
- 1一文快速了解浏览器Sui Explorer_sui区块浏览器
- 2Elasticsearch Linux学习结合SpringBoot实操_连接linux中的elasticsearch ,编写spring boot项目
- 32024最新华为OD机试试题库全 -【机器人仓库搬砖】- C卷_华为od2024题库
- 4GEE:关于遥感生态指数(RSEI)的若干疑问_遥感生态指数主成分分析全是正的
- 5西门子S7系列中间人攻击:流量劫持和转发(一)_plc 中间人攻击
- 6华为云认证有什么?考试难不难?
- 7Verilog 代码规范_verilog代码编写规范
- 8如何将mysql的数据导出excel_教你如何将SQL数据导出到EXCEL中
- 9【大语言模型】基础:TF-IDF
- 10Xilinx MicroBlaze软核的使用-Uartlite
缓存的深入浅出_深入浅出缓存那些事儿
赞
踩
前言
缓存的本质:为了节约对原始资源重复获取的开销,而将结果数据副本存放起来以供获取的方式——以空间换时间。
缓存命中率:我们把一批数据获取中,通过缓存获得数据的次数,除以总的次数,得到的结果就是缓存命中率。
缓存所要追求的目的:更低的延迟(latency) 和 更高的吞吐量(throughput)。
一、缓存的应用模式
- Cache-Aside
- Read-Through
- Write-Through
- Write-Back
1、Cache-Aside(最为常用)
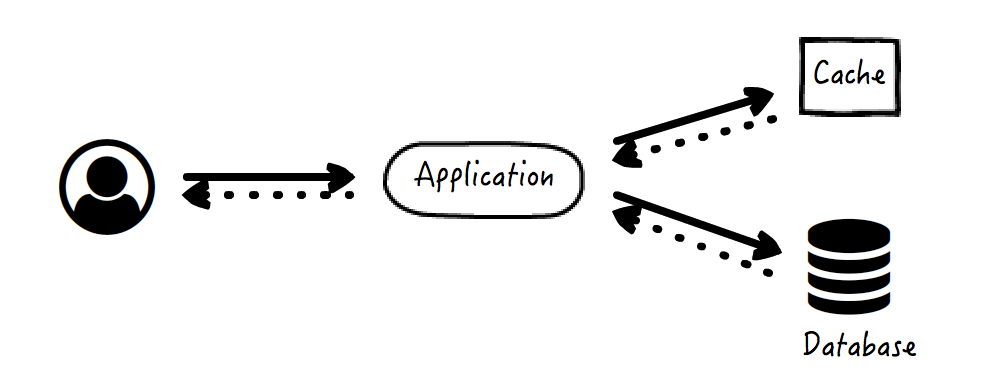
数据获取策略:
- 应用先去查看缓存是否有所需数据;
- 如果有,应用直接将缓存数据返回给请求方;
- 如果没有,应用执行原始逻辑,例如查询数据库得到结果数据;
- 应用将结果数据写入缓存。
数据读取的异常情形:
- 如果数据库读取异常,直接返回失败,没有数据不一致的情况发生;
- 如果数据库读取成功,但是缓存写入失败,那么下一次同一数据的访问还将继续尝试写入,因此这时也没有不一致的情况发生。
数据更新策略:应用先更新数据库,再令缓存失效。
如果先令缓存失效,再更新数据库,会导致数据不一致的严重问题:
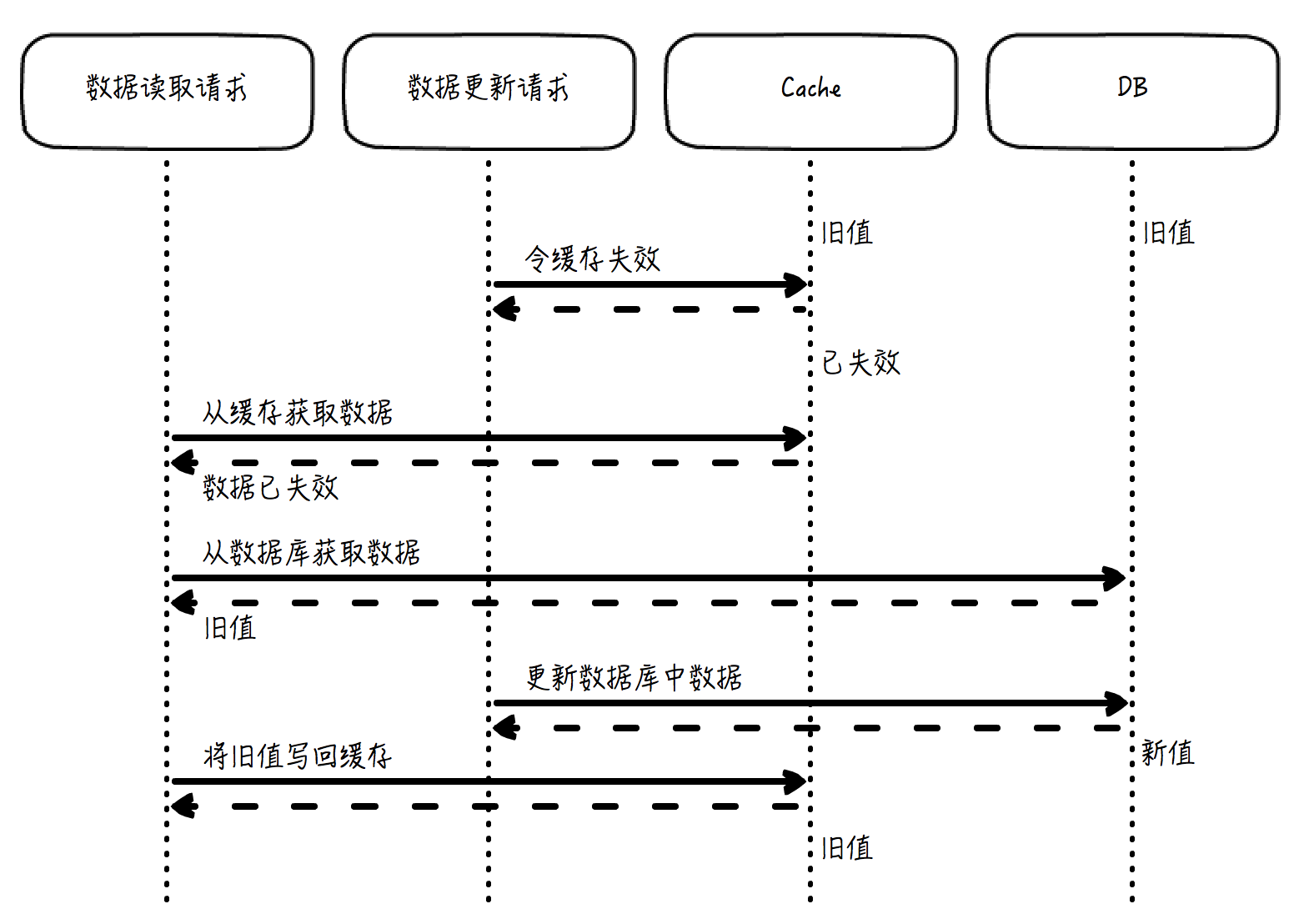
另外,数据库更新以后,需要令缓存失效,而不是更新缓存为数据库的最新值。为什么呢?
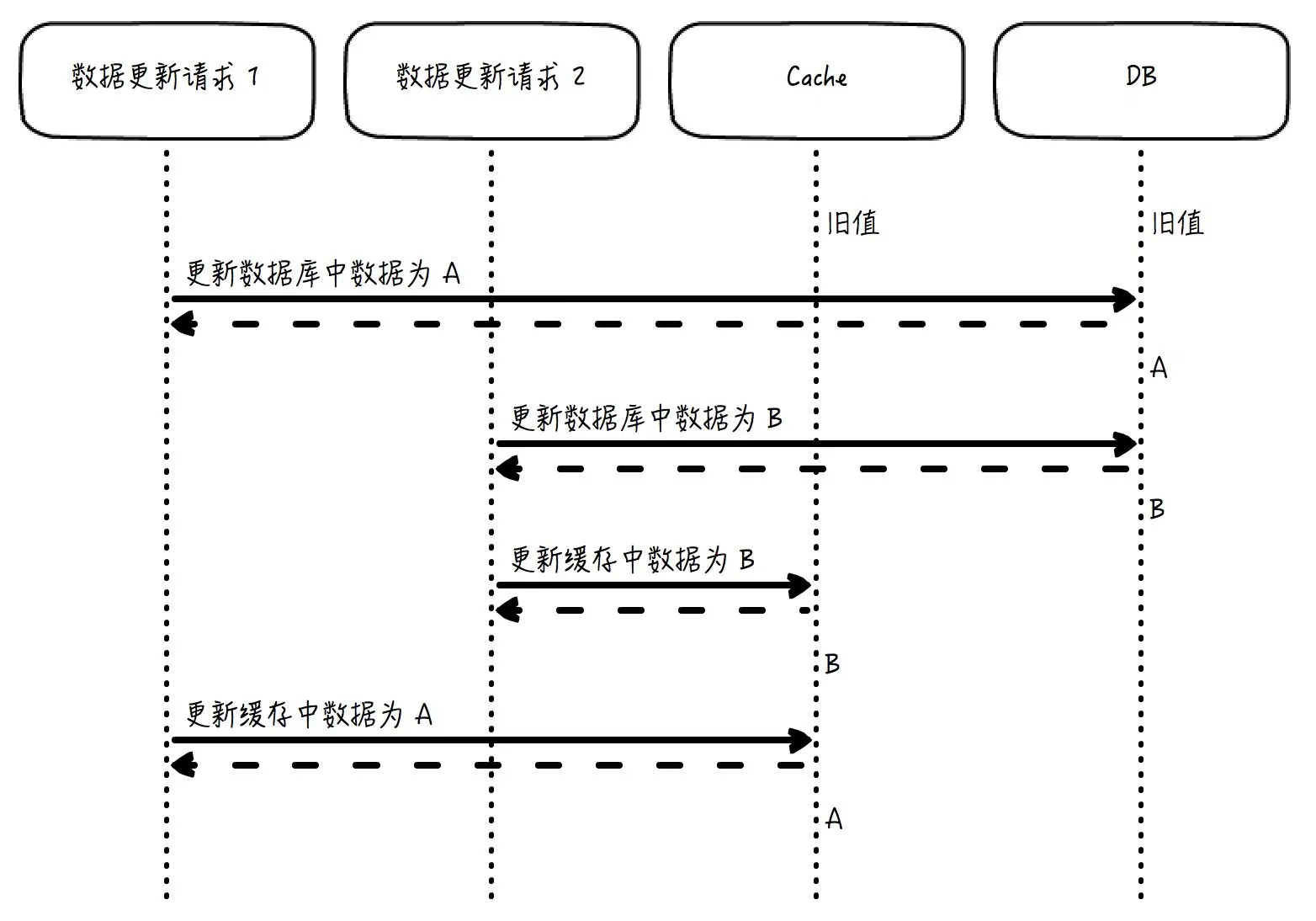
设想下:如果两个几乎同时发出的请求分别要更新数据库中的值为 A 和 B,如果结果是 B 的更新晚于 A,那么数据库中的最终值是 B。但是,如果在数据库更新后去更新缓存,而不是令缓存失效,那么缓存中的数据就有可能是 A,而不是 B。因为数据库虽然是“更新为 A”在“更新为 B”之前发生,但如果不做特殊的跨存储系统的事务控制,缓存的更新顺序就未必会遵从“A 先于 B”这个规则,这就会导致这个缓存中的数据会是一个长期错误的值 A。
如果是令缓存失效,这个问题就消失了。因为 B 是后写入数据库的,那么在 B 写入数据库以后,无论是写入 B 的请求让缓存失效,还是并发的竞争情形下写入 A 的请求让缓存失效,缓存反正都是失效了。那么下一次的访问就会从数据库中取得最新的值,并写入缓存,这个值就一定是 B。
数据更新的异常情形:
- 如果数据库操作失败,那么直接返回失败,没有数据不一致的情况发生;
- 如果数据库操作成功,但是缓存失效操作失败,这个问题很难发生,但一旦发生就会非常麻烦,缓存中的数据是过期数据,需要特殊处理来纠正。
2、Read-Through

这种情况下缓存系统彻底变成了它身后数据库的代理,二者成为了一个整体,应用的请求访问只能看到缓存的返回数据,而数据库系统对它是透明的。
数据获取策略:
- 应用向缓存要求数据;
- 如果缓存中有数据,返回给应用,应用再将数据返回;
- 如果没有,缓存查询数据库,并将结果写入自己;
- 缓存将数据返回给应用。
数据读取异常的情况分析和 Cache-Aside 类似,没有数据不一致的情况发生。
3、Write-Through
Write-Through 和 Read-Through 类似,图示同上,但 Write-Through 是用来处理数据更新的场景。
数据更新策略:
- 应用要求缓存更新数据;
- 如果缓存中有对应数据,先更新该数据;
- 缓存再更新数据库中的数据;
- 缓存告知应用更新完成。
这里的一个关键点是,缓存系统需要自己内部保证并发场景下,缓存更新的顺序要和数据库更新的顺序一致。比如说,两个请求分别要把数据更新为 A 和 B,那么如果 B 后写入数据库,缓存中最后的结果也必须是 B。这个一致性可以用乐观锁等方式来保证。
数据更新的异常情形:
- 如果缓存更新失败,直接返回失败,没有数据不一致的情况发生;
- 如果缓存更新成功,数据库更新失败,这种情况下需要回滚缓存中的更新,或者干脆从缓存中删除该数据。
还有一种和 Write-Through 非常类似的数据更新模式,叫做 Write-Around。它们的区别在于 Write-Through 需要更新缓存和数据库,而 Write-Around 只更新数据库(缓存的更新完全留给读操作)。
4、Write-Back
对于 Write-Back 模式来说,更新操作发生的时候,数据写入缓存之后就立即返回了,而数据库的更新异步完成。这种模式在一些分布式系统中很常见。
这种方式带来的最大好处是拥有最大的请求吞吐量,并且操作非常迅速,数据库的更新甚至可以批量进行,因而拥有杰出的更新效率以及稳定的速率,这个缓存就像是一个写入的缓冲,可以平滑访问尖峰。另外,对于存在数据库短时间无法访问的问题,它也能够很好地处理。
但是它的弊端也很明显,异步更新一定会存在着不可避免的一致性问题,并且也存在着数据丢失的风险(数据写入缓存但还未入库时,如果宕机了,那么这些数据就丢失了)。
二、清理缓存常见的策略(缓存的淘汰策略)
为什么需要清理缓存?这源于缓存污染带来的问题。
缓存污染指的是:在一些场景下,有些数据被访问的次数非常少,甚至只会被访问一次。当这些数据服务完访问请求后,如果还继续留存在缓存中的话,就只会白白占用缓存空间。
当缓存污染不严重时,只有少量数据占据缓存空间,此时,对缓存系统的影响不大。但是,缓存污染一旦变得严重后,就会有大量不再访问的数据滞留在缓存中。这样既占内存,又会降低应用的性能。而哪些数据能留存在缓存中,是由缓存的淘汰策略决定的。
8 种缓存的淘汰策略请作为了解:noeviction(不会进行数据淘汰的)、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
常见的 3 种缓存淘汰策略:
- 先进先出策略 FIFO(First In,First Out)
- 最少使用策略 LFU(Least Frequently Used)
- 最近最少使用策略 LRU(Least Recently Used)
其中使用最为广泛的是 “最近最少使用策略 LRU”。
1、最近最少使用策略 LRU
(1)、LRU 的致命缺陷
LRU 的原理是:维护一个限定最大容量的队列,队列头部总是放置最近访问的元素(包括新加入的元素),而在超过容量限制时总是从队尾淘汰元素。
这看起来是个很完美的缓存淘汰算法,在队列较长时,总是能保证最近访问的数据位于队列的头部,而在需要从缓存中淘汰数据时,总是能从尾部淘汰最不常用的那一个。但是,如果用户有意无意地访问一些错误信息,就会破坏掉这个 LRU 队列中最近访问数据的真实性。这时候大量的数据访问全部穿透缓存,导致数据库压力剧增,网站响应时间一下就飙升到了告警线之上。
既然这个问题已经很明确了,那么解决就不是难事了。有多种算法可以作为 LRU 的改进方案,比如 LRU-K。就是主缓存队列排的是“第 K 次访问的元素”,也就是说,如果访问次数小于 K,则在另外的一个“低级”队列中维护,这样就保证了只有到达一定的访问下限才会被送到主 LRU 队列中。
这种方法保证了偶然的页面访问不会影响网站在 LRU 队列中应有的数据分布。再进一步优化,可以将两级队列变成更多级,或者是将低级队列的策略变成 FIFO(2Q 算法)等等,但原理是不变的。
三、从缓存的视角出发
1、从缓存的视角看——当浏览器地址栏中输入 URL 按下回车后到底发生了什么?
- 它会先查询浏览器内部的“域名 -IP”缓存,如果你曾经使用该浏览器访问过这个域名,这里很可能留有曾经的映射缓存;
- 如果没有,会查询操作系统是否存在这个缓存,例如在 Mac 中,我们可以通过修改 /etc/hosts 文件来自定义这个域名到 IP 的映射缓存;
- 如果还没有,就会查询域名服务器(DNS,Domain Name System),得到对应的 IP 和可缓存时间。
2、从缓存的视角看——MVC 架构
- 对于 Controller 层来说,可以使用拦截过过滤器,在其中,我们就是可以配置缓存来过滤服务的,即满足某些要求的可缓存请求,我们可以直接通过过滤器返回缓存结果,而不执行后面的逻辑,我们在下一讲会学到具体怎样配置。
- 对于 Model 层来说,几乎所有的数据库 ORM 框架都提供了缓存能力,对于贫血模型的系统,在 DAO 上方的 Service 层基于其暴露的 API 应用缓存,也是一种非常常见的形式。
- 对于 View 层,很多页面模板都支持缓存标签,页面中的部分内容,不需要每次都执行渲染操作(这个开销很可能不止渲染本身,还包括需要调用模型层的接口而造成显著的系统开销),而可以直接从缓存中获取渲染后的数据并返回。
四、缓存相关的问题汇总
1、数据库与缓存数据一致性问题
在查询缓存数据时,我们会先读取缓存,如果缓存中没有该数据,则会去数据库中查询,之后再放入到缓存中。
当我们的数据被缓存之后,一旦数据被修改(修改时也是删除缓存中的数据)或删除,我们就需要同时操作缓存和数据库。这时,就会存在一个数据不一致的问题。
若先删除缓存,再删除数据库:在并发情况下,当 A 操作使得数据发生删除变更,那么该操作会先删除缓存中的数据,之后再去删除数据库中的数据,此时若是还没有删除成功,另外一个请求查询操作 B 进来了,发现缓存中已经没有了数据,则会去数据库中查询,此时发现有数据,B 操作获取之后又将数据存放在了缓存中,随后数据库的数据又被删除了。此时就出现了数据不一致的情况。
若先删除数据库,再删除缓存:在并发情况下,当 A 操作使得数据发生删除变更,那么该操作会先删除了数据库的操作,接下来删除缓存,失败了,那么缓存中的数据没有被删除,而数据库的数据已经被删除了,同样会存在数据不一致的问题。
那我们如何避免高并发下,数据更新删除操作所带来的数据不一致的问题呢?
通常的解决方案是:如果我们需要使用一个线程安全队列来缓存更新或删除的数据,当 A 操作变更数据时,会先删除一个缓存数据,此时通过线程安全的方式将缓存数据放入到队列中,并通过一个线程进行数据库的数据删除操作。当有另一个查询请求 B 进来时,如果发现缓存中没有该值,则会先去队列中查看该数据是否正在被更新或删除,如果队列中有该数据,则阻塞等待,直到 A 操作数据库成功之后,唤醒该阻塞线程,再去数据库中查询该数据。
但其实这种实现也存在很多缺陷,例如,可能存在读请求被长时间阻塞,高并发时低吞吐量等问题。所以我们在考虑缓存时,如果数据更新比较频繁且对数据有一定的一致性要求,我通常不建议使用缓存。
2、缓存穿透、缓存击穿、缓存雪崩
- 缓存穿透:指大量查询没有命中缓存,直接去到数据库中查询,如果查询量比较大,会导致数据库的查询流量大,对数据库造成压力。
- 缓存雪崩 和 缓存击穿:缓存雪崩与缓存击穿差不多,区别就是失效缓存的规模。
- 大量被高并发访问的缓存突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击,引起系统过载、宕机等问题,就叫做缓存雪崩。例如,缓存的过期时间同一时间过期了,缓存服务宕机了。
- 一个被高并发访问的缓存突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击,就叫做缓存击穿。
(1)、缓存穿透
我们可以在缓存中对这个 key 存放一个空结果,毕竟“没有结果”也是结果,也是需要缓存起来的。还有一种缓解方法是使用布隆过滤器等数据结构,在数据库查询之前,预先过滤掉某些不存在的结果。
还有一种特殊情况也会造成缓存穿透的严重后果。一般的缓存策略下,往往需要先发生一次缓存命中失败,接着从实际存储(比如数据库)中得到结果,再回填到内存缓存中。但是,如果这个数据库查询过程比较慢,大量同一数据的请求像雨点一样几乎同时到来,就会全部穿透缓存,一并落到了数据库上,而那个时候最早的那个请求引发的缓存回填甚至都还没有发生,在这种情况下数据库直接就挂掉了,虽然缓存的机制本身看起来并没有任何问题。这种问题在某些时间窗口敏感的高并发系统中可能出现,解决方法有这样两种:
- 一种是以流量控制的方式,限制对于同一数据的访问,必须等到前一个完成以后,下一个才能进行,即如果缓存失效而引发的数据库查询正在进行,其它请求就得老老实实地等着。这种方法通用性好,但这个等待机制可能较为复杂,且有可能影响用户体验。
- 另一种方法是缓存预热,在大批量请求到来以前,先主动将该缓存填充好。这种方法操作简单高效,但局限性是需要提前知道哪些数据可能引发缓存穿透的问题。
(2)、缓存雪崩
机房断电导致网站无法提供服务,短期内访问恢复,随后又丧失服务能力。此时会导致缓存雪崩。
对于这种类型的雪崩,最常见的解决方法无非还是限流、预热两种:前者保证了请求大量落到数据库的时候,系统只接纳能够承载的数量;而后者则在请求访问前,先主动地往内存中加载一定的热点数据,这样请求到来的时候,缓存不是空的,已经具有一定的保护能力了。
另外一个常见的缓存雪崩场景是:缓存数据通常都有过期时间的,如果缓存加载的时间比较集中,那么很可能到了某一时间点,大量的缓存就会同时过期,于是对应这些数据的请求全部落到了后面的数据库上,从而造成系统崩溃。这个问题解决起来也不难,那就是避免缓存集中写入的时间,如果无法避免,就使用一个范围随机数来均匀地分散过期时间,从而打散缓存过期对系统造成的压力。
3、缓存容量失控
假设有这样一个需求:用户的行为需要被记录到数据库里。
但是每条记录发生的时候都写一次数据库的话开销就太大了,于是有同事设计了一个链表:“用户的行为首先会被即时记录到内存链表里面去;每 10 分钟从链表往数据库里面集中写一次数据,然后清空链表内的数据。”看起来这就像是 Write-Back 模式,也确实可以实现需求。可是,上线没多久系统就挂掉了。存在的问题如下:
- 清空链表数据是使用时间条件触发的任务来完成,通过时间因素来限制空间大小,远不如通过队列长度来限制空间大小来得可靠。换句话说,如果这 10 分钟内事件暴增,链表就很容易变得非常大。这个变化范围取决于请求的上限,而不是在缓存系统自己的掌控中。
- 清空链表的任务,如果在执行的过程中出现了异常,甚至仅仅是处理速度受到阻塞,那就会直接导致链表数据无法得到清空,甚至越积越多。实际上,链表清空数据并写入数据库是一个耗时的异步行为,这是另一个受控性较差的点。我们在使用异步系统批量写入数据的时候,一定要考虑这个潜在的危险。
因此,我们对于缓存容量的控制,最好是基于缓存容量本身来直接控制,但是考虑到某些编程语言的自身限制,比如 Java,从内存消耗的角度来实现不方便,那么就可以通过基于队列的长度来替代实现。
【说明】
本文是我看了熊燚老师的课程后,结合网上一些观点整理的笔记。欢迎大家一起来学习交流。

