
- 1【阿里淘天笔试题汇总】2024-04-03-阿里淘天春招笔试题(第一套)-三语言题解(CPP/Python/Java)
- 2Oracle exists 和 in 区别_exists和in的区别
- 3【java】反射
- 4Mac上Maven的安装和环境变量配置保姆级教程(最新版实时更新)
- 5watermark java_GitHub - k-ff/BlindWatermark: Java 盲水印
- 6字节跳动面试流程以及注意事项,各大厂具有通点,软测工程师面试时要注意了_测试工程师需要刷题吗
- 7使用Python进行数据分析——线性回归分析_进行样本数据集的线性回归模型分析代码python
- 8大模型模型结构总结
- 9SQL与NoSQL的区别 以MySQL与MongoDB为例_mysql、nosql mongodb
- 10软考132-上午题-【软件工程】-沟通路径
【Linux】地址空间&&虚拟地址
赞
踩
个人主页 : zxctscl
如有转载请先通知
1. 虚拟地址
1.1 虚拟地址引入
先先来一个测试代码:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<string.h> 4 #include<stdlib.h> 5 6 int g_val=100; 7 8 int main() 9 { 10 printf("father is running,pid:%d,ppid:%d\n",getpid(),getppid()); 11 12 13 pid_t id=fork(); 14 if(id==0) 15 { 16 int cnt=0; 17 while(1) 18 { 19 printf("I am child process,pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val); 20 sleep(1); 21 cnt++; 22 if(cnt==5) 23 { 24 g_val=300; 25 printf("I am child process,change %d->%d\n",100,300); 26 } 27 } 28 } 29 else{ 30 while(1) 31 { 32 printf("I am father process,pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val); 33 sleep(1); 34 } 35 36 } 37 } 38

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
编译运行:
子进程把数据改了,父进程的数据没有改变,但是父子地址是一样的。
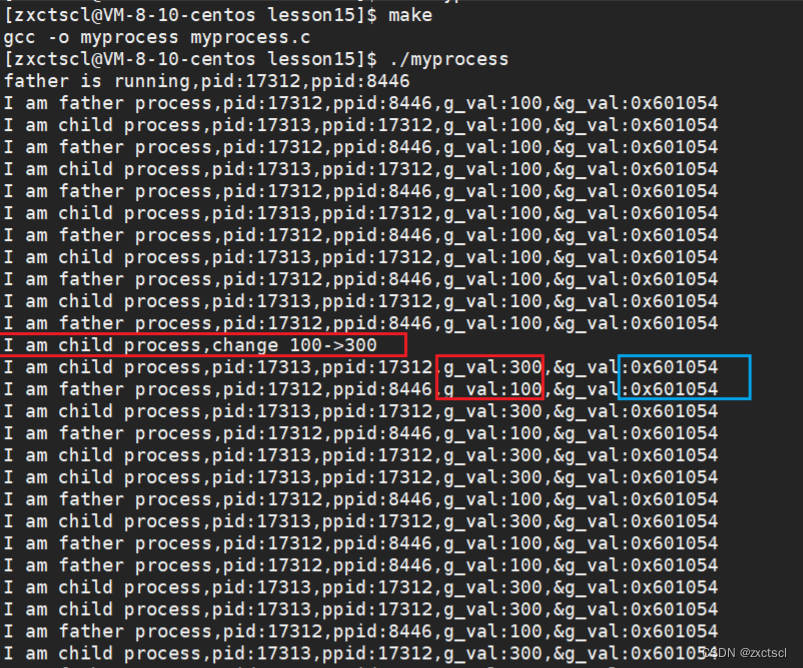
这个地址绝对不是物理地址,理论上修改了数据为300之后不可能在输出有100,访问一个地址怎么可能又是100也是300。这个地址在系统层面上称之为虚拟地址。
1.2 虚拟地址理解
每一个进程除了要把代码和数据加载到内存之外,对于当前的操作系统来讲,系统当中会为每一个进程创建一个地址空间。
地址空间在操作系统里面。在32位和64位下的地址空间大小是不一样的,为了方便这里使用32位来表述。32位从低到高一个有4GB的地址空间范围,实际上这个地址空间当中打印出来的地址,是该空间内对应的地址。进程是可以指向这个地址空间的。
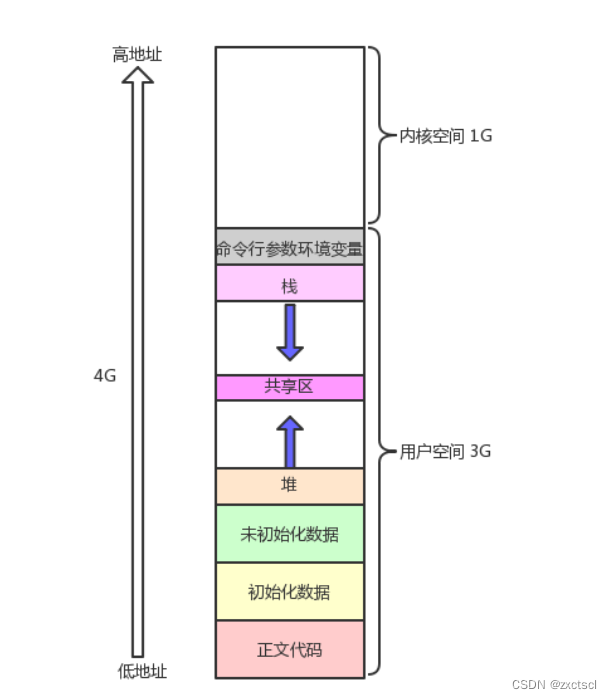
其实PCB和地址空间都是在物理内存里面的,只不过要访问初始化全局数据的时候,不在地址空间上保存,地址空间只会提供线性连续地址,让用户之后通过虚拟地址的地址空间,将虚拟地址转化到为了物理内存中。
此时计算机的体系结构中还存在一个页表,页表它的主要功能是负责将地址空间中的虚拟地址和物理地址之间建立映射关系。未来在用进程进行访问的时候,操作系统会自动用虚拟地址查页表转换为物理地址,然后让用户访问到数据。
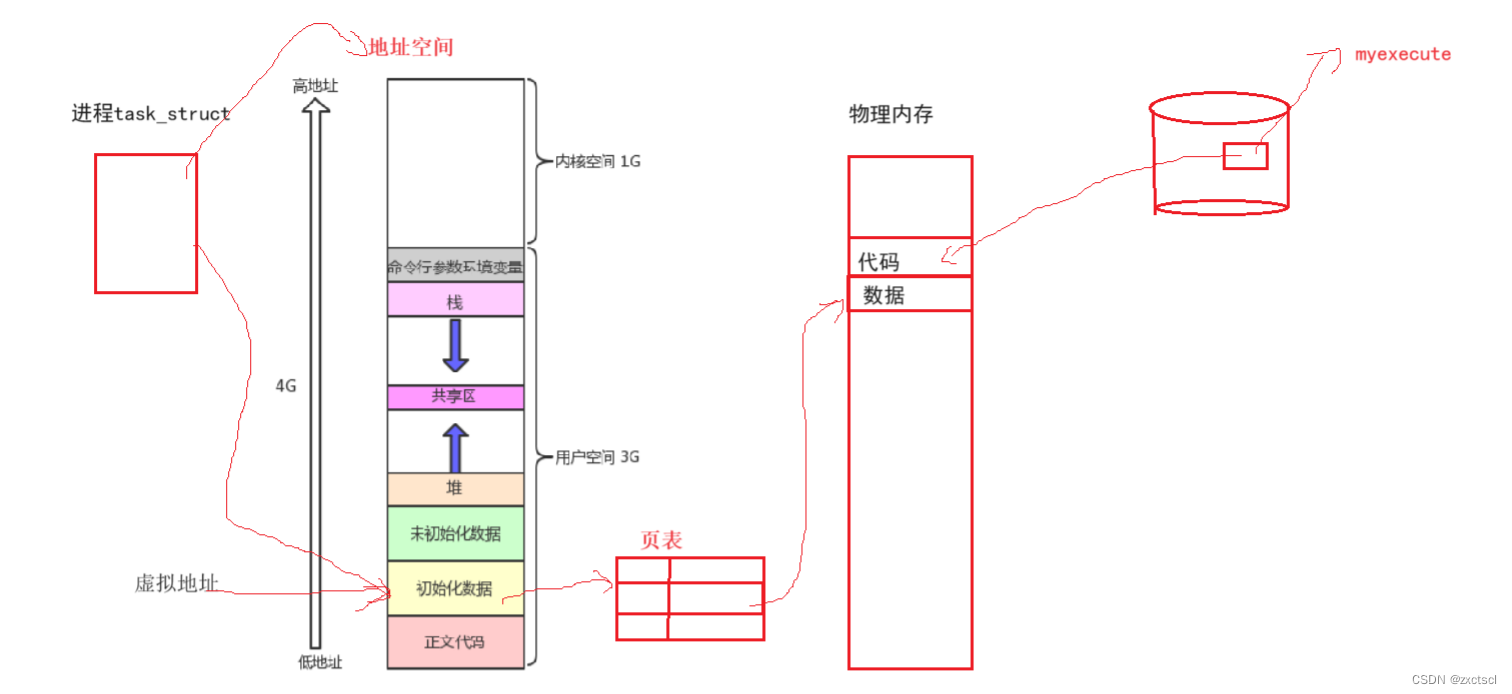
父进程的代码可以通过页表地址映射转换到为了内存中代码,父进程通过连续的地址空间就可以访问到它的代码和数据。

假设在物理内存上存放一个全局变量g_val,默认内容是100,g_val在页表在地址空间中都要被找到,所以在地址空间的初始化数据中就有它的地址虚拟地址,页表的左侧也有它的虚拟地址,在页表右侧就有它对应的物理地址。
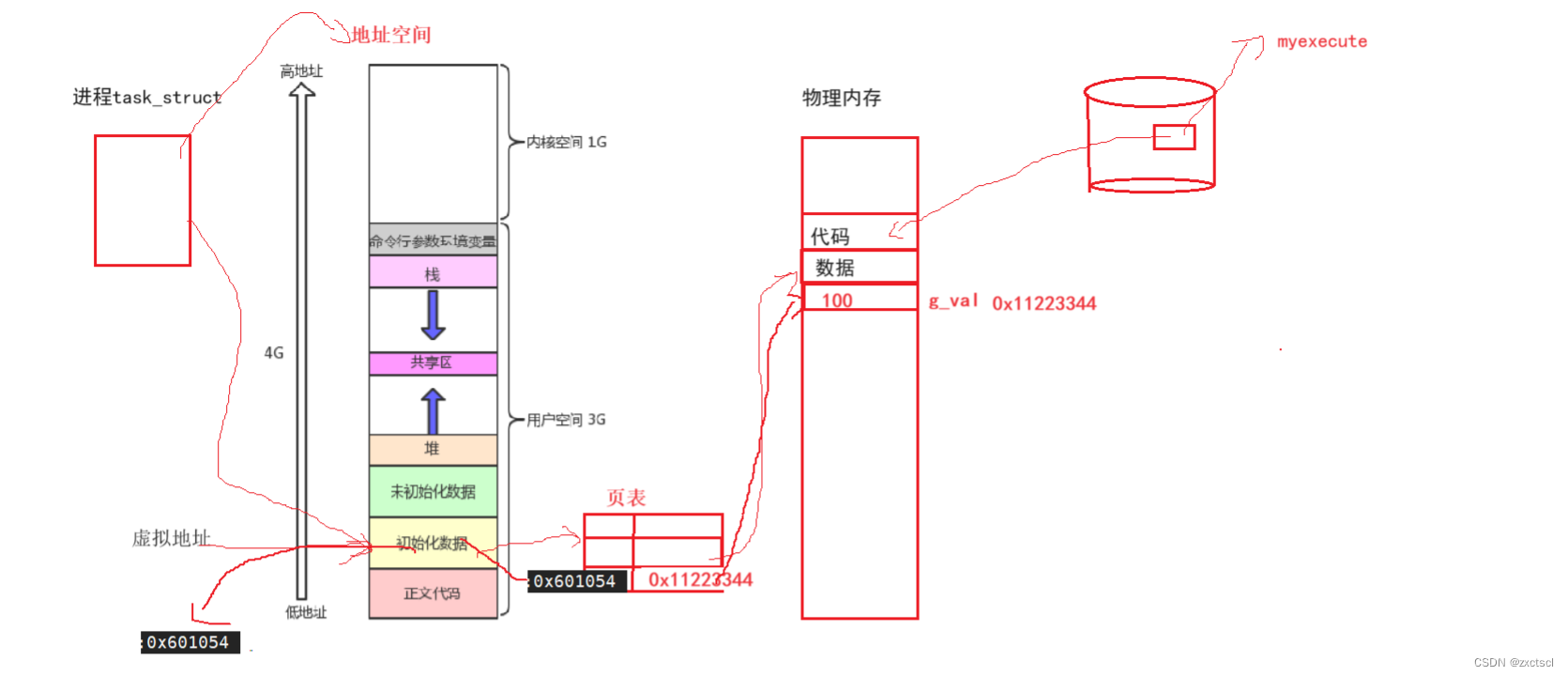
当创建了一个子进程,本质上是系统多了一个进程,它也有自己的task_truct,还有自己的虚拟地址空间,还有它所对应的页表。
每个进程都要有自己的虚拟的地址空间,也要有自己对应的页表。
每个进程都要有自己独立的地址空间,那么操作系统就得管理很多个进程的地址空间,而地址空间本质上就是内核中的一个数据结构对象。
子进程会把父进程的很多数据结构全拷贝一份,基本上子进程的PCB、地址空间和页表基本上和父进程的一致。
子进程的地址空间也会有一个虚拟地址,子进程对应的页表也来自父进程,所以页表保存的地址,从而子进程也会指向那个g_val。
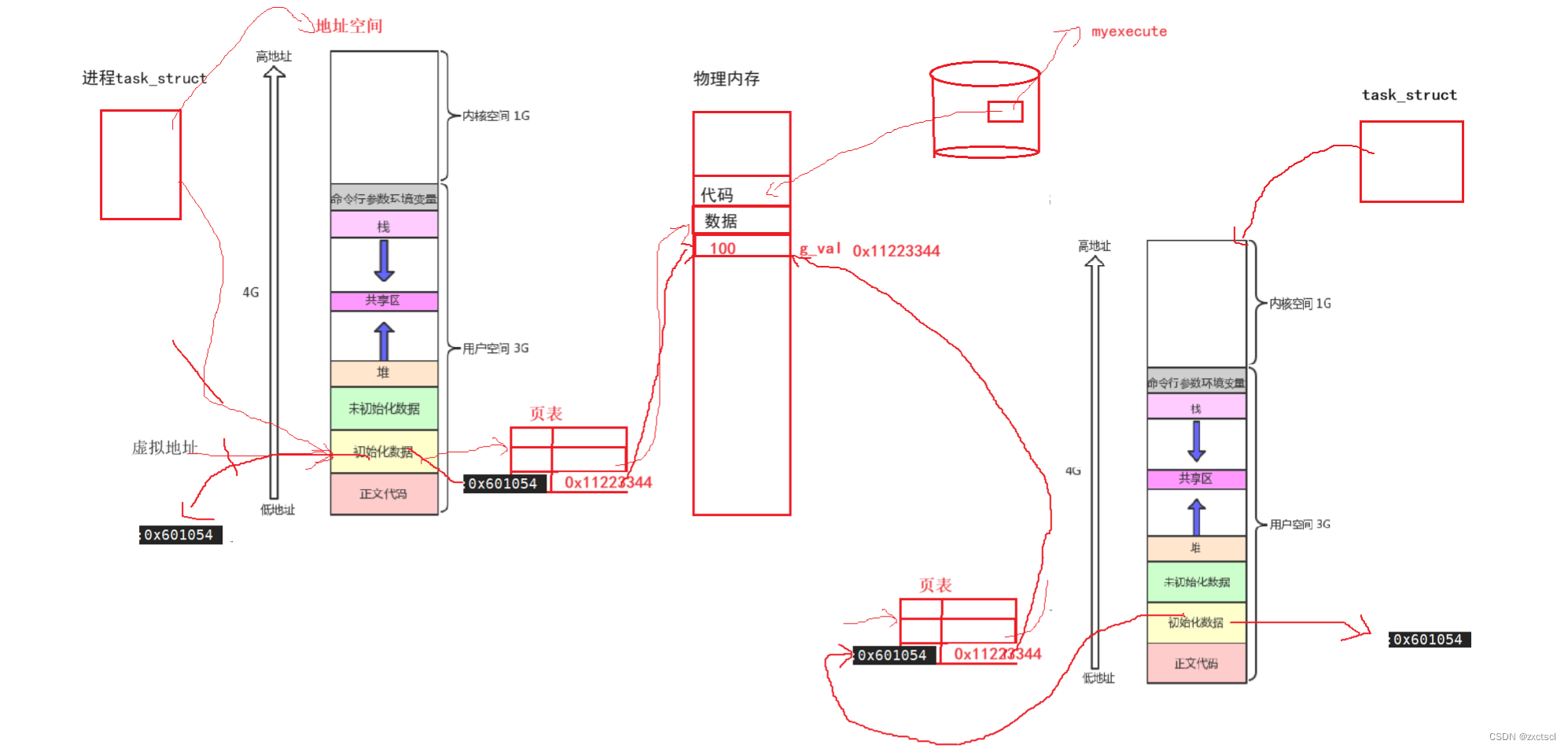
所以子进程和父进程看到的虚拟地址是一样的,并且它们的页表也一样,指向的物理内存也一样,所以它们打印出来的地址也就是相同的了。
如果子进程进行写入,也是通过页表向物理内存处进行写入,写入的时候直接找到g_val把100改为300。可子进程一旦对数据做修改了,父进程就会看到。如果子进程直接修改了数据,就会导致程序运行本身问题。
而进程本身在运行的时候具有独立性,所以子进程对数据进行修改,就不能影响到父进程,所以当子进程尝试对数据进行修改时,操作系统发现父进程也有,就在在子进程修改之前,在物理内存中出现开辟一个空间,开辟完成之后。然后把修改之前的数据拷贝到新空间中,再把新的物理地址和之前的物理地址相比较,把新的物理地址放在子进程的页表中,重新构建映射,页表的右侧就指向新的物理地址空间,这个工作结束,才会就行让子进程执行写入操作,把100改为300。
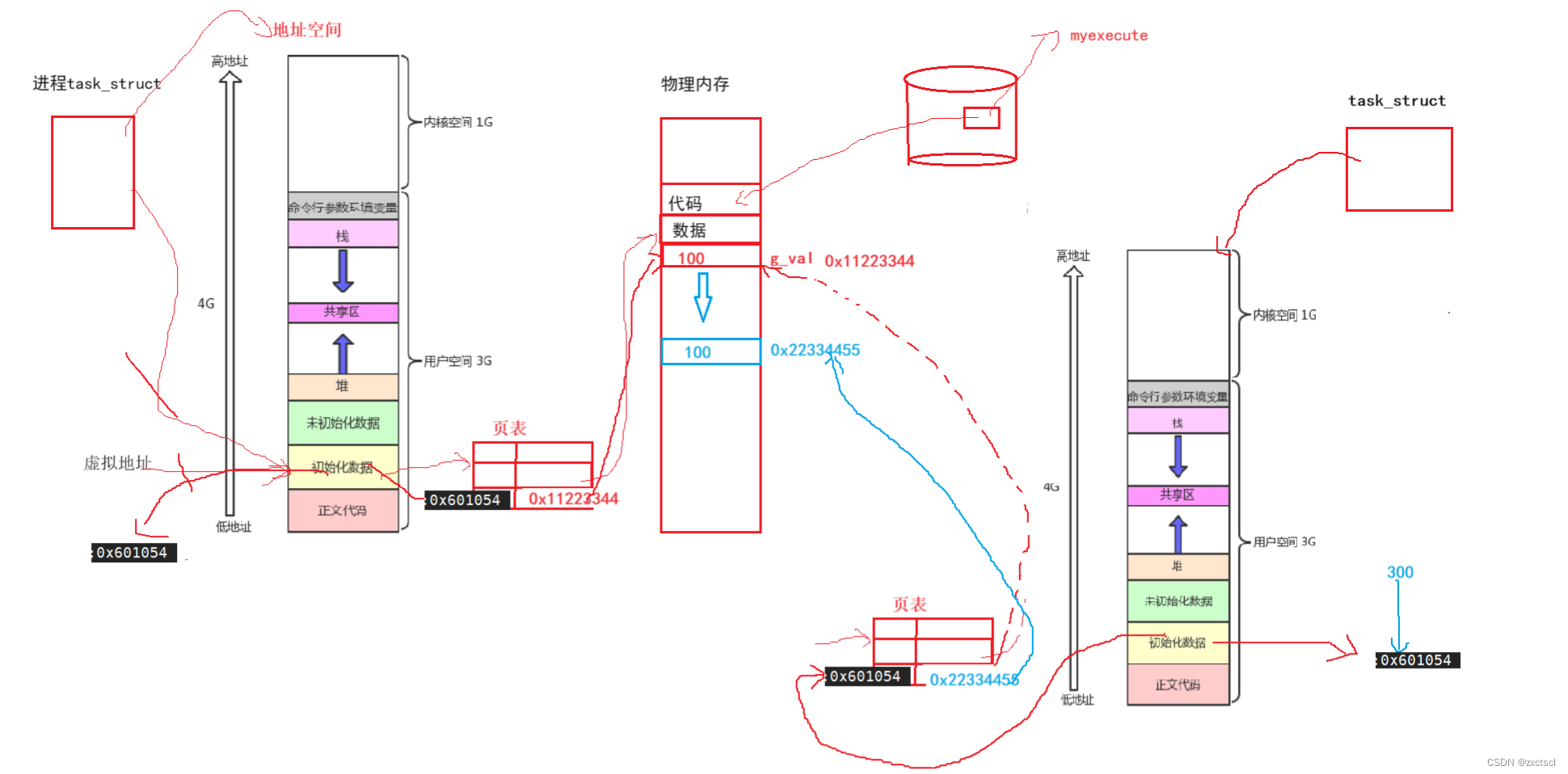
重新开辟物理内存这些都是操作系统自己做,上面这个过程叫做写时拷贝。
修改的只是子进程的物理地址和页表,而地址空间里面的依然是虚拟地址。子进程和父进程的虚拟地址是一样的,只是映射到物理内存到不同区域,所以对应看到的地址是一样的,但内容却不一样。
1.3 虚拟地址细节问题
如果父子进程不写,未来一个全局变量,默认是被父子共享的,代码(只读)是共享的。
为什么会存在写时拷贝?
因为进程具有独立性,所以父子进程有自己的地址空间和页表。
但是代码是共享的,那么怎么不在创建子进程的时候,全部给子进程拷贝一份?
主要是在父进程中的数据子进程不一定都会修改,而这些占据的空间又很大,子进程程序拷贝一份就是在浪费空间,所以采用写时拷贝,就是为了按需申请。必须写时才能拷贝是为了保证进程的独立性。
按需申请本质是通过调整拷贝时间顺序,达到有效节省空间的目的。
2. 地址空间
2.1 理解地址空间
地址空间本质是内核的一个struct结构体,结构体里面有各种各样的区域划分,内部有很多的属性都是表示start,end的范围。
来看看源码里面描写这个结构体:
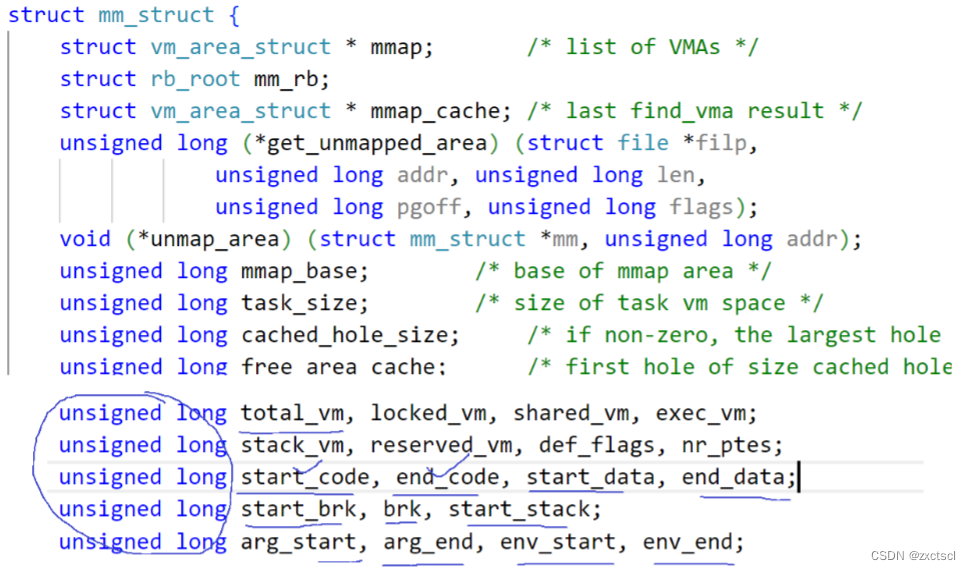
并不是限定了某一个范围,而是这个范围之间它所对应地址空间都可以使用。这个范围可以根据页表映射到物理内存。
操作系统给每一个进程都划分一块进程地址空间。

为什么要有地址空间?
一个程序的代码和数据放在物理内存中,如果没有虚拟地址空间,要直接找到程序的代码和数据,就必须让进程的PCB把对应的代码和数据都记录下来。如果当前还有其他程序,都在物理内存中,每一个程序都在物理内存中加载的话,也就要求每一个进程所对应的代码和数据在物理内存的哪一个位置都得记录下来。这个记录对应进程而言负担是比较大的,也就是进程直接使用物理地址。
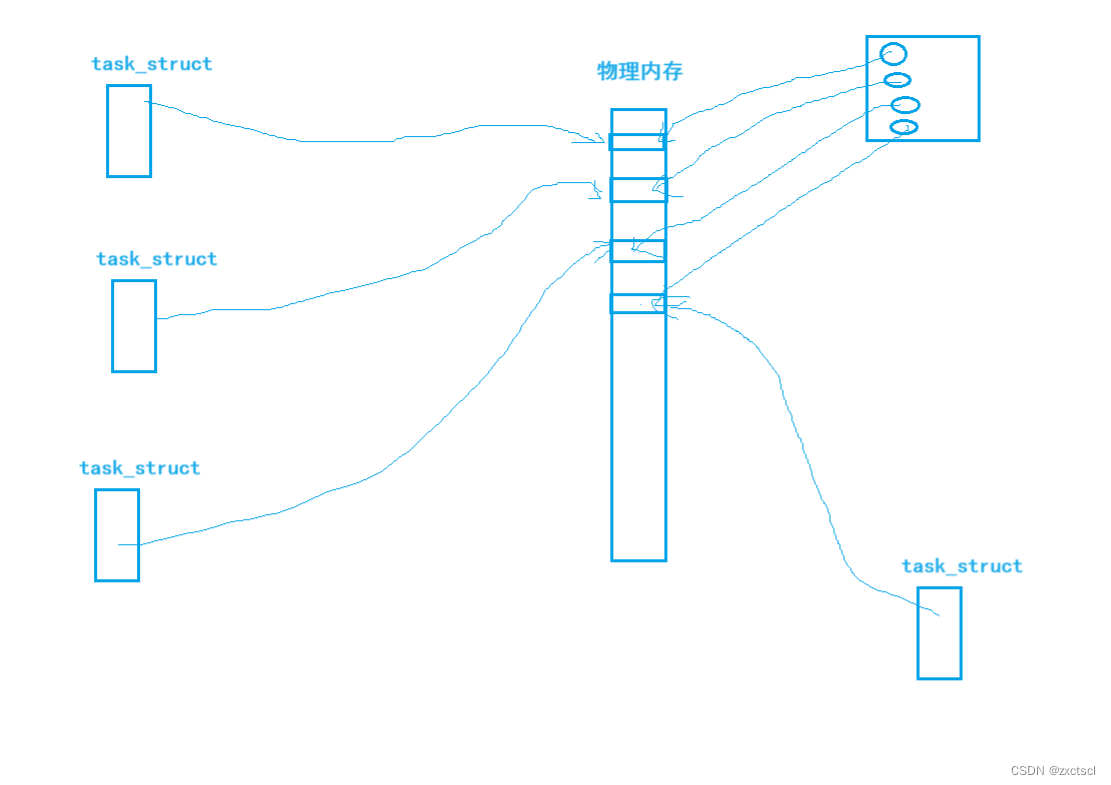
就有可能出现访问越界,或者访问到其他进程的代码和数据。所以用进程记录物理地址就比较混乱,不利于做统一管理。
实际物理内存中的代码区,数据区、堆区、栈区、共享区、命令行参数和环境变量,对一个进程来讲可能是乱序的,那么再加载其他进程也是乱序的。
进程在申请内存时,在地址空间上能申请就可以,在页表对应的左侧就可以了,右侧可以先不填,当用户真正用到的时候在申请。
地址空间和也表存在的好处就是:一、将无序变有序,让进程以统一的视角来看待物理内存以及自己运行的各个区域。
二、进程管理模块和内存管理模块进行解耦
地址空间并不是百分百使用的,一般只使用一部分。比如在堆区,申请了五十个字节,可是遍历的时候计数器越界了,在地址空间里面就越界了,操作系统就直接拦截了这个请求,所有的非法请求都不能通过地址空间到物理内存上,也就是保护物理内存。
拦截非法请求就是对物理内存进行保护。
2.2 页表和写时拷贝
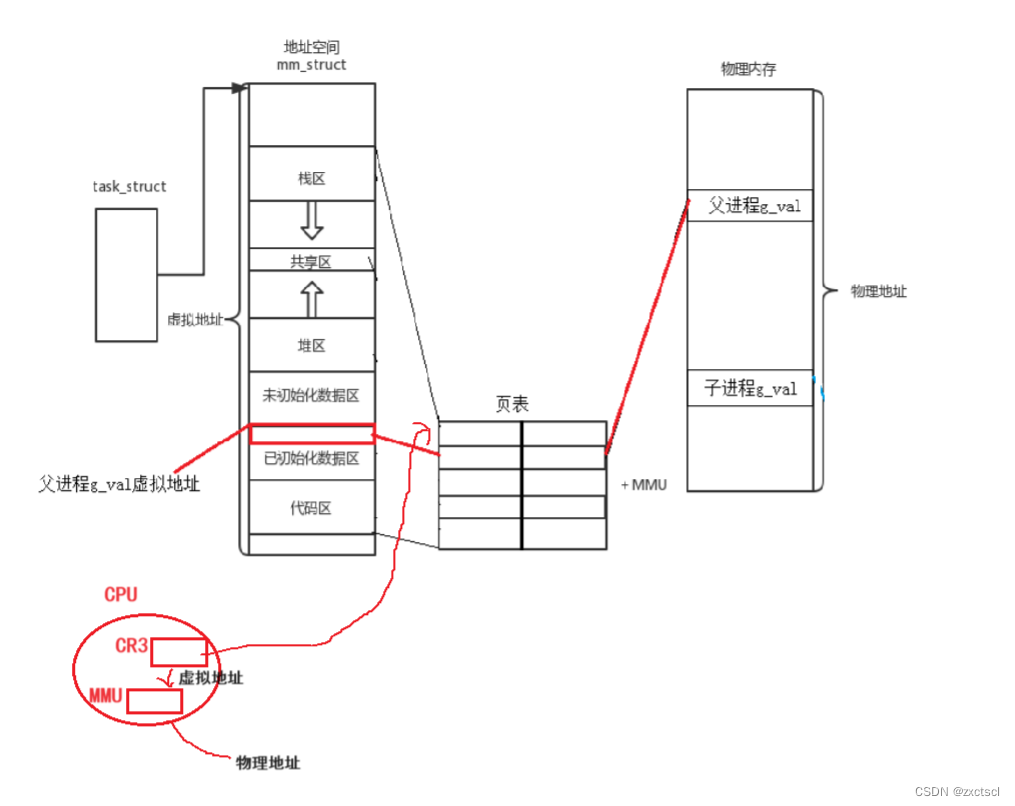
查页表对内存地址进行访问是CPU,它里面包含CR3寄存器内,CPU的还有有一个叫做MMU硬件(内存管理单元),快速把虚拟地址结合页表转化为物理地址。
页表里面的一些选项来支持权限管理。就像是C语言中不能修改字符常量区,是因为页表里面没有给修改的权限。

操作系统支持写时拷贝,页表给父进程的权限是rw。当父进程创建子进程之后,子进程的页表权限是r。当父进程一旦创建子进程,父进程为了支持写时拷贝,因为父进程走到已初始化全局区本来就是可以写的,但创建子进程之后,操作系统会直接修改页表中该位置的权限,都修改为r。当父子进程中任何一个尝试写入时,此时系统就会直接识别到错误。
操作系统识别到错误就得判断:1.是不是数据不在物理内存;2.是不是数据想要写时拷贝;3.如果都不是,才能进行异常处理。
第一种解决就是缺页中断,第二种就发生写时拷贝。
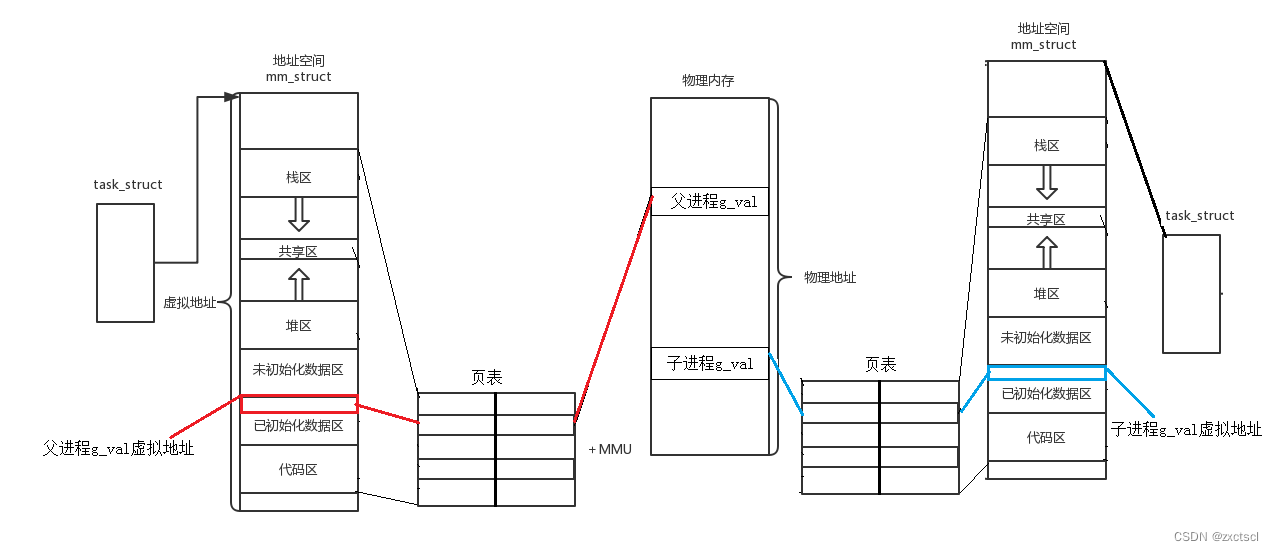
上面的图就足矣说名问题,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!

在最开始的时候,地址空间的页表里面的数据从哪里来?
程序一旦加载到内存就有地址。程序在变成二进制的时候本身就有地址。也就是说程序里面本身就有地址。

来看一下之前的代码:
1 #include<stdio.h> 2 #include<unistd.h> 3 #include<string.h> 4 #include<stdlib.h> 5 6 7 int main() 8 { 9 pid_t id=fork(); 10 if(id==0) 11 { 12 while(1) 13 { 14 printf("child,%d,%p\n",id,&id); 15 sleep(1); 16 } 17 } 18 else if(id>0) 19 { 20 while(1) 21 { 22 printf("father,%d,%p\n",id,&id); 23 sleep(1); 24 } 25 } 26 return 0; 27 } 28
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
当fork()时候,不管是父进程还是子进程,都要return。在return时候,本质就是对id进行写入,而id本身是父进程定义的变量,不论是父进程还是子进程,谁先return,都得return两次,进程在return的时候,发生写时拷贝。所以当父进程用id的时候,它认为id大于0;子进程在返回的时候它认为id等于0。所以虚拟地址相同而物理地址不同。
3. 进程调度
Linux中的nice值并不是能任意调度的,而是从-20到19,这40个数字之间变换。
在操作系统中每一个CPU都会有一个运行队列:
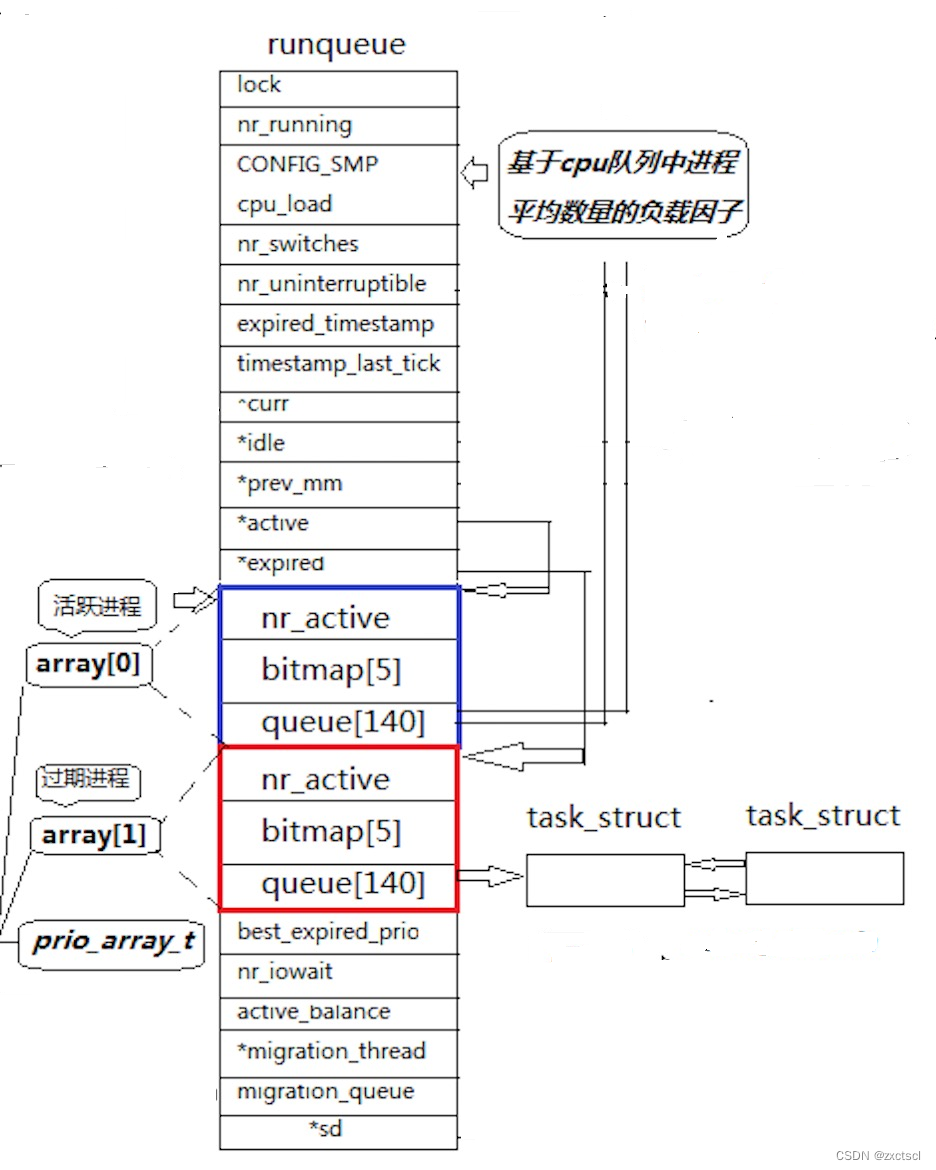
来看看蓝色区域的部分,这里面有queue队列包含140项,它其实是task_struct *queue[140]
queue[140]: 一个元素就是一个进程队列,相同优先级的进程按照FIFO规则进行排队调度,所以,数组下标就是优先级!
nr_active: 总共有多少个运行状态的进程
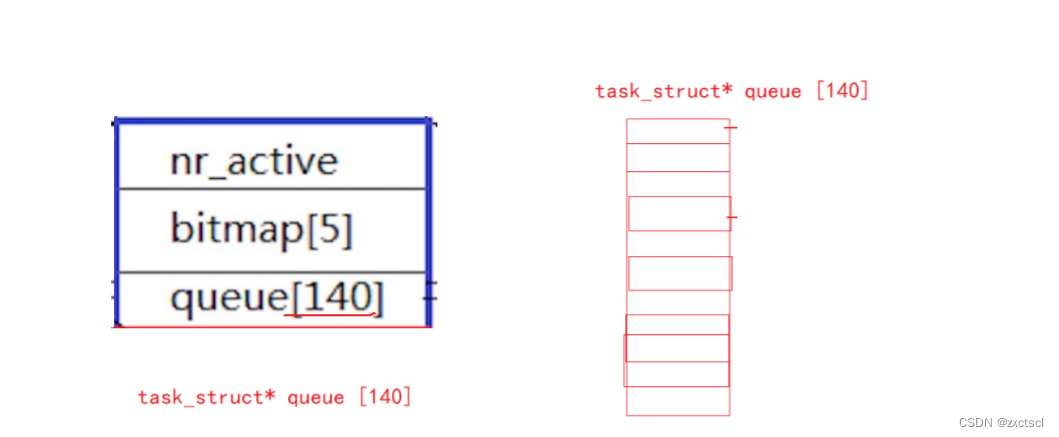
从该结构中,选择一个最合适的进程,过程是怎么的呢?
- 从0下表开始遍历queue[140]
- 找到第一个非空队列,该队列必定为优先级最高的队列
- 拿到选中队列的第一个进程,开始运行,调度完成!
- 遍历queue[140]时间复杂度是常数!但还是太低效了!
bitmap[5]:一共140个优先级,一共140个进程队列,为了提高查找非空队列的效率,就可以用5*32个比特位表示队列是否为空,这样,便可以大大提高查找效率!
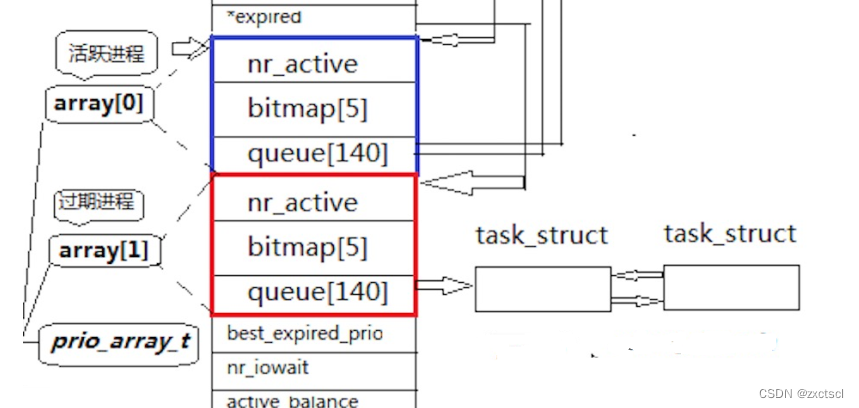
活跃进程的task_struct *queue[140]只出不进,过期进程的task_struct *queue[140]只进不出。
active指针和expired指针:active指针永远指向活动队列;expired指针永远指向过期队列。
可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都存在的。
没关系,在合适的时候,只要能够交换active指针和expired指针的内容,就相当于有具有了一批新的活动进程!
有问题请指出,大家一起进步!!!

