
- 1C和C++相互调用 error LNK2001: unresolved external symbol_c++unresolved什么意思
- 2利用低代码从0到1开发一款小程序_小程序低代码
- 3Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本_gpt-4的层数和训练参数
- 4使用org.apache.commons.io.FileUtils,IOUtils;工具类操作文件
- 5shell命令-find常用命令_shell find -exec
- 6Gradle 安装和配置教程_gradle-8.3-bin.zip放哪个位置
- 7《最长的一帧》理解01_场景渲染
- 8负载均衡_用户将请求发送给负载均衡
- 9Apriori算法中使用Hash树进行支持度计数_hash树在apriori算法中的作用
- 10glance服务器上传的镜像支持,openstack-理解glance组件和镜像服务
文本领域的数据预处理技术、深度学习训练技巧以及Debug经验_数据处理文本动态技术
赞
踩
0. 引言
这篇文章将介绍一些关于文本的处理技术和深度学习训练的技巧。其实这些技巧单独拿出来大家应该都很熟悉,重点是如何将这些技巧和自己的应用场景结合起来。
1. 文本领域的数据预处理技术
1.1 文本纠错
在一个项目中,我们会用到文本纠错技术呢?在这里我举个例子,例如我们中一些数据来自语音识别或者OCR获得,那么我们就会用到纠错技术。例如,OCR的一些错误都是一些形似的字体,而语音识别的一些错误都是读音相似的文字,所以不同场景要用到不同的纠错技术。具体纠错类型我们分为两种:
- Non-word拼写错误
- Real-word拼写错误
1.1.1 Non-word拼写错误
首先看一下Non-word的拼写错误,这种错误表示此词汇本身在字典中不存在,比如把“要求”误写为“药求”,把“correction”误拼写为“corrction”。寻找这种错误很简单,例如分完词以后找到哪个词在词典中不存在,那么这个词就可能是错误拼出来的的词。
操作步骤
• 找到候选词
• 接着基于特定算法找出与错拼词关联最高的一个或多个单词作为纠正选项
如何确定候选项呢?
• 英文:编辑距离
• 中文:拼写相近、字形相近
如何找出最关联项:可以根据贝叶斯定理,得到如下表达式:
P
(
候
选
项
∣
错
误
单
词
)
∝
P
(
候
选
项
)
∗
P
(
错
误
单
词
∣
候
选
项
)
P(候选项|错误单词)∝ P(候选项)* P(错误单词|候选项)
P(候选项∣错误单词)∝P(候选项)∗P(错误单词∣候选项)
“此选项本身在语料中出现的可能性”和“人们意图打候选项时会错打成错误单词的可能性”的乘积。前者可视为uni-gram语言模型,需要计算词语的出现频次,当然也可以扩张至二阶或三阶,比如计算“错误单词左边单词+候选项+错误单词右边单词”在语料中的出现情况。
1.1.2 Real-word拼写错误
单词本身没有错误,但是不符合上下文语境,常常涉及语法语义层面的错误,比如把“我现在在公司里”错写成“我现在在公式里”。这种错误比上面以一种错误纠错更加困难。
操作步骤
• 首先针对每个单词根据编辑距离、同音词、近形词等方式选出候选项(也包括单词本身)
• 接下来计算基于候选项的语言模型,以及在候选项情况下出现错误单词的条件概率;如果综合计算而得单词本身出现在此语境中的概率较大,则不进行纠正,否则推荐纠正项。
• 注:在实际应用中不可能对每个词进行排查,可以应用语言模型等方式对句子进行粗粒度的初步筛查(困惑度)。
这里举个小例子,只给定少量英语语料,如何设计一个简单的英文纠错系统(Non-word)?

这里简单说一下思路,首先全部单词变成小写,并且计算他们出现的次数,再除以单词总数(字典长度)作为该词的频率,对输入的单词在词典里进行匹配,至少0次编辑,最多2次编辑。找出编辑距离最小的,当编辑距离为最小的不只一个时,找出所有单词里的概率最大的作为输出。
对于Real-Word可以先确定候选项,然后通过语言模型(一阶/二阶)进行统计。
1.2 低频词处理
接下来我们再讲一下低频词,大家做一些文本任务的时候,例如文本分类等,大家都会把低频词给过滤掉,为什么过滤低频词对任务不会有影响呢?接下来,我们说一下过滤低频词的原理。
原因主要有两点:
• 出现频率特别低的词汇对语料整体的影响不大
• 极大地减少计算复杂度(减小词典单词量)
有一个定律叫做齐夫定律:在自然语言的语料库里,一个单词出现的频率与它在频率表里的排名成反比。还有一个现象叫做长尾现象:就是说少部分频率很高的词汇占据了词料的大部分,而大部分的单词出现频率很低。
中文词汇有几十万,常用的就几千个。出现频率特别低的词汇对语料整体的影响不大,过滤掉他们还极大地减少计算复杂度(减小词典单词量)。
但是也要分场景,有一些垂直产业,医疗法律等,可能低频词起到了很关键的作用(类似TFIDF)。
1.3 停用词
这里再说一些停用词的处理,感觉大家现在都将去停用词作为了任务和项目的标配。语气词、助词等都可以作为停用词来处理。但是,也需要考虑自己的应用场景。
举几个样例:
例如情感分类任务:“啊、吗、太、可”等语气助词也很重要
对于人物关系信息抽取:动词反而不那么重要,名词更重要
对于事件识别:名词、动词都很重要
1.4 关键词提取
下面我们在来讲关键词提取,其实关键词提取可以当作获取特征的一种方式。具体获得关键词的方式有很多种,我们依次介绍一下:
1.4.1 基于特征统计
- 词频:一般来说,一个词在文本中出现次数越多,表明作者越想表达这个词,因此可以通过对词频的简单统计便可以评估出词语的重要性。
- TF-IDF(term frequency–inverse document frequency):综合考虑了词在文本中的词频以及普遍重要性,直观地说,一个词在其它文本中出现越少,在本文本中出现越多,那么对此文本的重要性越强。
- 位置特征(开头或结束)
- 词跨度:指的是一个词在文本中首次与末次出现的距离(跨度越大,一般越重要)
- 词的固有属性:包括一系列特征,词长、词性、对应的句法成分、开头大小写、是否全部大小写、词缀等。
1.4.2 基于主题模型
关于LDA主题模型的原理,我以前也在我的博客中详细介绍过了。主题模型的核心假设是,存在隐含变量,即文本主题,决定了文本中词汇的出现情况。它假设语料库中蕴含了多个主题,而每个主题下面对应了一系列的词语。当作者在书写某篇文章时,是先设定某个主题再从中选择某个词的过程。

在具体运算中,首先需要指定主题的数目,一般需要根据实验结果多次调节,主题模型根据文本中词的出现频率情况即词袋模型去学习两类概率分布。每个主题下概率较大的词汇可认为是关键词。
假设有M篇文章,K个主题,N个单词,那我们所求的是:
• 文档-主题分布:M个维度为K的多项式分布
• 主题-单词分布:K个维度为N的多项式分布
1.4.3 基于TextRank
TextRank的思想是由PageRank起源的,PageRank,网页排名,Google用 它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。如果一个网页被很多其他网页链接到,说明这个网页比较重要,也就是PageRank值会相对较高。如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
TextRank是PageRank在文本上的应用,核心思想如下:
• 如果一个单词出现在很多单词边上,说明这个单词比较重要。
• 一个TextRank值很高的单词边上的单词,TextRank值会相应地因此而提高。
在我们应用的时候,可以用半径为2进行边的构造,如下所示:

这种做法就天然的认为距离越近的单词关系越大,但是实际情况中并不全是这样的,可能两个相似度很高的单词在一个句子中距离较远(例如两个人名),这里我们可以用依存句法分析进行优化,改善连接关系:

1.5 短语提取
刚才讲了关键词提取,其实很多时候有很多固定的词汇搭配,:“green hand”、“white lie”、“十八般武艺”、“鲤鱼跃龙门”;专业表达:“支持向量机”、“弱监督学习”、“自适应学习”;新的短语表达:“5G元年”、“基层减负年”、“雨女无瓜”。
像这种短语搭配,如果我们把它切词切分开来,就丧失了原有的意义,有时候我们希望提取出一个短语出来。
短语提取步骤:
1)基于N-gram统计获取出现频率较高的短语作为候选项。
2)对候选项进行多维度的特征统计。
3)将多维度特征进行综合评估、排序,取topK。
关键是如何进行特征统计,这里简单介绍两种特征指标。
PMI(Pointwise Mutual Information):中文译作点互信息,能够刻画单词间经常一起搭配的程度。

两者联合出现的情况越多,单独出现的情况越少,此候选项为某一固定搭配的完整语义单元的可能性越大。例:“支持向量机”,“支持”,“向量机”
**左(右)邻字熵:**如果是某一完整意义的短语,其左右的搭配应当很丰富,此指标从熵的角度来衡量某一候选项的自由搭配程度。保证了一个短语的完整度。

其中 W W W表示候选项左(右)侧所出现字的集合,此集合越是丰富,说明候选项为某固定短语的可能性越高。例:“持向量机” 左侧:“支”;“支持向量机”左侧:字多种多样。
短语提取还可以有一个很好的帮助,那就是新词挖掘。
基于点互信息、左(右)邻字熵进行新词挖掘,以字为单位进行操作,这里给了一个github链接,并且在西游戏名著里挖掘出很多新词:

在一些比较新的领域或者专业领域,可以先进行新词挖掘,然后再分词进入神经网络。
1.6 文本数据增强
首先我们先推荐一键中文数据增强工具:https://github.com/425776024/nlpcda
1.6.1 EDA
Easy Data Augmentation for Text Classification Tasks (EDA)提出并验证了几种加噪的 text augmentation 技巧,分别是同义词替换(SR: Synonyms Replace)、随机插入(RI: Randomly Insert)、随机交换(RS: Randomly Swap)、随机删除(RD: Randomly Delete),下面进行简单的介绍:
(1)同义词替换(SR: Synonyms Replace):不考虑stopwords,在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。
Eg: “我非常喜欢这部电影” —> “我非常喜欢这个影片”,句子仍具有相同的含义,很有可能具有相同的标签。
(2) 随机插入(RI: Randomly Insert):不考虑stopwords,随机抽取一个词,然后在该词的同义词集合中随机选择一个,插入原句子中的随机位置。该过程可以重复n次。
Eg : “我非常喜欢这部电影” —> “爱我非常喜欢这部影片”。
(3) 随机交换(RS: Randomly Swap):句子中,随机选择两个词,位置交换。该过程可以重复n次。
Eg: “如何评价 2017 知乎看山杯机器学习比赛?” —> “2017 机器学习?如何比赛知乎评价看山杯”。
(4) 随机删除(RD: Randomly Delete):句子中的每个词,以概率p随机删除。
Eg: “如何评价 2017 知乎看山杯机器学习比赛?" —> “如何 2017 看山杯机器学习 ”
这四种方式所带来的问题:
同义词替换SR有一个小问题,同义词具有非常相似的词向量,而训练模型时这两个句子会被当作几乎相同的句子,但在实际上并没有对数据集进行有效的扩充。
随机插入RI很直观的可以看到原本的训练数据丧失了语义结构和语义顺序,同义词的加入并没有侧重句子中的关键词,在数据扩充的多样性上实际会受限较多。
随机交换RS实质上并没有改变原句的词素,对新句式、句型、相似词的泛化能力实质上提升很有限。
随机删除RD不仅有随机插入的关键词没有侧重的缺点,也有随机交换句式句型泛化效果差的问题。随机的方法固然能够照顾到每一个词,但是没有关键词的侧重,若随机删除的词刚好是分类时特征最强的词,那么不仅语义信息可能被改变,标签的正确性也会存在问题。
1.6.2 回译
在这个方法中,我们用机器翻译把一段中文翻译成另一种语言,然后再翻译回中文。

1.6.3 半监督 & 无监督
这两种算法是最新的深度学习增强算法,这里笔者并没有深究细节,只是简单说一说他的原理和思想。
半监督 Mixmatch是为了更好地利用未标注的数据,减轻对于大规模标注数据集的依赖;如今也证明了这是一种强有力的学习范式。它的工作方式是通过 MixUp 猜测数据扩增方法产生的无标签样本的低熵标签,并把无标签数据和有标签数据混合起来。
无监督数据增强UDA了使用标记和未标记的所有数据,对有标签的数据训练时加入了cross entropy loss 函数。对未标记数据,与Mixmatch使用 l2 loss 不同,UDA对增广后未标记的数据预测结果使用KL散度。Targeted data augmentation 特定目标的数据增强则包括了back translation回译、autoaugment(图像)、TFIDF word replacement。其中回译是从英文转法文再译回英文,IDF是从DBPedia语料中获取。
2. 深度学习训练技巧
首先说一说神经网络普遍存在的问题。
第一个问题是优化问题。
- 神经网络的损失函数为非凸函数,找到全局最优解通常比较困难。
- 神经网络有大量参数,训练数据也很大量,一阶优化方法的训练效率通常比较低,而二阶优化方法计算代价很高。
- 深度神经网络存在梯度消失或爆炸问题,导致基于梯度的优化方法经
常失效。
第二个问题是泛化问题
由于深度神经网络的复杂度比较高,并且拟合能力强,很容易在训练集上产生过拟合。因此在训练深度神经网络时,同时也需要通过一定的正则化方法来改进网络的泛化能力。
2.1 梯度下降法方式
深度神经网络的参数学习主要通过梯度下降法来寻找一组可以最小化结构风险的参数。在具体实现中,梯度下降法可以分为:批量梯度下降(速度慢,稳定)、随机梯度下降(速度快,不稳定)以及小批量梯度下降。基于速度与稳定性的考量,经常使用小批量梯度下降法。
那么具体批量大小如何调整呢?
一般来说梯度下降的批量大小应该和学习率挂钩的。一般而言,批量大小会影响随机梯度的方差(即稳定性)。批量越大,随机梯度的方差越小,引入的噪声也越小,训练也越稳定,相应地,可以设置较大的学习率。批量较小时,需要设置较小的学习率,否则会影响模型收敛。学习率通常要随着批量大小的增大而相应地增大。线性缩放规则:当批量大小增加 倍时,学习率也增加m倍。
2.2 学习率调整
在梯度下降法中,学习率的取值很关键,如果过大很可能不会收敛,如果过小则收敛速度太慢。
目前流行的学习率调整的方向有以下三种:
• 学习率衰减
• 学习率预热
• 自适应调整学习: AdaGrad、RMSprop、AdaDelta
学习率衰减:一开始可设置大点的学习率;在最优点附近后减小学习率。具体的衰减方式有很多种,如下图所示::
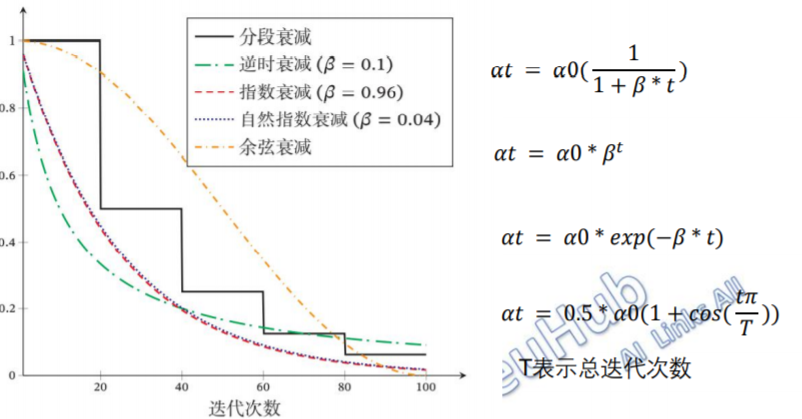
学习率预热:为了提高训练稳定性,在最初几轮迭代时,采用比较小的学习率,等梯度下降到一定程度后再恢复到初始的学习率,这种方法称为学习率预热。
自适应调整
AdaGrad算法(Adaptive Gradient Algorithm)
在一般的梯度下降法中,每个参数在每次迭代时都使用相同的学习率。但实际上,在每个参数的维度上收敛速度都不相同,AdaGrad的主要思想是根据不同参数的收敛情况分别设置学习率。
我们假设在第 t t t次迭代时,先计算参数梯度平方的累计值:

参数更新差值∆为( g t g_t gt表示第 t t t次迭代计算出的梯度,是一个常数,取exp(-7)到exp(-10)之间):

学习率将随着梯度的倒数增长,也就是说有较大梯度累积的具有较小的学习率,而较小的梯度累积的具有较大的学习率,可以解决普通的sgd方法中学习率一直不变的问题。
缺陷: 由于分母中对历史梯度一直累加,学习率将逐渐下降至0,在经过一定次数的迭代依然没有找到最优点时,由于这时的学习率已经非常小,很难再继续找到最优点。
RMSProp算法
基于上述的缺陷,RMSProp对此进行了改进。RMSProp优化算法和AdaGrad算法唯一的不同,在于累积平方梯度在
G
t
G_t
Gt的求法不同,用一个衰减系数
β
β
β(一般取0.9)来控制历史信息的获取。历史梯度信息的累计乘上一个衰减系数 ,然后用
(
1
−
β
)
(1− β)
(1−β)作为当前梯度的平方加权系数相加,公式如下:
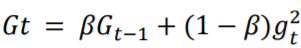
在迭代过程中,每个参数的学习率并不是呈衰减趋势,既可以变小也可以变大,在有些情况下可避免 AdaGrad 算法中学习率不断单调下降以至于过早衰减的缺点。
AdaDelta算法
不仅对历史梯度信息做有选择的累加,对历史的参数更新差值∆也做有选择的累加。Adadelta算法是Adagrad算法的延伸,与RMSProp算法一样,是为了解决Adagrad中学习率不断减小的问题,RMSProp是通过移动加权平均的方式,Adadelta也一样:

对于 G t G_t Gt的运算和RMSProp一样,这样参数更新差值∆为:
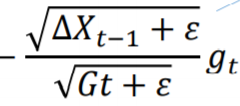
这样在一定程度上保持住了学习率的稳定性。
2.3 梯度修正
在梯度下降法中,除了学习率调整,还可以调整梯度。批量梯度下降法中,如果每次选取样本数量比较少,损失会呈现振荡的方式下降(与整体训练集上的最优梯度不一致)。解决方式:通过使用最近一段时间内的平均梯度来代替当前时刻的随机梯度来作为参数更新的方向,从而提高优化速度。
• Momentum动量
是模拟物理中的概念,某物体的动量指的是该物体在它运动方向上保持运动的趋势。动量法(Momentum Method)是会考虑之前的梯度情况:
参数更新差值∆为(p通常设为0.9):
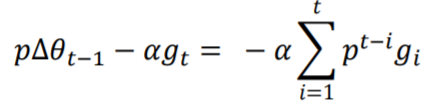
更新取决于最近一段时间内梯度的加权平均值。当某个参数在最近一段时间内的梯度方向不一致时,参数更新幅度变小;反之,参数更新幅度变大,起到加速作用。
• Nesterov加速梯度(Nesterov Accelerated Gradient,NAG)
这种方法是对Momentum动量法的改进。在动量法中,参数更新方向Δ 为:上一步的参数更新方向Δ -1和当前梯度的反方向
−
g
t
-gt
−gt的叠加。相当于分为两步进行,先根据Δ-1 更新一次得到参数,再用
−
g
t
-gt
−gt进行更新。
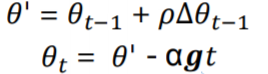
其中梯度 为点 t − 1 t−1 t−1上的梯度,因此在第二步更新中有些不太合理,更合理的更新方向应该为 θ ′ θ' θ′ 上的梯度。两者的区别如下图所示:

• Adam(Adaptive Moment Estimation Algorithm)
Momentum和 RMSprop 算法的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
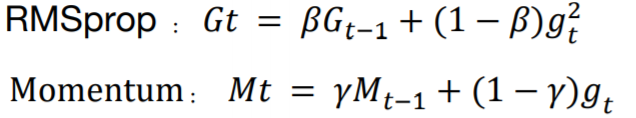
在迭代初期值会比真实的均值和方差要小,要进行修正,参数更新差值∆为:

总结如下:

2.4 参数初始化
参数初始值的选取十分关键,关系到网络的优化效率和泛化能力。一般而言,参数初始化的区间应该根据神经元的性质进行差异化的设置。如果一个神经元的输入连接很多,它的每个输入连接上的权重就应该小一些,以避免神经元的输出过大(当激活函数为 ReLU 时)或过饱和(当激活函数为Sigmoid函数时)。
**预训练初始化:通常情况下,一个已经在大规模数据上训练过的模型可以提供一个好的参数初始值,这种初始化方法称为预训练初始化;随机初始化:使得不同神经元之间的区分性更好。**如何选取合适的随机初始化区间?为了使得训练平稳性,应当尽量保持每个神经元的输入和输出的方差一致。
Xavier初始化的基本思想就是尽量保持每个神经元的输入和输出的方差一致。在神经网络中,第 l l l层的一个神经元值 a ( l ) a^{(l)} a(l),接收到前一层的 M l − 1 M_{l-1} Ml−1个神经元的输出 a i ( l − 1 ) a_i^{(l-1)} ai(l−1)。
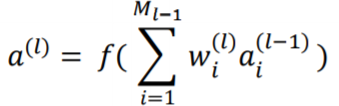
a ( l ) a^{(l)} a(l)的方差为:
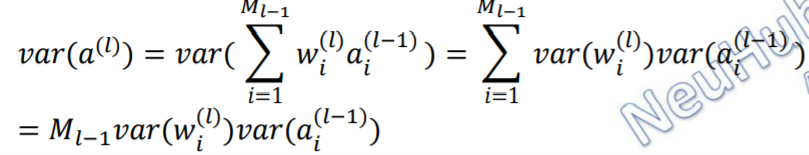
如果为了梯度保持相等,同时考虑考虑到在反向传播中,误差信号也不被放大或缩小:

注:这里假设激活函数为恒等函数,但是 也适用于 Logistic 函数和Tanh 函数。因为神经元的参数和输入的绝对值通常比较小,处于激活函数的线性区间,这时Logistic函数和Tanh函数可以近似为线性函数。在实际应用中,通常乘以一个缩放因子。
2.5 归一化
最后我们再来分析归一化,归一化也是想让学习更加稳定一点。将传统机器学习中的数据归一化方法应用到深度神经网络中,对神经网络中隐藏层的输入进行归一化,从而使得网络更容易训练。
某一神经层的输入分布会受到前几层参数变化的影响(越是后面的层,分布偏移越大);而每次参数更新都会导致神经层的输入分布在不同批次间也发生改变。从机器学习角度来看,如果神经层的输入分布发生了改变,那么其参数需要重新学习。
所以我们需要对神经层中间过程进行归一化操作,使分布保持稳定。现在流行的归一化有两种,批归一化和层归一化。
2.5.1 批归一化
对于神经网络中的每一个神经元(线性变化之后,非线性变化之前),基于Mini-batch进行标准归一化。但是:取值集中到 0 附近,若使用 Sigmoid型激活函数时,此区间接近线性变换区间,减弱了神经网络的拟合能力。因此:为了避免对神经网络的表示能力造成负面影响,增加两个参数用于分布的缩放和平移。具体公式如下图:

批归一化的特点:批归一化可以看作一个特殊的神经层:非线性变化->批归一化->线性变化。小批量数据的时候,噪声较大。当训练完成时,用整个数据集上的均值与方差用来作归一化。相当于正则化方法:神经网络在训练时,对一个样本的预测不仅考虑到该样本本身,也考虑到同一批次中的其他样本,因此,使得神经网络不会“过拟合”到某个特定样本,从而提高网络的泛化能力。
对于归一化是否有效,大家有很多争议,下面是很多大佬的讨论:
https://arxiv.org/pdf/1807.03341.pdf
https://arxiv.org/pdf/1807.03341.pdf
那我们总结一下批归一化的优点:
- 可应用大学习率
- 对权重初始化不太敏感
- 替代数据preparation
- 可省略Dropout
缺陷是:对单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则与整体数据的均值与方差偏移太大。
2.5.2 层归一化
批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化。(即均值与方差的计算方式不同)。层归一化是在每个数据的所有维度上进行归一化,批归一化是对所有数据在每个维度上进行归一化。
3 . 深度学习Debug
这一小节的目标是了解深度学习常见潜在的bug以及如何去排查可能存在的bug
3.1 常见的一个bug
现象:梯度在变化,损失也在下降,看似一切正常。
但是预测结果出来了:全部都是零值,或者预测全是正样本,生成全是:啊啊啊啊啊。
检查流程:
- 把复杂的模型首先替换成为简单的模型( transformer – > lstm) , 确认是否是模型
的问题 - 去掉暂时不必要的数据预处理环节。 ( 正则化,数据增强模块)
- 验证输入数据的正确性(数据大小,padding, index)
- 从较小的数据集开始,等数据过拟合之后,利用训练样本进行测试
- 加入之前忽略的项(正则,自定义损失等)
3.2 数据集问题
- 再次检查输入数据。 例如混淆了batch , length 的维度,打印或显示一批,确
保正确 - 随机输入维度相同的数据,看是否产生错误的方式一样,如果是,说明在某
些时候你的网络把数据转化为了垃圾。试着逐层调试,并查看出错的地方。 - 确保输入样本与输出的匹配性
- 确认是否太多噪音( 标签的错误) ,噪音太多很难用dl学习
- 打乱数据集
- 是否类别失衡(需要做解决类别失衡的问题)
- 确保数据集不是单一的标签
- 减少训练的batch size 到合适的大小( 8/ 32 / 64)
3.3 数据归一化
- 归一化特征( 我们需要对数据进行规范化的主要原因是大部分的神经网络流程假设输入和输出数据都以一个约是1的标准差和约是0的均值分布。这些假设在深度学习文献中到处都是,从权重初始化、激活函数到训练网络的优化算法。)
- 模型数据是否足够(是否一直欠拟合)
3.4 实现的问题
- 试着解决问题的更简单的版本
- 检查损失函数 ( 自己实现的损失函数,增加测试单元)
- 核实损失函数输入 ( with softmax or without softmax)
- 利用其他指标来监控模型,例如精度等
- 检查是否在一些层无意中阻止了梯度的更新
- 扩大网络规模
- 探索维度误差
3.5 训练问题
- 使用一个真正小的数据集,确保能正常工作
- 检查权重的初始化,使用Xavier或者其他初始化
- 改变超参
- 减小正则化
- 尝试使用不同的优化器 ,例如从Adam换到SGD
- 提督爆炸或者消失 ( 监控提督,同时进行梯度阶段)
- 增加减小学习率
- 神经网络梯度太深

