
- 1【MATLAB】在MATLAB中编写函数判断一个数是不是素数_matlab判断一个数是否为素数
- 2多线程与并发 - Thread中的start和run方法的区别___start_thread
- 3OpenStack集成Docker
- 4OpenHarmony ArkTS工程目录结构(Stage模型)_[compile result] arkts:error file: d:/myapplicatio
- 5栅格地图路径规划:基于红尾鹰算法(Red‑tailed hawk algorithm ,RTH)的机器人路径规划(提供MATLAB代码)
- 6第3章_瑞萨MCU零基础入门系列教程之开发环境搭建与体验_瑞萨单片机的e2s和pdg如何使用区别
- 7F1值(F-Measure)、准确率(Precision)、召回率(Recall) 菜鸡版理解
- 8解决vue i18n 项目中 title 双英 切换问题_i18n.t is not a function
- 9【网络工程师必备】华为设备网络基础配置命令总结,看过的都收藏了_8.8.8.8:90 用户认证系统
- 10java中的4种访问制权限有哪些?分别作用范围是什么?_java中的访问权限有哪几种?各自的访问范围是什么?设置访问权限的目的是什么?
论文阅读:Retrieval-augmented Generation across Heterogeneous Knowledge_retrieval augmented generation
赞
踩
跨异构知识的检索增强生成
NAACL 2022 论文链接
摘要
检索增强生成(RAG)方法越来越受到NLP社区的关注,并在许多NLP下游任务上取得了最先进的性能。与传统的预训练生成模型相比,RAG方法具有知识获取容易、可扩展性强、训练成本低等显著优点。尽管现有的RAG模型已应用于各种知识密集型NLP任务,如开放领域QA和对话系统,但大部分工作都集中在从维基百科检索非结构化文本文档上。在本文中,我首先阐述了从单一源同质语料库检索知识的当前障碍。然后,我展示了现有文献和我的实验的证据,并提供了跨异构知识的检索增强生成方法的多种解决方案。
引言
近年来,大型预训练语言模型(PLM),如T5(Raffel等人,2020年)和GPT3(Brown等人,2020),已经彻底改变了自然语言处理(NLP)领域,在各种下游任务上取得了显著的性能(Qiu等人,2020》)。这些PLM从预训练语料库中学习了大量的深度知识(Petroni等人,2019),因此他们可以预测下游任务的输出,而无需访问任何外部存储器或原始文本,作为参数化的隐式知识库(Roberts等人,2020)。仅使用目标数据的输入-输出对微调PLM的方式通常被称为紧密账簿设置(Petroni等人,2019)。
尽管这一发展令人振奋,但此类大型PLM仍存在以下问题缺点:(i)他们通常是离线训练的,使得模型对最新信息不可知,例如,询问2011-2018年训练的聊天机器人关于新冠肺炎(Yu等人,2022b)。(ii)他们仅通过“查找存储在参数中的信息”进行预测,导致可解释性较差(Shuster等人,2021)。(iii)他们大多接受一般领域语料库的培训,因此在特定领域的任务中效果较差(Gururangan等人,2020)。(iv)对于学术研究小组来说,他们的预培训阶段可能非常昂贵,将模型预培训仅限于少数行业实验室(Izsak等人,2021)。
乍一看似乎显而易见的解决方案是允许语言模型自由访问开放世界资源,如百科全书和书籍。用外部信息增加PLM输入的方式通常被称为开卷设置(Mihaylov等人,2018)。开放式书籍环境中的一个突出方法是检索增强生成(RAG)(Lewis等人,2020b;Y u等人,2022c),这是一种融合PLM和传统IR技术的新学习范式,在许多知识密集型NLP任务中取得了最先进的性能(Petroni等人,2021)。与大规模PLM对应物(例如GPT-3)相比,RAG模型具有一些显著的ad52优势:(i)知识不是隐式存储在模型参数中,而是以即插即用的方式显式获取,从而实现了极大的可扩展性;(ii)模型不是从头开始生成,而是基于一些检索到的引用生成输出,这减轻了文本生成的难度。
尽管RAG模型已在现有文献中广泛使用,但大部分工作都集中在从通用领域语料库(如维基百科)中检索非结构化文本。然而,性能通常受限于仅一个特定知识的覆盖范围。例如,在许多开放领域QA数据集中,只有有限部分问题可以从维基百科段落中得到答案,而剩下的问题只能依靠输入问题,因为无法检索到支持性文档(Oguz等人,2022)。在本文中,我首先阐述了从单一源同质语料库检索知识的当前障碍。然后,我从现有文献和我自己的实验中展示了一些证据,并提供了跨异构知识的检索增强生成方法的多种潜在解决方案。
背景
我将首先提供RAG框架的正式定义,并列出必要的符号。RAG旨在基于源输入x(x,y来自语料库D)预测输出y,而文档参考集Z是可访问的(例如,维基百科)。此外,文档z之间的关联∈ Z和元组(x,y)∈ D不一定是已知的,尽管它可以由人类注释(Dinan等人,2019)或弱监督信号(Karpukhin等人,2020)提供。
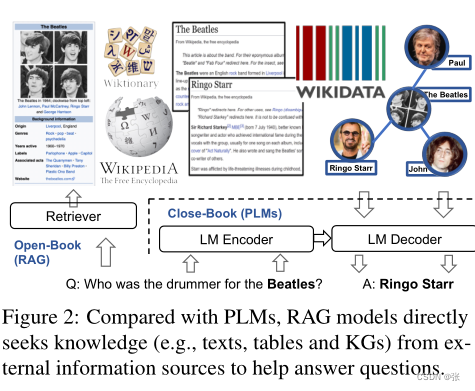
总体而言,通用RAG框架有两个主要组件:(i)文档检索器和(ii)文本生成器,如图2所示。RAG的目标是训练一个模型,以最大化给定x和Z的y的可能性。在实践中,Z通常包含数百万个文档,使Z上的枚举变得不可能。因此,RAG的第一步是利用文档检索器,例如DPR(Karpukhin等人,2020),将搜索范围缩小到少数相关文档。检索器将x和Z作为输入,并生成前K个文档Z={Z(1),···,Z(K)}的相关度分数{s1,··,sK}。然后,RAG的第二步是使用文本生成器,例如BART(Lewis等人,2020a)和T5(Raffel等人。,2019),以通过将输入x和检索到的文档集Z作为条件来产生期望的输出y。
文档检索器 神经文档检索器通常使用两个独立的编码器,如BERT(Devlin等人,2019),分别对查询和文档进行编码,并通过计算两个编码表示之间的单个相似性分数来估计它们的相关性。例如,在DPR(Karpukhin等人,2020)中,文档Z和上下文查询x被映射到相同的密集嵌入空间中。每个文档z的相关性得分s(x,z)被计算为文档嵌入hz和查询嵌入hx之间的向量内积,即s(x、z)=hTx×hz。
文本生成器 它可以使用任何编码器-解码器框架,例如BART(Lewis等人,2020a)和T5(Raffel等人,2019)。该模型采用输入序列以及支持文档来生成所需的输出。将输入序列与支持文档组合的一种简单方法是将它们顺序连接起来(Lewis等人,2020a)。然而,该方法存在输入序列长度限制和计算成本高的问题。FiD(Izacard and Grave,2021)在编码器中独立处理段落,对所有检索到的段落进行关注,在许多知识密集型NLP任务中表现出最先进的性能。
背景和动机
尽管取得了显著的成绩,但以往的检索增强生成(RAG)工作主要利用单一来源的同质知识检索空间,即维基百科文章(Karpukhin等人,2020;Lewis等人,2020b;Petroni等人,2021;Izacard和53 Grave,2021;Y u等人,2022a)。然而,它们的模型性能可能会受到仅包含一个特定知识的限制。例如,在许多开放领域QA数据集中,只有有限部分问题可以从维基百科段落中得到答案,而剩下的问题只能依靠输入查询,因为无法检索支持性文档(Oguz等人,2022)。由于许多有用的信息不能仅基于维基百科来实现,一个自然的解决方案是将检索语料库从维基百科扩展到整个万维网(WWW)。然而,由于长尾问题和大量劳动力的成本,通过扩大单一来源知识的条目数量来提高覆盖率是不明智的(Piktus等人,2021;Lazaridou等人,2022年)。例如,如表1所示,将维基百科(22M个文档)的检索空间增加到网络规模的语料库CCNet(906个文档)甚至会损害NQ和HotpotQA数据集上的模型性能。这很可能是因为与维基百科语料库相比,网络语料库的质量较低(质量可能意味着真实性、客观性、缺乏有害内容、来源可靠性等)(Piktus等人,2021)。

一种替代的解决方案不是扩展单个源知识中的条目数量,而是求助于异构知识源。这也符合我们回答问题的人类行为,这些问题往往寻求从不同来源获得的各种知识。因此,跨异构知识源的基础生成是提高知识覆盖率并有更多空间选择适当知识的自然解决方案。值得一提的是,没有哪种知识类型能够总是表现得最好。最合适的知识取决于情况,在这种情况下,可能需要结合多种知识来回答一个问题。
来自现有文献的证据
现有文献中有几项研究结合了多种知识来增强语言模型,例如用知识图增强常识推理(Y u等人,2022d),并引入多模态视觉特征来增强情感对话(Liang等人,2022)。然而,他们中的大多数使用来自不同来源的对齐知识(例如,图形文本对、图像文本对),而没有从大规模异构语料库中检索知识。
与本提案最相关的工程是UniK QA(Oguz等人,2022)和PLUG(Li等人,2021)。在UniK QA中,Oguz等人(2022)提出从结构化(即KG三元组)、半结构化(即表)和非结构化数据(即文本段落)的合并语料库中检索信息,以用于开放域QA(Oguz等,2022)。他们的实验是在多个开放域QA基准数据集上进行的,包括NaturalQuestions(NQ)(Kwiatkowski等人,2019)、TriviaQA(TQA)(Joshi等人,2017)和WebQuestion(WebQ)(Berant等人,2013)。
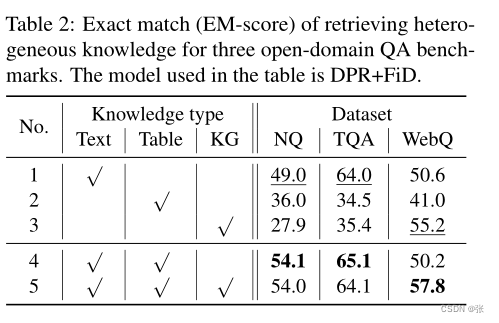
表2中前三行的结果突出了当前最先进的开放域QA模型的局限性,这些模型只使用一个信息源。在三种类型的知识源中,纯文本方法在NQ和TQA数据集上表现最好,纯KG方法在WebQ数据集上的表现最好。这是因为WebQ中的大多数问题都是从Freebase收集的。最后两行中的结果表明,在NQ和TQA数据集上,添加半结构化和结构化信息源显著提高了纯文本模型的性能。这表明表和知识图三元组包含有价值的知识,这些知识要么在非结构化文本中缺失,要么很难从中提取。
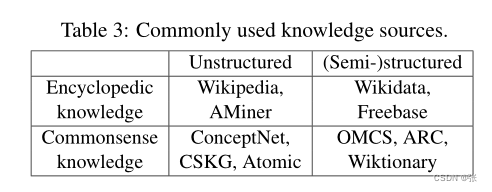
值得一提的是,知识异质性不仅可以通过知识数据的格式(即结构化和非结构化知识)来定义,还可以通过知识的范围(即百科全书式和通用的感知知识)。表3显示了两类常见的知识来源。除了结合结构化和非结构化知识之外,结合百科全书式和常识性知识也为许多NLP任务带来好处,例如对实体的常识推理。对CREAK(Onoe等人,2021)和CSQA2.0(Talmor等人,2021)数据集进行了一些初步实验。CREAK是一个由人类撰写的关于实体的英语声明的数据集,这些声明要么是真的,要么是假的,比如“哈利波特可以教学生如何在扫帚柄上飞行(真的)”。该模型被认为是将关于实体的事实核查与常识推断联系起来。与这一说法相关的一个实体事实,“哈利·波特是一个巫师,擅长骑扫帚”,可以从维基百科中检索到。一个常识,“如果你擅长某项技能,你可以教别人如何做”,可以从ATOMIC中检索到(Sap等人,2019)。通过在第一步检索中利用常识知识和百科全书式知识,如表4所示,RAG模型可以实现比仅使用其中任何一种更出色的性能。
建议的解决方案
如上所述,在解决开放领域QA和许多其他知识密集型NLP任务时,通常需要异构知识。一个自然的假设是扩展知识源并添加更多数据以增加相关上下文的覆盖范围,从而提高端到端性能。在本节中,我将介绍三种跨异构知识生成基础的潜在解决方案。
将不同的知识同质化为统一的知识表示
第一个解决方案是将不同的知识源数据同质化为统一的数据格式——非结构化文本。然后,这种转换只需要一个检索器,就可以跨不同类型的数据进行相关性比较,并提供文本知识,以便通过串联轻松地增加生成模型的输入。表3显示了一些常用的知识源。例如,半结构化表格和结构化知识图三元组可以通过基于模板的方法(Bosselut等人,2019年;Oguz等人,2022年)或神经数据到文本方法(Wang等人,2021;Nan等人,2021)转换为非结构化文本。
首先,基于模板的方法易于实现,不需要培训过程。例如,知识图中的关系三元组由主语、谓语和宾语组成。它可以通过将三个元素的表面形式串联成一个单词序列来序列化。此外,表还可以分层转换为文本格式:首先,将每行的单元格值用逗号分隔;然后组合这些行以分号分隔的文本形式。虽然基于模板的方法很简单,但可能会出现语法错误和语义不完整的问题。相反,神经图文本和表到文本生成方法依赖于预先训练的语言模型,可以确保语法正确性和语义完整性。一旦任一类型的方法将结构化和半结构化数据转换为非结构化文本,就可以使用密集检索器模型(如DPR(Karpukhin等人,2020))对所有数据进行索引并检索相关知识。读取器模型将检索到的文本与原始输入连接起来,并通过T5(Raffel等人,2020)解码器计算整个表示的全部注意力。这种统一的知识索引允许模型学习各种格式和数据范围的知识,并且模型可以同时从多个知识源的统一索引中检索信息,以提高知识覆盖率。
基于异构知识的多虚拟Hops检索
检索到的数据有望弥补发电模型输入和输出之间的差距。换言之,检索器被训练为提供以输入为查询并与输出相关的信息。理想情况下,他们只找到一次55个输出相关信息。然而,这实际上可能需要跨知识源进行多次检索。因此,第二种解决方案是迭代地从不同的源检索知识。关于一个实体,百科全书式知识通常包含其属性信息(例如,年龄、持续时间),而常识性知识则包含人类日常生活中公认的事实。例如,维基百科中的实体“汤”被描述为“一种主要是液体食物,通常是温热或热的,由肉或蔬菜的成分与汤、牛奶或水混合制成”;在OMCS语料库中(Singh等人,2002年),它包含一个众所周知的事实“汤和沙拉可以是健康的午餐”。因此,为了回答“健康午餐中常见的成分是什么?”,百科全书式语料库和常识性语料库可以提供互补的知识,两者都应加以利用。
此外,还可能需要首先读取语料库的子集以提取有用信息,然后进一步从其他知识源检索信息。例如,给定输入q,它可能需要k个步骤,每个步骤从源si检索数据di∈ 具有增量查询qi=q的S⊕ 第1天⊕ · · · ⊕ 二−1(i)≤ k) 直到最后的dk包含可以直接增加输出生成的信息。这里S包括各种来源,如文本语料库、表格和知识图。然而,为了实现这一点,训练这种多跳检索器的主要挑战是它不能观察任何用于监督的中间文档,而只能观察最终输出。因此,多虚拟跳检索(MVHL)需要在没有任何中间信号的情况下执行多跳检索。我将在下面讨论两个有前途的设计。首先,MVHL方法将动态确定多跳检索何时完成。我用r(di;qi,si)表示查询qi和来自源si的数据di之间的相关性得分。如果r(di;qi,si)>r(di,qi),则搜索在第i步继续−1,硅−1.∪ si);因为di带来了无法在(i)检索到的新的相关信息− 1) -第步或之前的任何步骤。其次,MVHL可以使用顺序模型而不是启发式来控制多跳搜索。搜索预计将在步骤i完成,此时检索到的数据di和输出o之间的相关性(可由BERTScore计算)(Zhang等人,2020)达到局部最大值。为了建立关系模型在该目标相关性ro(di)和检索分数r(di;qi,si)之间,一个简单的解决方案是使用固定数量的跳数K(5或10)训练仅具有输出o的多跳检索器,并使用验证集来选择最佳模型。使用该模型,我可以观察r和ro的K长度序列,并训练基于r序列中的前K个元素预测ro(dk)的RNN模型。当预测的ro减少时,搜索终止。
基于结构化知识的检索文档推理
传统的阅读器模块通常将输入查询和检索到的文档顺序连接起来,然后将它们输入到预先训练的生成模型中,例如T5。虽然令牌级别的注意力可以隐式地学习输入查询和获取到的文档之间的一些关系模式,但它没有充分利用可以提供更明确基础的结构化知识。如图3所示,输入查询中的重要实体(即Lovely Rita)和检索到的文档(即流量管理员)之间的关系信息可能需要对上下文中未明确说明的结构化知识进行推理。因此,第三种解决方案是对结构化知识(例如Wikidata)执行多跳推理,以学习输入查询和检索到的文档之间的关系模式。通过这种方式,结构化知识进一步丰富了检索文档的表示。为了对检索到的文档执行知识推理,其思想是首先提取查询文档子图,因为对整个知识图的直接推理是困难的。子图上的实体可以通过维基百科段落中给定的超链接进行映射。然后,多关系图编码器通过聚集来自其相邻节点和边缘的信息来迭代地更新56每个实体节点的表示。然后,将嵌入的节点和关系表示以及查询和文档表示融合到阅读器模型中。


