
- 1Claude 3是什么?与GPT-4相比有什么优势?
- 2前端开发基础(3)—JavaScript_什么是javascript,它在前端开发中的角色是什么?
- 3USB驱动之Android usb鼠标驱动_安卓鼠标驱动
- 4鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Column)
- 5微信小程序如何跳转视频号直播间_小程序能跳转视频号吗
- 6在html中列表是块元素还是,HTML基础知识4-列表及表单的写法、块级元素和内联(行内)元素的区别...
- 7Spring 常用依赖以及使用demo_org.springframework.stereotype.service
- 8Nodejs 应用编译构建提速建议 | 京东云技术团队_node turbo
- 9将Linux curl命令转换为windows平台的Python代码
- 10VIM配置攻略(最强干货!!!!)_spacevim作者
【深度学习】基于PyTorch架构神经网络学习总结(基础概念&基本网络搭建)_pytorch 学习架构
赞
踩
神经网络整体架构
类似于人体的神经元

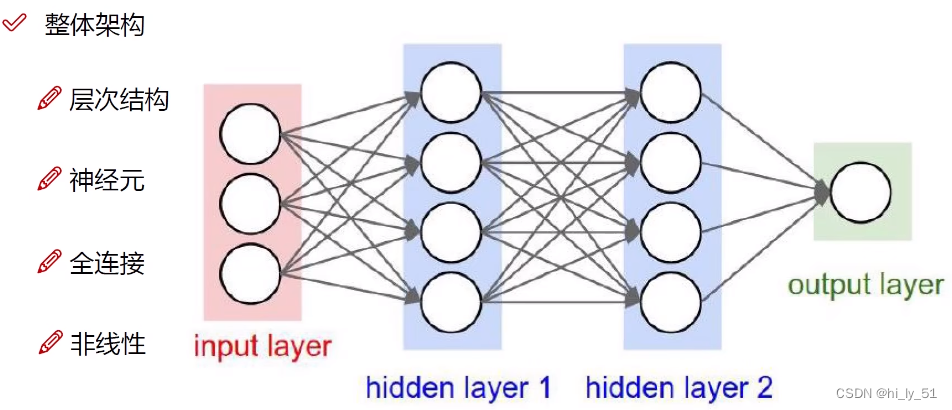
- 神经网络工作原来为层次结构,一层一层的变换数据。如上述示例有4层,1层输入层、2层隐藏层、1层输出层
- 神经元:数据的量或矩阵的大小,如上述示例中输入层中有三个神经元代表输入数据有3个特征值,输出层有1个神经元表明得到一个结果,若对于分类结果输出层一般有多个神经元
- 全连接:每一个神经元都与上一层中所有的神经元有关,权重参数矩阵
- 非线性:使用非线性函数进行数据映射,如max函数等
神经网络的强大之处即使用更多的参数来拟合复杂的数据
nn.Module的使用
利用PyTorch架构使用神经网络模型时,一般是利用torch.nn函数
自定义神经网络框架 | 官方示例:
- import torch.nn as nn
- import torch.nn.functional as F
-
- class Model(nn.Module):
- def __init__(self):
- super().__init__()
- self.conv1 = nn.Conv2d(1, 20, 5)
- self.conv2 = nn.Conv2d(20, 20, 5)
-
- def forward(self, x):
- x = F.relu(self.conv1(x))
- return F.relu(self.conv2(x))
对于forward函数相对于是用来说明神经网络中的处理过程,如进行卷积运算的次数与类型等,也可以进行简单的数据处理,如下:
- import torch
- from torch import nn
- '''自定义神经网络'''
- class NN_Test1(nn.Module):
- def __init__(self):
- super().__init__()
-
- def forward(self,input):
- output=input+1
- return output
-
- nn_test1=NN_Test1()#实例化类 获得一个对象
- x=torch.tensor(1.0)
- output=nn_test1(x)
- print(output)
卷积层(convolution)

-
stride参数用于设置卷积核在图像中的运行步数,如果为单个整数则说明横向纵向都是一样的,也可以设置为元组,(H,W)(横向、纵向)默认为1
-
padding:进行填充
使用示例:
- import torch
- import torch.nn.functional as F
- input=torch.tensor([[1,2,0,3,1],
- [0,1,2,3,1],
- [1,2,1,0,0],
- [5,2,3,1,1],
- [2,1,0,1,1]])##输入自定义的二维矩阵
- kernel=torch.tensor([[1,2,1],
- [0,1,0],
- [2,1,0]])#卷积核
- input=torch.reshape(input,(1,1,5,5))
- ##由于输入的格式为(batchsize,通道数,行数,列数)
- kernel=torch.reshape(kernel,(1,1,3,3))
-
- output=F.conv2d(input,kernel,stride=1)
- print(output)
- output2=F.conv2d(input,kernel,stride=2)
- print(output2)
输出效果:


-
dilation:设置卷积核的间隔,一般设置为1,在空洞卷积处会进行设置
-
bias:是否加以常数偏置 一般设置为true
-
kernel-size:在卷积过程中会不断的进行调整以寻找最佳
-
当out-channels与input-channels不同时,会将卷积核复制(可能有所变化)在进行运行将此次结果做出输出的一个通道
当论文中未给padding和stride参数的时候则需要根据以下的公式进行计算得到参数的值

示意图如下:

最大池化层(Pooling layers)
对应于pytorch中的torch.nn的Maxpooling2d 下采样

stride参数的默认值与卷积层的默认值不同,stride值在池化层中与卷积核的大小一致,即卷积核移动的大小与卷积核的大小一致;
dilation:空洞卷积,dilation设置空洞的大小,一般情况下不进行设置;
ceil_mode:为True时使用ceil模式,反之使用floor模式。这两种模式的示意图如下,即为ceil模式时进行向上取值,为floor时向下取值;
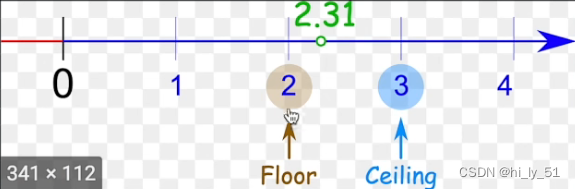
对于卷积核移动时会出现边界处卷积核内有不存在的值,当ceil_model为True时则该处得到的值保存,否则不保存。
为什么要进行最大池化??/最大池化的目的?
保留输入的特征同时将数据量减少
非线性激活
以ReLU为例


当inplace为true时input的值将直接进行替换;为false时则原值不改,有一个新值获取结果值;

一般inplace为false,可以保留原始数据防止数据的丢失,即默认值即可
对图像的作用:
给神经网络中引入非线性的特质,非线性特性越多的话才可以更好的训练得到符合各种曲线和特性的模型,提高泛化能力。
线性层及其他层
正则化层
使用该层可以加快神经网络的训练速度;
Recurrent Layers层
主要用于文字识别的网络结构;特定的网络结构;根据具体需要使用,大多数使用情况不太多用;
线性层
- import torch
- import torchvision
- from tensorboardX import SummaryWriter
- from torch import nn
- from torch.nn import Linear
- from torch.utils.data import DataLoader
-
- dataset=torchvision.datasets.CIFAR10(root="./dataset",train=False,
- transform=torchvision.transforms.ToTensor(),download=True)
- dataloader=DataLoader(dataset,batch_size=64)
-
- class Linear_class(nn.Module):
- def __init__(self):
- super().__init__()
- self.linear1=Linear(196608,10)
-
- def forward(self,input):
- output=self.linear1(input)
- return output
- linear_1=Linear_class()
- writer=SummaryWriter("logs_linear")
- for data in dataloader:
- imgs,targets=data
- # output=torch.reshape(imgs,(1,1,1,-1))
- output=torch.flatten(imgs)
- '''上述两行皆是将数据展开为一行
- reshape可以指定尺寸进行变换
- flatten只能变为一行'''
- output=linear_1(output)
- print(output.shape)
可以确定输入输出数据的大小,即如上输入较大数据输出数据格式为10
dropout层
主要是防止过拟合
Spase层
主要用于处理自然语言
sequential & 实例操作
将下面的模型结果进行复现

tips:在进行展开后需要进行一个线性层得到64个数据,后再运行一个线性层得到10个
- '''未使用sequential时'''
- import torch
- from torch import nn
- from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
-
-
- class module_test(nn.Module):
- def __init__(self):
- super().__init__()
- self.conv1=Conv2d(3,32,5,padding=2)
- '''对于padding与stride是否需要进行修改
- 需要根据想要构建的模型自行进行计算'''
- self.maxpool1 = MaxPool2d(2)
- self.conv2 = Conv2d(32, 32, 5, padding=2)
- self.maxpool2 = MaxPool2d(2)
- self.conv3 = Conv2d(32, 64, 5, padding=2)
- self.maxpool3 = MaxPool2d(2)
- self.flatten=Flatten()
- self.linear1=Linear(1024,64)
- self.linear2=Linear(64,10)
- def forward(self,x):
- x=self.conv1(x)
- x=self.maxpool1(x)
- x=self.conv2(x)
- x=self.maxpool2(x)
- x = self.conv3(x)
- x = self.maxpool3(x)
- x = self.flatten(x)
- '''在此处不知经过展开后其数据大小时
- 可以在检验时进行试运行来获得其大小'''
- x = self.linear1(x)
- x = self.linear2(x)
- return x
- test1=module_test()
- print(test1)
- '''
- 如下为自己构建符合输入格式的数据来
- 进行所构建模型的检验
- '''
- input=torch.ones((64,3,32,32))##构建一个数据 全为1 且设置其形状
- output=test1(input)
- print(output.shape)
输出效果如下:

- '''加以sequential帮助完成模型的构建'''
- import torch
- from torch import nn
- from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
-
-
- class module_test(nn.Module):
- def __init__(self):
- super().__init__()
- self.model1=Sequential(
- Conv2d(3, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32,64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
-
- def forward(self,x):
- x=self.model1(x)
- return x
- test1=module_test()
- print(test1)
- '''
- 如下为自己构建符合输入格式的数据来
- 进行所构建模型的检验
- '''
- input=torch.ones((64,3,32,32))##构建一个数据 全为1 且设置其形状
- output=test1(input)
- print(output.shape)
将会自动运行sequential中所构建的层

- '''进行可视化网络结构'''
- writer=SummaryWriter("logs_sequential")
- writer.add_graph(test1,input)
- writer.close()
主要使用的是add_graph这个函数,效果如下,可以在网页中双击后进行放大查看
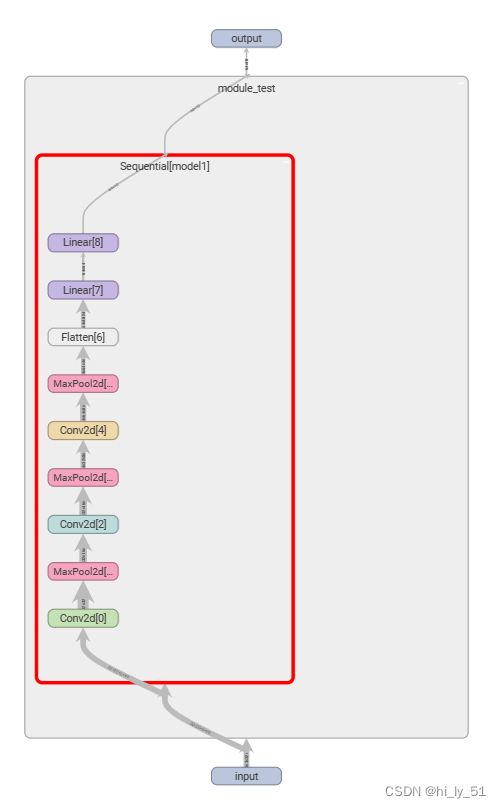
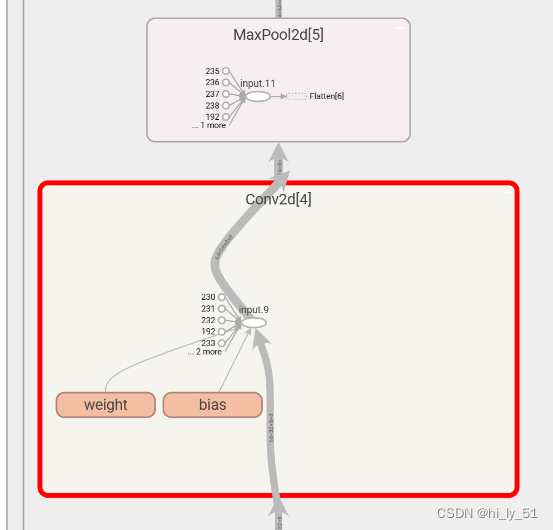
损失函数与反向传播
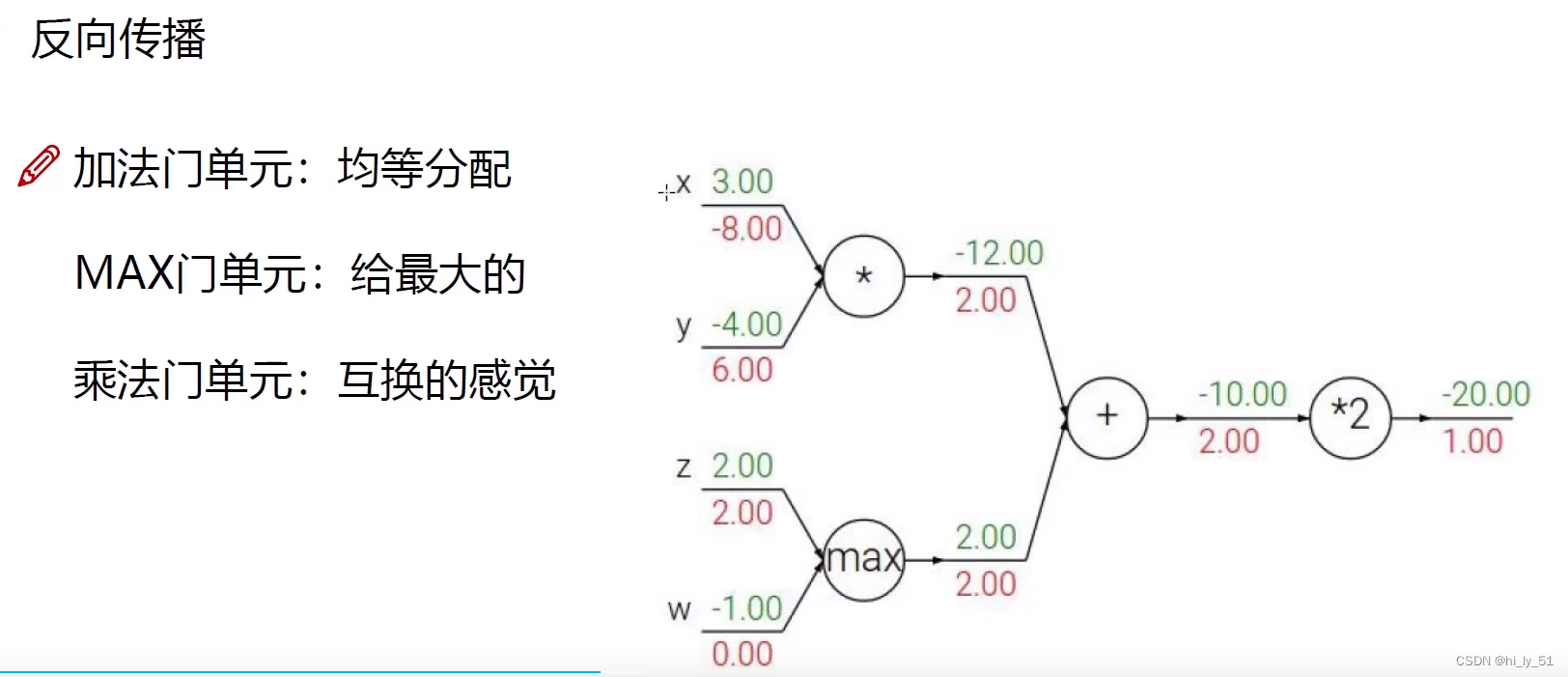
反向传播主要是利用链式法则,将梯度从后往前逐步传播,梯度也是一步一步传的
常见的门单元
-
加法门单元:梯度均等分配;
-
MAX门单元:将梯度给最大值,较小值没有获得;
-
乘法门单元:互换的感觉
在torch中自己存在一些损失函数如下:
-
L1Loss——平均误差
-
MSEloss——平方均差
-
CrossEntropyLoss——交叉熵 对于分类问题可以使用该损失函数
在使用损失函数的时候需要按照需求去使用,需要注意输入的形状与输出的形状。
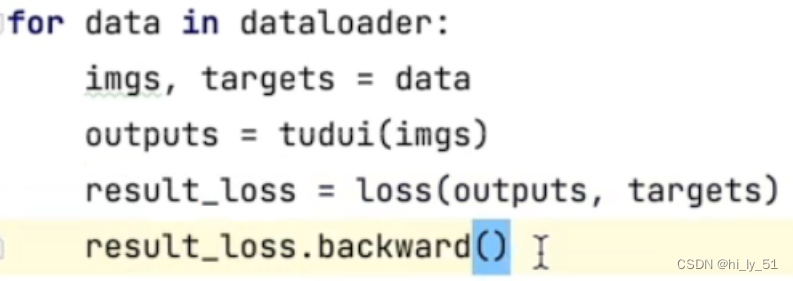
在使用损失函数后对其结果进行反向传播,即使用beakward() 反向传播时自动根据梯度下降的原理进行权重等参数的更新,若没有反向传播将不会进行梯度的更新
e.g:
优化器
对于pytorch所给出的所有优化器,对于入门阶段则仅需设置params和学习速率即可。之后的一些参数选择使用默认参数或者其他人使用的参数即可。
- import torch
- import torchvision
- from torch import nn
- from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
- dataset=torchvision.datasets.CIFAR10(root="./dataset",train=False,
- transform=torchvision.transforms.ToTensor(),download=True)
- dataloader=DataLoader(dataset,batch_size=1)
- class module_test(nn.Module):
- def __init__(self):
- super().__init__()
- self.model1=Sequential(
- Conv2d(3, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32,64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
- def forward(self,x):
- x=self.model1(x)
- return x
- loss=nn.CrossEntropyLoss()
- module1=module_test()
- '''定义优化器'''
- optimize1=torch.optim.SGD(module1.parameters(),lr=0.01)##其他参数可以不用设置
- '''对每轮都进行循环'''
- for epoch in range(20):#训练19轮
- running_loss=0.0
- for data in dataloader:
- imgs,targets=data
- outputs=module1(imgs)
- result_loss=loss(outputs,targets)
- '''使用优化器进行调优'''
- optimize1.zero_grad()#对每个结点的梯度进行清零
- result_loss.backward()#损失函数进行反向传播
- optimize1.step()#对每个参数进行调优
- running_loss=running_loss+result_loss
- print(epoch+"轮的误差之和为:"+running_loss)
现有模型的修改与使用
在pytorch官方文档中,torchaudio主要是处理语音;torchtext处理文本;torchvision处理图像。在pytorch官方中已经有提供的模型来进行使用。

以torchvision中的vgg16为例进行参数说明
当pretrained参数
-
为true时:在imagenet数据集中已经训练好了数据;在运行时会不会加载网络模型
为true所得到的参数为已经在数据集中训练了并且有一个较好效果的参数;
-
为false时则为一个初始化的数据,未在任何数据集中进行训练。在运行时会先加载网络模型
为false时的参数相对于是默认参数,未经过训练得到的参数;
progress参数,为true则显示下载进度条,反之不显示
对于ImageNet数据集以及未公开,需要自己去网络中下载
较多框架都会把VGG16做为一个前置的网络结构,即使用VGG16来提取一些特殊的特征,再在VGG16后加一些网络结构来实现一些功能。

对于VGG16,其对于图像的处理最终会将图像分为1000个类别。但是,如果需要分类的结果不是1000个类别则需要修改其网络结构,有以下两种方法进行更改:
-
对原始的网络结构进行修改
-
在其原本的网络结构后添加一个线性层,即输入为1000,输出为所需要的类别数
- '''直接在最后加一个网络层'''
- vgg16_true=torchvision.models.vgg16(pretrained=True)
- vgg16_true.add_module("add_linear",nn.Linear(1000,10))
- print(vgg16_true)
修改神经网络后运行结果如下,此时最终输出类别10个:

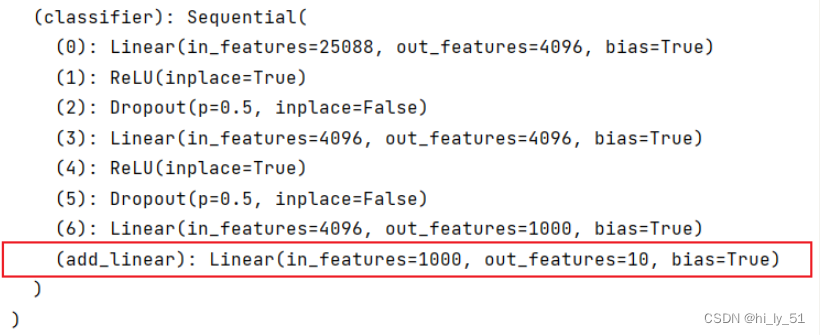
- '''想在classifier序列中加一个网络层'''
- vgg16_true=torchvision.models.vgg16(pretrained=True)
- vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
- print(vgg16_true)
输出结果:
- '''对原始模型进行修改'''
- vgg16_false=torchvision.models.vgg16(pretrained=False)
- vgg16_false.classifier[6]=nn.Linear(4096,10)
- print(vgg16_false)
输出结果: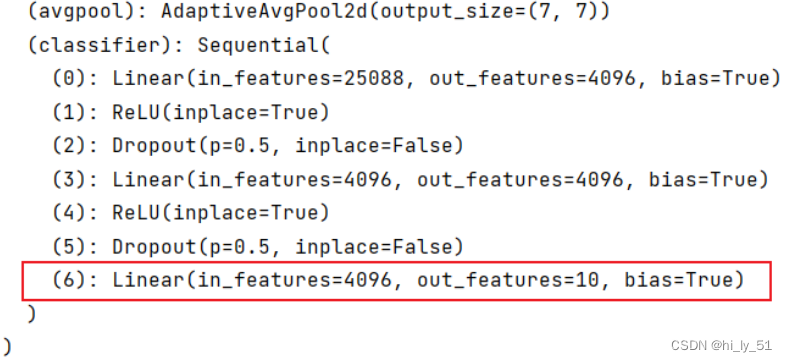
网络模型的保存与读取
保存方式:
- import torch
- import torchvision
-
- vgg16=torchvision.models.vgg16(pretrained=False)
- '''#保存方式1 模型结构+模型参数
- 其后缀格式任意都行,常用pth
- 保存时不仅保存了网络模型(网络结构),还保存了网络模型中的参数
- '''
- torch.save(vgg16,"vgg16_method1.pth")
-
- '''保存方式2 模型参数(官方推荐)
- 将模型的状态(网络模型的参数)保存为字典形式
- 不保存网络模型的结构而是保存其参数'''
- torch.save(vgg16.state_dict(),"vgg16_method2.pth")
加载方式:
- import torch
- import torchvision.models
-
- '''加载方式1 对应于保存方式1'''
- model1=torch.load("vgg16_method1.pth")
-
-
- '''加载方式2 对应于保存方式2'''
- vgg16=torchvision.models.vgg16(pretrained=False)
- vgg16.load_state_dict(torch.load("vgg16_method2.pth"))##通过字典参数的形式来加载模型
- model2=torch.load("vgg16_method2.pth")
陷阱
对自己创建的模型进行实例化与保存后,在进行模型加载时,可能会出现报错!!
在加载数据的时候,需要将模型的定义也允许,即定义类结构,使之保证模型是所需要的模型
完整的模型训练套路
- import torch.optim
- import torchvision
- from sympy.solvers.diophantine.diophantine import Linear
- from torch import nn
- from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
-
- import model
-
- '''准备数据集'''
- train_data=torchvision.datasets.CIFAR10(root="./dataset",train=True,
- transform=torchvision.transforms.ToTensor(),download=True)
- test_data=torchvision.datasets.CIFAR10(root="./dataset",train=False,
- transform=torchvision.transforms.ToTensor(),download=True)
- ##查看数据集的长度 即大小 张数
- train_data_size=len(train_data)
- test_data_size=len(test_data)
- print("训练数据集的长度为:{}".format(train_data_size))#字符串格式化
- print("测试数据集的长度为:{}".format(test_data_size))
-
- '''利用dataloader来加载数据集'''
- train_dataloader=DataLoader(train_data,batch_size=64)
- test_dataloader=DataLoader(test_data,batch_size=64)
-
- '''搭建神经网络 通常网络模型会自己放在一个文件中
- 需要引入model文件 且这两个文件需要在同一个文件夹下面'''
- from model import *
- model1=model.model_test()
-
- '''损失函数'''
- loss_fn=nn.CrossEntropyLoss()##交叉熵损失函数
-
- '''优化器'''
- learning_rate=0.01##设置优化器的学习速率
- optimizer=torch.optim.SGD(model1.parameters(),lr=learning_rate)##随机梯度下降
-
- '''设置训练网络的参数'''
- total_train_step=0#记录训练的次数
- total_test_step=0#记录测试次数
- epoch=10##训练轮数
-
- ##添加tensorboard
- writer=SummaryWriter("logs_train1")
-
-
- for i in range(epoch):
- print("----------第{}轮训练开始----------".format(i+1))
- ##训练步骤开始
- model1.train()
- for data in train_dataloader:
- imgs,targets=data
- outputs=model1(imgs)
- loss=loss_fn(outputs,targets)##将预测值与真实值放入
-
- ####优化器调优
- optimizer.zero_grad()###优化器梯度清零
- loss.backward()##反向传播
- optimizer.step()#参数优化
-
- ##已经训练了一次
- total_train_step+=1
- ###并不是每次都打印 避免无用信息
- if total_train_step%100==0:
- print("训练次数:{},loss:{}".format(total_train_step,loss.item()))
- writer.add_scalar("train_loss",loss.item(),total_train_step)
- ## loss.item()---→将tensor数据类型转为真实的数字
-
-
- '''进行测试 开始测试'''
- model1.eval()
- total_test_loss=0
- total_accuracy=0#整体正确个数
- with torch.no_grad():###对于该部分的代码没有梯度 使之无法调优
- for data in test_dataloader:
- imgs, targets = data
- outputs = model1(imgs)
- loss = loss_fn(outputs, targets) ##将预测值与真实值放入
- ###此处得到的仅为一部分数据在网络模型中得到的损失
- total_test_loss=total_test_loss+loss.item()##将每次的loss加入到整体的loss上
- '''计算正确率'''
- accuracy=(outputs.argmax(1)==targets).sum()##得到判断正确的数量
- total_accuracy=total_accuracy+accuracy
- print("整体测试集上的loss:{}".format(total_test_loss))
- print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
-
- writer.add_scalar("test_loss", total_test_loss, total_test_step)
- writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
-
- total_test_step=total_test_step+1
-
- ###将每一轮训练的模型保存
- torch.save(model1,"model_train{}.pth".format(i))
- # torch.save(model1.state_dict(),"model_train{}.pth".format(i))
-
- print("模型已保存!!")
- writer.close()
对于一些特色的层 如dropout层等,训练前要开启train()状态,测试前要eval()状态
如何判断模型是否训练完毕?或者是否达到需求?
→→→→在每次训练完一次后进行一次测试,使之在测试数据集上运行一次,以测试数据集上的损失/准确率来评估模型是否训练完毕。 在测试过程中不需要对模型进行调优了,利用现有的模型来进行测试
可以添加tensorboard 将每次的数据绘制处理
对于分类问题,可以使用正确率来表示在测试集上的表现效果
在语义分割或者目标检测问题,最简单的即为把得到的输出直接在tensorboard中显示,来看到测试结果
利用GPU训练
方式1 .cuda()
只有网络模型、损失函数以及数据有GPU训练的方法
- model1=model_test()
- if torch.cuda.is_available():
- model1.cuda()
- ……………………
- '''损失函数'''
- loss_fn=nn.CrossEntropyLoss()##交叉熵损失函数
- if torch.cuda.is_available():
- loss_fn=loss_fn.cuda()
- ………………
- for data in train_dataloader:
- imgs,targets=data
- if torch.cuda.is_available():
- imgs=imgs.cuda()
- targets=targets.cuda()
- outputs=model1(imgs)
- loss=loss_fn(outputs,targets)##将预测值与真实值放入
- ……………………
- for data in test_dataloader:
- imgs, targets = data
- if torch.cuda.is_available():
- imgs = imgs.cuda()
- targets = targets.cuda()
- outputs = model1(imgs)
- loss = loss_fn(outputs, targets)
但是如果电脑上没有相关的GPU将无法运行,可以先进行判断GPU是否可用后进行操作,如下
if torch.cuda.is_available(): model1.cuda()
谷歌google colab提供了免费的GPU 前提是可以访问Google
方式2 .to() 更加常用
device=torch.device("cuda")#在GPU上运行
对于多个显卡的电脑,device=torch.device("cuda:0")表示使用第一个显卡运行,与上面的一样 device=torch.device("cuda:1")使用第二个显卡
- '''定义训练的设备'''
- device=torch.device("cpu")#在CPU上运行
- ....
- model1=model_test()
- model1=model1.to(device)
- ...
- for data in train_dataloader:
- imgs,targets=data
- imgs=imgs.to(device)
- targets=targets.to(device)
- outputs=model1(imgs)
- ..
- for data in test_dataloader:
- imgs, targets = data
- imgs = imgs.to(device)
- targets = targets.to(device)
- outputs = model1(imgs)
对于模型与损失函数不需要后续赋值,只有数据、图片与标注需要进行再次赋值来覆盖原来变量
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
完整的模型验证套路
将模型运用到实际中
- import torch
- import torchvision.transforms
- from PIL import Image
- from torch import nn
- from torch.nn import Sequential
-
- image_path="./images/dog.jpg"###真实的图片
- image=Image.open(image_path)
- print(image)
- '''保留其图片的颜色通道
- 如果图片原本就有三个颜色通道 经过此操作后不变
- 加上这步后适应于png jpg各种格式的图片 '''
- image=image.convert('RGB')
- ##Compose函数将transform的几个变换联立在一起
- ##Resize函数 输入为PIL数据类型形成的为PIL数据类型 输入的为tensor数据出一致
- transform=torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
- torchvision.transforms.ToTensor()])
- image=transform(image)
- print(image.shape)
- '''加载网络模型'''
- class model_test(nn.Module):
- def __init__(self):
- super().__init__()
-
- self.model1=Sequential(
- nn.Conv2d(3, 32, 5, padding=2),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 32, 5, padding=2),
- nn.MaxPool2d(2),
- nn.Conv2d(32,64, 5, padding=2),
- nn.MaxPool2d(2),
- nn.Flatten(),
- nn.Linear(1024, 64),
- nn.Linear(64, 10)
- )
-
- def forward(self,x):
- x=self.model1(x)
- return x
-
- model=torch.load("model_train0.pth")
- print(model)
-
- image=torch.reshape(image,(1,3,32,32))
- model.eval()
- with torch.no_grad():##该步骤可以节约内存和性能
- output=model(image)
- print(output)
-
- print(output.argmax(1))##将输出转为便于解读的方式

