
- 1Spring5源码分析六
- 2CashFiesta 攻略_cashfiesta攻略
- 3如何从零开始搭建一套四旋翼无人机?
- 42021年全国职业院校技能大赛-网络搭建与应用赛项-公开赛卷(五)技能要求_所有用户使用漫游用户配置文件,配置文件存储在windows-1的 c:\profiles文件夹
- 5Git 多个账户,多个SSH配置_多个gitlab账号可以共用同一个ssh keys吗
- 6fastadmin二次开发使用教程php,fastAdmin插件开发教程之简明开发入门教程
- 7使用yolov8对视频进行实时检测_yolov8 检测视频
- 8用Django构建网上商城:django网上商城从零到有开发讲解_django商城
- 9Java网络爬虫——jsoup快速上手,爬取京东数据。同时解决‘京东安全’防爬问题_京东爬虫
- 10升级uniapp后小程序编译提示[ project.config.json 文件内容错误] project.config.json: libVersion 字段需为string
Django的web框架Django Rest_Framework精讲(四)_django rest framework
赞
踩
大家好,我是景天,今天我们继续DRF的最后一讲,Django的web框架Django Rest_Framework(四)
1.DRF认证组件Authentication
DRF除了提供序列化器,视图组件,路由组件外,还提供了很多其他组件,比如认证组件
创建个auth应用

DRF默认用的和admin是一套认证系统
查看原码

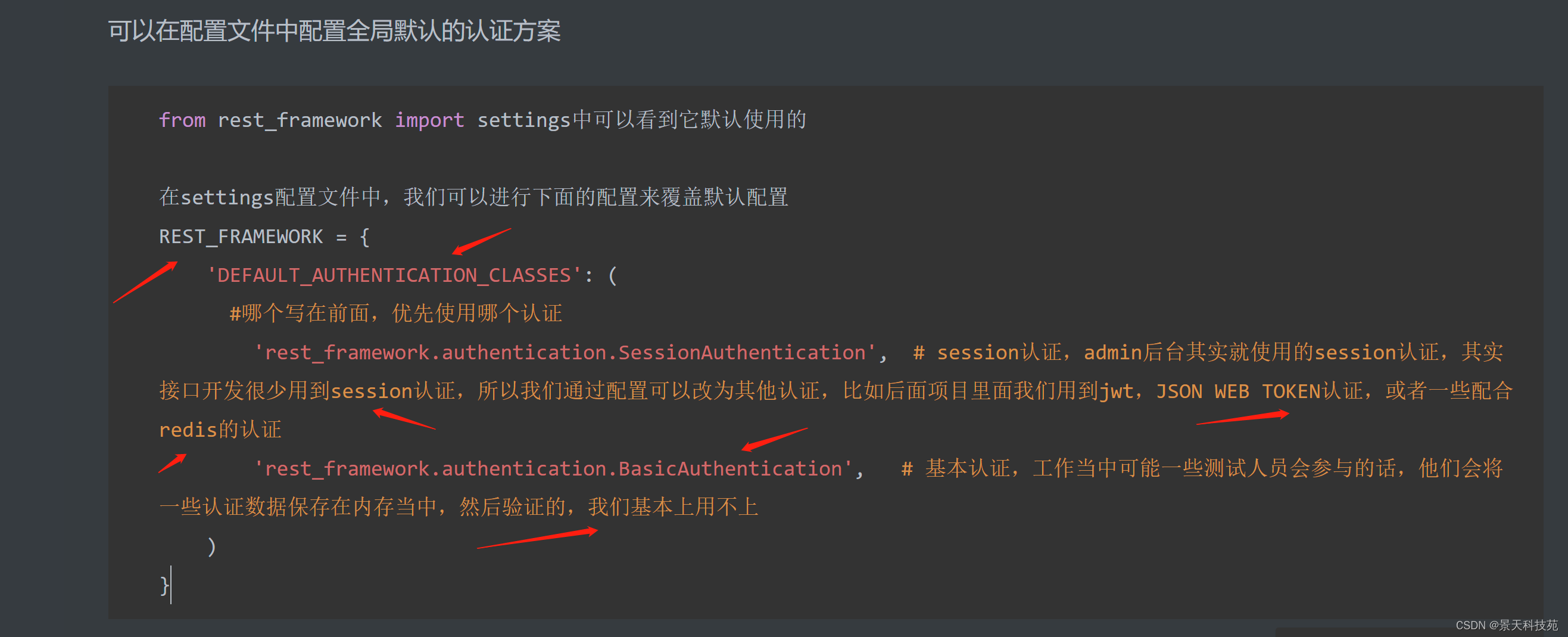
可以在配置文件中配置全局默认的认证方案
谁写在前面,优先使用哪个
#session认证,admin后台其实就使用的session认证,其实接口开发很少用到session认证,所以我们通过配置可以改为其他认证,比如后面项目里面我们用到jwt,JSON WEB TOKEN认证,或者一些配合redis的认证
我们可以自己写个认证类
auth这个应用名,不能使用,运行程序报错,和系统名称冲突

自己写认证类,我们可以参照Session认证类原码写法
Session认证类,继承BaseAuthentication,里面就写了两个方法

再查看BaseAuthentication,里面就写了两个空的方法,啥也没干,说明需要我们继承时重写父类方法
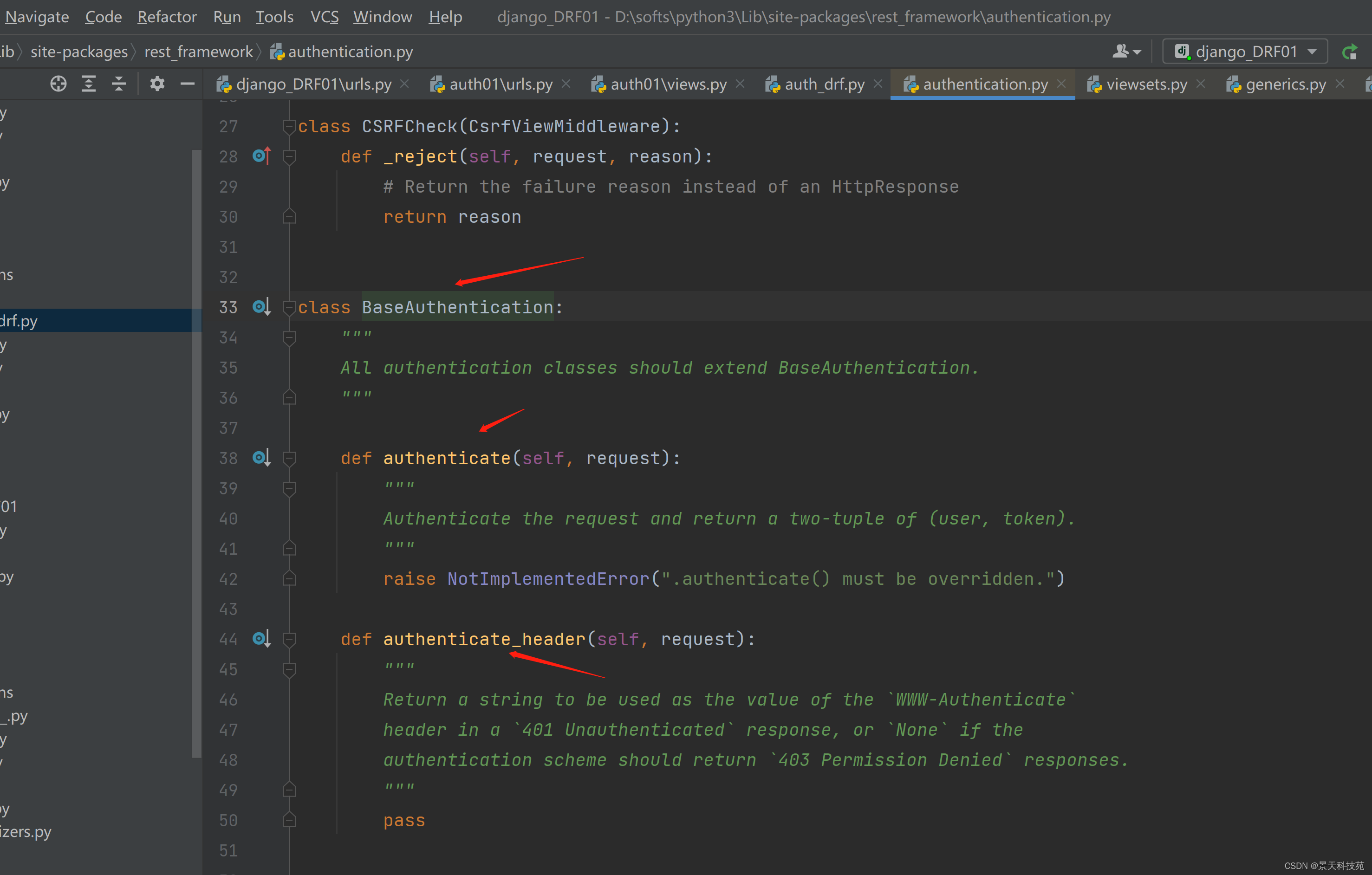
我们自己定义的认证类
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
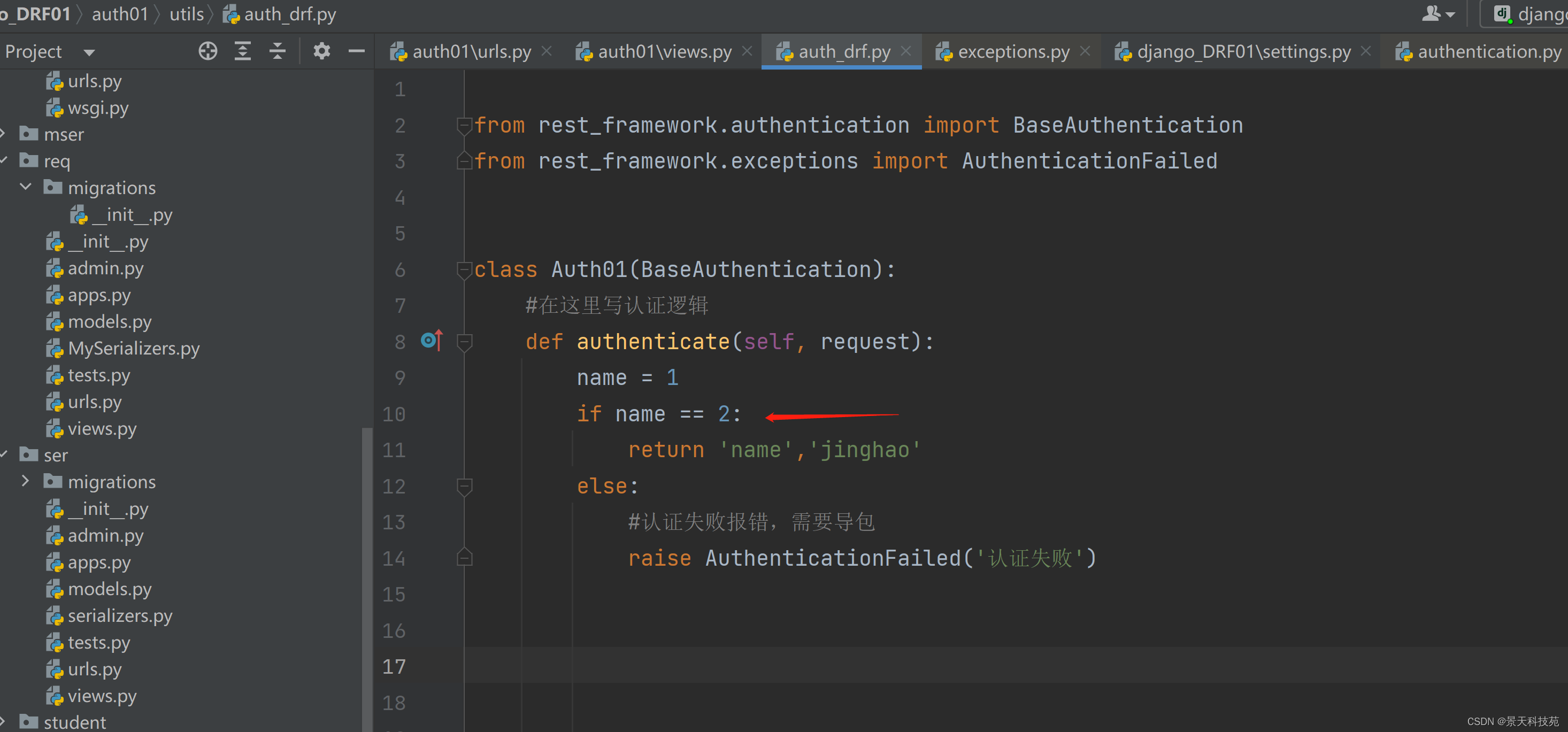
class Auth01(BaseAuthentication):
#在这里写认证逻辑
def authenticate(self, request):
name = 1
if name == 1:
return ‘name’,‘jinghao’ #这里认证返回的元祖数据,第一个被封装在request.user里面,第二个被封装在request.auth里面
else:
#认证失败报错,需要导包
raise AuthenticationFailed(‘认证失败’)
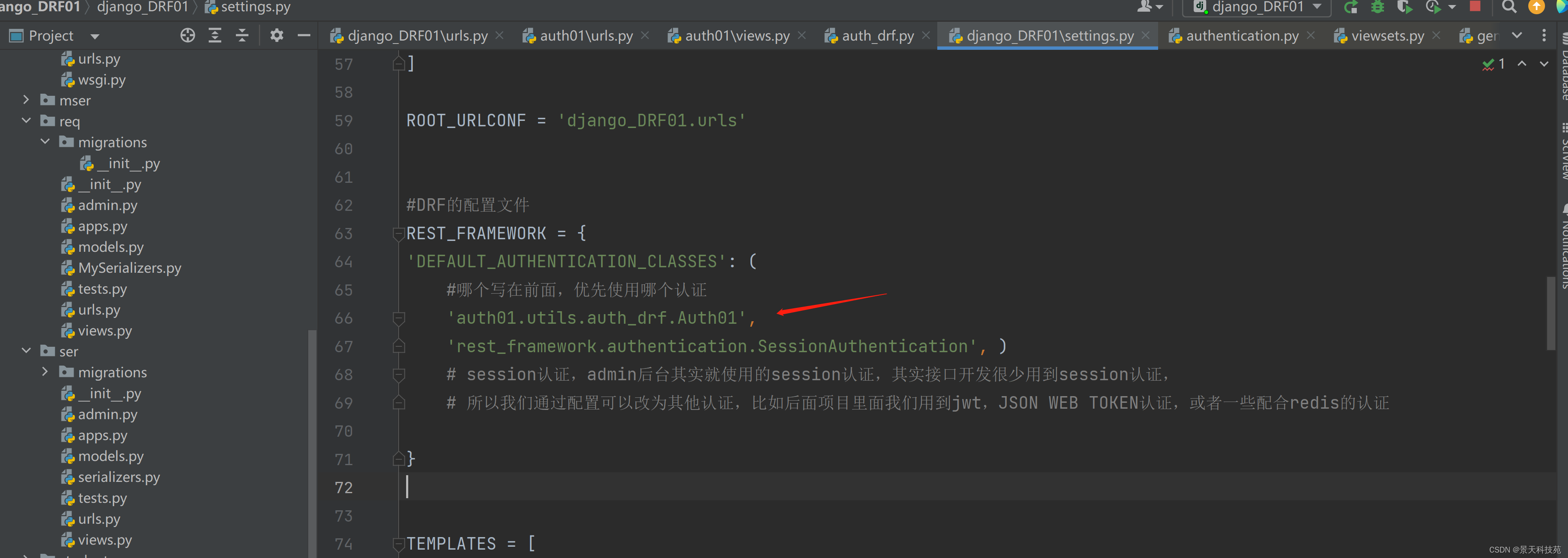
请求来了,先走认证组件,走完认证组件再走视图
全局配置,需要再settings.py里面将我们写的认证组件加进去
视图类
from rest_framework.views import APIView
from rest_framework.response import Response
from ser import models
class StudentView(APIView):
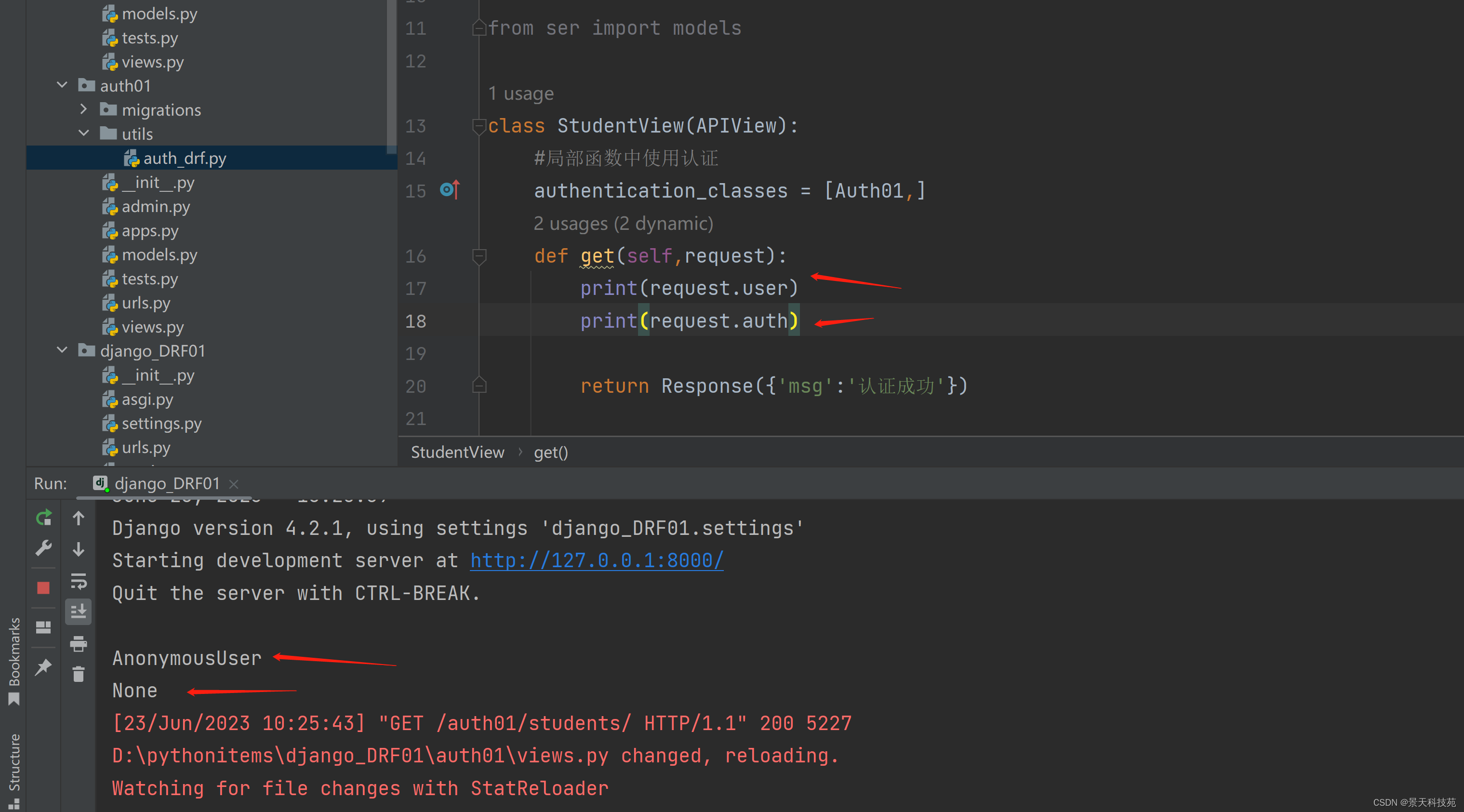
def get(self,request):
print(request.user)
print(request.auth)
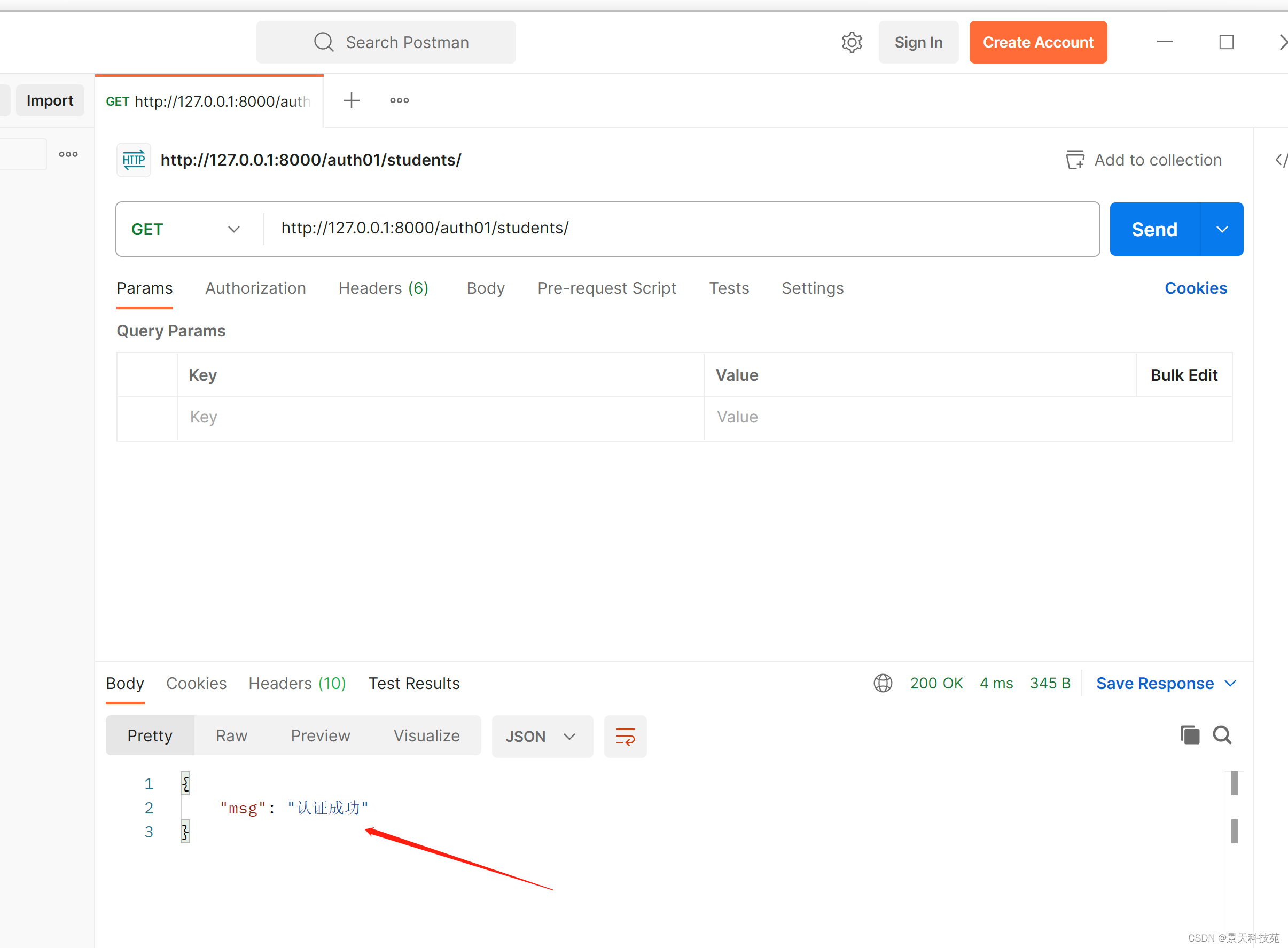
return Response({'msg':'认证成功'})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
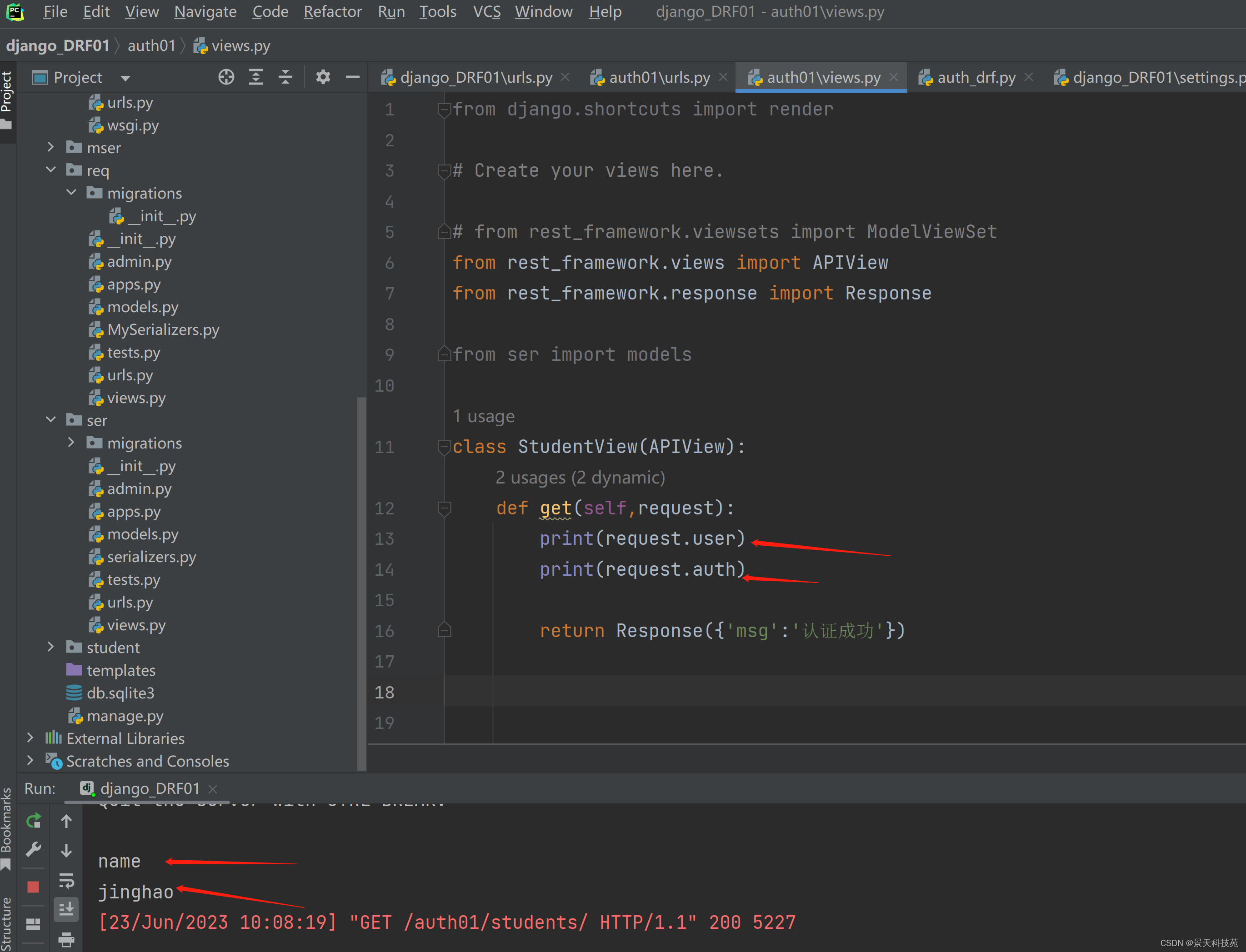
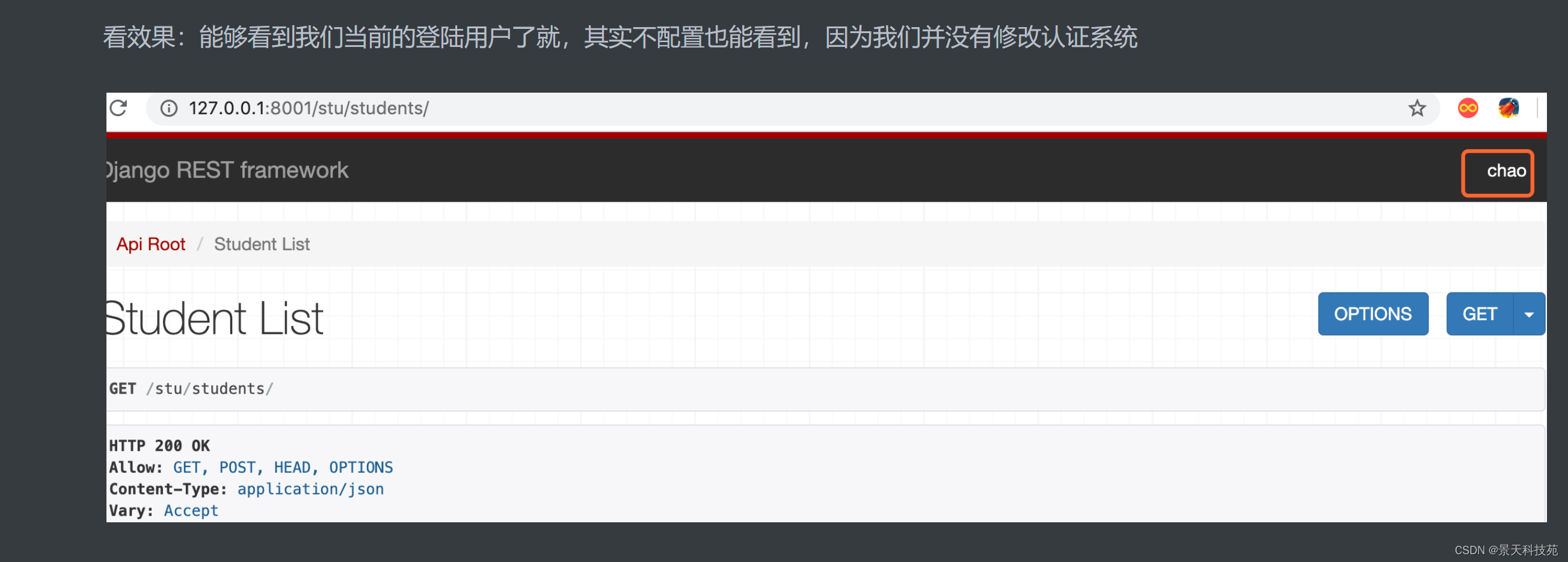
浏览器访问
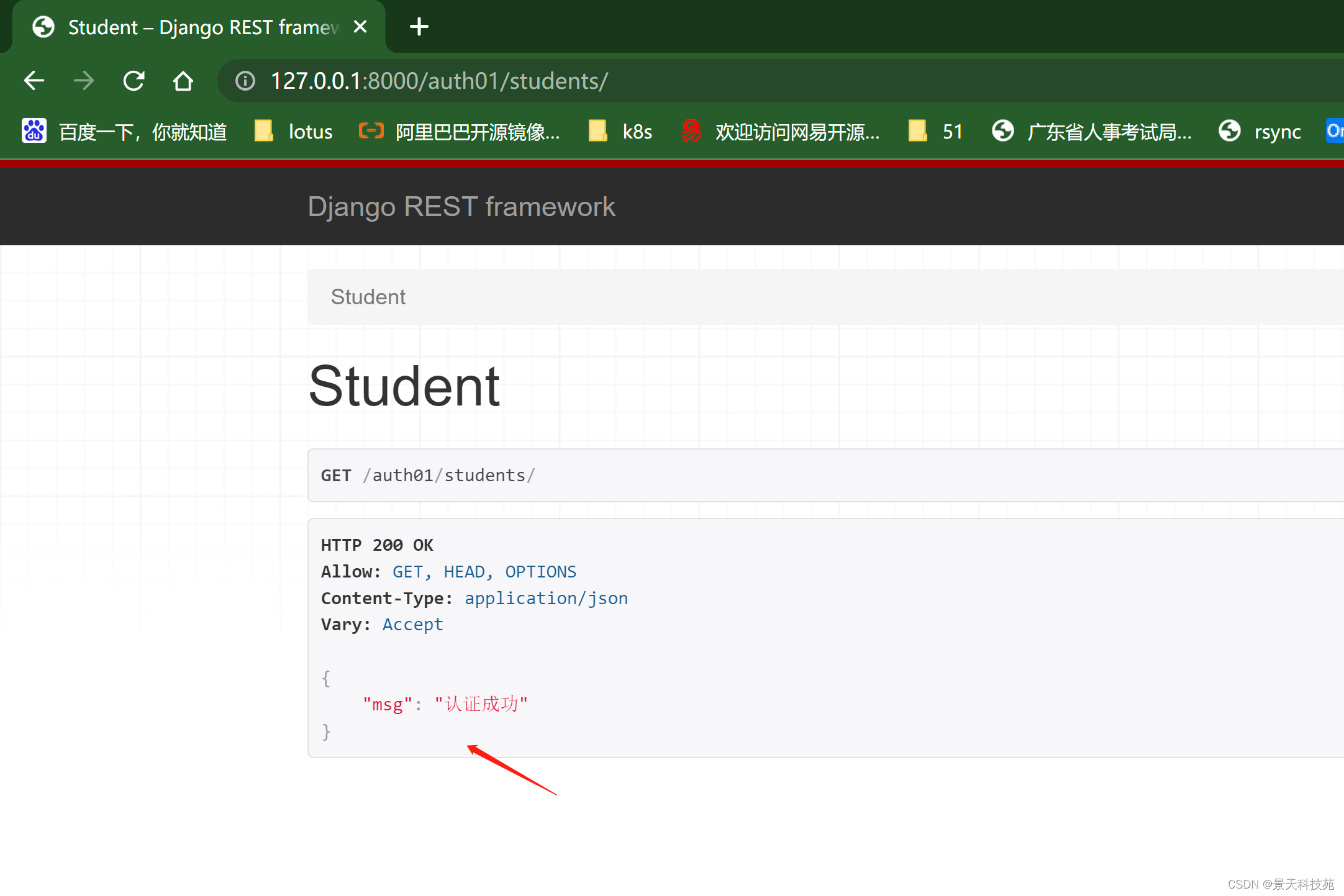
认证失败:
返回json字符串字典键是detail 值是我们定义的
基于登录状态认证,基于requset中的session或cookie的值的判断,来判断用户是否登录
如果认证不通过,视图函数中打印的request.user和request.auth 分别是AnonymousUser和None
上面是全局的视图函数中都生效,所有访问路径都要认证,如果想让一些路径不认证,还要写白名单,比较麻烦
如果想在个别视图函数中生效,可以定义在视图函数里面
先把全局的注释掉

在视图函数中,导包,然后使用
#认证组件也可以写成元祖形式的,到时候我们使用我们自己开发的认证组件的时候,写在列表或元祖中来使用
class StudentView(APIView):
#局部函数中使用认证
authentication_classes = [Auth01,]
def get(self,request):
print(request.user)
print(request.auth)
return Response({'msg':'认证成功'})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

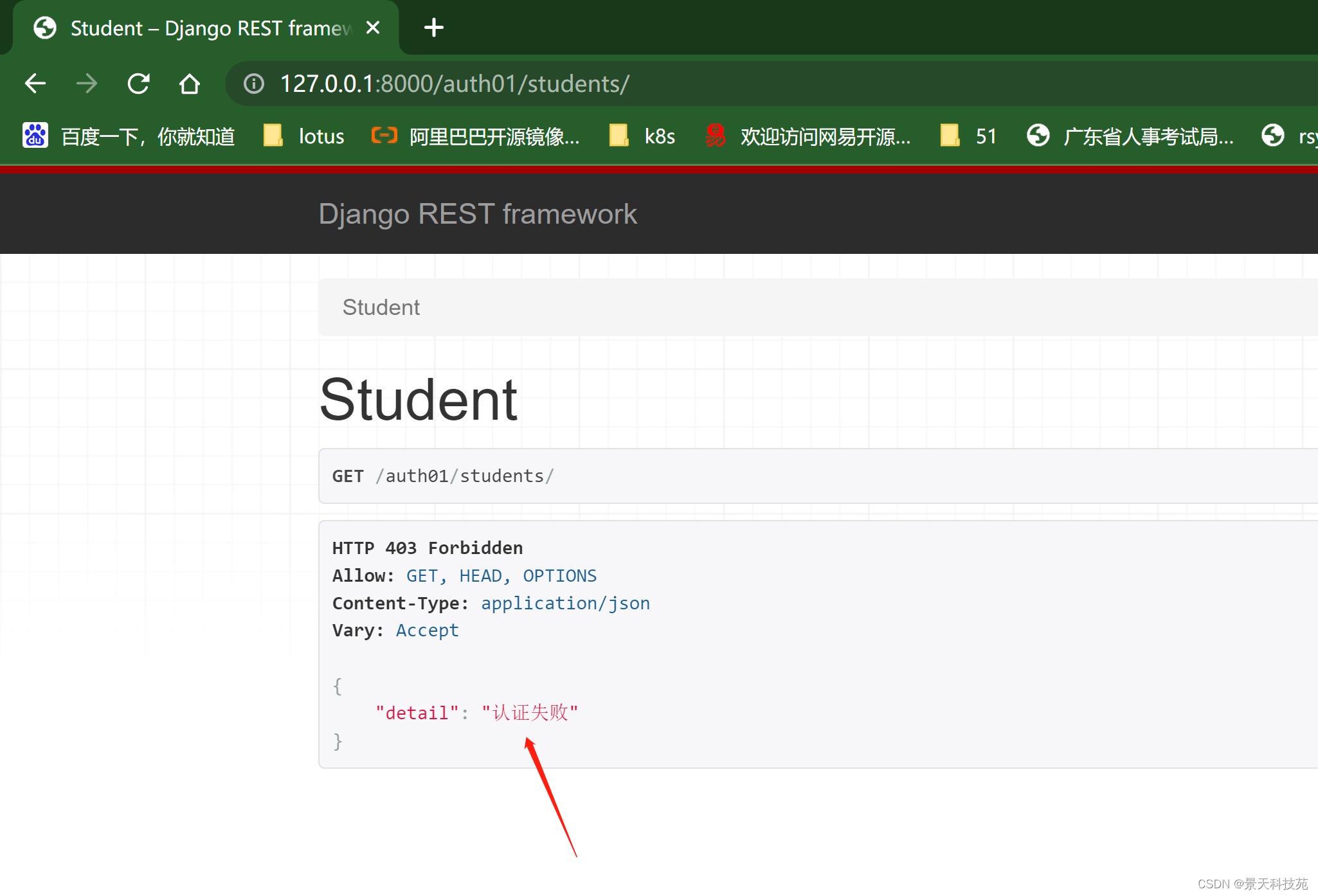
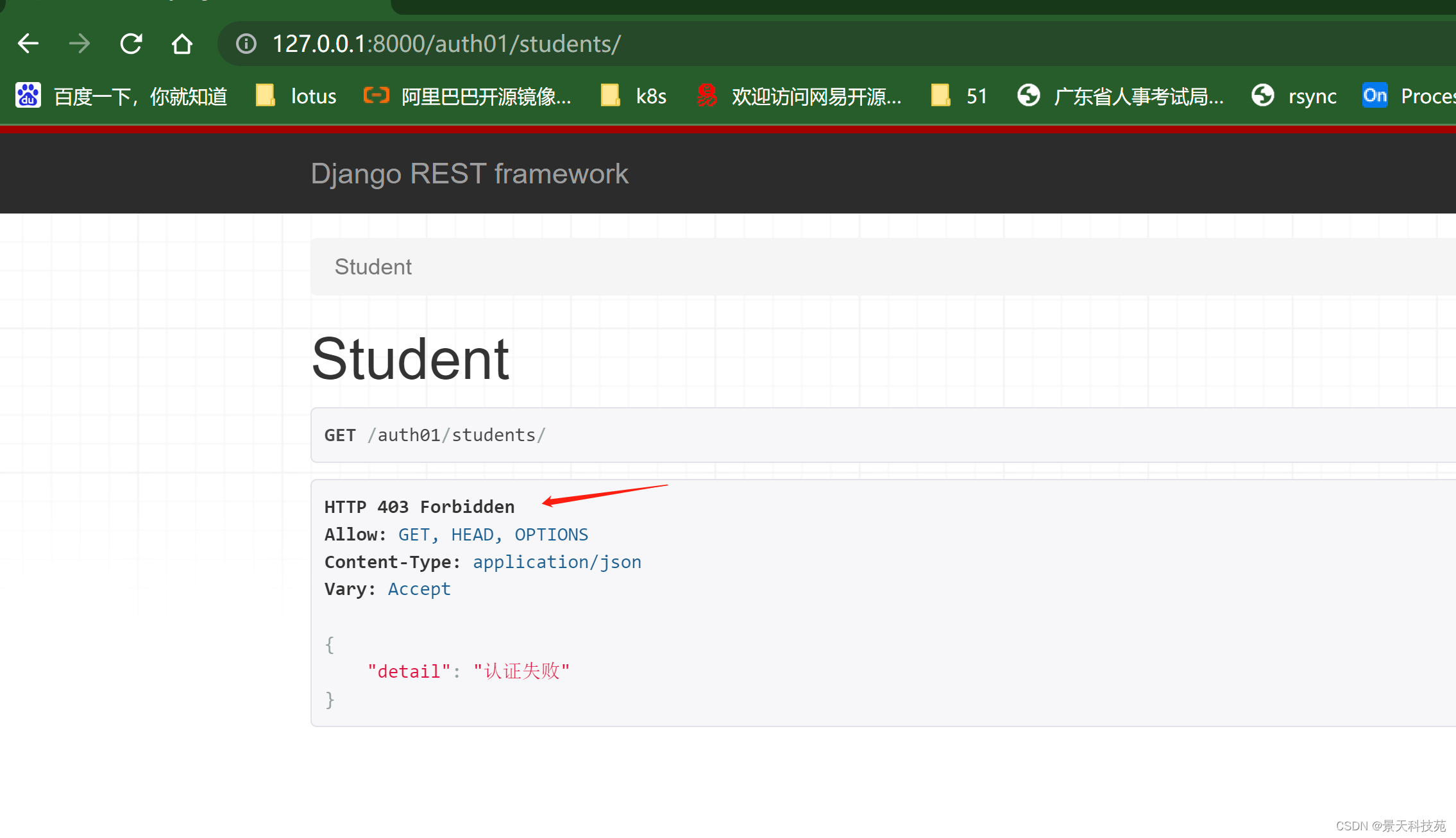
认证组件依然生效

认证失败,返回403状态码
2.权限Permissions
权限控制可以限制用户对于视图的访问和对于具体数据对象的访问。
- 在执行视图的dispatch()方法前,会先进行视图访问权限的判断
- 在通过get_object()获取具体对象时,会进行模型对象访问权限的判断
###使用
可以在配置文件中全局设置默认的权限管理类,如
REST_FRAMEWORK = {
…
'DEFAULT_PERMISSION_CLASSES': (
'rest_framework.permissions.IsAuthenticated', #登录状态下才能访问我们的接口,可以通过退出admin后台之后,你看一下还能不能访问我们正常的接口就看到效果了
)
- 1
- 2
- 3
}
未指明,使用的就是默认的权限配置,允许所有用户访问
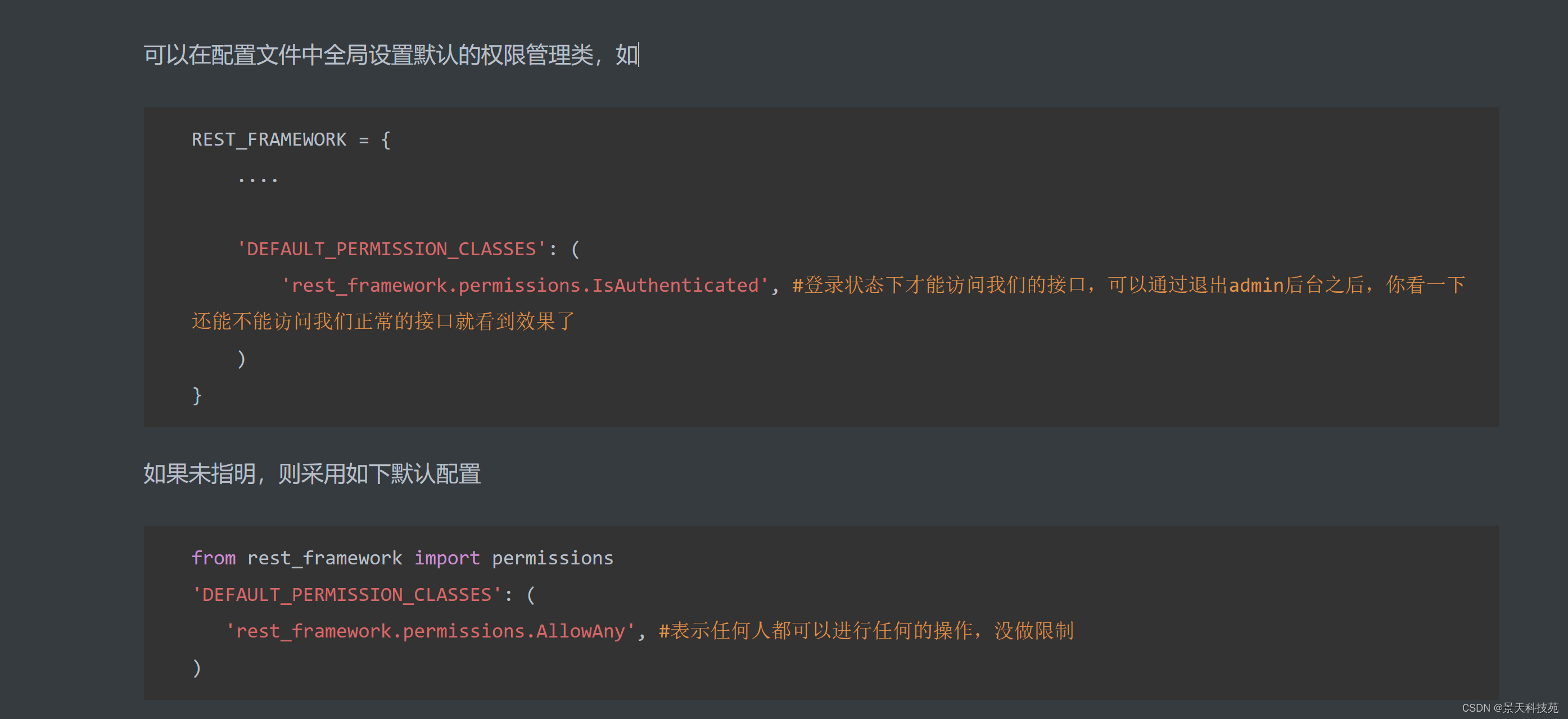
查看原码默认权限:
允许任何人访问
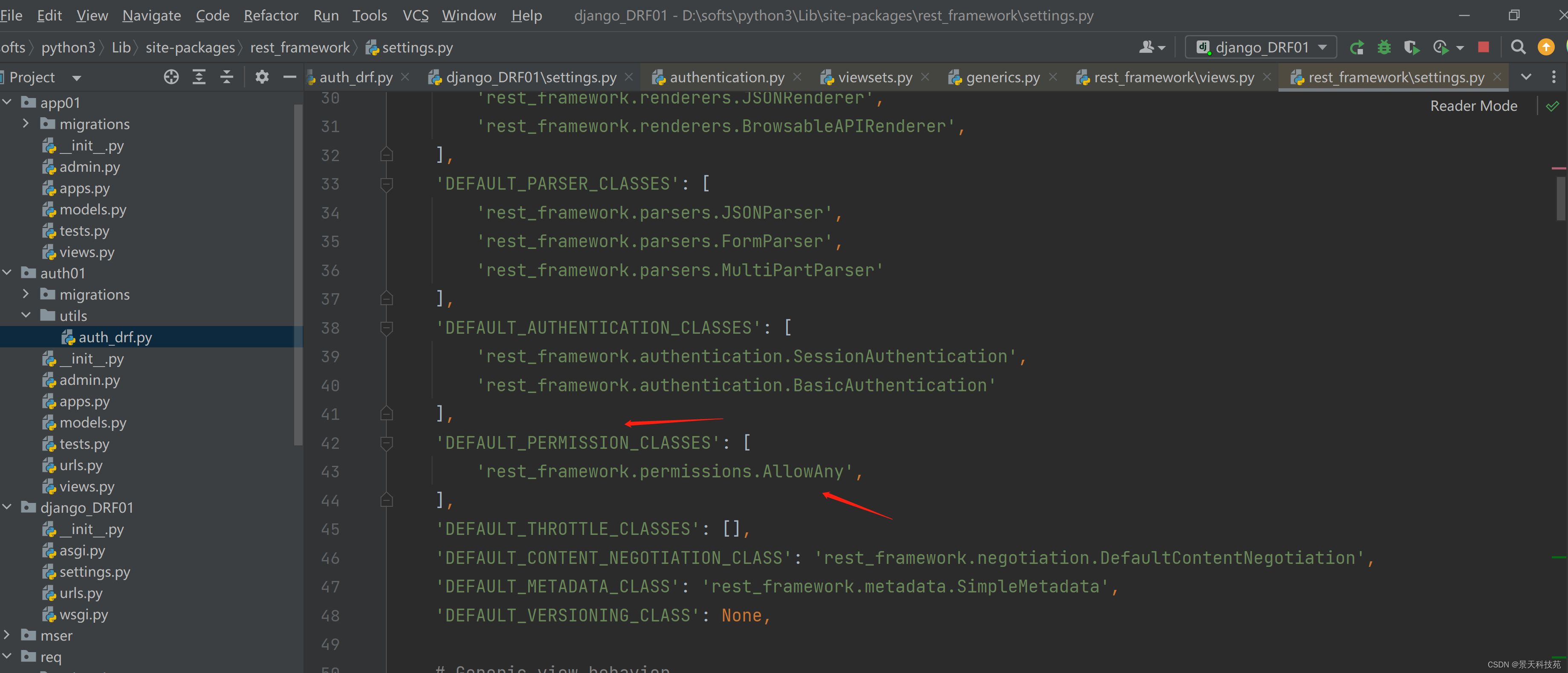
原码自带的,提供的权限: 自带的基本不用,一般都是自定义
- AllowAny 允许所有用户
- IsAuthenticated 仅通过认证的用户
- IsAdminUser 仅管理员用户
- IsAuthenticatedOrReadOnly 已经登录的用户可以对数据进行增删改查操作,没登录的用户只能查看
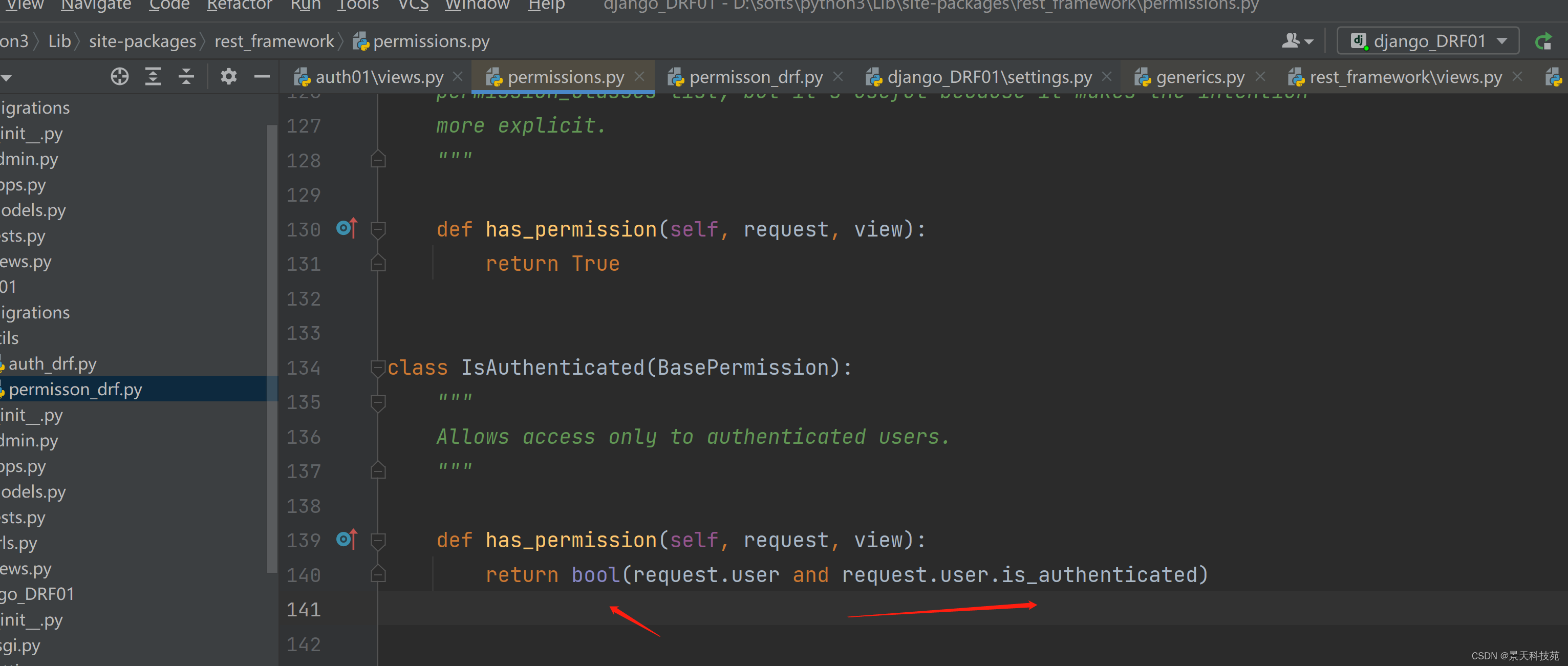
自定义权限:
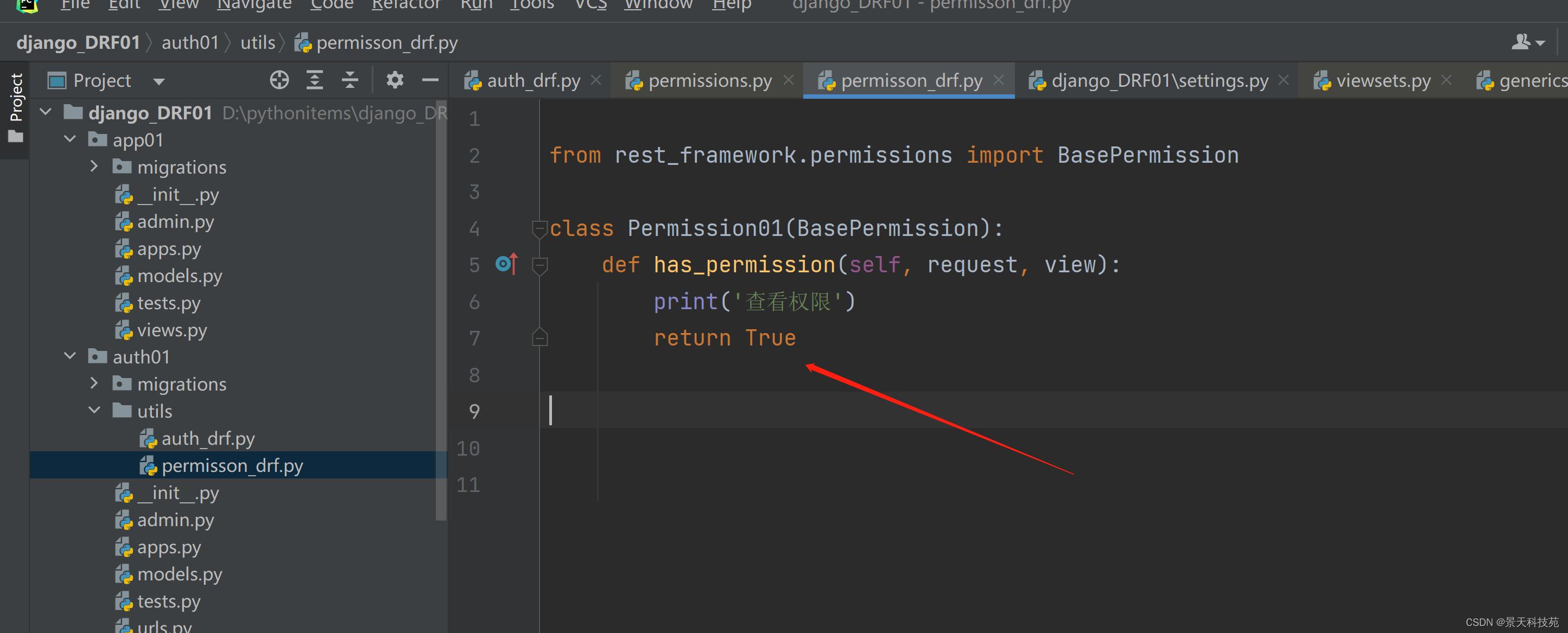
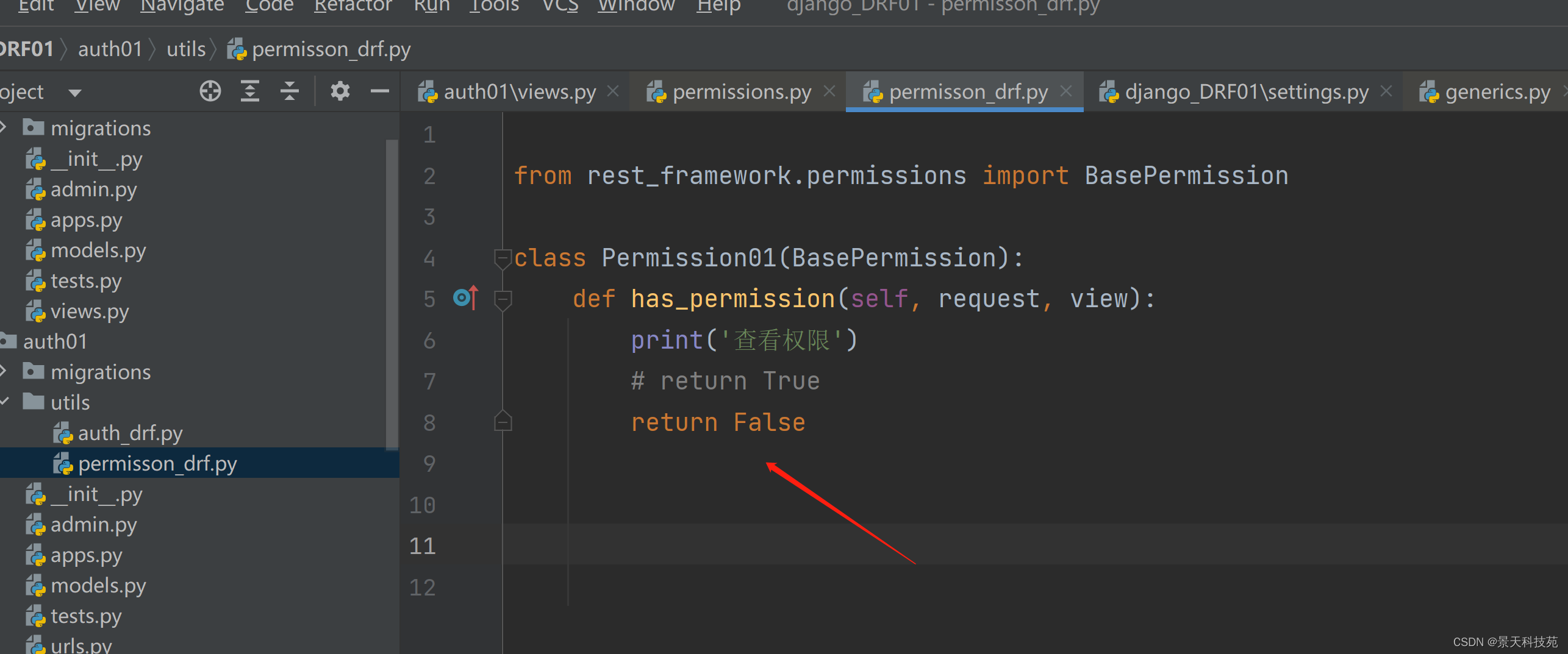
我们写的权限类,继承BasePermission
重写has_permission方法。有权限,返回True, 没有权限返回False

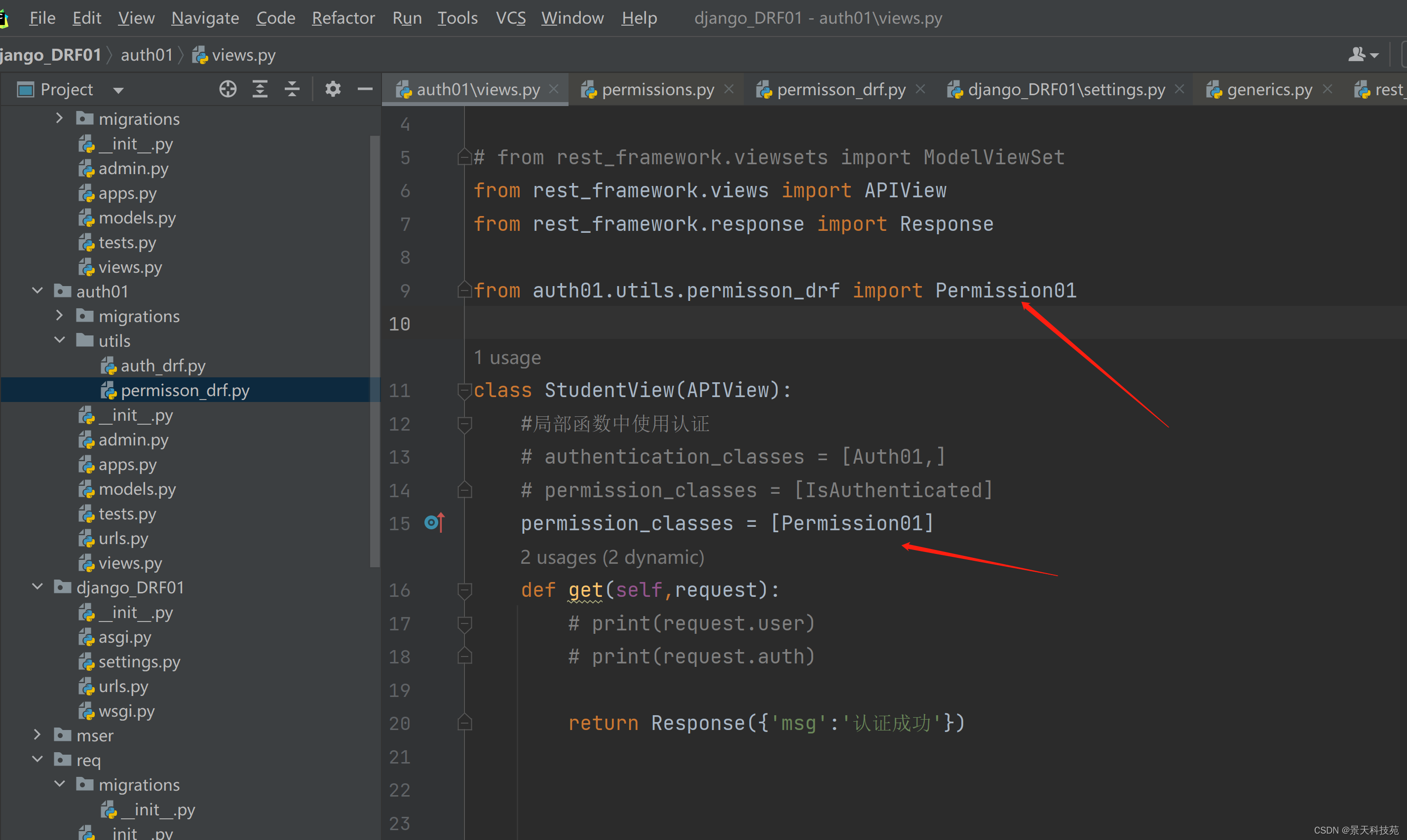
局部视图函数中使用
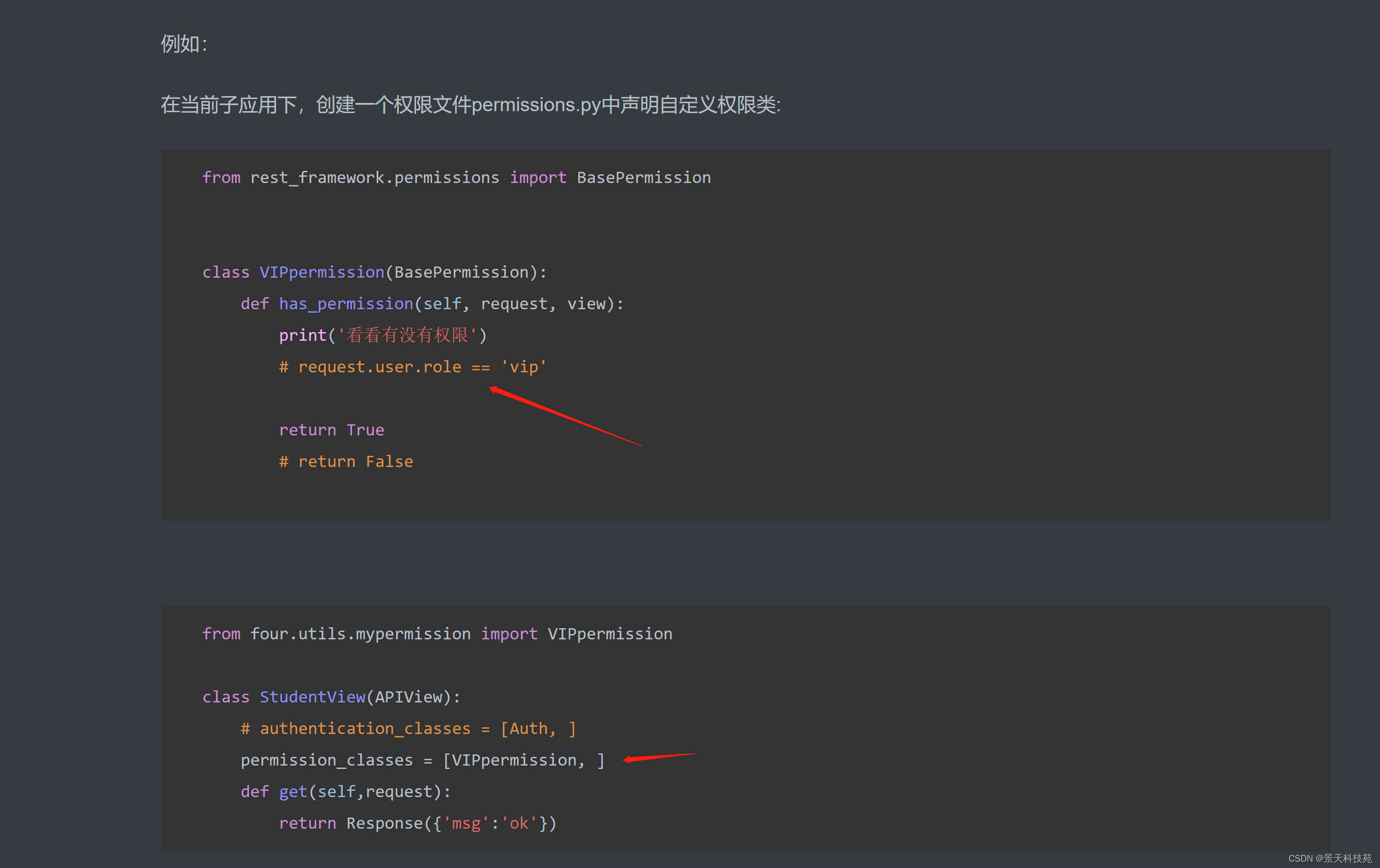
自定义权限类:
比如可以根据 request.user.role == ‘vip’ 判断是vip会员返回True,非vip会员返回False
全局配置:

视图函数,没有变化
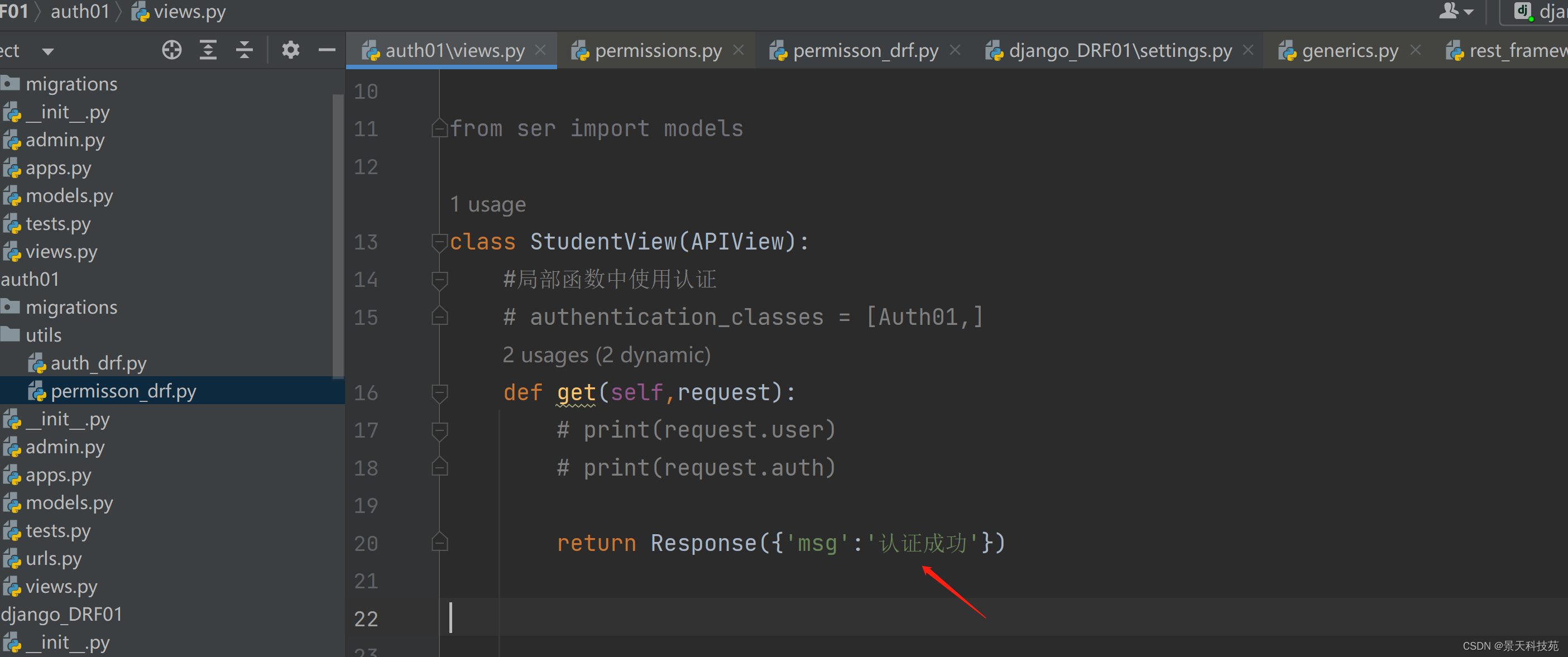
认证通过
如果我们返回Flase
访问会有报错

在admin管理系统中,有管理员和非管理员之说,后面我们登录认证不用admin的
局部视图函数使用权限组件
3.限流Throttling
可以对接口访问的频次进行限制,以减轻服务器压力。
一般用于付费购买次数,投票等场景使用.
##使用,可以全局使用,也可以局部使用
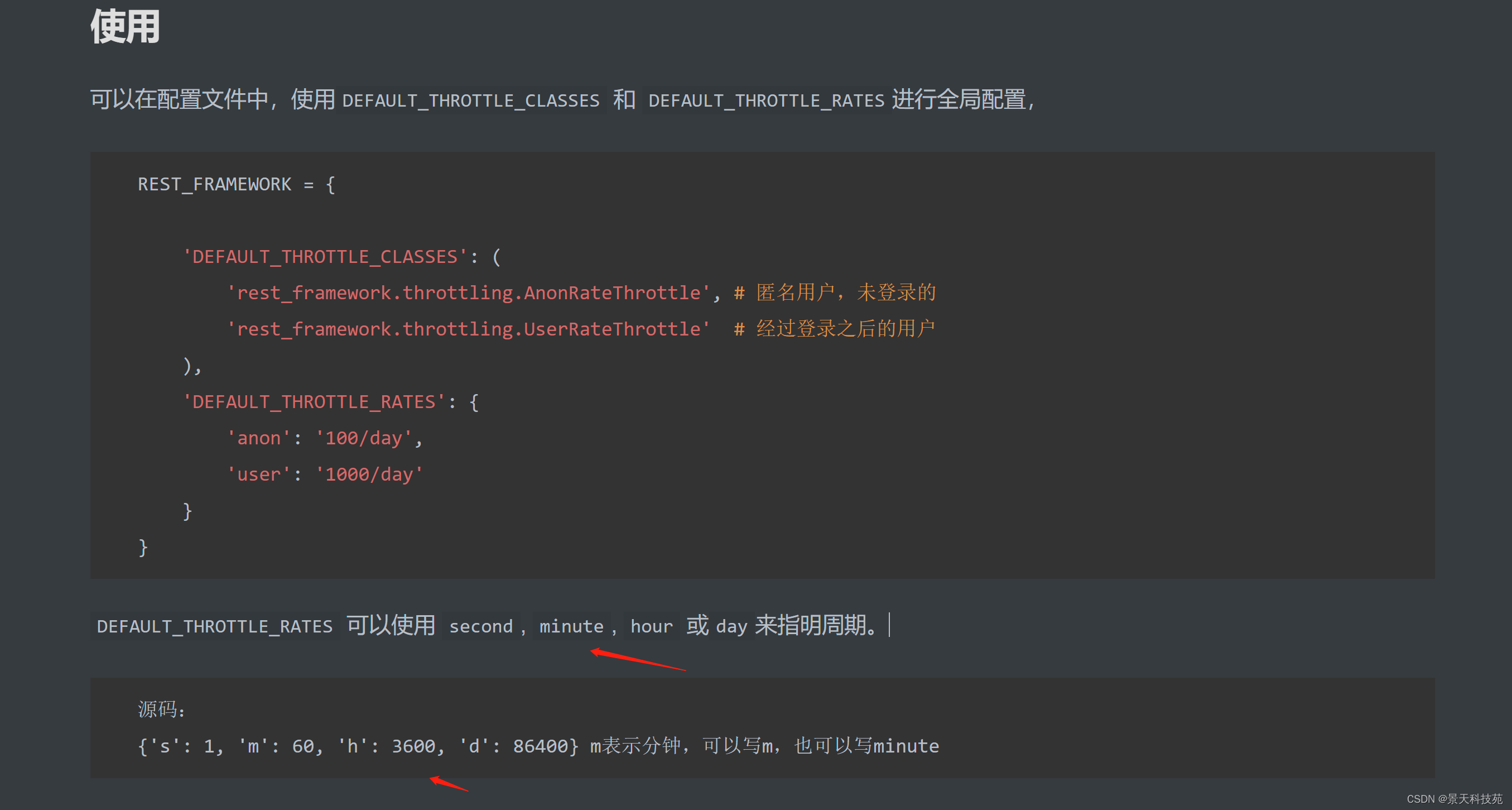
可以在配置文件中,使用DEFAULT_THROTTLE_CLASSES`和 DEFAULT_THROTTLE_RATES进行全局配置,
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle', # 匿名用户,未登录的 这俩是DRF提供的访问频率限制类
'rest_framework.throttling.UserRateThrottle' # 经过登录之后的用户
),
'DEFAULT_THROTTLE_RATES': {
'anon': '100/day',
'user': '1000/day'
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

原码,默认没有做任何访问频率限制

我们使用DRF自带的:
允许任何用户访问
未登录用户限制每分钟3次,登录用户限制每分钟5次
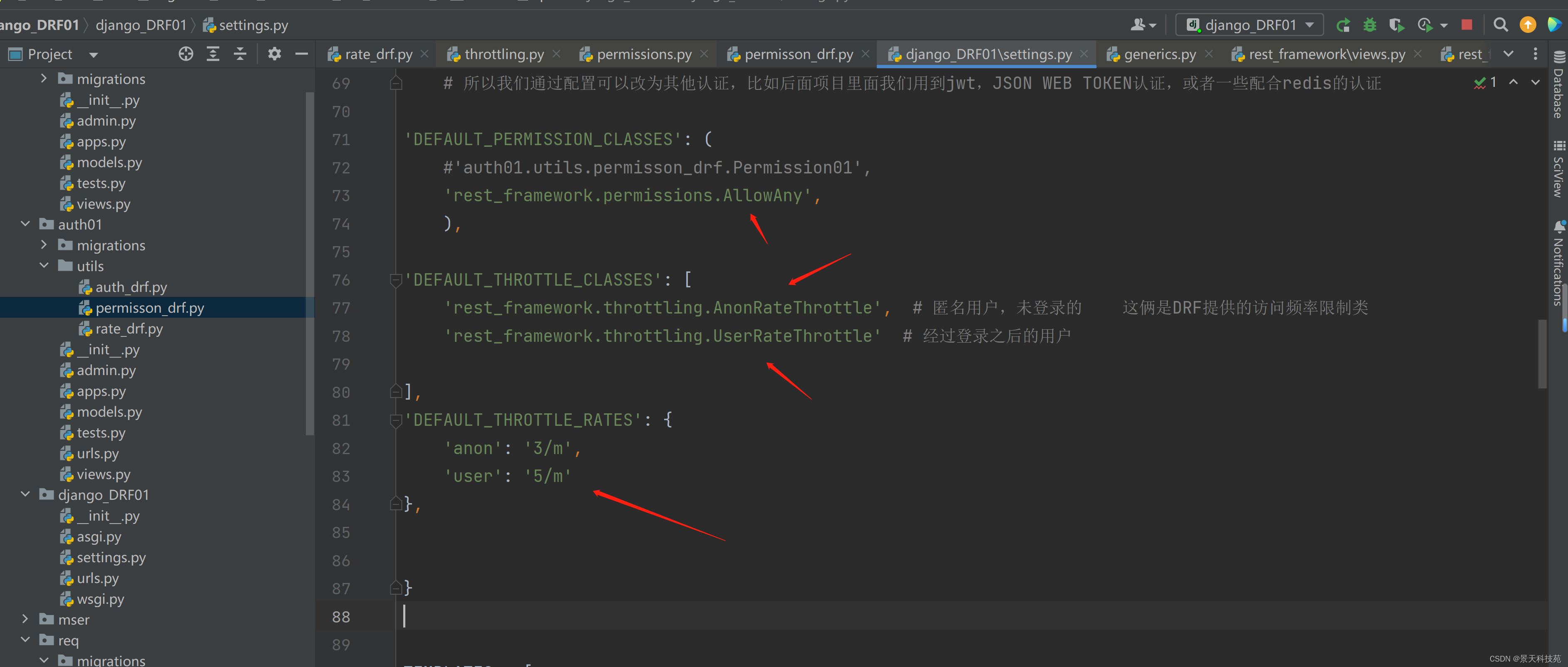
超次数之后,就不让访问了
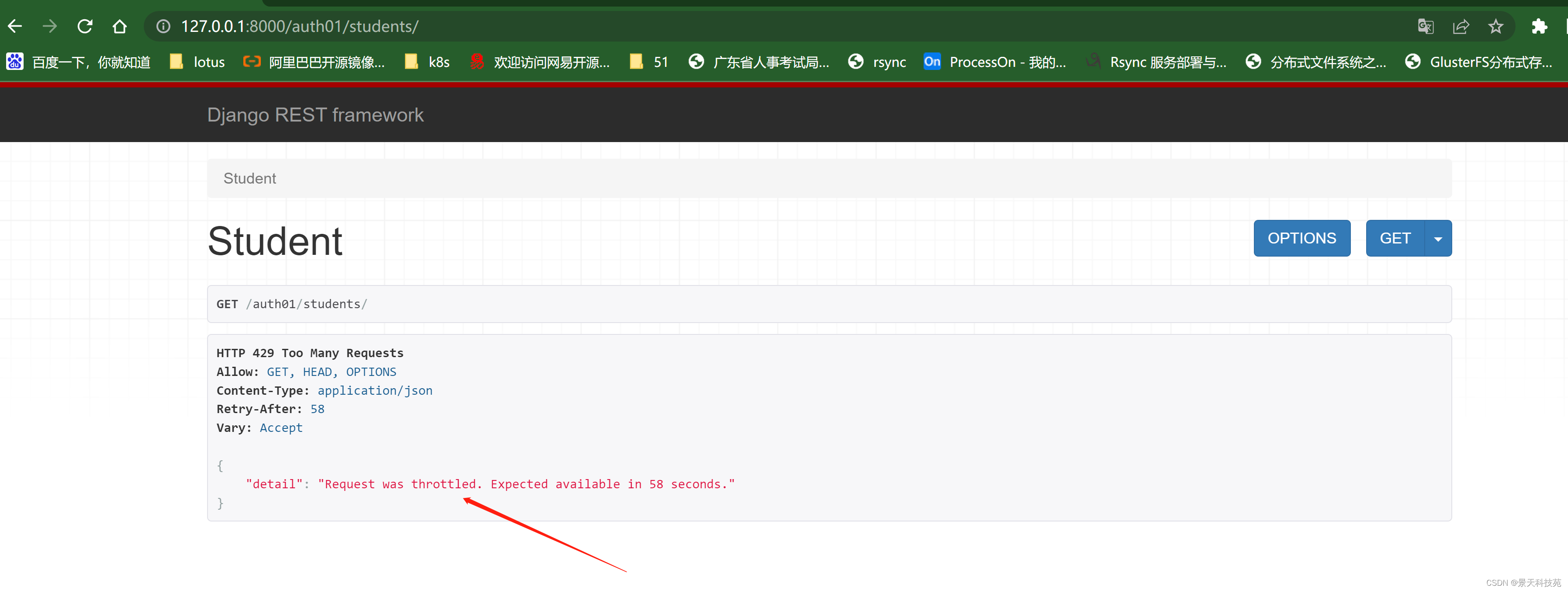
也可以局部使用
也可以在具体视图中通过throttle_classess属性来配置,如
from rest_framework.throttling import UserRateThrottle
from rest_framework.views import APIView
class ExampleView(APIView):
throttle_classes = (UserRateThrottle,)
…
自定义访问频率限制:
from rest_framework.throttling import BaseThrottle,SimpleRateThrottle
import time
from rest_framework import exceptions
visit_record = {}
class VisitThrottle(BaseThrottle):
# 限制访问时间
VISIT_TIME = 10
VISIT_COUNT = 3
# 定义方法 方法名和参数不能变
def allow_request(self, request, view):
# 获取登录主机的ip
id = request.META.get('REMOTE_ADDR')
self.now = time.time()
if id not in visit_record:
visit_record[id] = []
self.history = visit_record[id]
# 限制访问时间
while self.history and self.now - self.history[-1] > self.VISIT_TIME:
self.history.pop()
# 此时 history中只保存了最近10秒钟的访问记录
if len(self.history) >= self.VISIT_COUNT:
return False
else:
self.history.insert(0, self.now)
return True
def wait(self): #返回剩余秒数,过多久可以再次访问
return self.history[-1] + self.VISIT_TIME - self.now
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4.过滤Filtering
对于列表数据可能需要根据字段进行过滤,我们可以通过添加django-fitlter扩展来增强支持。

需要安装这个模块
pip install django-filter
和rest_framework一样,需要将该模块注册到应用,settings.py中配置

rest_framework配置文件中,将过滤器加进去
‘DEFAULT_FILTER_BACKENDS’: (‘django_filters.rest_framework.DjangoFilterBackend’,),
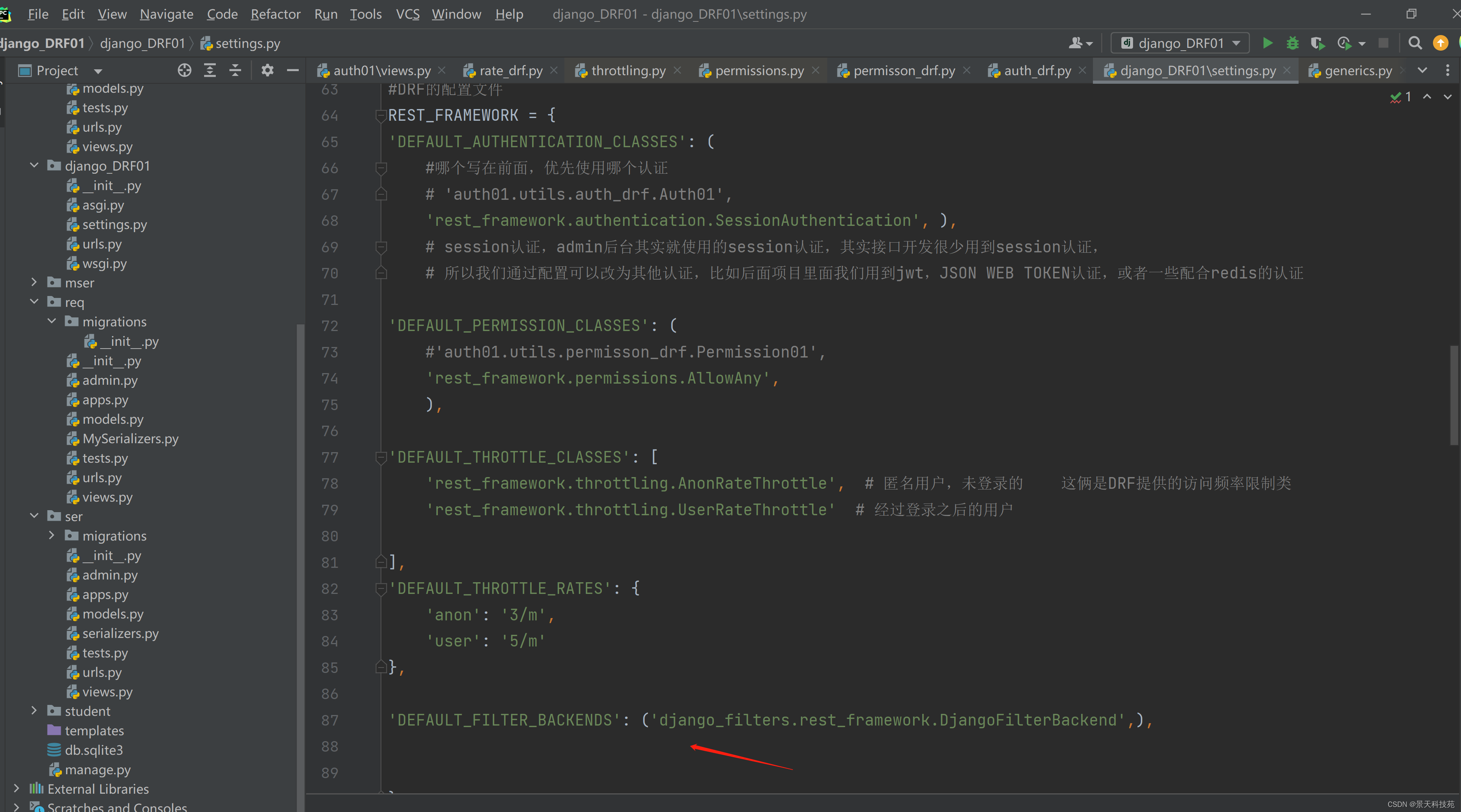
视图函数中使用过滤字段
filter_fields = (‘name’,‘age’)
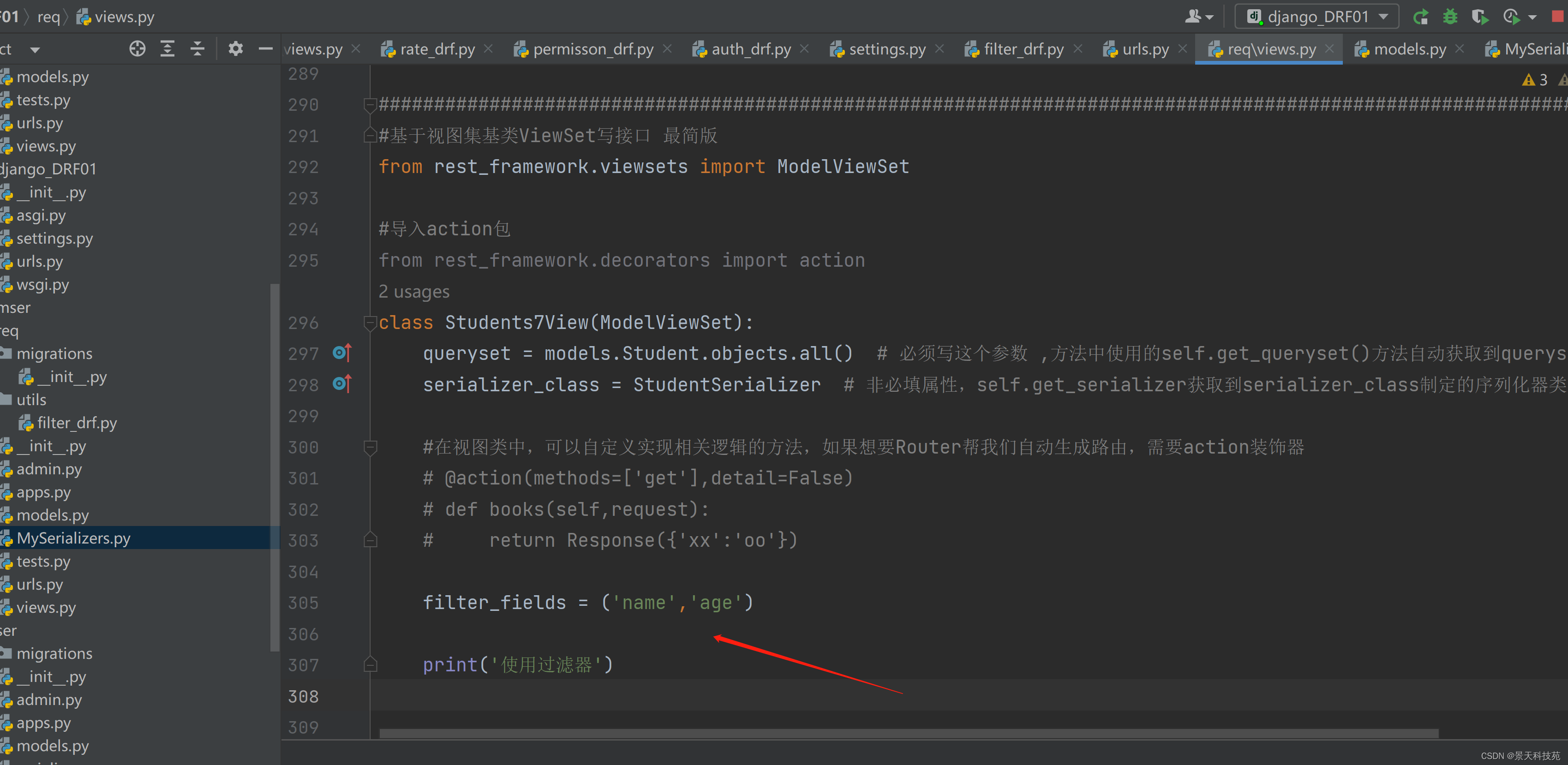
查询时,将过滤参数添加到url中 以 ?name=xx&age=xx 的形式传递过滤参数
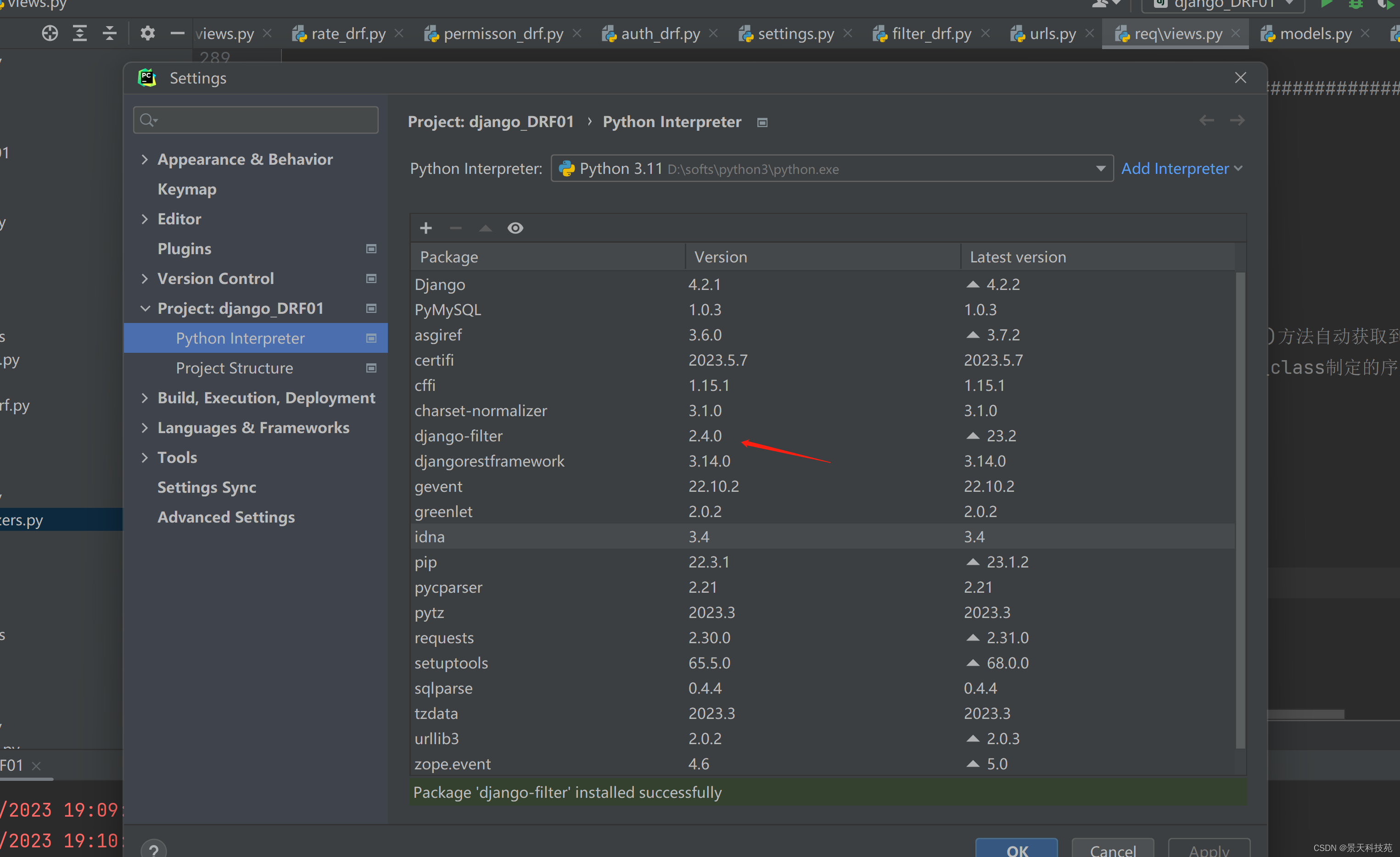
用最新的django-filter,过滤一直不生效,一直查询的都是全部数据
我们换成2.4.0版本就可以了
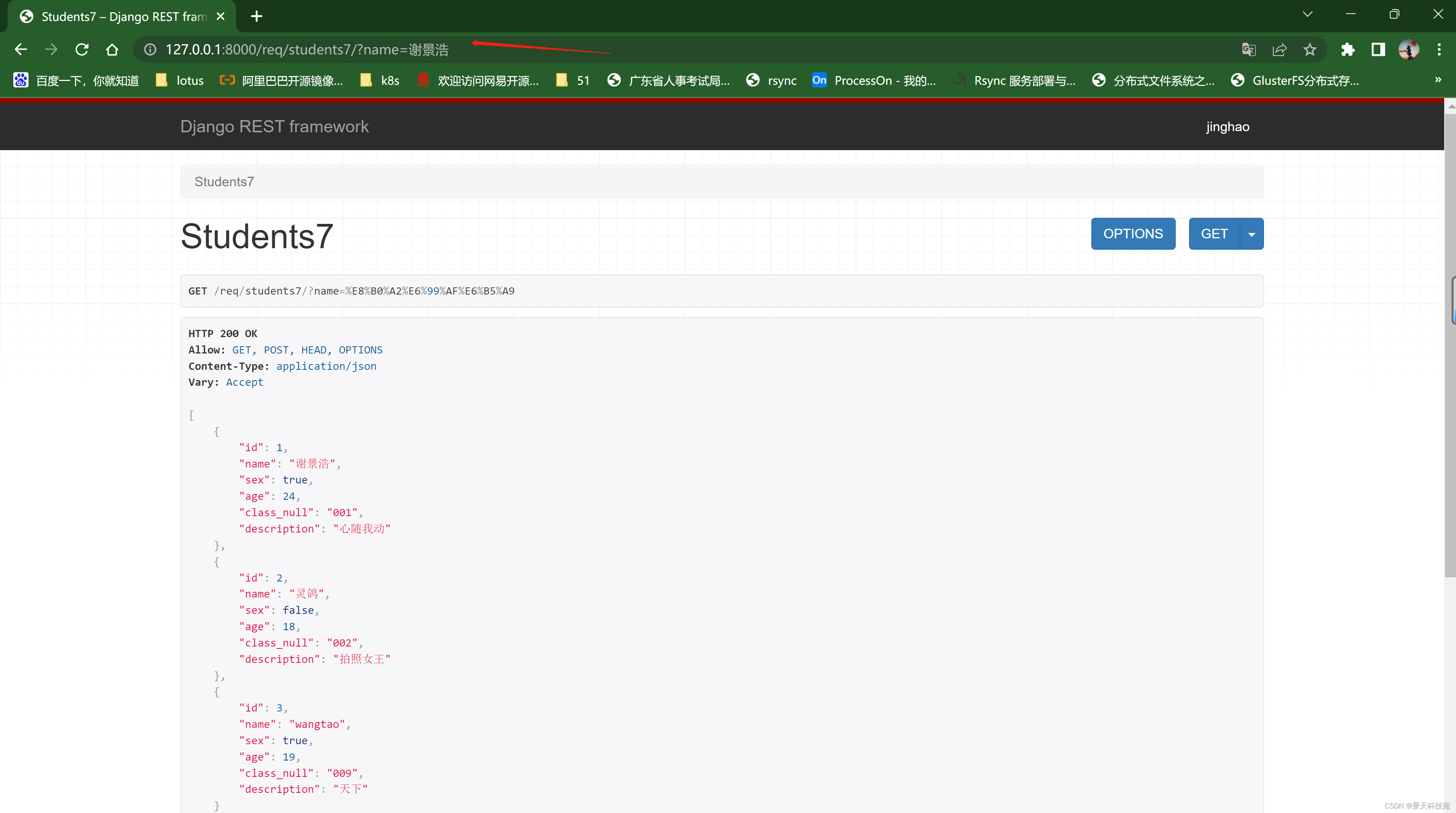
可以正常得到过滤数据,版本害死人啊

多条件组合查询,以&连接
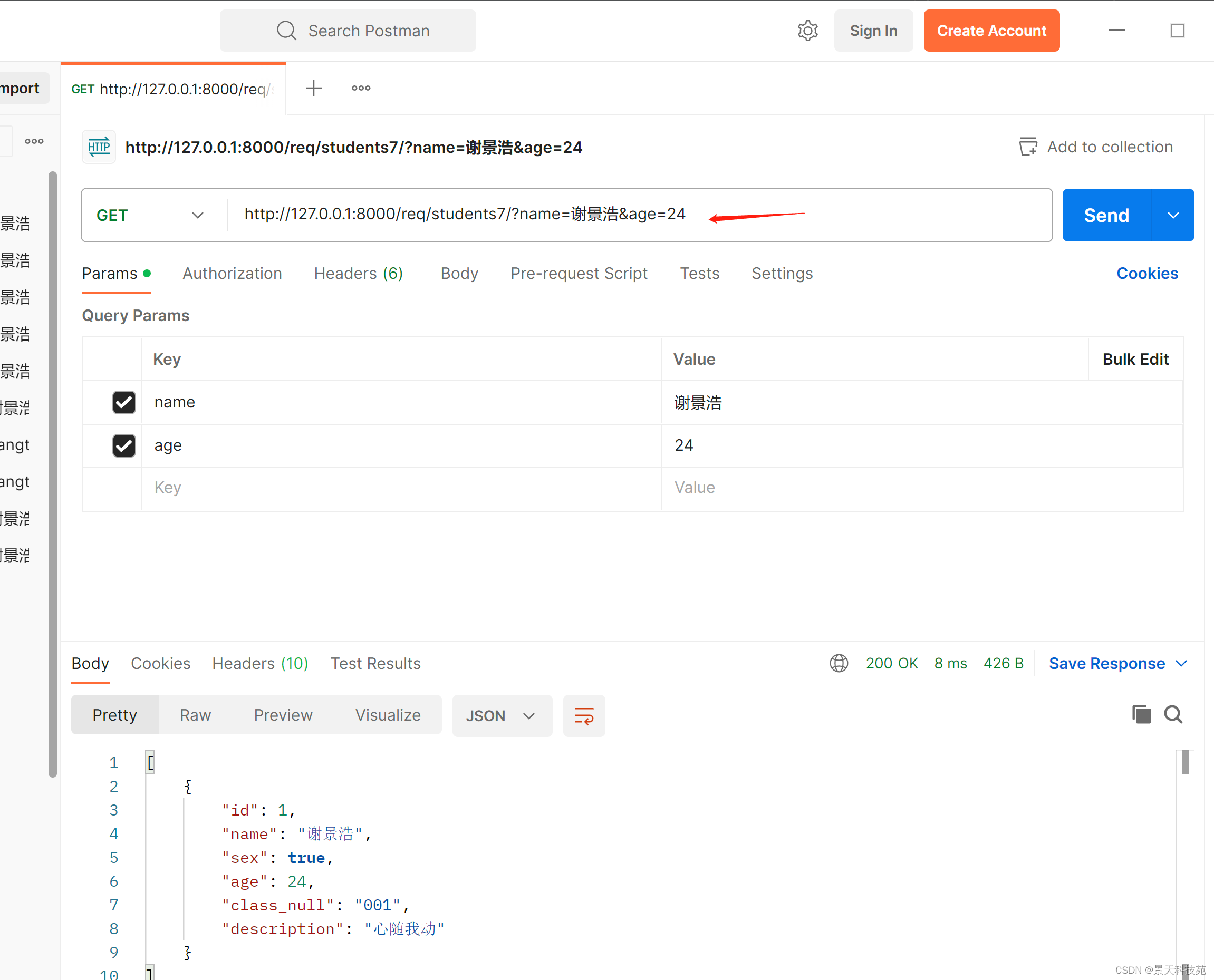
只能精确查询
5.排序
对于列表数据,REST framework提供了OrderingFilter过滤器来帮助我们快速指明数据按照指定字段进行排序。
使用方法:
在类视图中设置filter_backends,使用rest_framework.filters.OrderingFilter过滤器,REST framework会在请求的查询字符串参数中检查是否包含了ordering参数,如果包含了ordering参数,则按照ordering参数指明的排序字段对数据集进行排序。
前端可以传递的ordering参数的可选字段值需要在ordering_fields中指明。
from rest_framework.filters import OrderingFilter
class Students7View(ModelViewSet):
queryset = models.Student.objects.all() # 必须写这个参数 ,方法中使用的self.get_queryset()方法自动获取到queryset属性数据
serializer_class = StudentModelSerializer # 非必填属性,self.get_serializer获取到serializer_class制定的序列化器类
filter_backends = (OrderingFilter,)
ordering_fields = ('id', 'age')
# students/?ordering=-id
# url处写法: 127.0.0.1:8000/books/?ordering=-age
# 必须是ordering=某个值
# -id 表示针对id字段进行倒序排序
# id 表示针对id字段进行升序排序
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

查看已生效
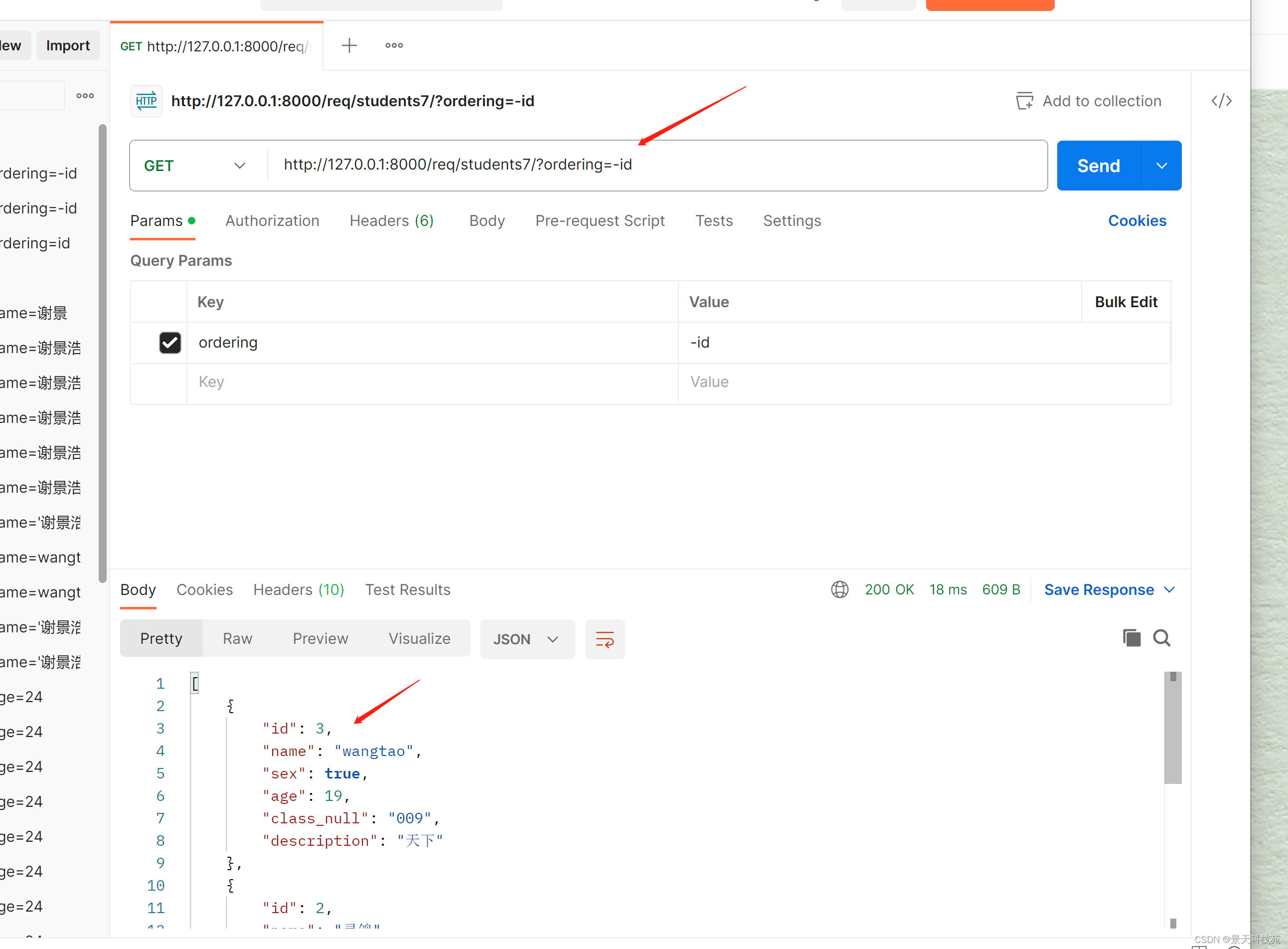
如果需要在过滤以后再次进行排序,则需要两者结合!
from rest_framework.generics import ListAPIView
from students.models import Student
from .serializers import StudentModelSerializer
from django_filters.rest_framework import DjangoFilterBackend #需要使用一下它才能结合使用
class Student3ListView(ListAPIView):
queryset = Student.objects.all()
serializer_class = StudentModelSerializer
filter_fields = ('age', 'sex')
# 因为filter_backends是局部过滤配置,局部配置会覆盖全局配置,所以需要重新把过滤组件核心类再次声明,
# 否则过滤功能会失效
filter_backends = [OrderingFilter,DjangoFilterBackend]
ordering_fields = ('id', 'age')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
#127.0.0.1:8000/books/?sex=1&ordering=-age
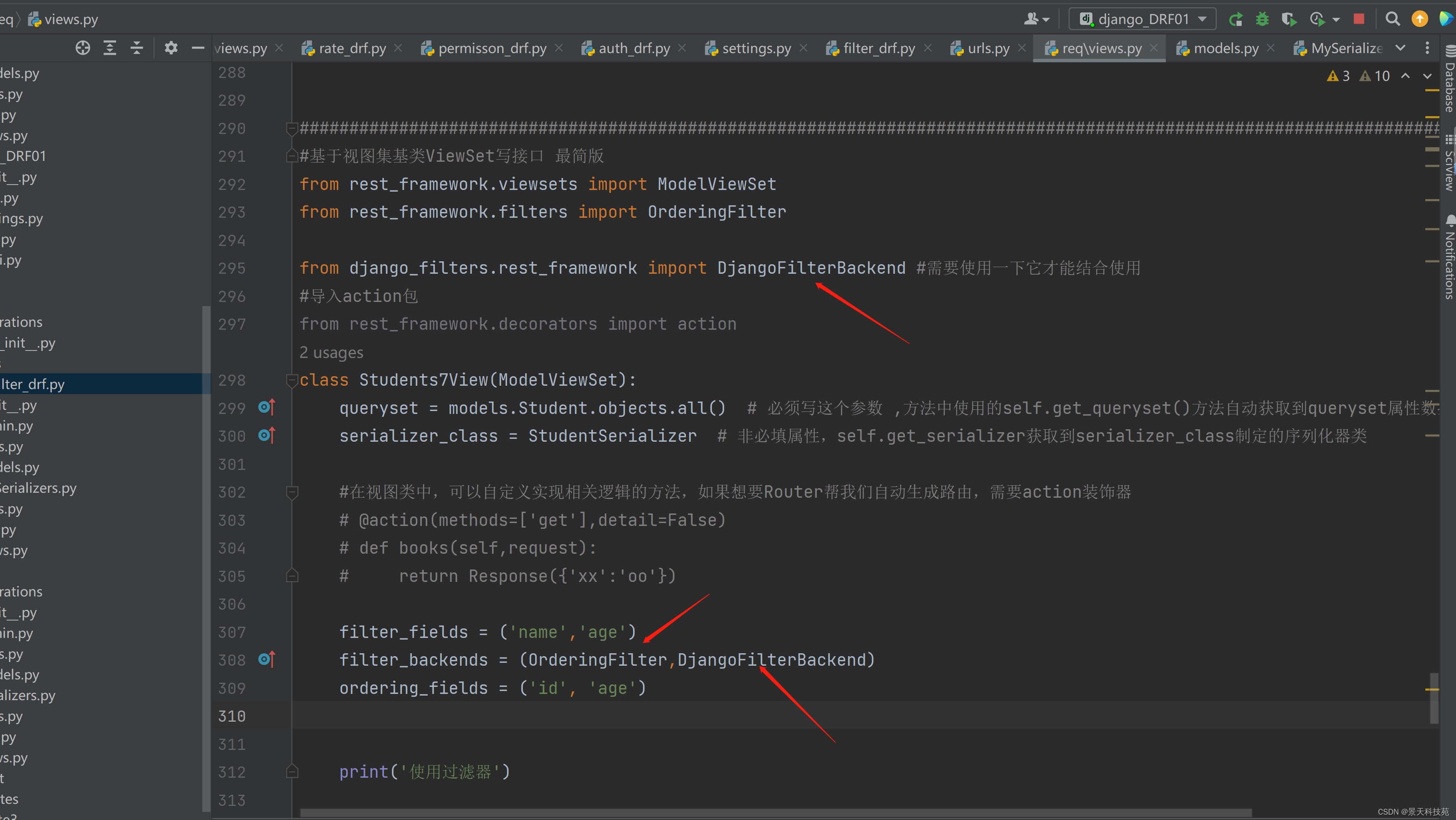
过滤后排序生效
6.分页Pagination
REST framework提供了分页的支持。
我们可以在配置文件中设置全局的分页方式,如:
REST_FRAMEWORK = {
#全局分页,一旦设置了全局分页,那么我们drf中的视图扩展类里面的list方法提供的列表页都会产生分页的效果。所以一般不用全局分页
‘DEFAULT_PAGINATION_CLASS’: ‘rest_framework.pagination.PageNumberPagination’,
‘PAGE_SIZE’: 100 # 每页最大数据量
}
全局配置:

每页显示两条,生效
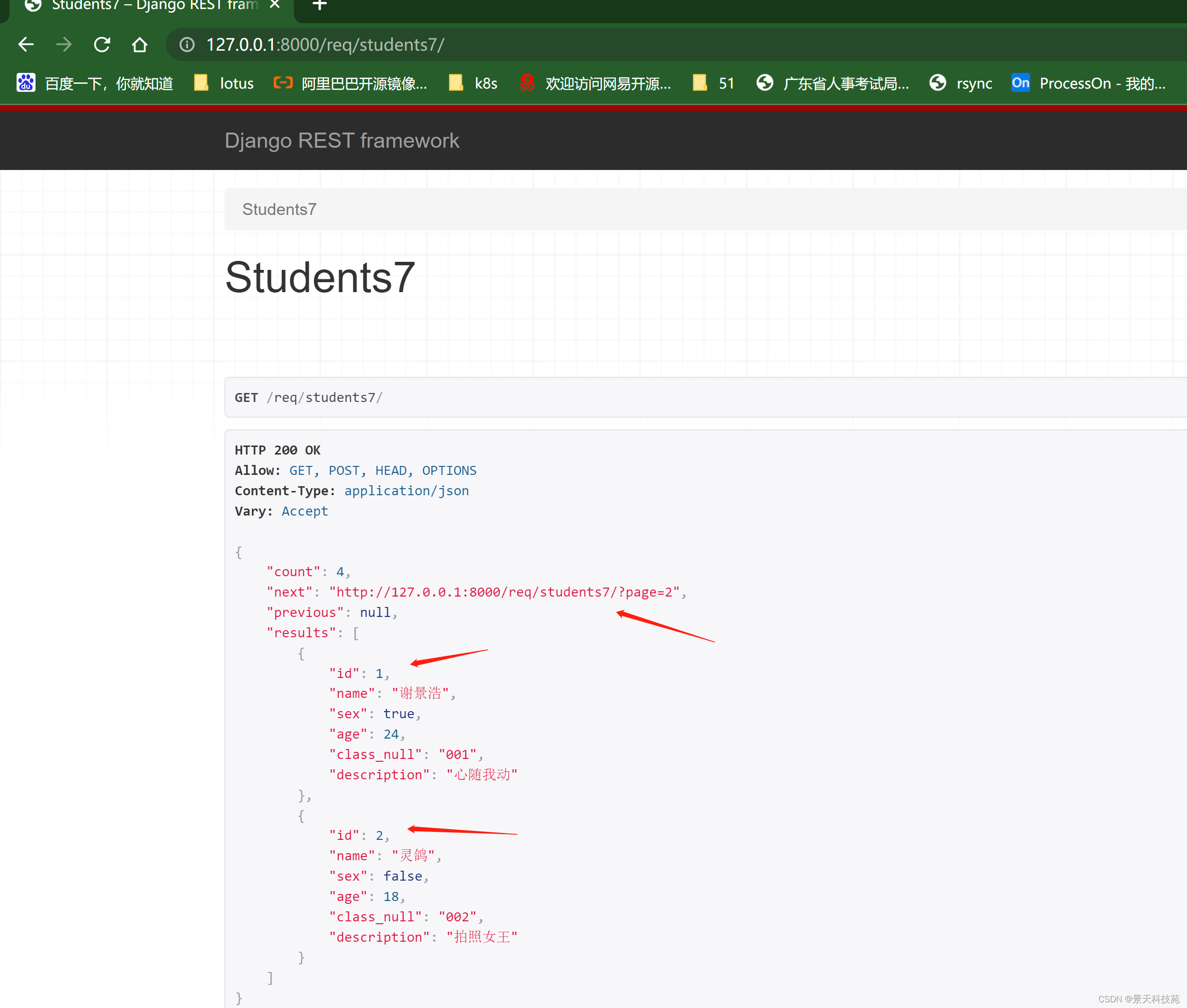
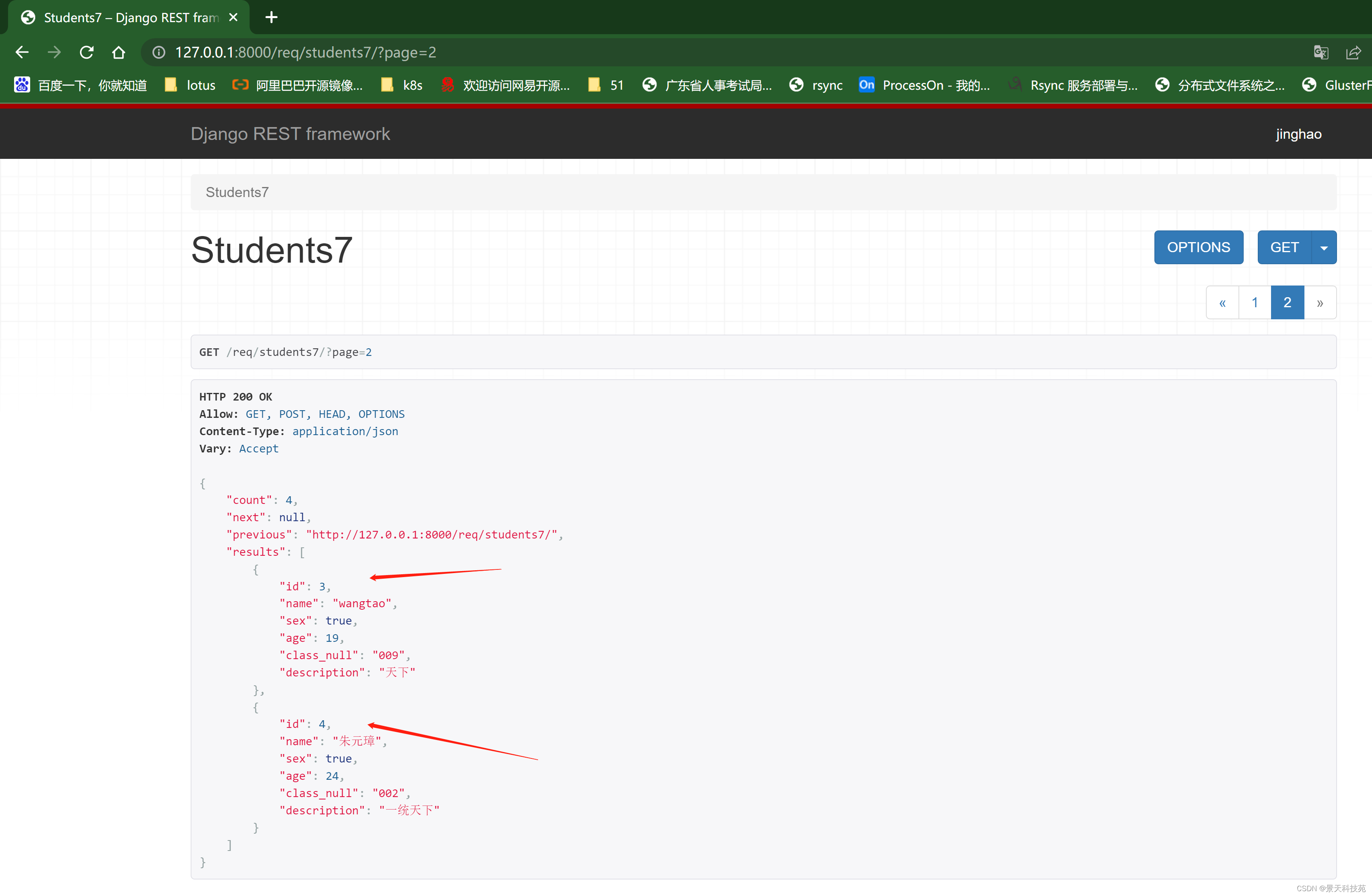
而且,上一页下一页链接都做好了,只能说牛逼
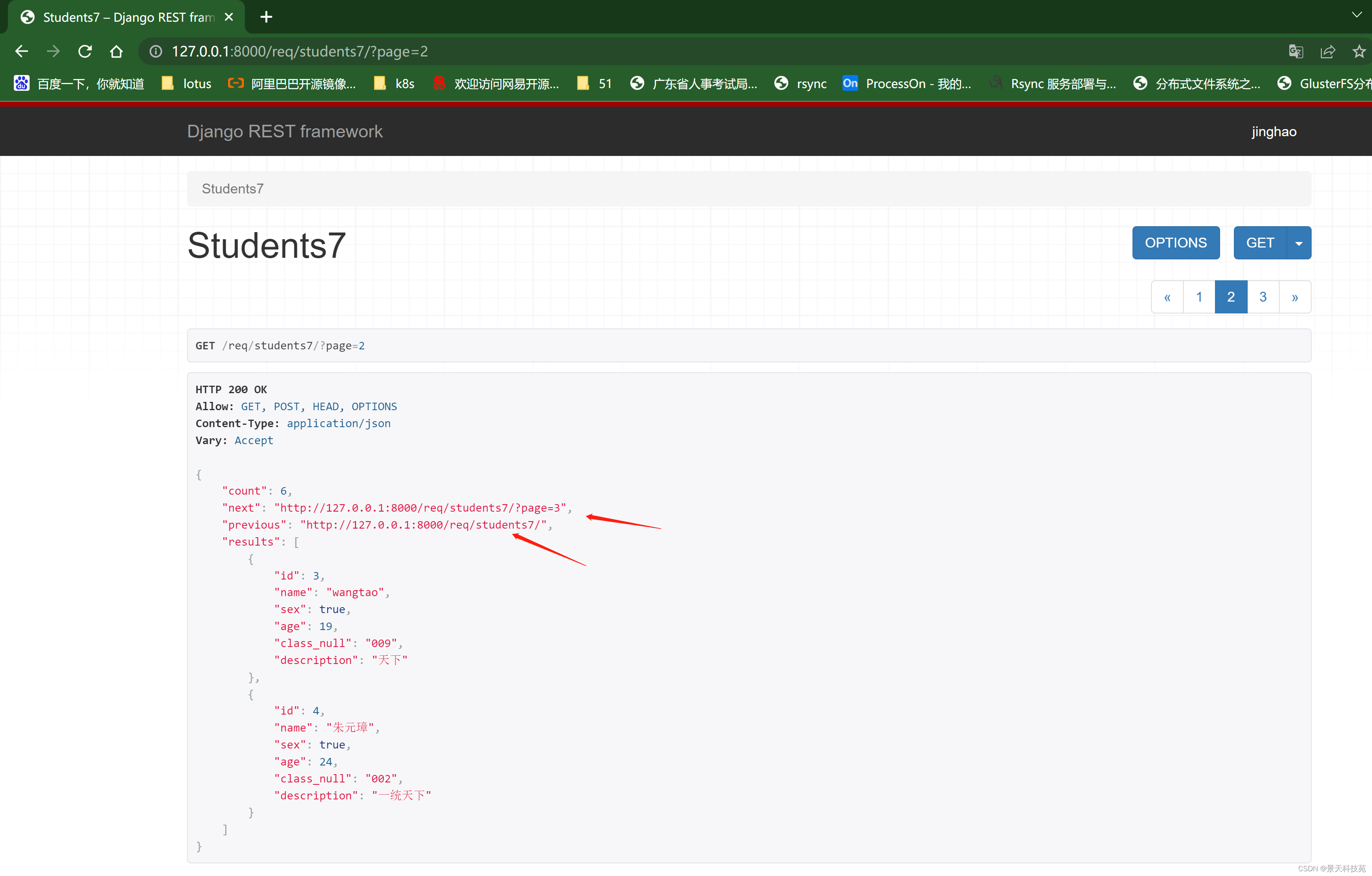
每个页面可能分页每页数量不一样,所以常用局部分页
自定义Pagination类,来为视图添加不同分页行为。在视图中通过pagination_class属性来指明。
class LargeResultsSetPagination(PageNumberPagination):
page_size = 1000
#127.0.0.1:8001/students/?page=5&page_size=10
page_size_query_param = 'page_size'
max_page_size = 10000
- 1
- 2
class BookDetailView(RetrieveAPIView):
queryset = BookInfo.objects.all()
serializer_class = BookInfoSerializer
pagination_class = LargeResultsSetPagination
# pagination_class = None
from rest_framework.pagination import PageNumberPagination
class LargeResultsSetPagination(PageNumberPagination):
page_size = 3 #每页显示多少条
# 127.0.0.1:8001/students/?page=5&page_size=10
page_size_query_param = 'page_size' #前端发送的每页数目关键字,前端可以跟聚这个参数来控制每页显示多少条
max_page_size = 10000 #前端最多能设置的每页最大数量,给前端设置个上限,不能无限大
- 1
- 2
比如,我们代码里写死了每页显示3条,但是前端可以通过url的page_size参数来控制每页显示多少条
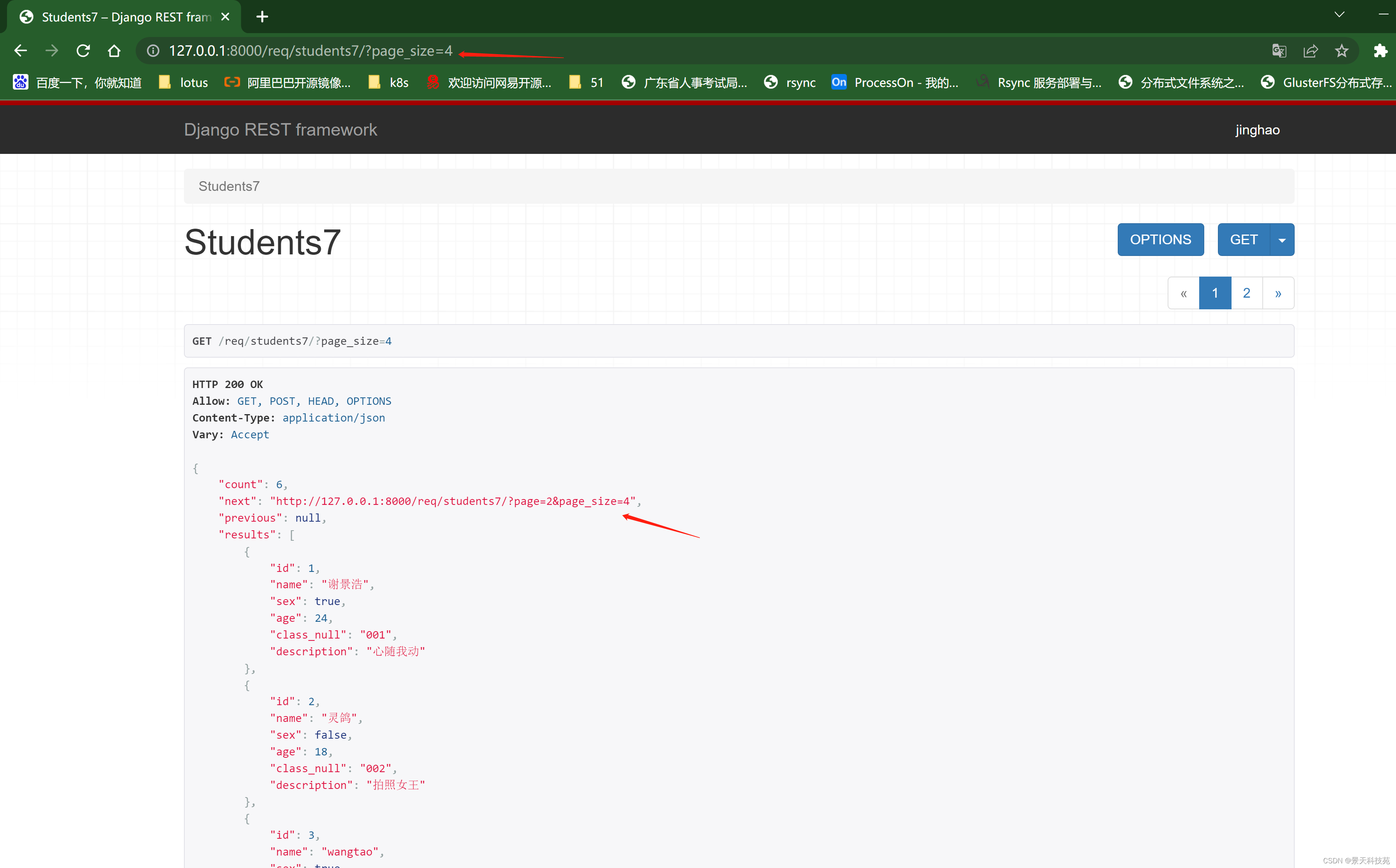
比如在全局里面设置了分页,如果在某个视图里面不想使用分页,添加如下参数
**注意:如果在视图内关闭分页功能,只需在视图内设置
pagination_class = None
可选分页器
1) PageNumberPagination 常用的就是这个
前端访问网址形式:
GET http://127.0.0.1:8000/students/?page=4
可以在子类中定义的属性:
- page_size 每页数目
- page_query_param 前端发送的页数关键字名,默认为"page"
- page_size_query_param 前端发送的每页数目关键字名,默认为None
- max_page_size 前端最多能设置的每页数量

2)LimitOffsetPagination(了解)
前端访问网址形式:#其实就是通过偏移量来取数据
GET http://127.0.0.1/four/students/?limit=100&offset=400 #从下标为400的记录开始,取100条记录
可以在子类中定义的属性:
- default_limit 默认限制,每页数据量大小,默认值与
PAGE_SIZE设置一致 - limit_query_param limit参数名,默认’limit’ , 可以通过这个参数来改名字
- offset_query_param offset参数名,默认’offset’ ,可以通过这个参数来改名字
- max_limit 最大limit限制,默认None, 无限制
MySQL的偏移量offset
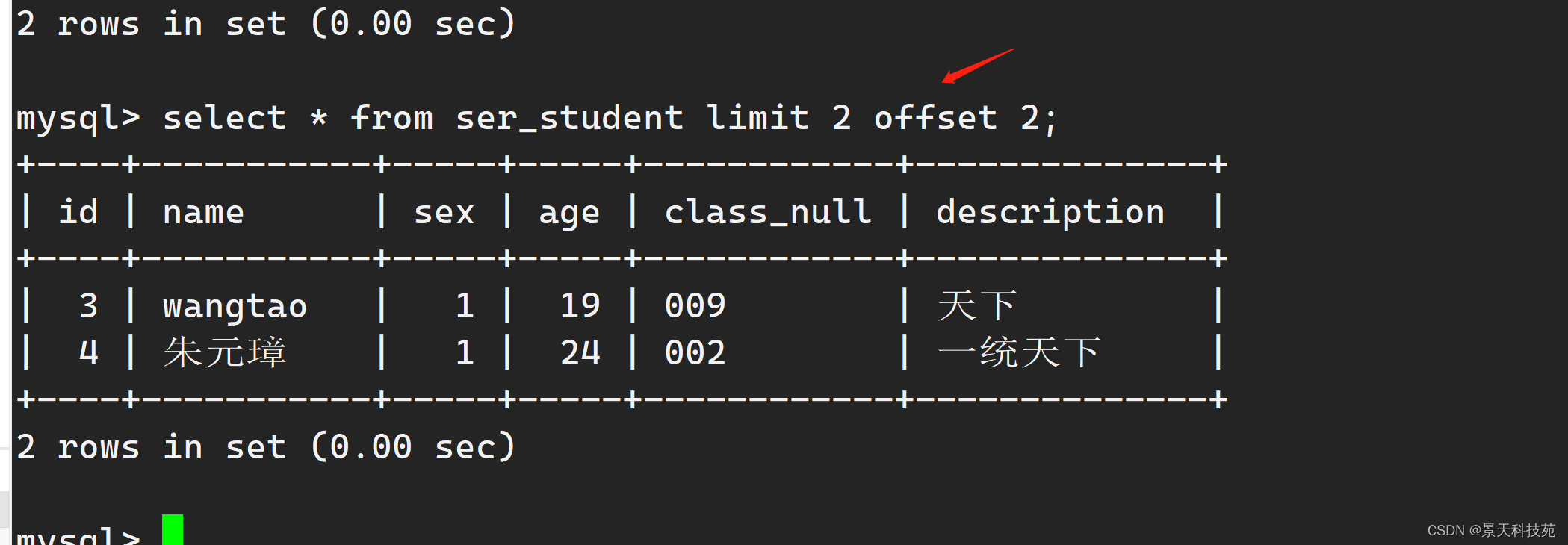
如果想查询前两条 sql语句后面加上limit 2
select * from ser_student limit 2;

如果想从第三条开始,查询后面的两条 再加上 offset 2
select * from ser_student limit 2 offset 2; 这句话的意思是从索引为2的记录开始,取2条
之前没有drf的时候,自己写分页就是通过offset偏移量来写
7.异常处理 Exceptions
我们不可能在所有的视图函数中都做try execpt 操作,这样做麻烦死了,所以我们使用DRF的异常处理类
REST framework提供了异常处理,我们可以自定义异常处理函数。
from rest_framework.views import exception_handler
我们看下原码,就是个函数
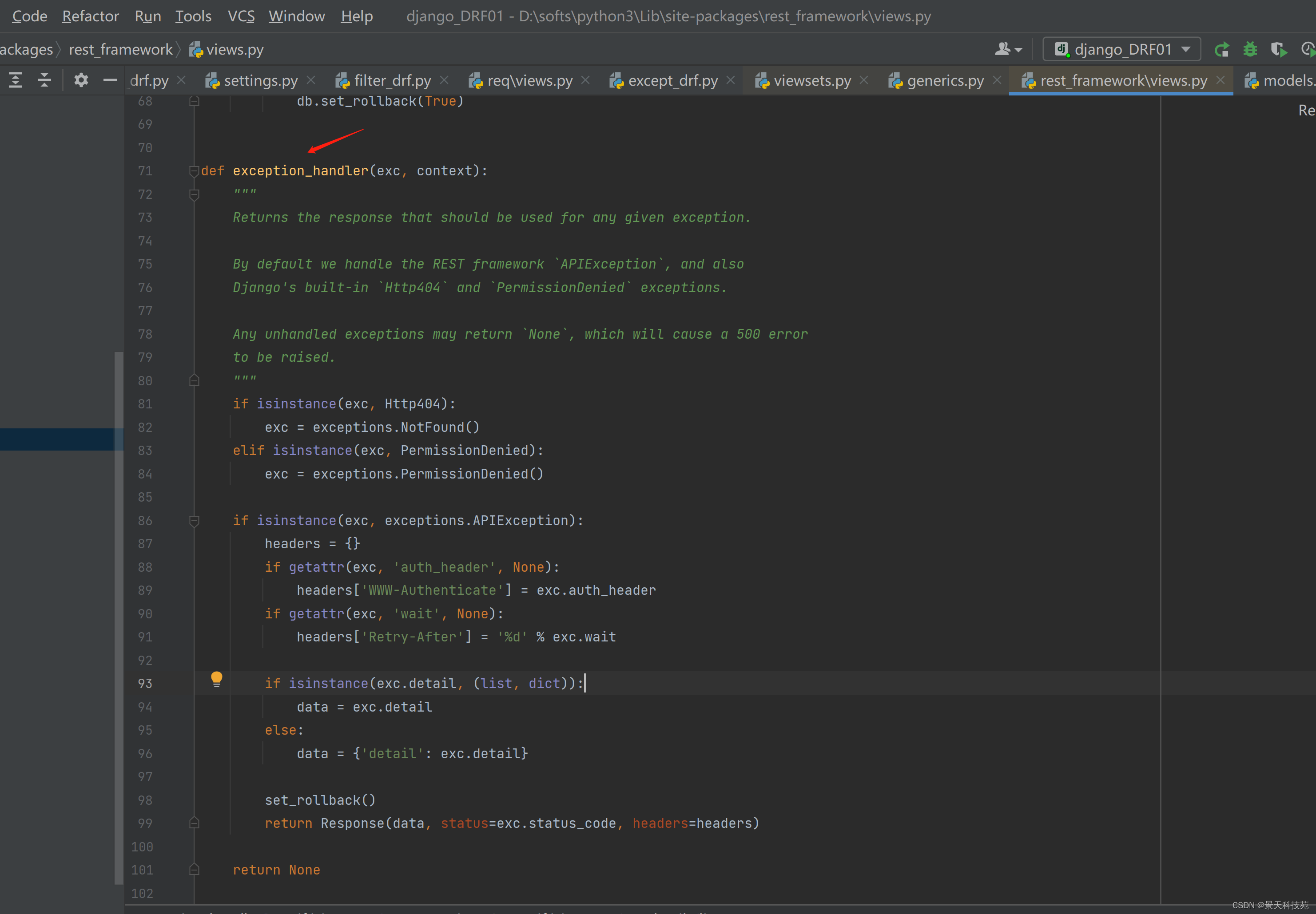
这个函数不能涵盖视图函数所有的错误,出现DRF捕获不到的异常,就返回None。如果程序内部错误没被捕获到,程序就崩了

因此,我们需要自己创建个异常捕获函数
首先,我们创建个类,模拟抛出异常
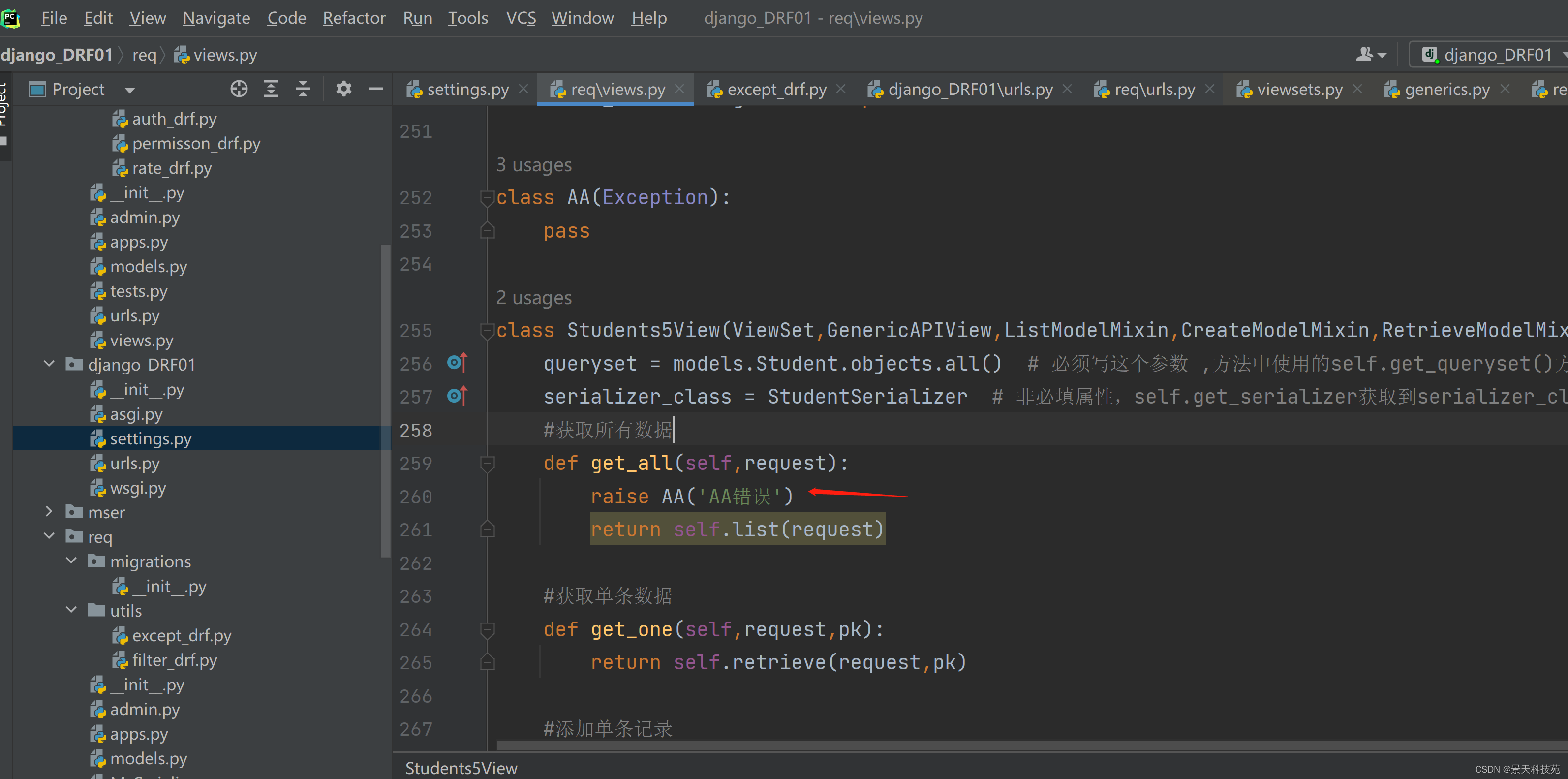
然后自定义异常捕获类
from rest_framework.views import exception_handler
from rest_framework.response import Response
from rest_framework import status
from req.views import AA
def myexecption(exc, context):
#先执行官方异常捕获函数,官方捕获异常捕获到,就返回错误信息,捕获不到就返回None
res = exception_handler(exc, context)
print('======>',exc, context)
#判断如果返回结果为None,有两种情况:1.程序没发生异常。2.程序发生异常了,官方的异常捕获没捕获到
if not res:
#判断异常类型,如果是AA错误,就返回页面告诉前端是AA错误类型,方便排查
if isinstance(exc,AA):
return Response({'error':'AA错误'},status=status.HTTP_500_INTERNAL_SERVER_ERROR)
else:
return None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在配置文件中还要声明自定义的异常处理
REST_FRAMEWORK = {
‘EXCEPTION_HANDLER’: ‘req.utils.except_drf.myexecption’,
}
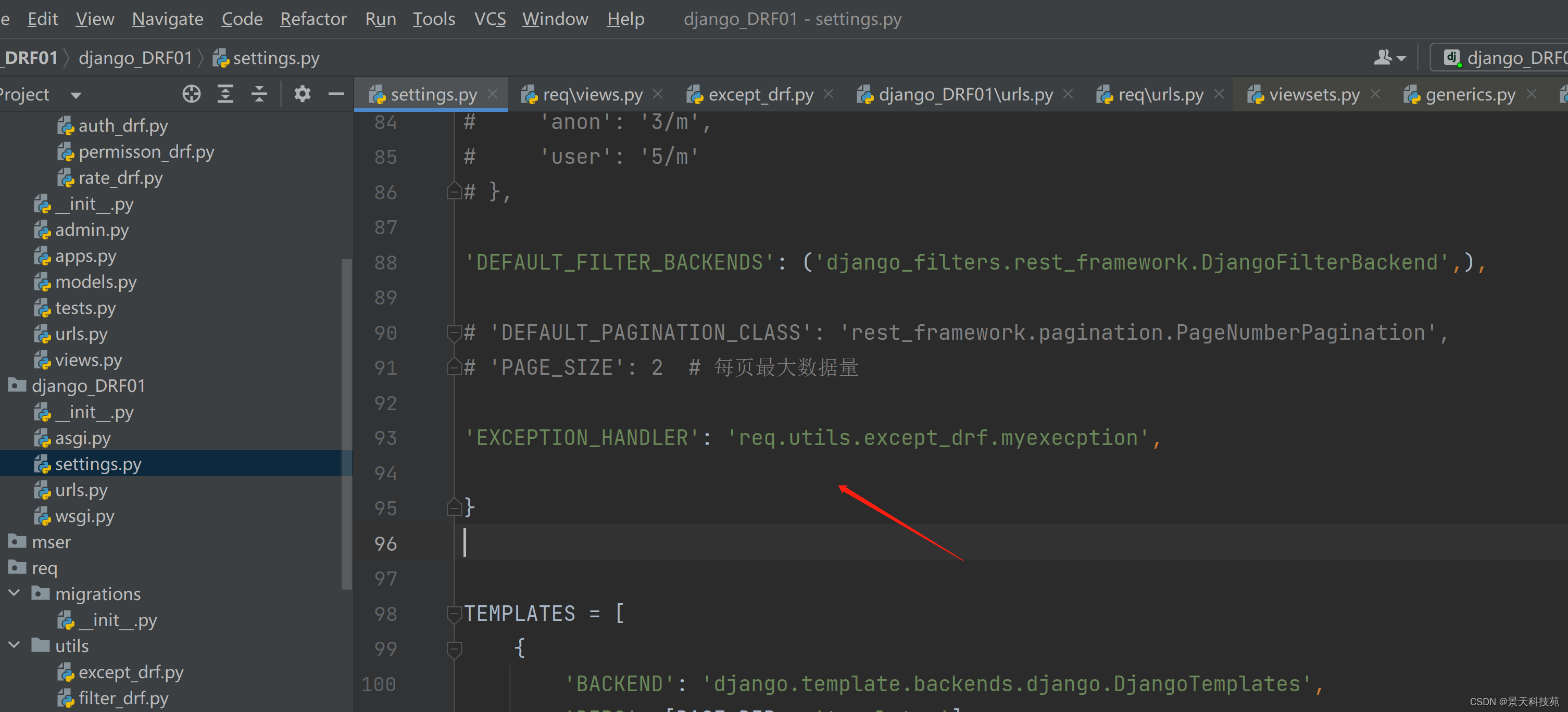
如果未声明,会采用默认的方式,如下
REST_FRAMEWORK = {
‘EXCEPTION_HANDLER’: ‘rest_framework.views.exception_handler’
}
请求:
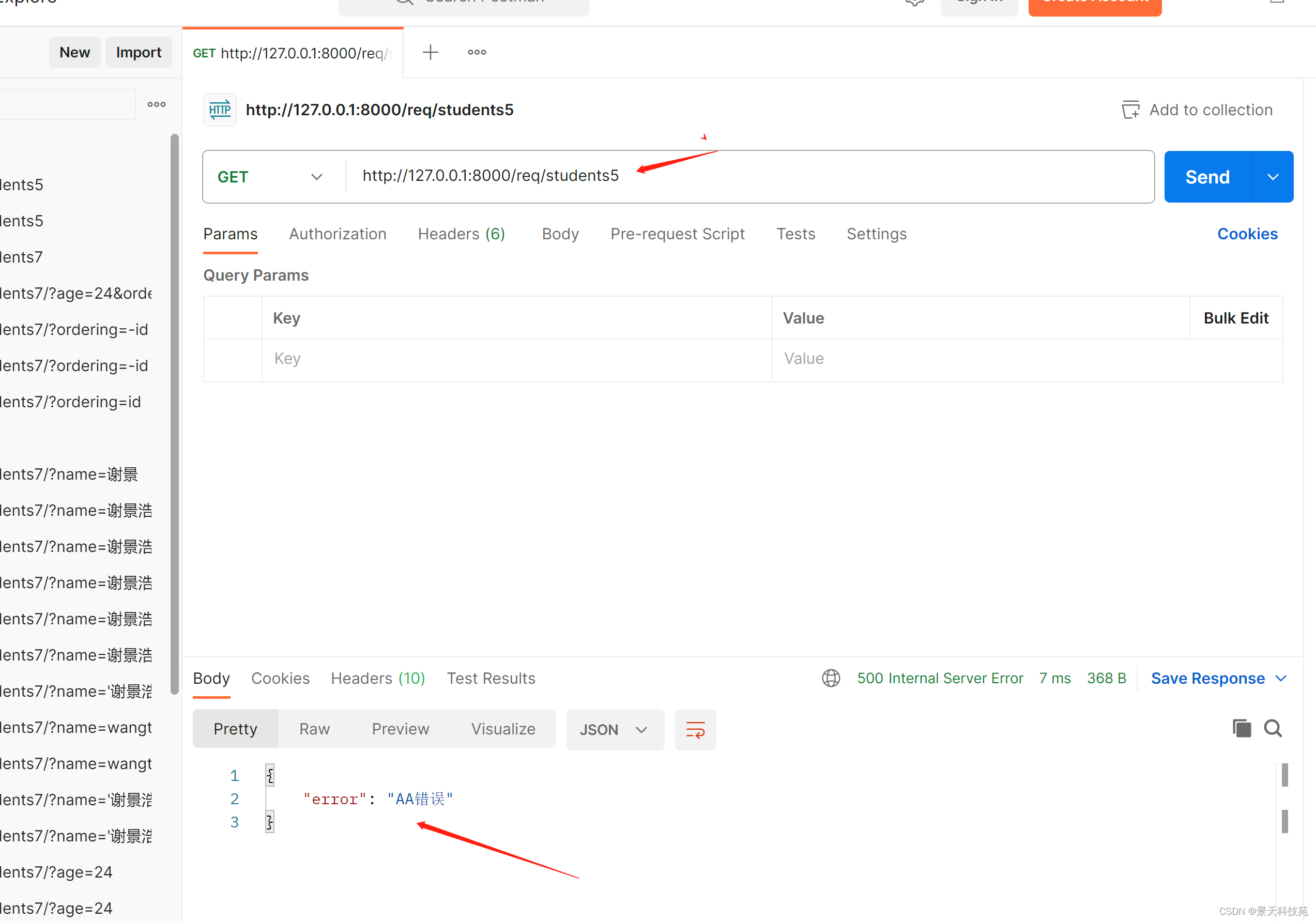
看下打印的异常信息
exec就是抛出的异常打印信息
context字典里面的 views 指向是哪个视图类 报的错

做日志的话,可以把错误通过日志记录起来
例如:
补充上处理关于数据库的异常
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework import status
from django.db import DatabaseError
def exception_handler(exc, context):
response = drf_exception_handler(exc, context)
if response is None:
view = context['view'] #出错的方法或者函数名称
if isinstance(exc, DatabaseError):
print('[%s]: %s' % (view, exc))
response = Response({'detail': '服务器内部错误'}, status=status.HTTP_507_INSUFFICIENT_STORAGE)
return response
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
REST framework定义的异常
- APIException 所有异常的父类
- ParseError 解析错误
- AuthenticationFailed 认证失败
- NotAuthenticated 尚未认证
- PermissionDenied 权限决绝
- NotFound 未找到
- MethodNotAllowed 请求方式不支持
- NotAcceptable 要获取的数据格式不支持
- Throttled 超过限流次数
- ValidationError 校验失败
也就是说,上面列出来的异常加粗部分不需要我们自行处理了,很多的没有在上面列出来的异常,就需要我们在自定义异常中自己处理了。
官方原码只帮我们处理了三种报错,其他的需要我们加进去自定义的函数中去
8.自动生成接口文档
写完接口后,一定要对接口功能进行描述,参数是什么,返回值是什么都要说清楚
有的公司以word,excel,或线上html形式来写
比如 聚宽 来测下交易策略行不行
接口文档

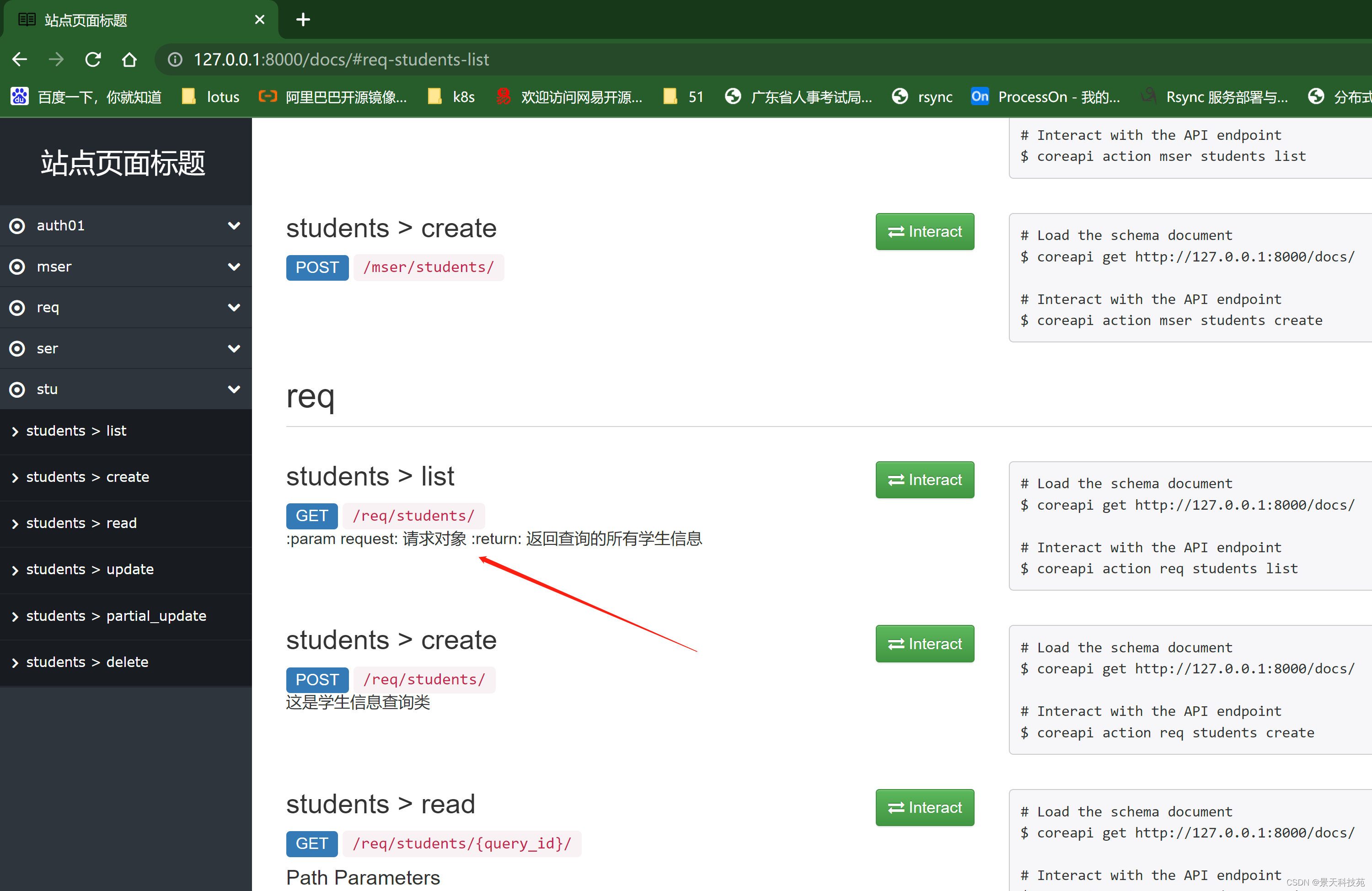
REST framework可以自动帮助我们生成接口文档。就是页面形式生成的接口文档
接口文档以网页的方式呈现。
自动接口文档能生成的是继承自APIView及其子类的视图。
https://www.kernel.org/doc/html/v4.12/core-api/index.html
安装依赖
REST framewrok生成接口文档需要coreapi库的支持。
pip install coreapi
设置接口文档访问路径
在总路由中添加接口文档路径。
文档路由对应的视图配置为rest_framework.documentation.include_docs_urls,
参数title为接口文档网站的标题。
from rest_framework.documentation import include_docs_urls
urlpatterns = [
…
path(‘docs/’, include_docs_urls(title=‘站点页面标题’))
]
总路由里面配置如下:

如果报下面的错,解决办法
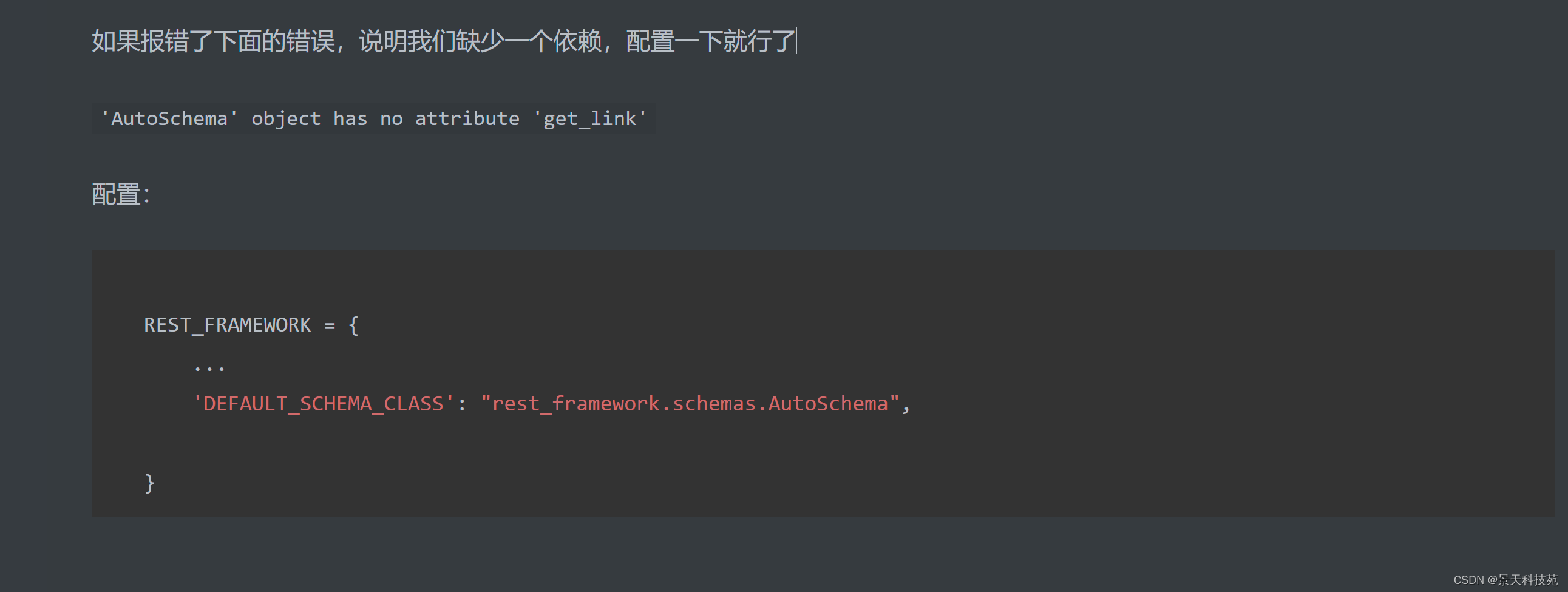
然后在DRF里面加上如下配置:
REST_FRAMEWORK = {
…
‘DEFAULT_SCHEMA_CLASS’: “rest_framework.schemas.AutoSchema”,
}
访问接口文档:
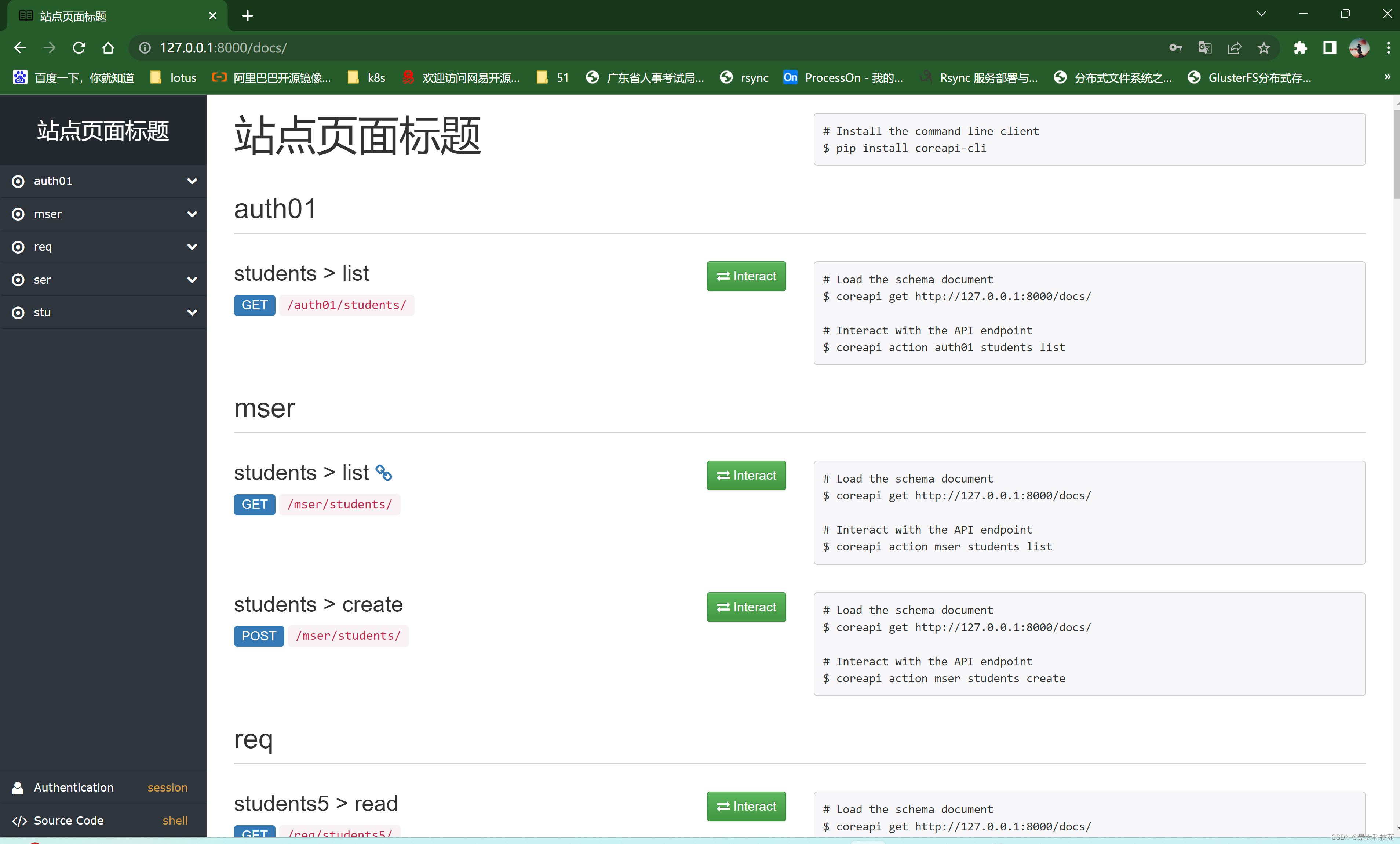
请求方法自动都做好了,参数需要自己写
文档描述说明的定义位置
1) 单一方法的视图,可直接使用类视图的文档字符串,如
class BookListView(generics.ListAPIView):
“”"
get: 返回所有图书信息.
post: 添加记录
“”"
#注意,这是在类中声明的注释,如果在方法中你声明了其他注释,会覆盖这个注释的
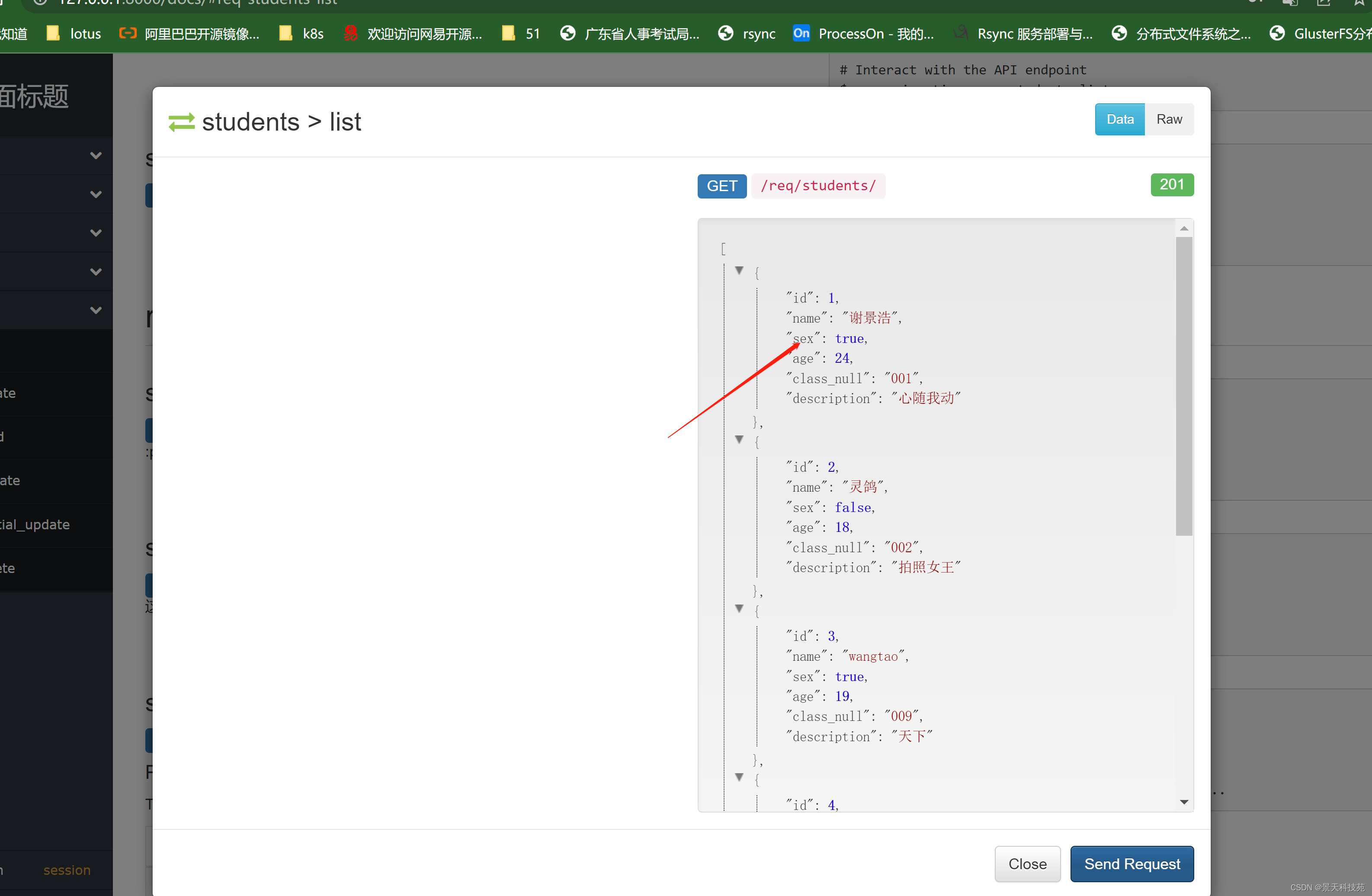
还可以交互验证接口是否正常

2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如
class BookListCreateView(generics.ListCreateAPIView):
“”"
get:
返回所有图书信息.
post:
新建图书.
"""
- 1
- 2
- 3
3)对于视图集ViewSet,仍在类视图的文档字符串中封开定义,但是应使用action名称区分,如
“”"
list:
返回图书列表数据
retrieve:
返回图书详情数据
latest:
返回最新的图书数据
read:
修改图书的阅读量
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
两点说明:
1) 视图集ViewSet中的retrieve名称,在接口文档网站中叫做read
2)参数的Description需要在模型类或序列化器类的字段中以help_text选项定义,如:
class Student(models.Model):
…
age = models.IntegerField(default=0, verbose_name=‘年龄’, help_text=‘年龄’)
…
或注意,如果你多个应用使用同一个序列化器,可能会导致help_text的内容显示有些问题
class StudentSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
extra_kwargs = {
'age': {
'required': True,
'help_text': '年龄'
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10


