- 1python 命名实体识别_使用Python和Keras的有关命名实体识别(NER)的完整教程
- 2C++ MFC中如何根据不同文件编码格式创建和写文本内容_mfc写文件
- 3软件测试(一)_软件测试(中文第三版).txt 将 软件测试文档中的 停用词过滤,过滤后的文字或者词组
- 4thinkphp5 域名路由_tp5 route::domain传参
- 5java springboot实现手机短信发送_srping boot cmpp2.0短信网关发送短信代码
- 6signature=b86ce7d3aaefb99272e0c9e086e6dc8a,MS15-023:内核模式驱动程序中的漏洞可能允许特权提升:2015 年 3 月 10 日...
- 7小红书百度快照抓取
- 89个有趣的Python小项目,练手必备(附源码)_python有趣的小项目
- 9鸿蒙系统下载地址_华为HarmonyOS鸿蒙系统应用开发工具DevEco Studio2.0安装及Hello World项目运行...
- 10JS逆向进阶篇【去哪儿旅行登录】【下篇-逆向Bella参数JS加密逻辑&Python生成】_bella js
Flink实现Exactly Once_flink exactly once
赞
踩
前言
Flink通过状态快照实现容错处理:
Flink 定期获取所有状态的快照,并将这些快照复制到持久化的位置,例如分布式文件系统。
如果发生故障,Flink 可以恢复应用程序的完整状态并继续处理,就如同没有出现过异常。
Flink 管理的状态存储在 state backend 中。
checkpoint 代码
- /**
- * 创建flink环境
- */
- val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
-
- /**
- * 使用flink 的 checkpoint将结果保存到hdfs上去
- *
- * 若任务中途失败或者重新运行,只需指定保存的hdfs路径,就可在上次执行的结果上继续执行
- * 不用让数据重新开始
- *
- * flink中的有状态计算才可以checkpoint,若自己创建的hashmap则无法保存
- */
-
- // 每 1000ms 开始一次 checkpoint
- env.enableCheckpointing(1000)
-
- // 高级选项:
-
- // 设置模式为精确一次 (这是默认值)
- env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
-
- // 确认 checkpoints 之间的时间会进行 500 ms
- env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
-
- // Checkpoint 必须在一分钟内完成,否则就会被抛弃
- env.getCheckpointConfig.setCheckpointTimeout(60000)
-
- // 允许两个连续的 checkpoint 错误
- env.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
-
- // 同一时间只允许一个 checkpoint 进行
- env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
-
- // ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业取消时,保留作业的 checkpoint。注意,这种情况下,需要手动清除该作业保留的 checkpoint。
- // ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,删除作业的 checkpoint。仅当作业失败时,作业的 checkpoint 才会被保留。
- env.getCheckpointConfig.setExternalizedCheckpointCleanup(
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
-
- /**
- * 设置flink checkpoint保存状态的位置
- *
- * 创建一个临时数据库保存
- * env.setStateBackend(new EmbeddedRocksDBStateBackend(true))
- */
- env.setStateBackend(new HashMapStateBackend())
- //将状态保存到hdfs中
- env.getCheckpointConfig.setCheckpointStorage("hdfs://master:9000/flink/checkpoint")

一、状态快照 checkpoint
Checkpoint – 一种由 Flink 自动执行的快照,其目的是能够从故障中恢复。Flink开启checkpoint可在任务失败或者重启时,重新提交任务指定checkpoint保存外部系统的路径,即可在上次执行的结果上继续执行,数据不需重新开始。
checkpoint的执行:
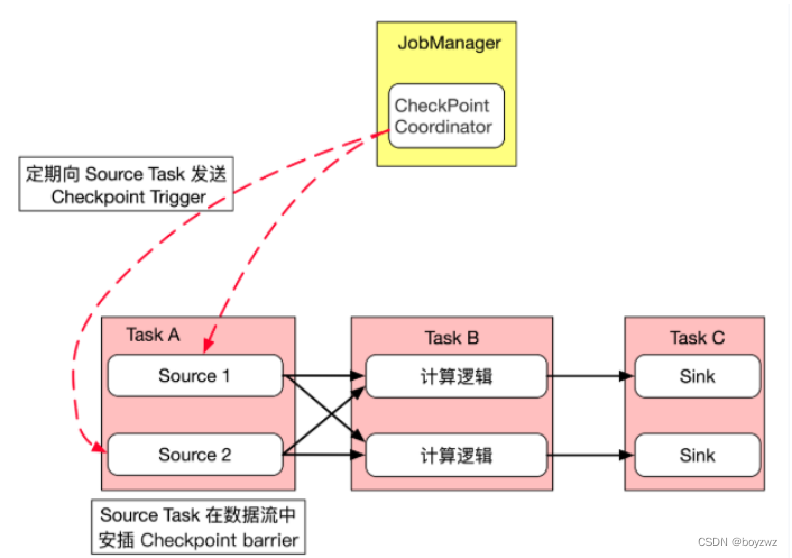
1、checkpoint是由JobManager定时去执行,flink快照机制并不是在同一时刻所有任务一同执行,而是所有任务在处理完同一数据后,保存自身状态
2、JM向Source Task发送Trigger,Source Task会保存自身状态(记录当前读取数据的偏移量),并在数据流中,插入带有编号的 checkpoint barriers,向下游传递barrier
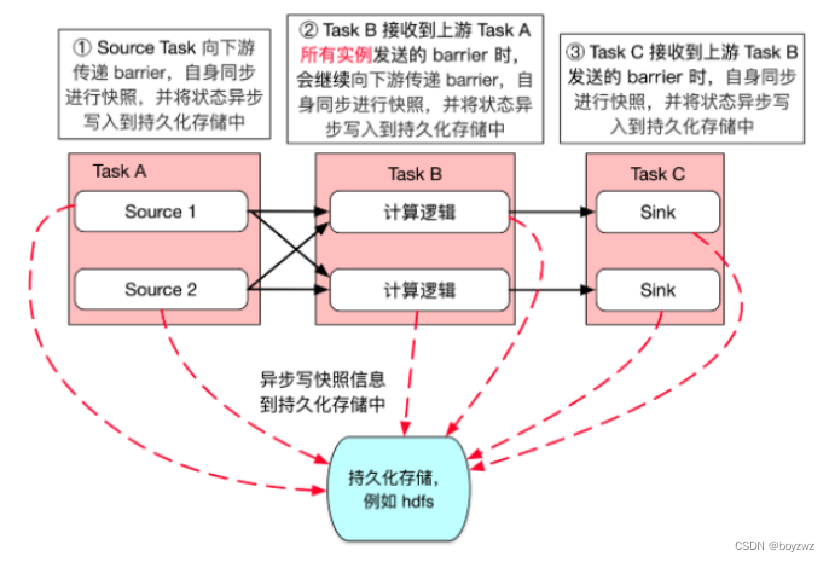
3、当下游的task接收到barrier时,会保存自身状态(如有上游有多个分区任务,下游task收到上游所有实例的barrier才会做快照),继续向下游传递barrier
4、当所有task完成同一次checkpoint的barrier之后,一次checkpoint完成
5、当快照被持久保存后,JM会删除旧的checkpoint文件
6、当任务状态信息备份完成后,会上报JM,当所有的任务都上报后,完成一次checkpoint
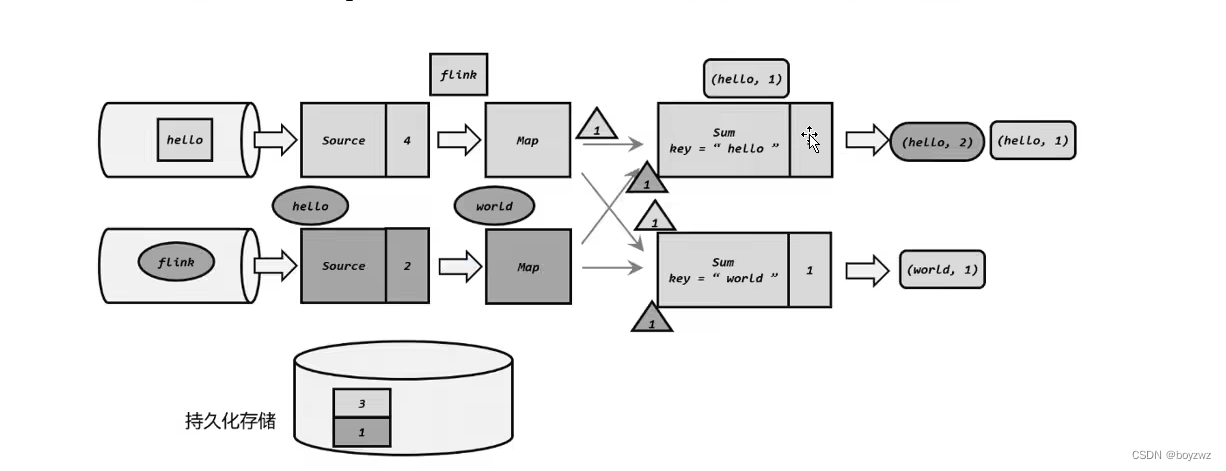
二、端对端确保精确一次 Exactly Once
状态一致性:
计算结果要保证准确
每一条数据都不应该丢失,也不应该重复计算
在遇到故障时可以恢复状态,恢复以后的重新计算,结果也应该是正确的
(每一条数据的处理只影响一次结果)
状态一致性分类:
AT_MOST_ONCE(最多一次)可能会导致数据丢失
AT_LEAST_ONCE(最少一次)可能会导致数据重复,多次处理
EXACTLY_ONCE (精确一次)
Exactly Once:
Flink 使用了轻量级快照机制--检查点(checkpoint)来保证exactly once语义
1、source端
必须是可重放的
Flink 分布式快照保存数据计算的状态和消费的偏移量,保证程序重启之后不丢失状态和消费偏移量
2、端对端
内部保证--checkpoint
3、sink端

sinks 必须是事务性的(或幂等的)
幂等:对一个数据进行多次操作,对结果只会更改一次。即第一次操作以后,后面重复执行就不起作用了(hashmap集合,对于一个kv数据存入多次,结果不会改变)
sink端必须支持事务写入(要么全部成功,要么全部不写入)
若sink端数据不是事务写入,一条一条写入的,发生故障的话,会回滚到上一次checkpoint,有些数据就会再次写入,即产生重复数据。
两次写入(Two-Phase-Commit,2PC)

1、sink端会先将数据写入事务,预提交至外部系统中
2、当sink端读取到上游传递来的barrier,保存自身状态到状态后端后,上报JM(同时会开启一个新的事务,在barrier后的到达的数据,将由新的事务预提交);当所有任务上报后,checkpoint完成,sink端正式提交
3、若在预提交阶段发生故障,预提交的数据会全部撤销,此时回滚到上次checkpoint,再次处理数据,写入的数据也不会重复
实现exactly once需要配置:
1、必须启用checkpoint
2、选择参数EXACTLY_ONCE
3、Kafka中默认为read_uncommitted,即会读取到未提交的数据,所以应将其修改为read_committed
4、Flink的Kafka连接器配置超时时间默认为1小时,Flink集群配置事务超时时间为15分钟,应设置前者小于后者
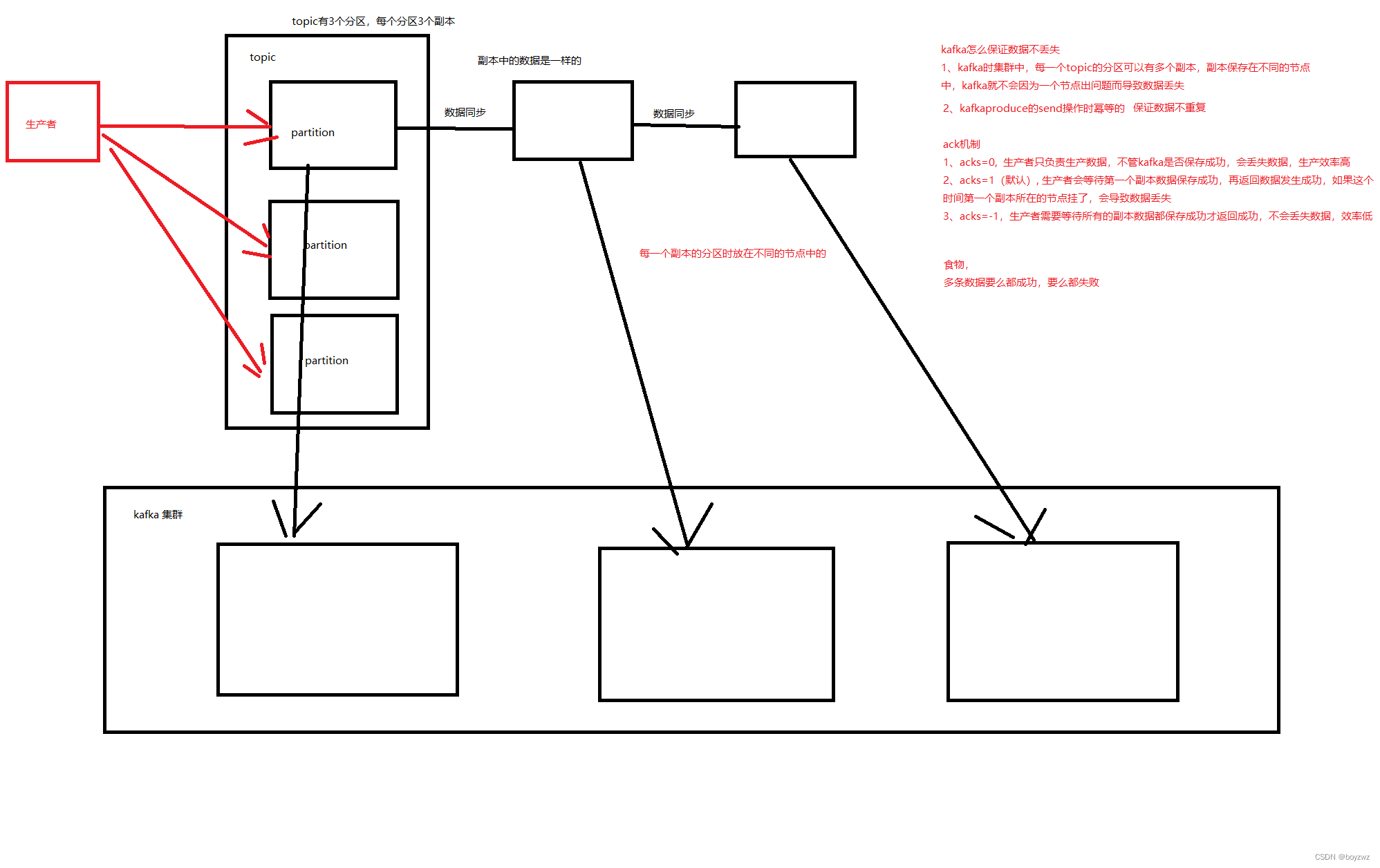
三、Kafka中数据不丢失