
- 1Elasticsearch:(二)3.安装Elasticsearch-head插件
- 2FPGA原理与结构——时钟IP核的使用与测试_fpga怎么调用时钟ip
- 3测试用例常见设计方法_如何设计测试用例
- 4推荐几个比较好的软件测试博客论坛_软件测试论坛
- 5python元胞自动机模拟交通_教程FLUS模型|未来土地利用变化情景模拟模型(GeoSOSFLUS)...
- 6WINDOWS环境下RABBITMQ的启动和停止命令_怎么在windos powershell里关闭rabbitmq
- 7APP开发实战178-查看和删除多余的依赖库_如何删除uniapp不需要的依赖
- 82023亚太杯数学建模竞赛C题新能源电动汽车数据分析与代码讲解_2023年亚太赛c题
- 9SiteServer 学习笔记 Day05 添加模板
- 10AI智能电销机器人是什么?能给我们带来哪些便利?
数据库面试题 Java 程序员 SQL 深入解析(一)_java数据库选择题解析
赞
踩
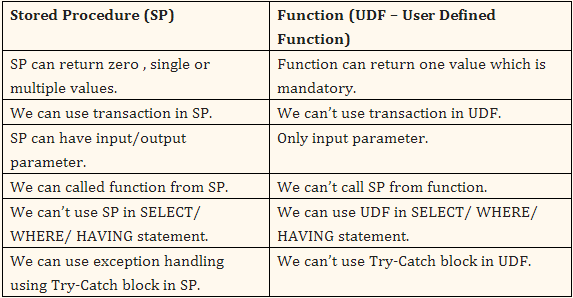
存储过程和函数的区别(stored procedure vs function)
- You can’t mix in stored procedures with ordinary SQL, whilst with stored function you can.e.g. SELECT get_foo(myColumn) FROM mytable is not valid if get_foo() is a procedure, but you can do that if get_foo() is a function. The price is that functions have more limitations than a procedure.
就是说存储过程不能和 SQL 语句混合使用,而函数可以。
函数有如:只能返回一个变量的限制。而存储过程可以返回多个。
存储过程可以有输入参数、返回值、输出参数,还能返回多个多个记录集。但它得到的结果不能在 sql 语句使用。
函数是可以嵌入在sql中使用的,可以在select等中调用,而存储过程不行,存储过程是通过 call 调用。
组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它
当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
存数过程例子
下面的@Barcode和@Caption是输入参数:
CREATE PROCEDURE usp_AddProduct
(
@Barcode varchar(13),
@Caption nvarchar(50)
)
AS
BEGIN
IF LEN(@Barcode) < 13
RAISERROR('Barcode length is too short.')
INSERT INTO MyProducts (Barcode, Caption) VALUES (@Barcode, @Caption)
END- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如何调用存储过程,使用 EXEC 或者 CALL
EXEC usp_AddProduct '2293891100011', 'MyProductCaption'- 1
创建下面的存储过程
这儿的 output 是输出参数,return 1是返回值
create procedure sp_output
@output_var int output
as
set @output_var = 121
return 1- 1
- 2
- 3
- 4
- 5
- 6
执行存储过程 首先需要声明 declare @out int
<1>执行下列,返回121
declare @out int
exec sp_output @out output
select @out
<2>执行下列,返回1
declare @out int
declare @count int
exec @count = sp_output @out output
select @count
函数例子
CREATE FUNCTION hello (s CHAR(20))
RETURNS CHAR(50) DETERMINISTIC
RETURN CONCAT('Hello, ',s,'!');
Query OK, 0 rows affected (0.00 sec)
CREATE TABLE names (id int, name varchar(20));
INSERT INTO names VALUES (1, 'Bob');
INSERT INTO names VALUES (2, 'John');
INSERT INTO names VALUES (3, 'Paul');
SELECT hello(name) FROM names;
+--------------+
| hello(name) |
+--------------+
| Hello, Bob! |
| Hello, John! |
| Hello, Paul! |
+--------------+
3 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这个是实现了将 name 转化为 Hello,name !
范式
第1范式
一范式就是属性不可分割。
就是说学生身材信息包含(身高 体重)。这不符合第1范式,因为是可以拆分的,分为身高 体重
第2范式
二范式就是要有主键,要求其他字段都完全依赖依赖于主键。消除了部分依赖。
部分依赖多出现在主见个数大于1的情况,比如学生id,学生姓名,课程 id,课程分数。(不符合)
这儿的主键是(学生 id,课程 id)
(学生 id,课程 id) -> 课程分数,课程分数需要学生 id 和课程 id 共同决定,这儿是完全依赖的关系
但是(学生 id,课程 id) -> 学生姓名,这儿只需要学生 id 就能确定学生姓名,是部分依赖。所以不符合第2范式
第3范式
在2范式的基础上,不存在传递依赖的情况。
比如 学生 id,学生,指导老师,老师地址。
学生 id ->指导老师,指导老师->老师地址,虽然老师地址是完全依赖于学生 id 的,但是这里面是传递依赖,不符合第3范式。
BC 范式
有这样一个配件管理表(仓库 id,配件 id,职工 id,配件数量)
有以下约束要求:
(1) 一个仓库有多名职工;
(2) 一个职工仅在一个仓库工作;
(3) 每个仓库里一种型号的配件由专人负责,但一个人可以管理几种配件;
(4) 同一种型号的配件可以分放在几个仓库中。
分析表中的函数依赖关系,可以得到:
(1) 职工 id->仓库 id;
(2) (仓库 id,配件 id)->配件数量
(3) (仓库 id,配件 id)->职工号
(4) (职工 id,配件 id)->配件数量
可以看到,候选键有:(职工id,配件 id);(仓库 id,配件 id)。
所以,职工id,配件 id,仓库 id均为主属性,配件数量为非主属性。
显然,非主属性是直接依赖于候选键的。所以此表满足第三范式。
WNO表示仓库号,PNO表示配件号,ENO表示职工号,QNT表示数量
而我们观察一下主属性:(仓库 id,配件 id)->职工 id; 职工 id->仓库 id。
显然仓库 id 对于候选键(仓库 id,配件 id)存在传递依赖,所以不符合BCNF.
第4范式
一般用不到3范式,不纠结
数据库事务
注意就是原子性 一致性 隔离性 持久性
原子性(Atomic)(Atomicity)
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
一致性(Consistent)(Consistency)
事务在完成时,必须使所有的数据都保持一致状态。就是比如取了200块钱,那么对应的账户就要少200块钱
隔离性(Insulation)(Isolation)
由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。这称为隔离性,因为它能够重新装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。
持久性(Duration)(Durability)
事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
数据库基础概念
关键字
关键字的更严密定义是:在关系R中如记录完全函数依赖于属性(组)X,则称X为关系R中的一个候选关键字。
在表l.2中,“系代码”是关系“系”的候选关键字,表l.4中“职工号”是关系“教师”的候选关键字。在表1.7“成绩”关系中,“学号+课程号”是候选关键字。
候选关键字有如下性质:
.在一个关系中, 候选关键字可以有多个。例如表1.6的系关系中,系号、系名都是候选关键字。
如果某个字段或多个字段的值可以唯一地标识一条记录,则该字段就称为关键字。
如果一个关键字是用以区别每条记录的唯一性标志,并作为该表与其他表实现关联的,则称为主关键字或主码。
除主关键字以外的其他关键字称候选关键字。
如有一个表,字段为:
id firstname lastname address phone IDcard
那么id或IDcard或firstname+lastname都可以说是关键字。
其中id为主关键字,IDcard和firstname+lastname为候选关键字
主属性
在一个关系中,如一个属性是构成某一个候选关键字的属性集中的一个属性,则称它为主属性。如一个属性不是构成该关系任何一个候选关键字的属性集的成员,就称它为非主属性。例如表1.7中,“学号+课程号”是关键字,那么“学号”是主属性,“课程号”是主属性,分数是非主属性。
参考文章
MySQL stored procedure vs function, which would I use when?
存储过程详解–存储过程简介
Oracle基础学习三:过程PROCEDURE 和函数FUNCTION 的创建及调用解释一下关系数据库的第一第二第三范式?

