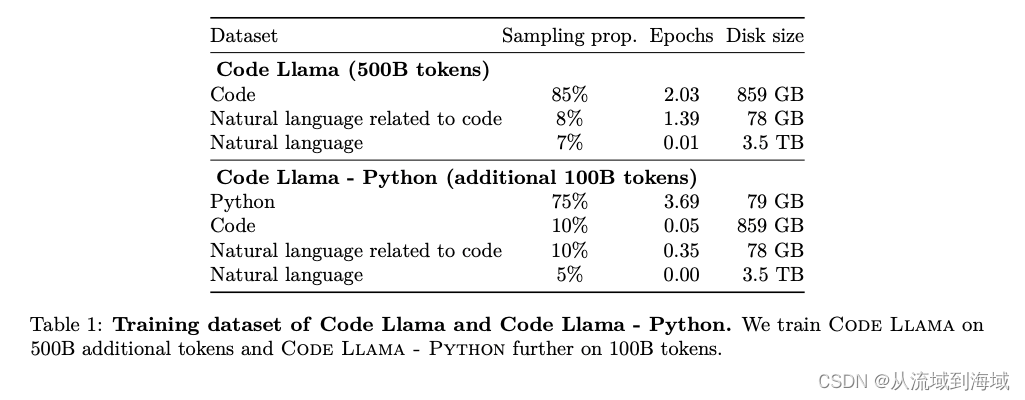
细节上:
- Code Training即使用代码数据进行训练
- Code Infilling值得是根据代码上下文预测残缺的代码部分,仅针对代码文本进行挖空预测,方法与Bert的挖空预测类似:
a. 从完整的代码中选择一部分进行掩码(mask)并替换为<MASK>符号,构成上下文作为输入
b. 然后采用自回归的方式对mask进行预测
模型效果对比上,神秘的unnatural版本在HumanEval的pass@1上领先GPT-3,接近于GPT-4(5%左右差距),其余部分明显领先PaLM系列和StarCoder系列模型:
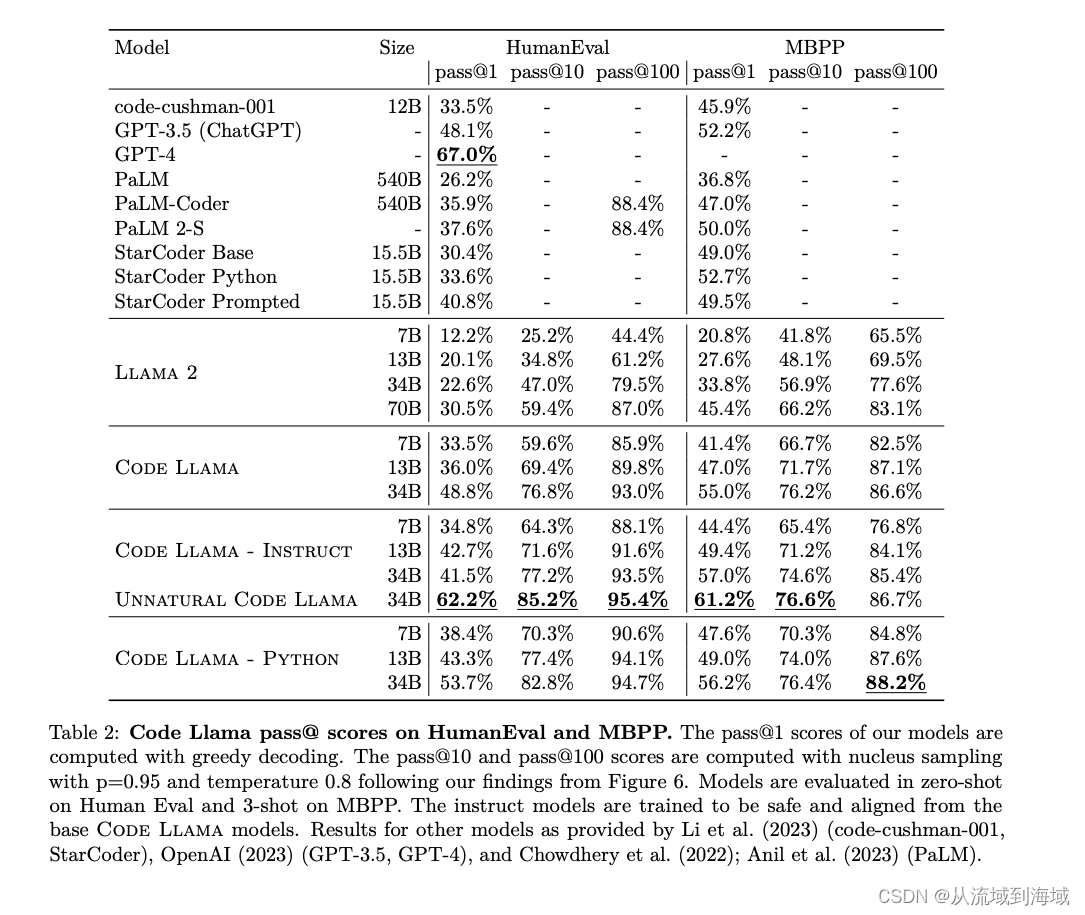
参考文献
- https://ai.meta.com/llama/
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- 大模型技术实践(二)|关于Llama 2你需要知道的那些事儿
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- 大规模预训练语言模型方法与实践,崔一鸣,北京BAAI,2023年8月26日
- https://ai.meta.com/blog/code-llama-large-language-model-coding/
- Code Llama: Open Foundation Models for Code

