
热门标签
热门文章
- 1本地训练,立等可取,30秒音频素材复刻霉霉讲中文音色基于Bert-VITS2V2.0.2_spk2id
- 2ERROR: Unable to determine org.gradle.api.plugins.AndroidMavenPlugin argument #1: missing parameter_org.gradle.api.plugins.mavenplugin
- 3基于ChatGPT4学习大模型day1
- 4Spring Boot:简化Spring应用程序的开发_springboot如何简化开发
- 5Java基础学习: hutool之CollUtil集合操作工具类
- 6智谱AI发布国产最强大模型GLM4,理解评测与数学能力仅次于Gemini Ultra和GPT-4,编程能力超过Gemini-pro,还有对标GPTs商店的GLMs_智谱glm4
- 7【脚本语言系列】关于Python结构化文本文件处理配置文件.ini,你需要知道的事_python结构化配置文件
- 820源代码模型的数据增强方法:克隆检测、缺陷检测和修复、代码摘要、代码搜索、代码补全、代码翻译、代码问答、问题分类、方法名称预测和类型预测对论文进行分组【网安AIGC专题11.15】_漏洞检测技术的数据增强方法吗
- 9基于ERNIE3.0模型对小红书评论进行句子级情感分析_基于ernie情感分析
- 10vulnhub靶机corrosion1_vulnhub靶场下载
当前位置: article > 正文
联邦学习代码理解python_联邦学习 代码
作者:AllinToyou | 2024-04-07 17:49:56
赞
踩
联邦学习 代码
联邦学习代码理解
代码地址
https://github.com/AshwinRJ/Federated-Learning-PyTorch
实验环境
vscode , GPU , 学校实验平台远程连接ssh,配置开发环境
源代码
- federated_main.py 主函数
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import os #导入标准库os。利用其中的API 。操作系统接口模块。 import copy #拷贝库 import time #时间库 import pickle #数据持久化保存方法 import numpy as np from tqdm import tqdm #进度条模块 import torch #PyTorch库,用于深度学习任务。 from tensorboardX import SummaryWriter #PyTorch可视化,tensorboard可视化方法,SummaryWriter实例 from options import args_parser #解析参数 from update import LocalUpdate, test_inference #参数更新,本地模型参数更新, from models import MLP, CNNMnist, CNNFashion_Mnist, CNNCifar #模型设置 from utils import get_dataset, average_weights, exp_details #应用集,工具函数 if __name__ == '__main__': start_time = time.time() #开始时间 # define paths path_project = os.path.abspath('..') #获取上层目录的完整路径。 logger = SummaryWriter('../logs') #python可视化工具,SummaryWriter一般是用来记录训练过程中的学习率和损失函数的变化 args = args_parser() #输入命令行参数 # 有改动 # if args.gpu_id: # torch.cuda.set_device(args.gpu_id) # device = 'cuda' if args.gpu else 'cpu' #判断GPU是否可用: device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # load dataset and user groups # 加载数据集,用户本地数据字典 train_dataset, test_dataset, user_groups = get_dataset(args) # BUILD MODEL 建立模型 if args.model == 'cnn': # Convolutional neural netork 卷积神经网络 if args.dataset == 'mnist': global_model = CNNMnist(args=args) elif args.dataset == 'fmnist': global_model = CNNFashion_Mnist(args=args) elif args.dataset == 'cifar': global_model = CNNCifar(args=args) elif args.model == 'mlp': # Multi-layer preceptron 多层感知机 img_size = train_dataset[0][0].shape len_in = 1 for x in img_size: len_in *= x global_model = MLP(dim_in=len_in, dim_hidden=64, dim_out=args.num_classes) else: exit('Error: unrecognized model') # Set the model to train and send it to device.#设置模型进行训练,并传输给计算设备 global_model.to(device) global_model.train() print(global_model) # copy weights 复制权重 global_weights = global_model.state_dict() # Training 开始训练 train_loss, train_accuracy = [], [] #损失函数,准确率 val_acc_list, net_list = [], [] cv_loss, cv_acc = [], [] print_every = 2 val_loss_pre, counter = 0, 0 for epoch in tqdm(range(args.epochs)): #tqdm是一个功能强大的,快速,可扩展的Python进度条,支持在for循环中展示运行时间和进度 local_weights, local_losses = [], [] #本地模型权重,损失函数 print(f'\n | Global Training Round : {epoch+1} |\n') global_model.train() #将模型设置为训练模式 m = max(int(args.frac * args.num_users), 1) idxs_users = np.random.choice(range(args.num_users), m, replace=False) #随机选取用户的索引列表 #执行本地更新 for idx in idxs_users: local_model = LocalUpdate(args=args, dataset=train_dataset, idxs=user_groups[idx], logger=logger) w, loss = local_model.update_weights( model=copy.deepcopy(global_model), global_round=epoch) local_weights.append(copy.deepcopy(w)) #深拷贝 local_losses.append(copy.deepcopy(loss)) #深拷贝 # update global weights 联邦平均,更新全局权重 global_weights = average_weights(local_weights) # update global weights 将更新后的全局权重载入模型 global_model.load_state_dict(global_weights) loss_avg = sum(local_losses) / len(local_losses) train_loss.append(loss_avg) # Calculate avg training accuracy over all users at every epoch 每轮训练,都要计算所有用户的平均训练精度 list_acc, list_loss = [], [] global_model.eval() for c in range(args.num_users): local_model = LocalUpdate(args=args, dataset=train_dataset, idxs=user_groups[idx], logger=logger) acc, loss = local_model.inference(model=global_model) list_acc.append(acc) list_loss.append(loss) train_accuracy.append(sum(list_acc)/len(list_acc)) # print global training loss after every 'i' rounds 每i轮打印全局Loss if (epoch+1) % print_every == 0: print(f' \nAvg Training Stats after {epoch+1} global rounds:') print(f'Training Loss : {np.mean(np.array(train_loss))}') print('Train Accuracy: {:.2f}% \n'.format(100*train_accuracy[-1])) # Test inference after completion of training 训练后,测试模型在测试集的表现 test_acc, test_loss = test_inference(args, global_model, test_dataset) print(f' \n Results after {args.epochs} global rounds of training:') print("|---- Avg Train Accuracy: {:.2f}%".format(100*train_accuracy[-1])) print("|---- Test Accuracy: {:.2f}%".format(100*test_acc)) # Saving the objects train_loss and train_accuracy: 保存目标训练损失和训练精度 file_name = '../save/objects/{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}].pkl'.\ #pkl文件 format(args.dataset, args.model, args.epochs, args.frac, args.iid, args.local_ep, args.local_bs) with open(file_name, 'wb') as f: pickle.dump([train_loss, train_accuracy], f) #文件写入,保存Loss和Accuracy print('\n Total Run Time: {0:0.4f}'.format(time.time()-start_time)) #显示运行时间 # PLOTTING (optional) 画图 # import matplotlib # import matplotlib.pyplot as plt # matplotlib.use('Agg') # Plot Loss curve 绘制损失曲线 # plt.figure() # plt.title('Training Loss vs Communication rounds') # plt.plot(range(len(train_loss)), train_loss, color='r') # plt.ylabel('Training loss') # plt.xlabel('Communication Rounds') # plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_loss.png'. # format(args.dataset, args.model, args.epochs, args.frac, # args.iid, args.local_ep, args.local_bs)) # # # Plot Average Accuracy vs Communication rounds 平均准度曲线vs通信回合数 # plt.figure() # plt.title('Average Accuracy vs Communication rounds') # plt.plot(range(len(train_accuracy)), train_accuracy, color='k') # plt.ylabel('Average Accuracy') # plt.xlabel('Communication Rounds') # plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_acc.png'. # format(args.dataset, args.model, args.epochs, args.frac, # args.iid, args.local_ep, args.local_bs))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- baseline_main.py 这个好像没啥用
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import os from tqdm import tqdm import matplotlib.pyplot as plt import torch from torch.utils.data import DataLoader from utils import get_dataset from options import args_parser from update import test_inference from models import MLP, CNNMnist, CNNFashion_Mnist, CNNCifar if __name__ == '__main__': args = args_parser() if args.gpu: # torch.cuda.set_device(args.gpu)有改动 torch.cuda.set_device(int(args.gpu)) device = 'cuda' if args.gpu else 'cpu' # load datasets train_dataset, test_dataset, _ = get_dataset(args) # BUILD MODEL if args.model == 'cnn': # Convolutional neural netork if args.dataset == 'mnist': global_model = CNNMnist(args=args) elif args.dataset == 'fmnist': global_model = CNNFashion_Mnist(args=args) elif args.dataset == 'cifar': global_model = CNNCifar(args=args) elif args.model == 'mlp': # Multi-layer preceptron img_size = train_dataset[0][0].shape len_in = 1 for x in img_size: len_in *= x global_model = MLP(dim_in=len_in, dim_hidden=64, dim_out=args.num_classes) else: exit('Error: unrecognized model') # Set the model to train and send it to device. global_model.to(device) global_model.train() print(global_model) # Training # Set optimizer and criterion 设置优化器和准则 if args.optimizer == 'sgd': optimizer = torch.optim.SGD(global_model.parameters(), lr=args.lr, momentum=0.5) elif args.optimizer == 'adam': optimizer = torch.optim.Adam(global_model.parameters(), lr=args.lr, weight_decay=1e-4) trainloader = DataLoader(train_dataset, batch_size=64, shuffle=True) criterion = torch.nn.NLLLoss().to(device) epoch_loss = [] for epoch in tqdm(range(args.epochs)): batch_loss = [] for batch_idx, (images, labels) in enumerate(trainloader): images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = global_model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() if batch_idx % 50 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch+1, batch_idx * len(images), len(trainloader.dataset), 100. * batch_idx / len(trainloader), loss.item())) batch_loss.append(loss.item()) loss_avg = sum(batch_loss)/len(batch_loss) print('\nTrain loss:', loss_avg) epoch_loss.append(loss_avg) # Plot loss plt.figure() plt.plot(range(len(epoch_loss)), epoch_loss) plt.xlabel('epochs') plt.ylabel('Train loss') # plt.savefig('../save/nn_{}_{}_{}.png'.format(args.dataset, args.model, # args.epochs)) # 确保目录存在,如果不存在则创建 save_dir = '../save/' if not os.path.exists(save_dir): os.makedirs(save_dir) # 保存图像 plt.savefig(os.path.join(save_dir, 'nn_{}_{}_{}.png'.format(args.dataset, args.model, args.epochs))) # testing test_acc, test_loss = test_inference(args, global_model, test_dataset) print('Test on', len(test_dataset), 'samples') print("Test Accuracy: {:.2f}%".format(100*test_acc))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- models.py 模型设置
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 from torch import nn import torch.nn.functional as F #MLP多层感知器模型 class MLP(nn.Module): def __init__(self, dim_in, dim_hidden, dim_out): super(MLP, self).__init__() self.layer_input = nn.Linear(dim_in, dim_hidden) #输入层 self.relu = nn.ReLU() #relu函数 self.dropout = nn.Dropout() #Dropout方法 self.layer_hidden = nn.Linear(dim_hidden, dim_out) #隐藏层 self.softmax = nn.Softmax(dim=1) #softmax全连接层 def forward(self, x): x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1]) x = self.layer_input(x) x = self.dropout(x) x = self.relu(x) x = self.layer_hidden(x) return self.softmax(x) #CNN卷积神经网络Mnist数据集 class CNNMnist(nn.Module): def __init__(self, args): super(CNNMnist, self).__init__() self.conv1 = nn.Conv2d(args.num_channels, 10, kernel_size=5) #conv2d二维数据 self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) #连接 self.fc2 = nn.Linear(50, args.num_classes) def forward(self, x): x = F.relu(F.max_pool2d(self.conv1(x), 2)) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = x.view(-1, x.shape[1]*x.shape[2]*x.shape[3]) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) return F.log_softmax(x, dim=1) #CNN卷积神经网络Fashion_Mnist数据集 class CNNFashion_Mnist(nn.Module): def __init__(self, args): super(CNNFashion_Mnist, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(2)) self.fc = nn.Linear(7*7*32, 10) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.view(out.size(0), -1) out = self.fc(out) return out #CNN卷积神经网络Cifa数据集 class CNNCifar(nn.Module): def __init__(self, args): super(CNNCifar, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) #卷积层 self.pool = nn.MaxPool2d(2, 2) #池化层 self.conv2 = nn.Conv2d(6, 16, 5) #卷积层 self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, args.num_classes) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return F.log_softmax(x, dim=1) #模型C class modelC(nn.Module): def __init__(self, input_size, n_classes=10, **kwargs): super(AllConvNet, self).__init__() self.conv1 = nn.Conv2d(input_size, 96, 3, padding=1) self.conv2 = nn.Conv2d(96, 96, 3, padding=1) self.conv3 = nn.Conv2d(96, 96, 3, padding=1, stride=2) self.conv4 = nn.Conv2d(96, 192, 3, padding=1) self.conv5 = nn.Conv2d(192, 192, 3, padding=1) self.conv6 = nn.Conv2d(192, 192, 3, padding=1, stride=2) self.conv7 = nn.Conv2d(192, 192, 3, padding=1) self.conv8 = nn.Conv2d(192, 192, 1) self.class_conv = nn.Conv2d(192, n_classes, 1) def forward(self, x): x_drop = F.dropout(x, .2) conv1_out = F.relu(self.conv1(x_drop)) conv2_out = F.relu(self.conv2(conv1_out)) conv3_out = F.relu(self.conv3(conv2_out)) conv3_out_drop = F.dropout(conv3_out, .5) conv4_out = F.relu(self.conv4(conv3_out_drop)) conv5_out = F.relu(self.conv5(conv4_out)) conv6_out = F.relu(self.conv6(conv5_out)) conv6_out_drop = F.dropout(conv6_out, .5) conv7_out = F.relu(self.conv7(conv6_out_drop)) conv8_out = F.relu(self.conv8(conv7_out)) class_out = F.relu(self.class_conv(conv8_out)) pool_out = F.adaptive_avg_pool2d(class_out, 1) pool_out.squeeze_(-1) pool_out.squeeze_(-1) return pool_out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- options.py 参数设置
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import argparse #联邦参数,模型参数,其他参数 def args_parser(): parser = argparse.ArgumentParser() # federated arguments (Notation for the arguments followed from paper) #联邦参数: parser.add_argument('--epochs', type=int, default=10, help="number of rounds of training") #epochs:训练轮数,10 parser.add_argument('--num_users', type=int, default=100, help="number of users: K") #num_users:用户数量K,默认100 parser.add_argument('--frac', type=float, default=0.1, help='the fraction of clients: C') #frac:用户选取比例C,默认0.1 parser.add_argument('--local_ep', type=int, default=10, help="the number of local epochs: E") #local_ep:本地训练数量E,默认10 parser.add_argument('--local_bs', type=int, default=10, help="local batch size: B") #local_bs:本地训练批量B,默认10 parser.add_argument('--lr', type=float, default=0.01, help='learning rate') #lr:学习率,默认0.01 parser.add_argument('--momentum', type=float, default=0.5, help='SGD momentum (default: 0.5)') #momentum:SGD动量,默认0.5 # model arguments模型参数: parser.add_argument('--model', type=str, default='mlp', help='model name') #model:模型名称,默认mlp,即全连接神经网络 parser.add_argument('--kernel_num', type=int, default=9, help='number of each kind of kernel') #kernel_num:卷积核数量,默认9个 parser.add_argument('--kernel_sizes', type=str, default='3,4,5', help='comma-separated kernel size to \ use for convolution') #kernel_sizes:卷积核大小,默认3,4,5 parser.add_argument('--num_channels', type=int, default=1, help="number \ of channels of imgs") #num_channels:图像通道数,默认1 parser.add_argument('--norm', type=str, default='batch_norm', help="batch_norm, layer_norm, or None") #norm:归一化方式,可以是BN和LN parser.add_argument('--num_filters', type=int, default=32, help="number of filters for conv nets -- 32 for \ mini-imagenet, 64 for omiglot.") #num_filters:过滤器数量,默认32 parser.add_argument('--max_pool', type=str, default='True', help="Whether use max pooling rather than \ strided convolutions") #max_pool:最大池化,默认为True # other arguments其他设置: parser.add_argument('--dataset', type=str, default='mnist', help="name \ of dataset") #dataset:选择什么数据集,默认mnist parser.add_argument('--num_classes', type=int, default=10, help="number \ of classes") #num_class:分类数量,默认10 parser.add_argument('--gpu', default=None, help="To use cuda, set \ to a specific GPU ID. Default set to use CPU.") #gpu:默认使用,可以填入具体cuda编号 parser.add_argument('--optimizer', type=str, default='sgd', help="type \ of optimizer") #optimizer:优化器,默认是SGD算法 parser.add_argument('--iid', type=int, default=1, help='Default set to IID. Set to 0 for non-IID.') #iid:独立同分布,默认是1,即是独立同分布 parser.add_argument('--unequal', type=int, default=0, help='whether to use unequal data splits for \ non-i.i.d setting (use 0 for equal splits)') #unequal:是否平均分配数据集,默认0,即是 parser.add_argument('--stopping_rounds', type=int, default=10, help='rounds of early stopping') #stopping_rounds:停止轮数,默认是10 parser.add_argument('--verbose', type=int, default=1, help='verbose') #verbose:日志显示,0不输出,1输出带进度条的日志,2输出不带进度条的日志 parser.add_argument('--seed', type=int, default=1, help='random seed') #seed: 随机数种子,默认1 args = parser.parse_args() return args
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- sampling.py 采集IID和非IID的数据
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import numpy as np from torchvision import datasets, transforms #采集mnist_iid def mnist_iid(dataset, num_users): """ Sample I.I.D. client data from MNIST dataset :param dataset: :param num_users: :return: dict of image index """ num_items = int(len(dataset)/num_users) dict_users, all_idxs = {}, [i for i in range(len(dataset))] for i in range(num_users): dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False)) all_idxs = list(set(all_idxs) - dict_users[i]) return dict_users #采集mnist_noniid def mnist_noniid(dataset, num_users): """ Sample non-I.I.D client data from MNIST dataset :param dataset: :param num_users: :return: """ # 60,000 training imgs --> 200 imgs/shard X 300 shards num_shards, num_imgs = 200, 300 idx_shard = [i for i in range(num_shards)] dict_users = {i: np.array([]) for i in range(num_users)} idxs = np.arange(num_shards*num_imgs) labels = dataset.train_labels.numpy() # sort labels idxs_labels = np.vstack((idxs, labels)) idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()] idxs = idxs_labels[0, :] # divide and assign 2 shards/client for i in range(num_users): rand_set = set(np.random.choice(idx_shard, 2, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[i] = np.concatenate( (dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) return dict_users #采集mnist_noniid_unequal def mnist_noniid_unequal(dataset, num_users): """ Sample non-I.I.D client data from MNIST dataset s.t clients have unequal amount of data :param dataset: :param num_users: :returns a dict of clients with each clients assigned certain number of training imgs """ # 60,000 training imgs --> 50 imgs/shard X 1200 shards num_shards, num_imgs = 1200, 50 idx_shard = [i for i in range(num_shards)] dict_users = {i: np.array([]) for i in range(num_users)} idxs = np.arange(num_shards*num_imgs) labels = dataset.train_labels.numpy() # sort labels idxs_labels = np.vstack((idxs, labels)) idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()] idxs = idxs_labels[0, :] # Minimum and maximum shards assigned per client: min_shard = 1 max_shard = 30 # Divide the shards into random chunks for every client # s.t the sum of these chunks = num_shards random_shard_size = np.random.randint(min_shard, max_shard+1, size=num_users) random_shard_size = np.around(random_shard_size / sum(random_shard_size) * num_shards) random_shard_size = random_shard_size.astype(int) # Assign the shards randomly to each client if sum(random_shard_size) > num_shards: for i in range(num_users): # First assign each client 1 shard to ensure every client has # atleast one shard of data rand_set = set(np.random.choice(idx_shard, 1, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[i] = np.concatenate( (dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) random_shard_size = random_shard_size-1 # Next, randomly assign the remaining shards for i in range(num_users): if len(idx_shard) == 0: continue shard_size = random_shard_size[i] if shard_size > len(idx_shard): shard_size = len(idx_shard) rand_set = set(np.random.choice(idx_shard, shard_size, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[i] = np.concatenate( (dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) else: for i in range(num_users): shard_size = random_shard_size[i] rand_set = set(np.random.choice(idx_shard, shard_size, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[i] = np.concatenate( (dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) if len(idx_shard) > 0: # Add the leftover shards to the client with minimum images: shard_size = len(idx_shard) # Add the remaining shard to the client with lowest data k = min(dict_users, key=lambda x: len(dict_users.get(x))) rand_set = set(np.random.choice(idx_shard, shard_size, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[k] = np.concatenate( (dict_users[k], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) return dict_users #采集cifar_iid def cifar_iid(dataset, num_users): """ Sample I.I.D. client data from CIFAR10 dataset :param dataset: :param num_users: :return: dict of image index """ num_items = int(len(dataset)/num_users) dict_users, all_idxs = {}, [i for i in range(len(dataset))] for i in range(num_users): dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False)) all_idxs = list(set(all_idxs) - dict_users[i]) return dict_users #采集cifar_noniid def cifar_noniid(dataset, num_users): """ Sample non-I.I.D client data from CIFAR10 dataset :param dataset: :param num_users: :return: """ num_shards, num_imgs = 200, 250 idx_shard = [i for i in range(num_shards)] dict_users = {i: np.array([]) for i in range(num_users)} idxs = np.arange(num_shards*num_imgs) # labels = dataset.train_labels.numpy() # labels = np.array(dataset.train_labels)有改动 labels = np.array(dataset.targets) # sort labels idxs_labels = np.vstack((idxs, labels)) idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()] idxs = idxs_labels[0, :] # divide and assign for i in range(num_users): rand_set = set(np.random.choice(idx_shard, 2, replace=False)) idx_shard = list(set(idx_shard) - rand_set) for rand in rand_set: dict_users[i] = np.concatenate( (dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0) return dict_users if __name__ == '__main__': dataset_train = datasets.MNIST('./data/mnist/', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])) num = 100 d = mnist_noniid(dataset_train, num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- update.py 本地模型参数更新
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import torch from torch import nn from torch.utils.data import DataLoader, Dataset class DatasetSplit(Dataset): ##使用dataset重构 """An abstract Dataset class wrapped around Pytorch Dataset class. 一个抽象的数据集类,封装在Pytorch数据集类中。 """ def __init__(self, dataset, idxs): self.dataset = dataset self.idxs = [int(i) for i in idxs] def __len__(self): #__len__函数。返回数据列表长度,即数据集的样本数量 return len(self.idxs) def __getitem__(self, item): #__getitem__函数。通过dataset读取图像数据,最后返回下标为item的图像数据和标签的张量。 image, label = self.dataset[self.idxs[item]] return torch.tensor(image), torch.tensor(label) #torch.tensor() #转换为张量形式,且会拷贝data #本地更新模型构建模块 class LocalUpdate(object): def __init__(self, args, dataset, idxs, logger): self.args = args self.logger = logger self.trainloader, self.validloader, self.testloader = self.train_val_test( dataset, list(idxs)) #划分数据集 self.device = 'cuda' if args.gpu else 'cpu' #判断GPU是否可用 # Default criterion set to NLL loss function默认条件设置为NLL损失函数 self.criterion = nn.NLLLoss().to(self.device) #交叉熵损失函数,用于描述系统的混乱程度,值越小,与真实样本越接近 def train_val_test(self, dataset, idxs): """ Returns train, validation and test dataloaders for a given dataset and user indexes. 返回给定数据集的训练、验证和测试数据加载器,还有用户索引。 """ # split indexes for train, validation, and test (80, 10, 10) idxs_train = idxs[:int(0.8*len(idxs))] idxs_val = idxs[int(0.8*len(idxs)):int(0.9*len(idxs))] idxs_test = idxs[int(0.9*len(idxs)):] trainloader = DataLoader(DatasetSplit(dataset, idxs_train), batch_size=self.args.local_bs, shuffle=True) validloader = DataLoader(DatasetSplit(dataset, idxs_val), batch_size=int(len(idxs_val)/10), shuffle=False) testloader = DataLoader(DatasetSplit(dataset, idxs_test), batch_size=int(len(idxs_test)/10), shuffle=False) return trainloader, validloader, testloader #本地权重更新 def update_weights(self, model, global_round): # Set mode to train model设置模式为训练模式 model.train() epoch_loss = [] # Set optimizer for the local updates为本地更新设置优化器 if self.args.optimizer == 'sgd': optimizer = torch.optim.SGD(model.parameters(), lr=self.args.lr, momentum=0.5) #使用SGD作为优化器 elif self.args.optimizer == 'adam': optimizer = torch.optim.Adam(model.parameters(), lr=self.args.lr, weight_decay=1e-4) #使用Adam作为优化器 for iter in range(self.args.local_ep): batch_loss = [] for batch_idx, (images, labels) in enumerate(self.trainloader): images, labels = images.to(self.device), labels.to(self.device) model.zero_grad() #梯度清零 log_probs = model(images) loss = self.criterion(log_probs, labels) loss.backward() #反向传播梯度计算 optimizer.step() #更新参数 if self.args.verbose and (batch_idx % 10 == 0): print('| Global Round : {} | Local Epoch : {} | [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( global_round, iter, batch_idx * len(images), len(self.trainloader.dataset), 100. * batch_idx / len(self.trainloader), loss.item())) self.logger.add_scalar('loss', loss.item()) #保存程序中的数据,然后利用tensorboard工具来进行可视化的 batch_loss.append(loss.item()) #每经过一次本地轮次,统计当前的loss,用于最后的平均损失统计 epoch_loss.append(sum(batch_loss)/len(batch_loss)) return model.state_dict(), sum(epoch_loss) / len(epoch_loss) #model.state_dict()是Pytorch中用于查看网络参数的方法,可以用torch.save()保存成pth文件 #评估函数 def inference(self, model): """ Returns the inference accuracy and loss. 返回推理精度和损失。 """ model.eval() #不改变权值样本训练。开启模型的评估模式 loss, total, correct = 0.0, 0.0, 0.0 for batch_idx, (images, labels) in enumerate(self.testloader): images, labels = images.to(self.device), labels.to(self.device) # Inference outputs = model(images) batch_loss = self.criterion(outputs, labels) loss += batch_loss.item() # Prediction _, pred_labels = torch.max(outputs, 1) #返回输入tensor中所有元素的最大值 pred_labels = pred_labels.view(-1) #view函数的作用为重构张量的维度,相当于numpy中resize()的功能 correct += torch.sum(torch.eq(pred_labels, labels)).item() total += len(labels) accuracy = correct/total return accuracy, loss def test_inference(args, model, test_dataset): """ Returns the test accuracy and loss. """ model.eval() loss, total, correct = 0.0, 0.0, 0.0 device = 'cuda' if args.gpu else 'cpu' criterion = nn.NLLLoss().to(device) testloader = DataLoader(test_dataset, batch_size=128, shuffle=False) for batch_idx, (images, labels) in enumerate(testloader): images, labels = images.to(device), labels.to(device) # Inference outputs = model(images) batch_loss = criterion(outputs, labels) loss += batch_loss.item() # Prediction _, pred_labels = torch.max(outputs, 1) pred_labels = pred_labels.view(-1) correct += torch.sum(torch.eq(pred_labels, labels)).item() total += len(labels) accuracy = correct/total return accuracy, loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- utils.py 应用集
#!/usr/bin/env python # -*- coding: utf-8 -*- # Python version: 3.6 import copy import torch from torchvision import datasets, transforms from sampling import mnist_iid, mnist_noniid, mnist_noniid_unequal from sampling import cifar_iid, cifar_noniid #根据命令台参数获取相应的数据集和用户数据字典。获取数据集 def get_dataset(args): """ Returns train and test datasets and a user group which is a dict where the keys are the user index and the values are the corresponding data for each of those users. 返回训练和测试数据集以及用户组,用户组是字典,其中键是用户索引,值是对应的数据每一个用户。 """ if args.dataset == 'cifar': data_dir = '../data/cifar/' apply_transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) #transforms.Compose()把多个步骤融合到一起 #ToTensor()能够把灰度范围从0-255变换到0-1之间 #而后面的transform.Normalize()则把0-1变换到(-1,1) train_dataset = datasets.CIFAR10(data_dir, train=True, download=True, transform=apply_transform) test_dataset = datasets.CIFAR10(data_dir, train=False, download=True, transform=apply_transform) # sample training data amongst users在用户中采集训练数据 if args.iid: # Sample IID user data from Mnist从Mnist中采集IID用户数据 user_groups = cifar_iid(train_dataset, args.num_users) else: # Sample Non-IID user data from Mnist从Mnist中采集Non-IID用户数据 if args.unequal: # Chose uneuqal splits for every user每个用户选择不平等划分 raise NotImplementedError() else: # Chose euqal splits for every user每个用户选择不平等划分 user_groups = cifar_noniid(train_dataset, args.num_users) elif args.dataset == 'mnist' or 'fmnist': if args.dataset == 'mnist': data_dir = '../data/mnist/' else: data_dir = '../data/fmnist/' apply_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(data_dir, train=True, download=True, transform=apply_transform) test_dataset = datasets.MNIST(data_dir, train=False, download=True, transform=apply_transform) # sample training data amongst users if args.iid: # Sample IID user data from Mnist user_groups = mnist_iid(train_dataset, args.num_users) else: # Sample Non-IID user data from Mnist if args.unequal: # Chose uneuqal splits for every user user_groups = mnist_noniid_unequal(train_dataset, args.num_users) else: # Chose euqal splits for every user user_groups = mnist_noniid(train_dataset, args.num_users) return train_dataset, test_dataset, user_groups #权重取平均 def average_weights(w): """ Returns the average of the weights.返回权重的平均值 """ w_avg = copy.deepcopy(w[0]) #深拷贝,就是从输入变量完全复刻一个相同的变量,无论怎么改变新变量,原有变量的值都不会受到影响。 for key in w_avg.keys(): for i in range(1, len(w)): w_avg[key] += w[i][key] w_avg[key] = torch.div(w_avg[key], len(w)) return w_avg #细节输出 def exp_details(args): print('\nExperimental details:') print(f' Model : {args.model}') print(f' Optimizer : {args.optimizer}') print(f' Learning : {args.lr}') print(f' Global Rounds : {args.epochs}\n') print(' Federated parameters:') if args.iid: print(' IID') else: print(' Non-IID') print(f' Fraction of users : {args.frac}') print(f' Local Batch size : {args.local_bs}') print(f' Local Epochs : {args.local_ep}\n') return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
代码运行结果
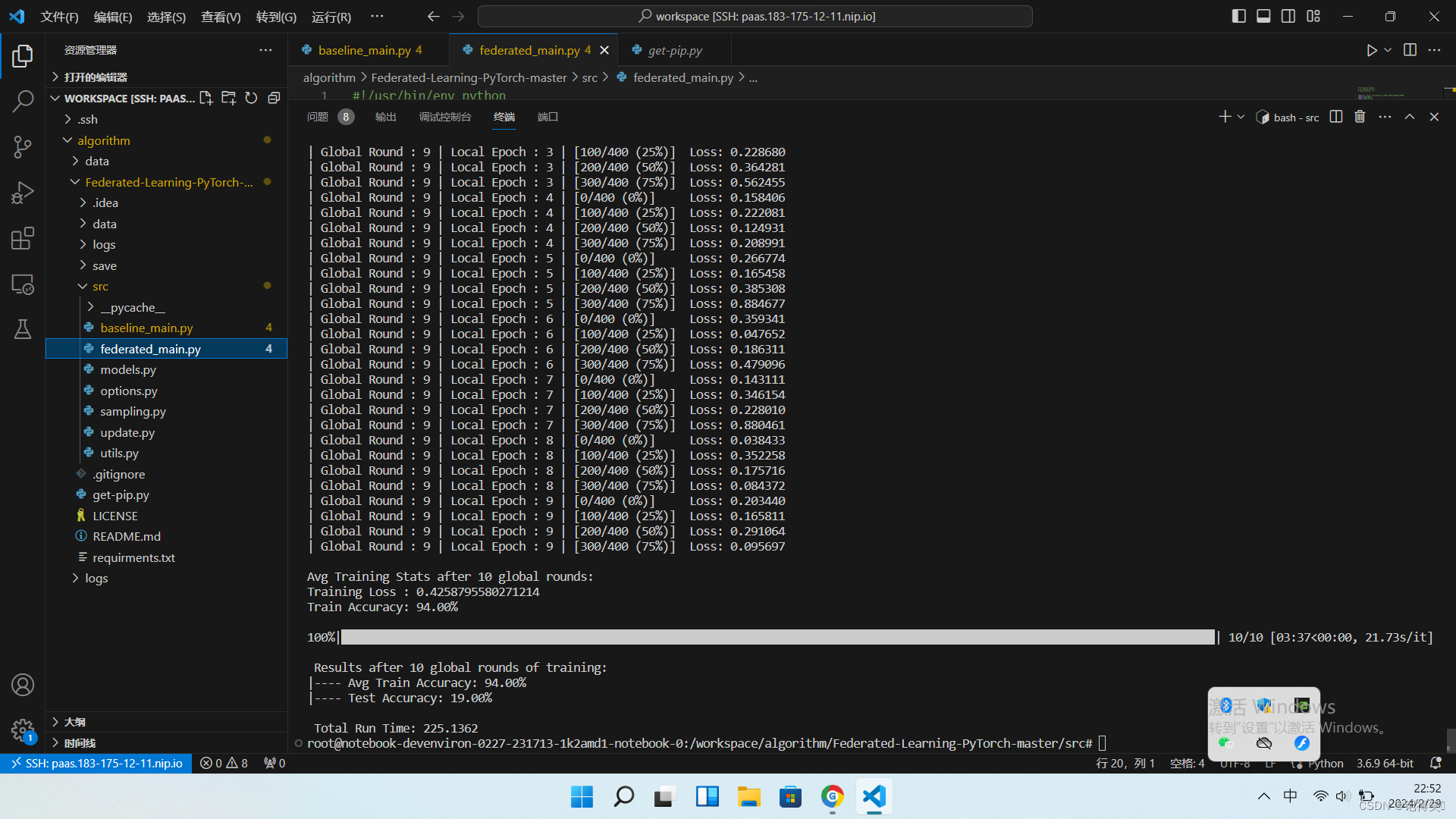
运行命令
#镜像
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
- 1
- 2
#安装包
pip install numpy
pip install tqdm
pip install torch
pip install tensorboardX
pip install torchvision
pip install torch==1.7.1 torchvision==0.8.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
#运行程序
python federated_main.py --model=cnn --dataset=cifar --gpu=0 --iid=1 --epochs=1
python federated_main.py --model=cnn --dataset=cifar --gpu=0 --iid=0 --epochs=1
python federated_main.py --model=cnn --dataset=cifar --gpu=0 --iid=1 --epochs=10
python federated_main.py --model=cnn --dataset=cifar --gpu=0 --iid=0 --epochs=10
- 1
- 2
- 3
- 4
- 5
注:本人学习过程记录,如有问题,请联系指正!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/379840
推荐阅读

相关标签

