
- 1BERT用于序列到序列的多标签文本分类_vanilla bert
- 2电脑装系统如何选择版本(w10安装多个版本sqlserver的步骤)_安装两个sqlserver
- 3Hive配置Spark计算引擎,速度快!_hive使用spark引擎
- 4宝塔面板部署腾讯云的域名
- 5Flask+Echarts搭建全国疫情可视化大屏_疫情大屏
- 651单片机程序存储器和数据存储器_8051单片机的存储器分为哪几个空间?中断服务程序的入口地址分别是什么?
- 7MySQL面试精华汇总
- 8Python flask请求上下文(RequestContext)和应用上下文(AppContext)_python app_context
- 9通过权威数据共享使跨政府变得成功_数据资源共享的例子
- 10Create2024百度AI开发者大会记录
[Java集合篇]Collection单列集合和Map双列集合知识点汇总_单列集合和双列集合
赞
踩
[Java集合篇] Collection 单列集合(ArrayList、LinkedList、HashSet、TreeSet)和 Map 双列集合(HashMap、ConcurrentHashMap 、Hashtable)的区别与遍历
写在前面
1. 为什么会出现集合
数组的长度是固定的,当添加的元素超过了数组的长度时需要对数组重新定义,而集合能存储任意对象,长度是可以改变的,随着元素的增加而增加,随元素的减少而减少。
2.数组和集合的区别
- 区别1 :
- 数组既可以存储基本数据类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值。
- 集合能存储引用数据类型(对象)集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象。
- 区别2:
- 数组长度是固定的,不能自动增长。
- 集合的长度的是可变的,可以根据元素的增加而增长。
- 数组和集合什么时候用?
- 1.如果元素个数是固定的推荐用数组。
- 2.如果元素个数不是固定的推荐用集合。
1. Collection 单列集合
Collection 作为单列集合的根接口,子接口List 和 Set 接口均继承父类 Collection 接口。
2. List 集合接口下的子类
在List接口下,我们常用的子类有三个,分别是ArrayList、LinkedList 和 Vector,List 集合中元素是有序的,存和取的顺序一致,有索引,可以存储重复元素。
2.1 ArrayList(优先考虑)
-
ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
-
线程不安全,效率高。
2.2 Vector(JDK 1.0出现,线程安全)
- 底层数据结构是数组,查询快,增删慢。
- 线程安全,效率低。
- Vector相对ArrayList查询慢(线程安全的)。
- Vector相对LinkedList增删慢(数组结构)。
2.3 LinkedList
- 底层数据结构是链表,查询慢,增删快。
- 线程不安全,效率高。
2.4 Vector和 ArrayList 的区别
- Vector是线程安全的,效率低。
- ArrayList是线程不安全的,效率高。
共同点:都是数组实现的。
2.5 ArrayList和LinkedList的区别(常见面试题)
- ArrayList底层是数组结构,查询和修改快,时间复杂度为1。
- LinkedList底层是链表结构的,增和删比较快,查询和修改比较慢,时间复杂度为n。
共同点:都是线程不安全的。
3. ArrayList集合的四种遍历方法
ArrayList的遍历方法可以总结为以下四种形式,分别是迭代器迭代实现、增强for循环实现、通过索引实现、通过集合转换为数组进行遍历数组实现。显然,我们在开发中优先采用的是前两种遍历方式来实现。
public static void arrayList() { ArrayList<String> list = new ArrayList<>(); list.add( "a" ); list.add( "b" ); list.add( "a" ); list.add( "d" ); list.add( "e" ); //迭代器迭代(推荐) Iterator<String> it = list.iterator(); while (it.hasNext()) { String values = it.next(); System.out.println( values ); } System.out.println( "=====================" ); //增强for循环(推荐) for (String string : list) { System.out.println( string ); } System.out.println( "=====================" ); //通过索引遍历 for (int i = 0; i < list.size(); i++) { System.out.println( list.get( i ) ); } System.out.println( "=====================" ); //将集合转换为数组进行遍历 Object[] strings = list.toArray(); for (Object string : strings) { System.out.println( string ); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4. Set集合接口下的子类
Set 接口下的两个常用子类是 HashSet(无序存储,底层哈希算法实现)、 TreeSet(有序存储,底层二叉树算法实现)和 LInkedHashSet 集合。
Set 接口与 List 接口最大的区别就是 Set 接口的内容不允许重复元素的存和取是无序的,及存和取的顺序不一致,没有索引的存在,也不可以存储重复的元素。
4.1 HashSet 原理(如何保证元素的唯一性)
- 使用 Set 集合都是需要去掉重复元素的,如果在存储的时候逐个 equals() 比较,效率肯定很低,哈希算法提高了去重的效率,进而降低了使用 equals() 方法的次数。
- 当 HashSet 调用 add() 方法存储对象的时候,先调用对象的 hashCode() 得到一个哈希值,然后在集合中查找是否有哈希值相同的对象:
- 如果没有哈希值相同的对象就直接存入到集合当中;
- 如果有哈希值相同的对象,就和哈希值相同的对象逐个进行equals() 比较,比较结果为false就存入,true则不存。
- 对于LinkedHashSet 是HashSet 的子类,底层是链表实现,也可以保证元素的唯一性,和HashSet 原理一样。
4.2 自定义类的对象存储到 HashSet 去重复
- 类中必须重写hashCode() 和equals() 方法。
- 当 hashcode 值相同时,才会调用 equals() 方法。
- 对于两个对象相同而言,必须 hashCode() 和equals() 方法的返回值都相同才能判断为相同,二者缺一不可。
4.3 TreeSet有序存储
-
底层是二叉树算法实现,一般在开发中不需要对存储的元素进行排序,所以在开发的时候大多用HashSet ,并且HashSet 的效率比较高,推荐使用。
-
TreeSet 是用来排序的,可以指定一个顺序,对象存入之后会按照指定的顺序排序。
-
使用方式:
<1> 自然顺序(Comparable)
TreeSet 类的add() 方法中会把存入的对象提升为Compara 类型;
调用对象的comparaTo() 方法和集合中的对象进行比较;
根据comparaTo() 方法的返回的结果进行存储,返回0,集合中只有一个元素;返回正数,集合怎么存就怎么取;返回负数,集合倒序存储。
<2>比较器顺序(Comparator)
创建TreeSet 的时候可以制定一个Comparator;
如果传入了Comparator 的子类对象,那么TreeSet 就会按照比较器中的顺序排序;
add() 方法内部会自动调用Comparator 接口中的compare() 方法排序。
<3>两种方式的区别
TreeSet构造函数什么都不传,默认按照类中Comparable 的顺序(没有就报错ClassCastExcep);
TreeSet 传入Comparator ,就优先按照Comparator 接口中的compare() 方法排序。 -
举例:比较器比较代码实现
public static void intSort() { /* * 程序启动后可以从键盘输入多个整数,直到输入quit结束,把所有输入的整数倒序打印出来 * */ //1.创建Scanner对象,键盘录入 Scanner sc = new Scanner( System.in ); System.out.println( "请输入整数:" ); //2.创建TreeSet集合对象,传入比较器 TreeSet<Integer> treeSet = new TreeSet<>( new Comparator<Integer>() { @Override public int compare(Integer i1, Integer i2) { //int num = i2 - i1; //自动拆箱 int num = i2.compareTo( i1 ); return num == 0 ? 1 : num; } } ); //以字符串的形式无限循环接收整数,直到输入quit退出 while (true) { String line = sc.nextLine(); if ("quit".equals( line )) { break; } //4.判断是quit就退出,不是将其转换为Integer,并添加到集合 Inreger i = Integer.parseInt( line ); treeSet.add( i ); } //5.遍历集合并打印 for (Integer integer : treeSet) { System.out.println(integer); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.4 LinkedHashSet集合
对于 LinkedHashSet 而言,继承于HashSet ,又基于 LinkedHashMap来实现的。底层使用 LinkedHashMap 来存储所有的元素,并用双向链表记录插入顺序,其所有的方法操作上与HashSet 相同,因此LinkedHashSet 的实现非常简单,在此不多赘述。
5. HashSet 与 TreeSet 集合的两种遍历方法
HashSet 与 TreeSet 集合的两种遍历方式都是通过迭代器迭代遍历和通过增强for 循环遍历,两种方式均推荐使用,TreeSet遍历方式与之类似,在此不再展示。
//HashSet遍历方法 public static void hashSet() { HashSet<String> hashSet = new HashSet<>(); hashSet.add( "a" ); hashSet.add( "b" ); hashSet.add( "i" ); hashSet.add( "g" ); //通过迭代器迭代 Iterator<String> it = hashSet.iterator(); while (it.hasNext()) { System.out.println( it.next() ); } //通过增强for循环遍历 for (String values : hashSet) { System.out.println( values ); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6. Map双列集合下的子类
Map接口下常用的子类有HashMap 、TreeMap 、Hashtable 和 ConcurrentHashMap 实现类,Map集合可以存储一对对象,即会一次性保存两个对象,存在key = value 结构,其最大的特点还是可以通过key 找到对应的value 值。
6.1 HashMap 原理(常用)
- HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
- HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
- HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。我们用下面这张图来介绍 HashMap 的结构。(图片来源于网络)
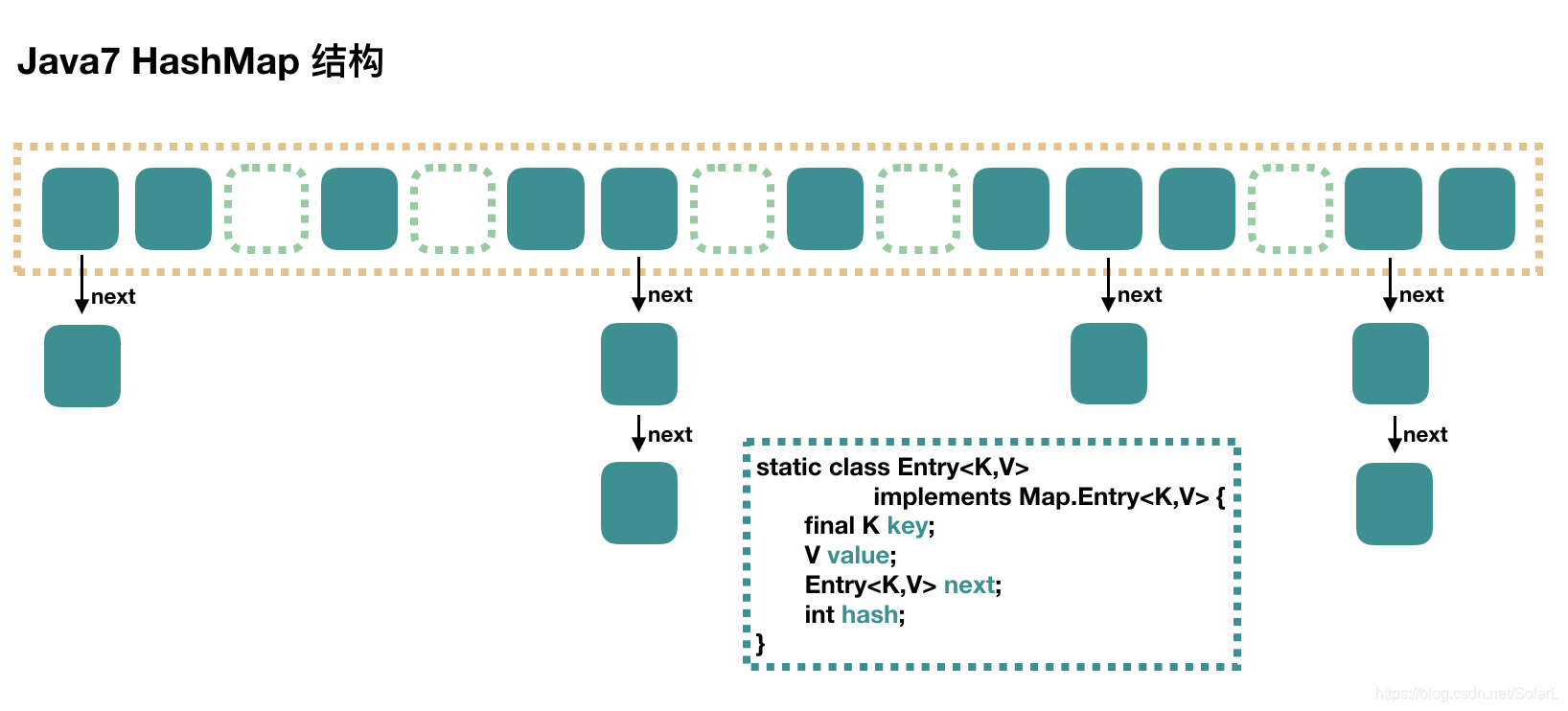
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
- capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
- loadFactor:负载因子,默认为 0.75。
- threshold:扩容的阈值,等于 capacity * loadFactor
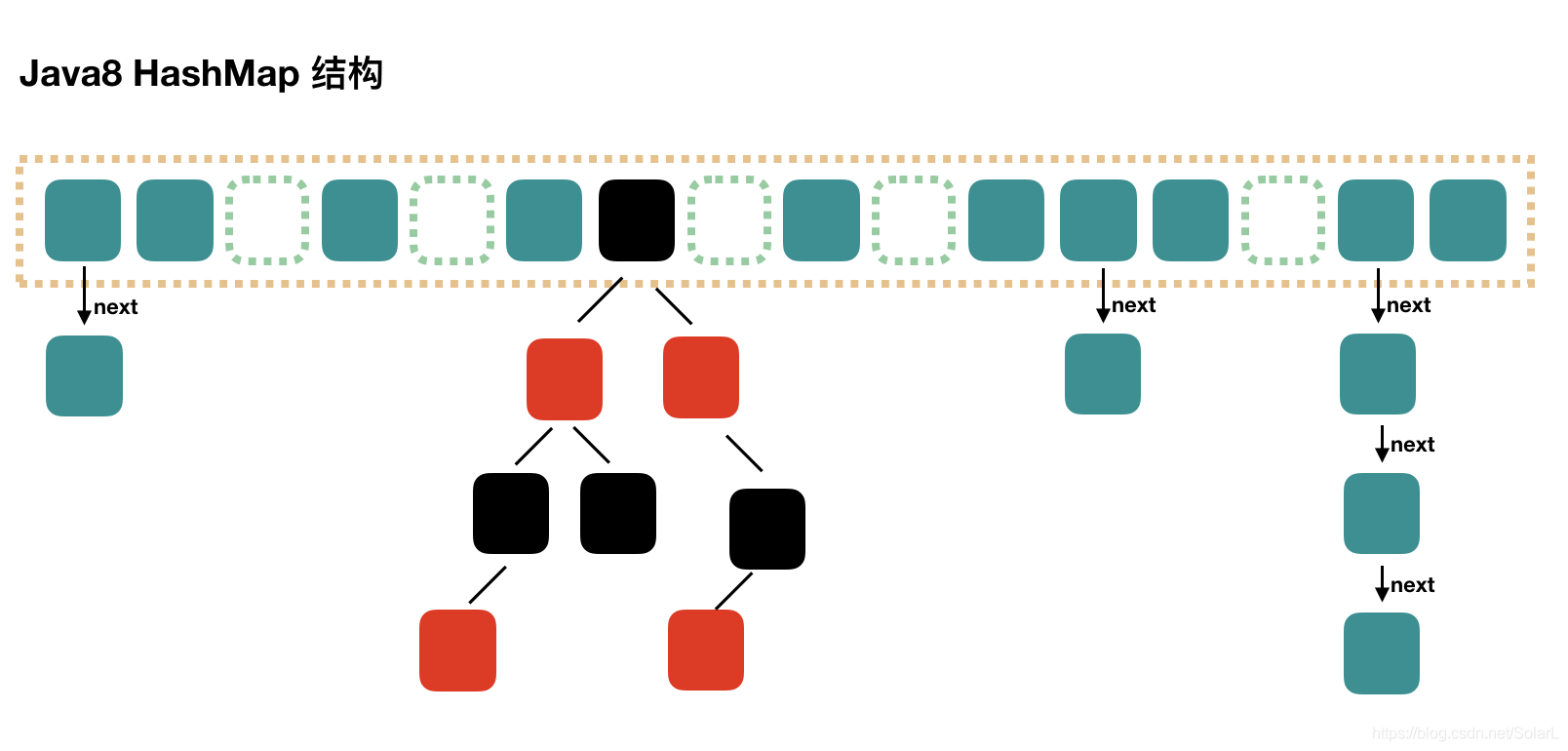
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。 根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。 为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
6.2 TreeMap
- TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的结果是排过序的。
- 如果使用排序的映射,建议使用TreeMap。
- 在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
6.3 Hashtable
- Hashtable 在JDK 1.0出现,犹如Vector ,很多映射的常用功能与HashMap类似,不同的是它继承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。
- Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
- Hashtable 的键和值都不允许有null 值。
6.4ConcurrentHashMap
- ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。简单理解就是,ConcurrentHashMap 是一个 Segment 数组,它的内部细分了若干个小的 HashMap ,我们称之为段Segment,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
- Segment 的大小也被称为ConcurrentHashMap 的并发度,默认情况下一个ConcurrentHashMap被进一步细分为16个段,既就是锁的并发度。
- ConcurrentHashMap 的并发处理其实采用的技术是减少锁粒度。缩小锁定对象的范围,从而减小锁冲突的可能性,进而提高系统的并发能力。
- ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
6.5 LinkedHashMap
- LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
7. HashMap 集合的四种遍历方法
Map集合子类的遍历方法基本类似,这里就只展示HashMap 集合的遍历方法,其他可参考以下代码实现遍历。
//HashMap遍历方法 public static void hashMap() { Map<Integer, String> map = new HashMap<>(); map.put( 0, "q" ); map.put( 1, "a" ); map.put( 2, "b" ); map.put( 5, "t" ); map.put( 3, "k" ); //根据键获取值(第一种) Set<Integer> keyset = map.keySet(); //获取所有键的值 //获取迭代器 Iterator<Integer> it = keyset.iterator(); while (it.hasNext()) { Integer key = it.next(); //获取每一个键 String value = map.get( key ); //根据键获取值 System.out.println( key + " " + value ); } //增强for循环遍历(第二种) for (Integer key : keyset) { System.out.println( key + " " + map.get( key ) ); } //根据键值对对象获取键和值 //Map.Entry说明 Entry是 Map的内部接口,将键和值封装成了 Entry对象,并存储到 Set集合中 Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); //迭代器遍历(第三种) Iterator<Map.Entry<Integer, String>> iterator = entrySet.iterator(); while (it.hasNext()) { //获取每一个Entry对象 Map.Entry<Integer, String> entry = iterator.next(); //父类引用指向子类对象 Integer key = entry.getKey(); //根据键值对对象获取键 String values = entry.getValue(); //根据键值对对象获取值 System.out.println( key + "" + values ); } //增强for循环遍历(第四种) for (Map.Entry<Integer, String> entry : map.entrySet()) { System.out.println( entry.getKey() + " " + entry.getValue() ); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
8. Map集合的常见面试题
-
8.1 HashMap 和 Hashtable 的区别是什么?
<1> HashMap 由JDK 1.2 版本出现,基于Dictionary 类,基本取代了JDK 1.0 版本出现的基于AbstractMap 类的Hashtable 。
<2> Hashtable 的方法是同步的,性能较低;HashMap未经同步,性能高,所以在多线程下要手动同步HashMap,类似于Vector 和 ArrayList 一样。
<3> HashMap 是线程不安全的,Hashtable 是线程安全的,底层源码在对应的方法上添加了synchronized 关键字进行修饰,由于在执行方法的时候需要获得对象锁,则执行起来比较慢,为保证线程安全就选用ConcurrentHashMap。
<4> HashMap 允许key 和 value 存放null 值,Hashtable key 和 value 均不可存放null 值,否则出现NullPointerException。
<5> 哈希值的使用不同。 Hashtable 直接使用对象的hashcode;而HashMap 重新计算hash值,而且用于代替求模。
<7> HashMap 中的hash数组的默认大小是 16,而且一定是2 的指数;Hashtable 中的hash 数组默认大小是 11,增加的方式是 old * 2 + 1。 -
8.2 HashMap 中的key 可以是任何对象或数据类型吗?
<1> 可以为null ,但不能是可变对象,如果是可变对象的话,对象中的属性改变,则对象hashcode 也进行相应的改变,导致下次无法查找到已存在Map 中的数据。
<2> 如果可变对象被用作键,那就要小心在改变对象状态的时候,不要改变它的哈希值了。我们只需保证成员变量的改变能保证该对象的哈希值不变即可。 -
8.3 请解释 HashMap 和 ConcurrentHashMap 的区别?
<1> HashMap 是非线程安全的, ConcurrentHashMap是线程安全的。
<2> ConcurrentHashMap 将整个Hash 桶进行了分段 segment,也就是将这个大的数组分成了几个小的片段segment,而且每个小的片段上都有锁的存在,所以在插入元素的时候需要先找到应该插入到哪一个片段,然后再向这个片段进行插入,同时还要获取到segment锁才能进行插入。 -
8.4 ConcurrentHashMap 是线程安全的吗?如何保证线程安全?
<1> Hashtable 集合在竞争激烈的并发环境下表现出效率低下的原因是所有访问Hashtable 的线程都必须竞争同一把锁。假如容器中里有多把锁,每把锁用于锁集合中的一部分数据,当多线程访问集合中不同数据段的数据时,就不会出现锁竞争,这样就可以提高并访问效率,这就是ConcurrentHashMap 所采用的锁分段技术。首先将数据分成一段一段的存储,然后在每段数据处都配一把锁,当一个线程占用锁并访问其中一段数据时,其他段的数据不受影响,可以被其他线程正常访问到。
<2> put 方法首先定位到Segment,然后在Segment 里进行插入。插入操作时先要判断是否需要对Segment 里的HashEntry 数组进行扩容,其次定位添加元素的位置,然后放在HashEntry 数组里。
<3> 如果需要在ConcurrentHashMap中添加一个新的表项,并不是将整个HashMap加锁,而是首先根据hashcode得到该表项应该存放在哪个段中,然后对该段加锁,并完成put操作。在多线程环境中,如果多个线程同时进行put操作,只要被加入的表项不存放在同一个段中,则线程间可以做到真正的并行。
以上就是集合类的知识点的汇总情况,后续将一直跟进,进行查漏补缺,同时,文章如有不足之处,欢迎各位大佬对此提出可行性意见和建议,共同成长进步。


