
- 1如何将原始SNP信息转化为0,1,2的矩阵形式_snp 0 1 2
- 2对于云原生时代的后端业务开发和项目系统学习,选Go Or Java?_go最佳就是云原生开发吗
- 3Guitar Pro 8.1 Mac/WIN中文破解版 2024最新下载、安装、激活、换机图文教程
- 4Linux之bash介绍
- 55个大厂出品的移动端组件库推荐!
- 6OpenAI(chatgpt)提示Account deactivated怎么办?_your openai account has been deactivated, please c
- 7RK3568 学习笔记 : 更改 u-boot spl 中的 emmc 的启动次序
- 8GitHub双重认证问题_github two-factor recovery
- 9如何开发类似QFIL下载工具_qsaharaserver.exe
- 10NLTK库安装教程(详细版)_nltk安装
ICCV 2023 Oral | HumanSD:更可控更高效的人体图像生成模型
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:juju(源:知乎,已授权)| 编辑:CVer公众号
https://zhuanlan.zhihu.com/p/647136726

在CVer公众号后台回复:HumanSD,可下载本论文、代码和数据
HumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation
论文:https://arxiv.org/abs/2304.04269
代码:https://github.com/IDEA-Research/HumanSD
项目主页:
https://idea-research.github.io/HumanSD/
几句话总结一下这篇文章?
本文提出了一个可控人物图像生成方法 HumanSD,旨在高效、准确、原生地控制以人为中心的图片的生成。具体来说,HumanSD 使用一种新颖的热图引导去噪损失(heatmap-guided denoisinh loss)来微调预训练的 Stable Diffusion 模型,这种策略有效加强了骨骼条件的控制力,同时减轻了灾难性遗忘效应。
相比 ControlNet、T2I-Adapter 等即插即用的双分支控制方法,HumanSD 展现了更优的可控力和更快的生成速度,其中可控精度提升 73%。同时,我们提供了适用于人体生成的大规模公开数据集用于后续研究。
是基于什么样的思考完成了这篇文章?
随着基于 Diffusion 模型的文生图的大火,除文字外的其他控制条件下的可控图像生成模型也迎来了一次小爆发,HumanSD [1]、ControlNet [2]、T2I-Adaptor [3]、Composer [4]、GLIGEN [5] 等 [6,7] 模型探索了将更精细化的控制条件加入文生图模型的不同方式。
事实上,由于 Diffusion 模型的隐空间中含有非常丰富的生成图像信息,将控制信息加入模型并不是一件难事,而由于文生图模型本身相对难以评测且目前仍没有成熟的评价标准,我们也很难对于究竟哪一模型在哪些情况下有着更优的表现这一问题得到确定性结论。
而本篇文章聚焦于一个小的可控文生图方向,也就是使用人体骨架信息控制人体图像生成,通过可量化的指标对“如何加入控制条件可以带来更好的控制性”、“如何加强可控生成的质量”、“ControlNet 等即插即用的控制方式是否最优”等问题一一回答,希望通过一些实验结论和理论分析了解和揭示大模型运作原理的冰山一角,同时也期待本篇工作可以带来更多相关领域的思考。

▲ 图1 生成效果展示
这篇工作做了什么?
HumanSD 的实现并不复杂,这里我们分为两个部分来讲解:1)控制条件的加入;2)使用特殊损失函数防止 fine-tune 过程中的灾难性遗忘并提升人体生成质量。
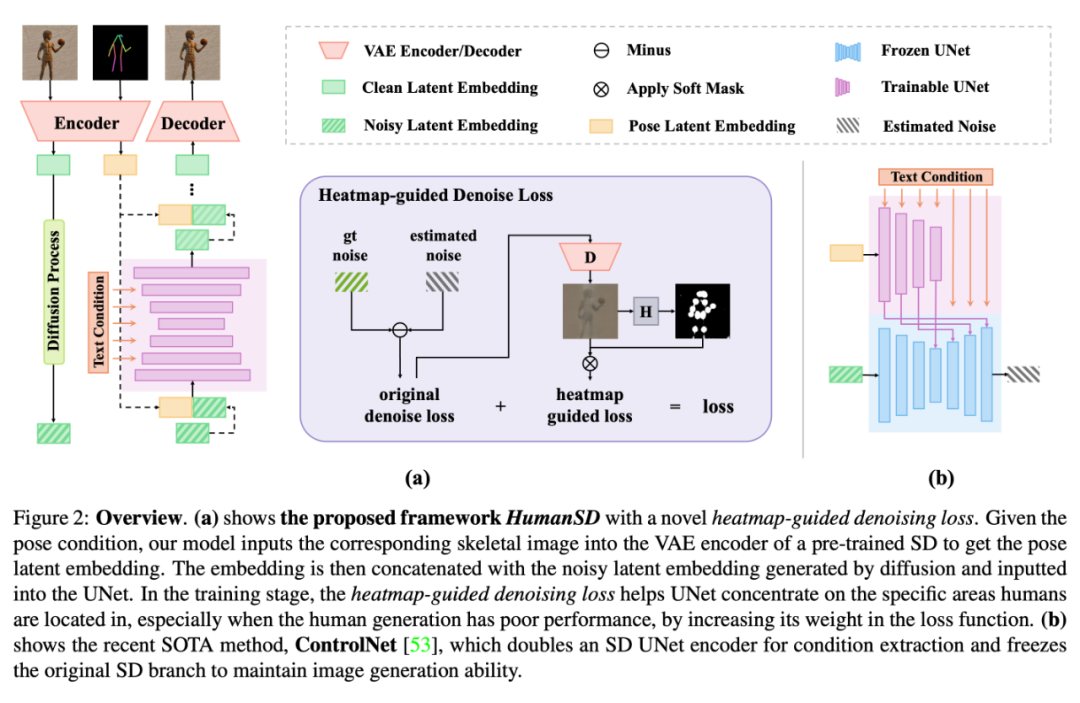
▲ 图2 HumanSD 模型示意图
(1)控制条件的加入:将控制条件在通道维度与 UNet 输入进行 concatenate 操作
【实现方法】如图 2 中(a)的左半部分所示,包含人体骨架信息的图片首先经过 Stable Diffusion 中用于提取 latent 信息的 VAE encoder,提取出 pose latent embedding,随后直接与图片的 noisy latent embedding 进行拼接,作为 UNet 的输入。由于这一操作只改变 UNet 的首层权重,因此初始化时仅将 UNet 第一层权重新加入部分置 0,其余全部直接使用预训练好的 Stable Diffusion 权重。
【直接通过 concatenate 加入控制条件】这一控制条件的加入方式在多篇文章中被证明有效,同时,Composer [4] 认为精细化的局部控制信息(如人体骨骼、线图、深度图)更适合通过 concatenate 的方式加入 UNet 的输入,而全局高密度信息(如文本、图片颜色板)更适合使用 attention 加入 UNet,本文人体骨骼的控制条件属于前者,因此更适合直接通过 concatenate 加。
【放开主模型进行 finetune】在数据量充足的情况下,开放主模型 finetune 相比冻结原始模型参数使用一个额外的 adapter 进行学习可以获得更好的控制效果,这可以同时在理论上和实验中找到依据。
我们以 ControlNet 为例,ControlNet 使用一个可训练的额外分支对冻结的原始分支进行控制,在这一过程中需要克服冻结的原始分支中可能存在的冲突(如图 3),因此导致在控制条件复杂或与原始分支输出差距过大的情况下,模型很容易无法做到精准控制,而放开主模型进行 finetune 则可以有效避免这一问题,更详细的公式推导可以参见原论文。

▲ 图3 分支控制带来的潜在冲突
(2)特殊损失函数 heatmap-guided denoising loss:对人体部分进行着重加权,提高反向传播过程中对人的关注度,同时防止灾难性遗忘
【实现方法】这一损失函数的出发点是将“需要控制的部分”中“生成仍不够好”的部分提高学习权重,因此这就带来了三个问题:1)如何找到生成仍不够好的部分;2)如何在隐空间中找到需要控制的部分;3)如何加强学习权重。
这一损失函数的具体实现可以参见图 2(a)紫色框内。首先针对(1),我们计算了每步 gt noise 和 UNet 输出的 estimated noise 的差,即 original denoise loss,并将其输入到 VAE decoder 得到生成图与原图间的差距。
随后针对(2),我们使用可输出人体关键点的检测器得到人体关键点的 heatmap,并将其作为 mask 区域,通过这一操作,我们就能够获得“生成的不够好的人体部分”,图 4 展示了对应的可视化结果。
针对(3),我们使用得到的 mask 区域对 loss 进行掩膜,得到加权后的 loss,作为反向传播输入的一部分。这一做法在 BREAK-A-SCENE[8]中也被使用(如图 5),并被其称为 masked diffusion loss。
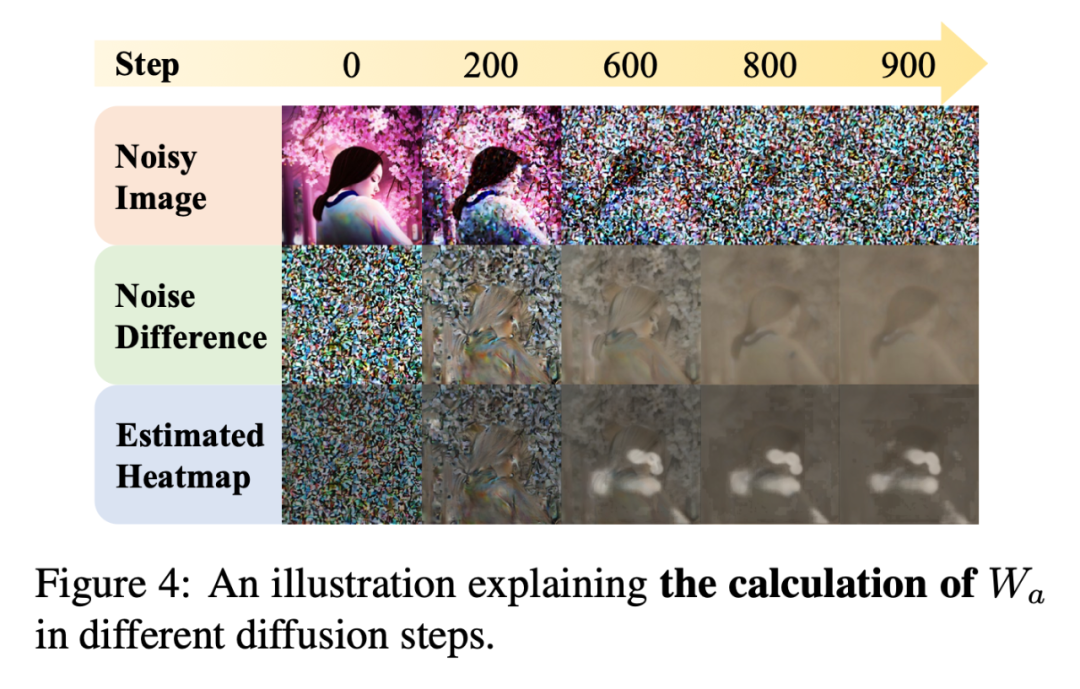
▲ 图4 mask区域可视化
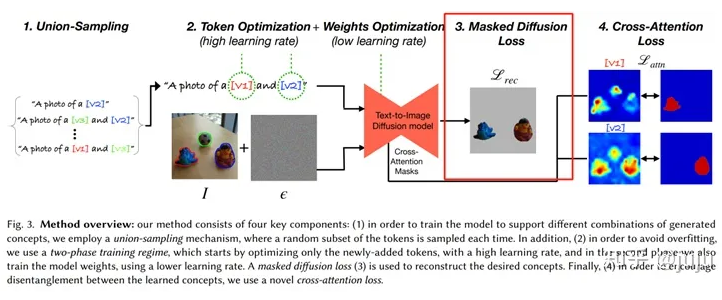
▲ 图5 break-a-scene中的masked diffusion loss
HumanSD是在什么数据上训练的呢?
Human-Art[9](介绍详见)是一个多场景的、具有高标注质量的、以人为中心的文本-图片-人体骨骼数据集,该数据集适用于多场景的人体图像生成,但其数据量仅有 5000 张,并不适合大规模的图片生成模型 finetune,因此本文构建了两个适合该任务的大规模数据集:GHI 以及 LAION-Human。
【GHI】GHI 直接从 Stable Diffusion 中采样,可以在不引入新数据分布的前体现保持原模型的生成能力。GHI 总共包含了 100 万个文本-图片-人体骨骼对,包括 14 个场景(来自 Human-Art [9])和 6826 个人类动作(来自 BABEL [10]、NTU RGB+D 120 [11]、HuMMan [12]、HAA500 [13] 和 HAKE-HICO [14])。
每个图像中有一到三个人物(比例为 7:2:1),我们利用 prompt engineering 设计了一系列 prompt,其中包括 18 个子 prompt 部分,包括图像场景风格、人物数量、人物特征、动作和背景描述(如:a realistic pixel art of two beautiful young girls running in the street of pairs at midnight, in winter, 64K, a masterpiece.)。
【LAION-Human】LAION-Human 通过对 LAION-5B 中的人体进行姿态检测得到,由于我们使用了在 Human-Art 上训练的检测器,LAION-Human 对非真实人体图像(如油画、雕塑)等有着更好的标注结果。
【Human-Art】为了提升模型在多场景的生成能力,我们同时也将Human-Art数据集加入训练。
实验结果如何测评,又说明了什么?
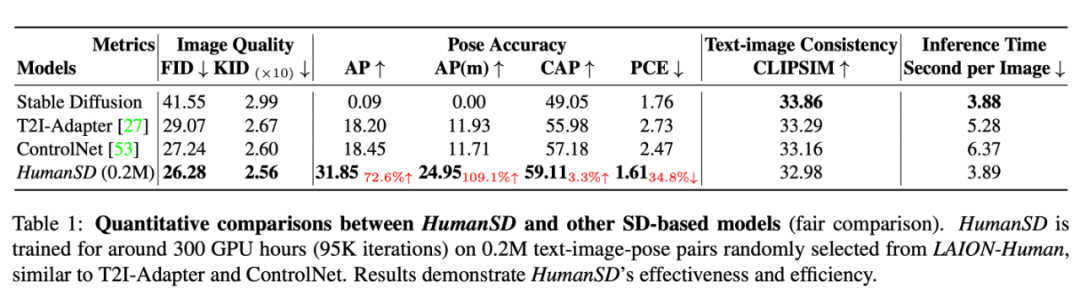
本文从图片生成质量(KID、FID),人体姿态控制准确度(AP、AP(m)、CAP、PCE),文本-图像匹配度(CLIPSIM)和运行时间(Second per Image)四个维度对结果进行了评测。
可以看到,HumanSD 在控制准确度上显著优于使用多分支控制的方法,并保证了较好的图片质量,同时由于不引入新的分支,HumanSD 的显存开销和运行时间也显著优于 ControlNet、T2I-Adapter。但同时可以看到,姿态条件的控制性会对文本条件的控制造成一定的负面影响,这可能是由于控制条件间的冲突所导致的。
更多的实验结果分析和消融实验可以参见原文。
在CVer公众号后台回复:HumanSD,可下载本论文、代码和数据
[1] Ju X, Zeng A, Zhao C, et al. HumanSD: A Native Skeleton-Guided Diffusion Model for Human Image Generation[J]. arXiv preprint arXiv:2304.04269, 2023.
[2] Zhang L, Agrawala M. Adding conditional control to text-to-image diffusion models[J]. arXiv preprint arXiv:2302.05543, 2023.
[3] Mou C, Wang X, Xie L, et al. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models[J]. arXiv preprint arXiv:2302.08453, 2023.
[4] Huang L, Chen D, Liu Y, et al. Composer: Creative and controllable image synthesis with composable conditions[J]. arXiv preprint arXiv:2302.09778, 2023.
[5] Li Y, Liu H, Wu Q, et al. Gligen: Open-set grounded text-to-image generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 22511-22521.
[6] Meng C, He Y, Song Y, et al. Sdedit: Guided image synthesis and editing with stochastic differential equations[J]. arXiv preprint arXiv:2108.01073, 2021.
[7] Voynov A, Aberman K, Cohen-Or D. Sketch-guided text-to-image diffusion models[J]. arXiv preprint arXiv:2211.13752, 2022.
[8] Avrahami O, Aberman K, Fried O, et al. Break-A-Scene: Extracting Multiple Concepts from a Single Image[J]. arXiv preprint arXiv:2305.16311, 2023.
[9] Ju X, Zeng A, Wang J, et al. Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 618-629.
[10] Abhinanda R. Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J. Black. BABEL: Bodies, action and behavior with English labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 722– 731, June 2021.
[11] Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C Kot. NTU RGB+D 120: A largescale benchmark for 3D human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 42(10):2684–2701, 2019.
[12] Zhongang Cai, Daxuan Ren, Ailing Zeng, Zhengyu Lin, Tao Yu, Wenjia Wang, Xiangyu Fan, Yang Gao, Yifan Yu, Liang Pan, Fangzhou Hong, Mingyuan Zhang, Chen Change Loy, Lei Yang, and Ziwei Liu. HuMMan: Multi-modal 4D human dataset for versatile sensing and modeling. In European Conference on Computer Vision (ECCV), pages 557– 577. Springer, 2022.
[13] Jihoon Chung, Cheng-hsin Wuu, Hsuan-ru Yang, Yu-Wing Tai, and Chi-Keung Tang. HAA500: Human-centric atomic action dataset with curated videos. In IEEE/CVF International Conference on Computer Vision (ICCV), pages 13465–13474, 2021.
[14] Yong-Lu Li, Liang Xu, Xinpeng Liu, Xijie Huang, Yue Xu, Mingyang Chen, Ze Ma, Shiyi Wang, Hao-Shu Fang, and Cewu Lu. HAKE: Human activity knowledge engine. arXiv preprint arXiv:1904.06539, 2019.
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集- 扩散模型和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-扩散模型或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如扩散模型或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信号: CVer333,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
-
- ▲扫码进星球
- ▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()


