
- 1eNSP基础常用命令_ensp配置命令大全
- 2【翻译CMSIS_RTOS2 API v2】鸿蒙CMSIS-RTOS2接口之任务(线程)管理_osprioritynormal
- 3企业指标体系的落地与推广:让指标体系真正发挥作用
- 4Android emulator无法启动的解决方法_没都会弹 android emulator closed unexpectedly
- 5langchin-chatchat部分开发笔记(持续更新)
- 6STM32驱动安信可RD-03D实现不同角度点亮不同LED灯
- 7java坦克大战 实训报告_坦克大战系统《Java程序开发实训》综合实训报告.doc
- 8MySQL出现too many connections错误_mysql too many connections
- 9linux下ping命令使用,ARP协议与SNMP协议_/proc/net/arp
- 10时序预测 | MATLAB实现BP神经网络时间序列预测_matlab神经网络时间序列
数据采集的基本原理_数据采集技术原理
赞
踩
爬虫基本原理
爬虫是 模拟用户在浏览器或者App应用上的操作,把操作的过程、实现自动化的程序
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入https://www.baidu.com
简单来说这段过程发生了以下四个步骤:
- 查找域名对应的IP地址。
浏览器首先访问的是DNS(Domain Name System,域名系统),dns的主要工作就是把域名转换成相应的IP地址 - 向IP对应的服务器发送请求。
- 服务器响应请求,发回网页内容。
- 浏览器显示网页内容
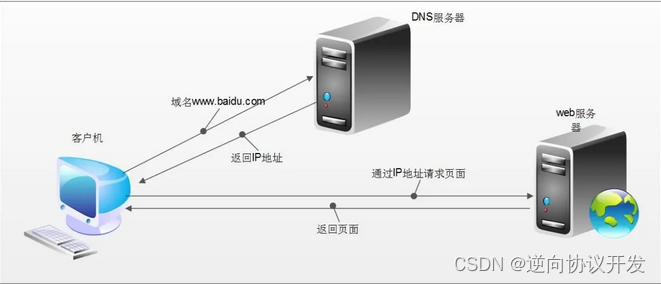
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
(1).浏览器是如何发送和接收这个数据呢?
HTTP协议(HyperText Transfer Protocol,超文本传输协议)目的是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。
(2).爬虫基本思路
- (1).通过URL或者文件获取网页,
- (2).分析要爬取的目标内容所在的位置
- (3).用元素选择器(re、BeautifulSoup、Xpath等)快速提取(Raw)目标内容
- (4).处理提取出来的目标内容 (通常整理合成一个 Json)
- (5).存储处理好的目标内容(比如放到 MongoDB、MySQL 之类的数据库,或者写进文件里.)
1.静态本地网页与json文件爬取演示
(1).html网页抓取
- import urllib.request as re
- from bs4 import BeautifulSoup
- # 1.使用urllib的request模块,打开一个带有html页面的链接,此时获取的只是一个链接对象
- response = re.urlopen("file:///D:/Project/Python/jyputerTest/Spider/Source/demo01.html")
- # 2.从连接对象中将网页源代码字符串获取到,此时是没有经过格式化的
- html = response.read()
- # 3.通过 BeautifulSoup 对网页源代码字符串进行解析
- soup = BeautifulSoup(html)
- # 4.我们就可以从BeautifulSoup中直接使用标签名作为参数 去直接获取对应 标签 中的数据
- soup.find('tr')
- soup.find_all('tr')
(2).json数据读取
- import urllib.request as re
- # 此时我们解析json使用的模版是json
- import json
-
- # 1.同样此时获取我们文件的连接
- response = re.urlopen("file:///D:/Project/Python/jyputerTest/Spider/Source/demo02.json")
- # 2.将连接中的数据读取为源字符串
- jsonString = response.read()
- # 3.加载数据为json,同时对读取到的json字符串做一个解码
- jsonObject = json.loads(jsonString.decode())
- # 4.对json中的数据进行值的获取(分不同的层级)
- jsonObject['employees'] # 根路径
- jsonObject['employees'][0] # 获取列表中的第一个元素
- jsonObject['employees'][0]['firstName'] # 获取字典中指定的key对应的值(value)
2.爬虫实战:7日天气预报 爬取
本次实战主要是使用 request库 和 BeautifulSoup 库进行数据的爬取
(1).实战原理
1),Requests 简介
request库是一个非常好用的请求发送包,它可以自动封装底层python 的网络请求。
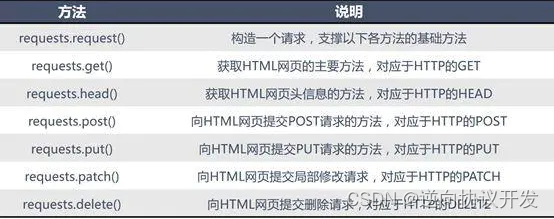
其中我们本次课程中是使用的:Requests.get()方法
Requests库的get()方法主要用于获取HTML网页,相当于HTTP的GET。其返回对象response的常用属性如下表所示,我们可通过这些属性获取要访问域名的基本信息。
2),BeautifulSoup 简介
BeautifulSoup库是用Python语言编写一个HTML/XML的解释器。它可以很好地处理不规范的标记并生成剖析树,其本身提供了简单又常用的导航、搜索以及修改剖析树的操作,利用它可以大大缩减编程时间。
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
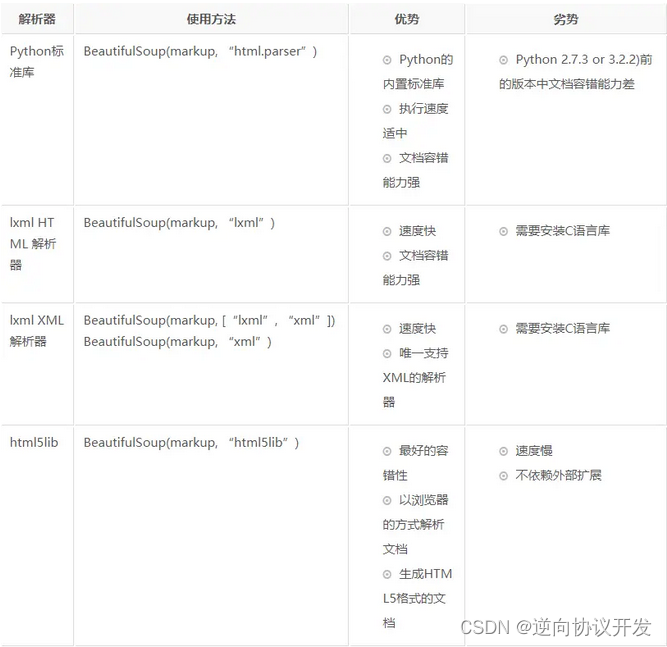
3),网页信息查找与提取
我们使用Chrome浏览器,对于要爬取的网页,可以按F12进入调试模式,也可以选择相应信息右键"检查",亦可进入调试模式,而且直接到达该信息HTML位置,更为方便。
(2).实战代码
- # 导入requests模块和bs4模块
- import requests
- from bs4 import BeautifulSoup
-
- # 加入请求头,防止网站监测出来我们是爬虫,所以都必须要引入请求;对于有需要 登录 的页面需要加上cookices,那么直接在header字典中将 " 'Cookie': '你的cookie' "添加进去
- header={
- "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
- }
- # 引入要爬取的网页的url
- url = 'http://www.weather.com.cn/weather/101120101.shtml'
-
- # 1、获取网页的响应
- # url,请求头,设置
- response = requests.get(url, headers=header,timeout=30)
- # 2,当网页获取成功的之后,设置网页的编码格式,方式出现中文的乱码
- response.encoding='utf-8'
-
- # 3,从获取到的文本连接中获取对应的网页源代码字符串
- data= response.text
- # print(text)
-
- # 4,通过 BeautifulSoup 对网页源代码字符串进行解析;第二个参数是:指定 BeautifulSoup 使用什么格式进行解析(这里使用的是lxml :在你安装BeautifulSoup的时候默认是没有这个库的,需要你手动去安装 pip install lxml)
- soup = BeautifulSoup(data,'lxml')
- # print(soup)
-
- # find()的作用是只去找 指定样式中 第一个出现的
- ul = soup.find(class_='t clearfix')
- # print(ul)
-
- ul_li = ul.find_all('li')
- # 遍历打印所有的元素
- for item in ul_li:
- # print(item)
- # 根据标签获取值
- # 1.获取当前日期
- day = item.find('h1').text
- # 2.获取当前日期下对应的天气
- wea = item.find(class_='wea').text
- # 3.获取当前日期下对应温度区间
- tem = item.find(class_='tem').text
- # 如果想获取最低气温(可以直接使用下标的方式直接去处理温度区间中的值)
- # print(tem[4:])
- # 4.取风向,使用find函数默认是在item中取第一次出现的em标签;对应的可以直接再去取span标签的值,就直接用“.标签案名”的方式进行获取
- ws = item.find('em').span.attrs['title']
- # 5.把两个风向都取出来的话,可以使用findall,此时先把所有的带有风向的span标签获取出来
- ws_all_span = item.find('em').find_all('span')
- # 使用 推导式 的方式将所有风向获取出来,并返回一个列表
- ws_all = [ws['title'] for ws in ws_all_span]
- # 6.获取风力,先拿到class,再拿到对应的i,对应的文本,然后将 "<" 做一个替换 "小于"
- win = item.find(class_='win').i.text.replace("<","小于")
-
- print('-----------------------------begin---------------------------------------------------------------------')
- print('-----------------------------1:日期-----------------------------------------------------------------')
- print(day)
- print('-----------------------------2:天气-----------------------------------------------------------------')
- print(wea)
- print('-----------------------------3:温度-----------------------------------------------------------------')
- print(tem)
- print('-----------------------------4:只获取第一个风向-----------------------------------------------------------')
- print(ws)
- print('-----------------------------5:两个风向都取出来-----------------------------------------------------')
- # 在输出的时候使用sep指定分隔符
- print(ws_all[0],ws_all[1],sep=',')
- print('-----------------------------6:风级-----------------------------------------------------------------')
- print(win)
- print('-----------------------------end---------------------------------------------------------------------')

(3).find() 参数总结
每一次执行find() 之后的返回值,仍然是一个对象(bs4.element.Tag),还可以继续调用对象中的 "." 方法。
| 参数 | 对应含义 |
|---|---|
| find("XXX") | 传入默认参数表示:查询指定 "XXX" 标签第一次出现的位置对应的属性值 |
| find_all("XXX") | 传入默认参数表示:查询指定 "XXX" 标签所有出现的位置对应的属性值 |
| find(class_='XXX') | 传入 "class_ " 参数表示:查询指定CSS属性为 "XXX" 的值 |
| find(id="XXX") | c传入"id" 参数表示:查找指定id属性为 "XXX" 的值 |
| find("XXX").span | 配合 "." 参数的时候,来获取 "XXX" 标签下嵌套的 "span" 标签(在之后的代码中可以对Span标签中的值进行进一步的值的获取) |
| find("XXX").span.attrs['title'] | 配合 "attrs["xxx"]" 参数的使用,来获取嵌套在"XXX" 标签下对应 "span "标签中指定的属性值,例如可以获取 "span" 标签中的 "title" 属性的值;同理:如果此时的 "span" 标签 换成 "a" 标签,那么此时再使用 ".attrs["href"]" 就可以获取 "a" 标签中的 "href" 属性的值,从而进行连接的跳转。 |
| find("XXX").span['title'] | 和上一个表格中的实现效果是等价的 |
(4).select() 选择器参数总结
在CSS中,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list。
以下的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容;获取将其中的值取出来,此时其类型仍然是一个对象(bs4.element.Tag)
| 参数 | 对应含义 |
|---|---|
| soup.select('xxx') | 通过标签名进行查找 |
| soup.select('.xxx') | 通过类名进行查找,也就是class属性 |
| soup.select('#xxx') | 根据id名查找 |
| soup.select('p #xxx') | 组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的。例如查找 p 标签中,id 等于 xxx 的内容,二者需要用空格分开 |
| soup.select("head > title") | 直接子标签查询,也是查询指定标签下的某一个标签。例如查询 p 标签下的 title 标签 |
| soup.select('a[class="sister"]') | 根据属性查找:查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。 |
3.re(正则表达式)的使用与图片文件的下载
此时以 "2.爬虫实战:7日天气预报 爬取" 的结果为例进行数据的保存:
此时已经有了从网页中获取的html文本
- 爬虫代码
- # 导入requests模块和bs4模块
- import requests
- from bs4 import BeautifulSoup
-
- # 加入请求头,防止网站监测出来我们是爬虫,所以都必须要引入请求;对于有需要 登录 的页面需要加上cookices,那么直接在header字典中将 " 'Cookie': '你的cookie' "添加进去
- header={
- "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
- }
- # 引入要爬取的网页的url
- url = 'http://www.weather.com.cn/weather/101120101.shtml'
-
- # 1、获取网页的响应
- # url,请求头,设置访问超时
- response = requests.get(url, headers=header,timeout=30)
- # 2,当网页获取成功的之后,设置网页的编码格式,方式出现中文的乱码
- response.encoding='utf-8'
-
- # 3,从获取到的文本连接中获取对应的网页源代码字符串
- data= response.text
- print(data)
图片文件的保存
- # 使用正则进行匹配
- import re
- # 此时的正则表达式的含义是:以 src=开头,然后 .png 结尾,中间是啥都行,而且此时是懒惰匹配
- images = re.findall(r'src="(.*?\.png)"',data)
-
- # 1.单张图片的保存
- response = requests.get(images[0])
- img = response.content
- title=0
- path = r'./picture/%s.jpg'%(title)
- with open(path,'wb') as f:
- f.write(img)
-
- # 2.批量url连接图片的保存
- # 每个文件的命令方式是从 0 开始递增的
- count = 0
- for url in images:
- response = requests.get(url)
- img = response.content
- count = count + 1
- # 使用C语言的格式(类似与占位符的方式)进行拼接 路径字符串 (此时的路径需要提前创建!!!或者再引入os库将创建文件夹)
- path = r'./picture/%s.jpg'%(count)
- # 以写和二进制的权限,打开文件,此时的文件会自动创建
- with open(path,'wb') as f:
- # 使用写的方式将文件下载到指定的路径汇总
- f.write(img)
(1),正则表达式
1).常用元字符:
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
2),字符转义
如果想查找元字符本身的话,得使用\来取消其特殊含义。比如.可以使用 \.的方式进行转义。
3).重复次数:常用限定符
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
4),字符类
对于需要匹配多个字符的时候,我们需要通过列表的方式进行指定,可以指定多个不同的字符,例如(a,e,i,o,u);或者是指定一个区间,例如:([0-9])
5),反义代码
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
6),贪婪与懒惰
-
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪*匹配。
-
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
| 代码/语法 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
4.爬虫实战:豆瓣电影信息 爬取
本次实战主要是使用 request库与 Xpath库进行操作
(1).实战原理
1),Xpath 简介
Xpath 即为 XML 路径语言(XML Path Language),它是一种用来确定 XML 文档中某部分位置的语言。Xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 Xpath 的提出的初衷是将其作为一个通用的、介于 Xpointer 与 XSL 间的语法模型。但是Xpath 很快的被开发者采用来当作小型查询语言。
Xpath解析网页的流程:
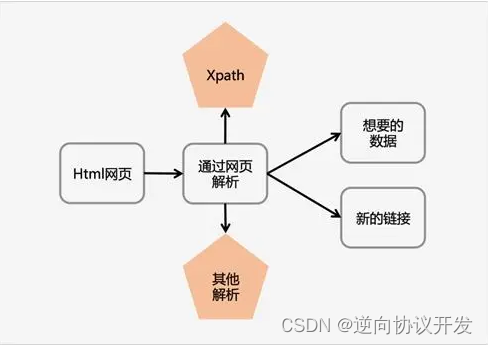
1.首先通过Requests库获取网页数据;
2.通过网页解析,得到想要的数据或者新的链接;
3.网页解析可以通过 Xpath 解析网页,然后通过定位元素,然后再右键使用Copy的方式获取元素的Xpath信息并获得文本:
file=s.xpath('元素的Xpath信息/text()')
(2).实战代码
- # 导入requests模块和bs4模块
- import requests
- from lxml import etree
-
- # 引入要爬取的网页的url
- url = 'https://movie.douban.com/subject/1292052/'
- # 加入请求头,防止网站监测出来我们是爬虫,所以都必须要引入请求;对于有需要 登录 的页面需要加上cookices,那么直接在header字典中将 " 'Cookie': '你的cookie' "添加进去
- header={
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
- }
- # 1、获取网页的响应
- # url,请求头,设置访问超时时间
- response = requests.get(url, headers=header,timeout=30)
- # 2,当网页获取成功的之后,设置网页的编码格式,方式出现中文的乱码
- response.encoding='utf-8'
-
- # 3,从获取到的文本连接中获取对应的网页源代码字符串
- data = response.text
-
- # 4.对获取到的网页源代码字符串使用etree解析
- s=etree.HTML(data)
-
- # 5.通过从网页中Copy的Xpath路径,依次获取电影名称、导演、主演、时长信息
- film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
- director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
- actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
- time=s.xpath('//*[@id="info"]/span[13]/text()')
-
- # 6.显示获取的信息内容
- print('name:',film)
- print('director:',director)
- print('actors:',actor)
- print('duration:',time)
(3).Xpath代码的来源
获取电影名称
元素的Xpath信息是需要我们手动获取的,获取方式为:定位目标元素(电影名称:肖申克的救赎),在网站上选取的目标元素上依次点击:右键 > 检查,按住快捷键“shift+ctrl+c”,移动鼠标到对应的元素时即可看到对应网页代码:
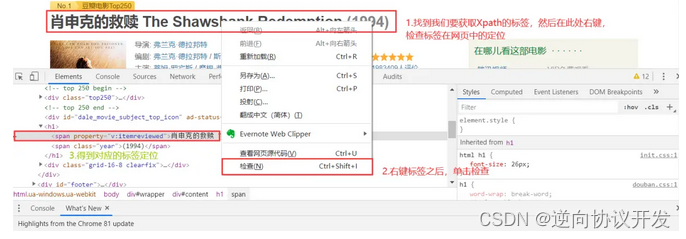
在电影标题对应的代码上依次点击 右键 > Copy > Copy XPath,获取电影名称的Xpath:
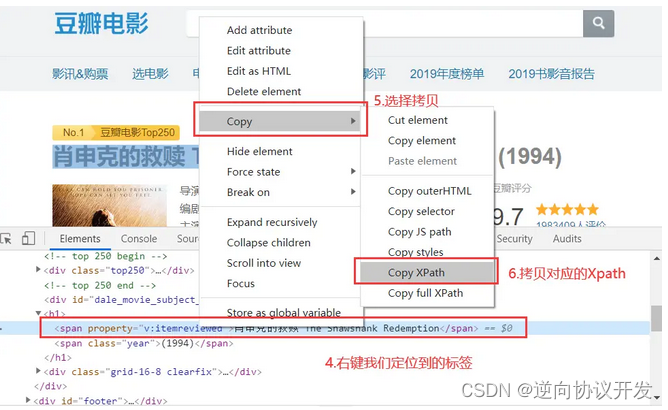
此时得到的标签示例 "//*[@id="content"]/h1/span[1]"
- # 1,直接将获取到Xpath打印出来,得到的是一个元素
- print(s.xpath('//*[@id="content"]/h1/span[1]'))
- # 输出结果:[<Element span at 0x1a4e1c0afc8>]
-
- # 2,可以再追加"/text()",获取元素中对应的值
- print(s.xpath('//*[@id="content"]/h1/span[1]/text()'))
- # 输出结果:['肖申克的救赎 The Shawshank Redemption']
同理可以得到其他元素的标签!!!
5.文本文件的保存
(1).保存字符串到本地txt文件中
此时以 "4.爬虫实战:豆瓣电影信息 爬取" 的结果为例进行数据的保存:
此时已经有了 “film”,“director”,“actor”,“time”变量对应的属性值
- 爬虫代码
- # 导入requests模块和bs4模块
- import requests
- from lxml import etree
-
- # 引入要爬取的网页的url
- url = 'https://movie.douban.com/subject/1292052/'
- # 加入请求头,防止网站监测出来我们是爬虫,所以都必须要引入请求;对于有需要 登录 的页面需要加上cookices,那么直接在header字典中将 " 'Cookie': '你的cookie' "添加进去
- header={
- "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
- }
- # 1、获取网页的响应
- # url,请求头,请求延迟(时间):主要是在多批次访问的时候,有一个停顿时间,可以防止网站监测为爬虫,也就是伪造一个真实的人的请求
- response = requests.get(url, headers=header,timeout=30)
- # 2,当网页获取成功的之后,设置网页的编码格式,方式出现中文的乱码
- response.encoding='utf-8'
-
- # 3,从获取到的文本连接中获取对应的网页源代码字符串
- data = response.text
-
- # 4.对获取到的网页源代码字符串使用etree解析
- s=etree.HTML(data)
-
- # 5.通过从网页中Copy的Xpath路径,依次获取电影名称、导演、主演、时长信息
- film=s.xpath('//*[@id="content"]/h1/span[1]/text()')
- director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
- time=s.xpath('//*[@id="info"]/span[13]/text()')
文件保存代码
- # 对最后文件的输出内容进行重新格式化拼接为一个字符串,然后进行保存
- # 1,首先测试输出效果
- print("1:name: {},\n2:director: {},\n3:actor: {},\n4:time: {}".format(film[0],director[0],actor,time[0]))
- # 2,赋于变量进行保存,然后测试输出
- outData = "1:name: {},\n2:director: {},\n3:actor: {},\n4:time: {}".format(film[0],director[0],actor,time[0])
- print(outData)
- # 3,连接本地文件系统,进行文件夹与文件的创建
- # 4,首先判断要输出的文件是否存在,如果存在则直接进入到指定文件夹中,不存在则创建文件夹
- import os
- if os.path.exists("./output"):
- os.chdir("./output")
- else:
- os.mkdir("./output")
- os.chdir("./output")
- # 5,打开一个文件(若文件不存在则创建一个),然后向文件中写入数据,最后关闭与本地文件系统的连接
- # 此时就是提前创建一个带有指定路径和文件的对象,然后再调用写操作,最后将写操作关闭
- myfile = open('./out.txt','w',encoding='utf-8')
- myfile.write(outData)
- myfile.close()
-
- # 6,如果想追加数据,直接打开文件,然后通过第二个参数指定模式为追加
- # 注意此时是在创建文件对象的同时,通过文件对象带调用写操作,
- with open('./out.txt','a',encoding='utf-8') as file:
- file.write('\n123465')
(2).保存字符串到Mysql数据库中
- # 1,首先在Mysql中建立你要导出的数据库和根据字段的内容创建数
- '''
- create databases test;
- use test;
- create table spiderTest(film varchar(100),director varchar(100),actor varchar(100),time varchar(100)) CHARSET=utf8;
- '''
- # 2,然后获取数据库的连接
- # 3,使用 execute()方法,执行插入语句将内容写入到数据库中
- import pymysql # 导入相应操作Mysql的库文件
-
- conn = pymysql.connect(host='localhost',user='root',password='111111',db='test',port=3306,charset='utf8')
- cursor=conn.cursor() # 连接数据库及光标
-
- # 注意此时对于演员的数据过长,所以只是截取了第一个数据写入的
- cursor.execute("insert into spiderTest(film,director,actor,time) values(%s,%s,%s,%s)",(str(film[0]),str(director[0]),str(actor[0]),str(time[0])))
- # 当执行完插入语句后需要手动提交,才会生效。
- conn.commit()
以上就完成今天所有的步骤了,如果需要的话希望大家可以喜欢

