
- 1Redis开源协议变更!Garnet:微软开源代替方案?_garnet:.exe 下载
- 2两个ESP8266相互通信_两个esp8266通信
- 3Hist2ST:联合Transformer和图神经网络从组织学图像中进行空间转录组学预测
- 4Oracle 中关键字 ‘exists‘ 与 ‘in’ 详解_oracle exists和in
- 5Redis 可视化客户端工具、fastgithub 加速器_redis客户端工具
- 6构建Python中的分布式日志系统:ELK与Fluentd的结合
- 7IOS 32位调试环境搭建
- 8X86_64 GNU汇编、寄存器、内嵌汇编_clang x86 寄存器
- 9Python 自动识别图片文字—保姆级OCR实战教程_cnocr
- 10历时三个月,外包两年的我成功上岸了,分享一下我的美的集团面经。_美的外包转内部
Qwen1.5大语言模型微调实践_qwen1.5是什么模型
赞
踩
在人工智能领域,大语言模型(Large Language Model,LLM)的兴起和广泛应用,为自然语言处理(NLP)带来了前所未有的变革。Qwen1.5大语言模型作为其中的佼佼者,不仅拥有强大的语言生成和理解能力,而且能够通过微调(fine-tuning)来适应各种特定场景和任务。本文将带领大家深入实战,探索如何对Qwen大语言模型进行微调,以满足实际应用的需求。
一、了解Qwen1.5大语言模型
Qwen1.5模型是Qwen的升级版,也是Qwen2的测试版。它与Qwen类似,是只有一个decoder解码器的 transformer 模型,具有SwiGLU激活、RoPE、multi-head attention多头注意力。
- Qwen1.5有7个模型尺寸:0.5B, 1.8B, 4B, 7B, 14B, 72B 模型,还外加 14B (A2.7B) MoE 模型。
- chat 聊天模型的质量得到明显提高
- 在 base 模型和 chat 模型支持多语言的能力(中文,英文等)
- 支持 32768 tokens 的上下文长度
- 所有模型启用System prompts,可以进行角色扮演
- 不再需要 trust_remote_code
二、微调GPU资源评估和环境准备
这里我使用 Llama-Factory 训练框架来对 Qwen1.5 来进行微调,微调的方法可以使用 LoRA 或 QLoRA,可以大大节省GPU资源。具体的 Llama-Factory 环境搭建方法可以看官方链接:https://github.com/hiyouga/LLaMA-Factory

三、准备微调数据集和预训练模型
(1)数据集准备
微调数据集是微调过程中的关键。我们需要根据具体任务的需求,收集并整理相关的数据。这些数据应该包含输入和对应的输出,以便模型在训练过程中学习如何从输入中生成期望的输出。这里我使用一些公开的数据集来进行微调。
更多的数据集请看链接:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs
(2)Pre-training 模型准备
直接在 huggingface 下载,下载地址:Qwen
如果自己网络无法访问 huggingface ,也可以使用 HF-Mirror - Huggingface 镜像站 来进行下载也可以。
四、模型微调训练
(1)运行打开web ui 界面 按照 LLaMA-Factory 里面的教程搭建好环境之后就可以开始对模型进行微调了,执行以下命令来启动web ui 界面来进行微调:
- cd LLaMA-Factory
-
- export CUDA_VISIBLE_DEVICES=0 # use gpu0
- python src/train_web.py # or python -m llmtuner.webui.interface
如果想修改 网页服务的地址和端口号,直接在 src/train_web.py 修改就可以了。这里也可以代码中的 share 设置为True ,就可以把本地网络的web ui 界面作为一个 public 链接分享出去。
- from llmtuner import create_ui
-
-
- def main():
- create_ui().queue().launch(server_name="127.0.0.1", server_port=6006, share=True, inbrowser=True)
-
-
- if __name__ == "__main__":
- main()
(2)配置训练参数
然后根据的要求来进行配置,我的配置如下:
模型名称: Qwen1.5-7B-Chat
模型路径:填写自己本地下载的模型的路径,或者 Hugging Face 路径
微调方法:可以选用 lora, freeze, full 等
量化等级:选择 none,不进行量化,也可以启用 4/8 bit 模型量化(即 QLoRA)
提示模板:qwen
训练阶段:Supervised Fine-Tuning,也可以选 Reward Modeling, PPO, DPO, Pre-training等
数据路径:数据所在文件夹,默认为项目中的 data 文件夹
数据集:提取了 data 文件夹中的 *.json 文件,可直接选择。选择完成之后点一下“预览数据集”确认自己的数据是否正确。
其他的参数比如 学习率、训练轮数(epoch)、批处理大小、学习率调节器 等都是深度学习训练常见的参数,可以根据自己的情况选择就好。这里我使用默认的参数。
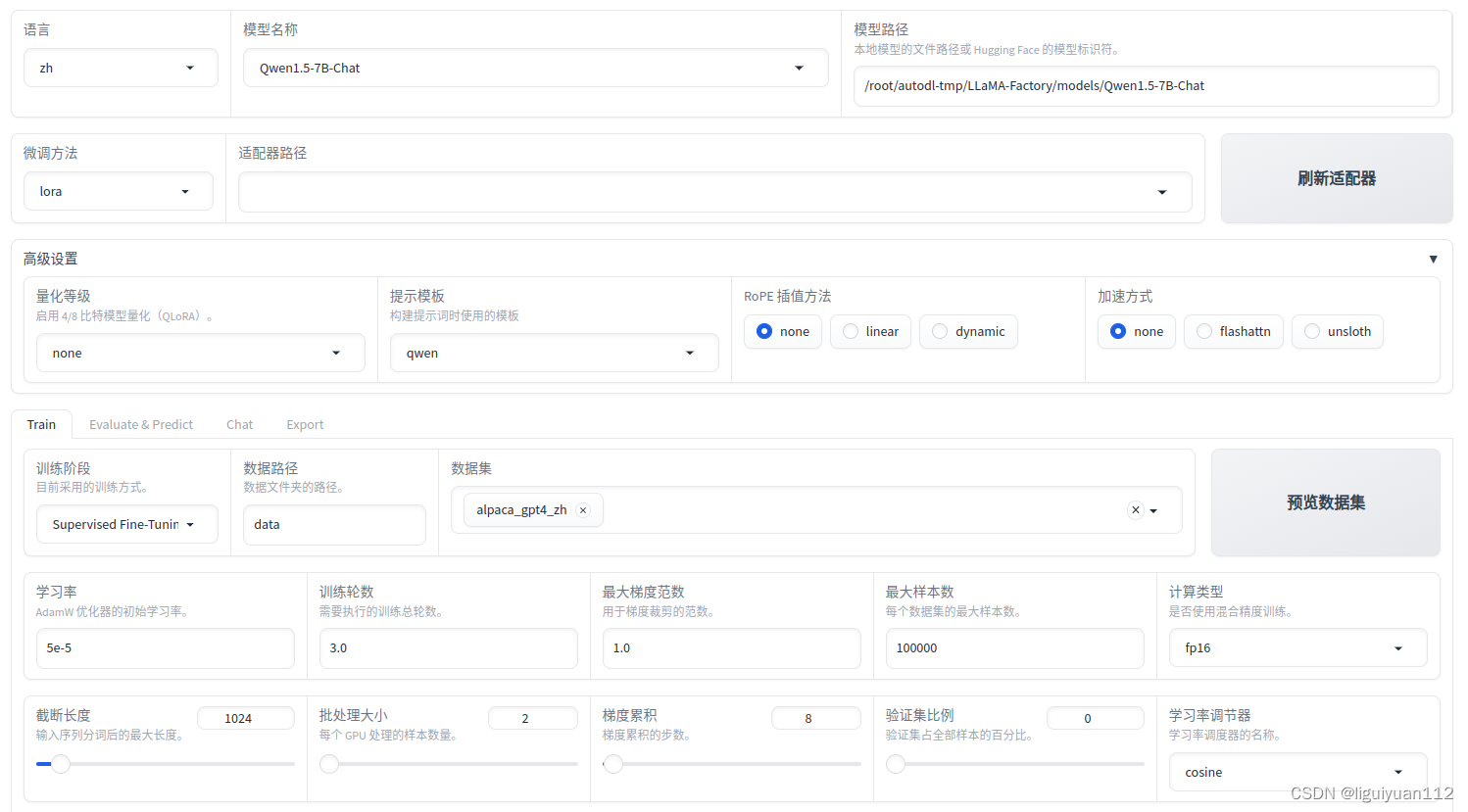
LoRA 参数设置中,可以修改 lora 秩的大小,缩放系数,权重随机丢弃的概率等参数,这里我保持默认。
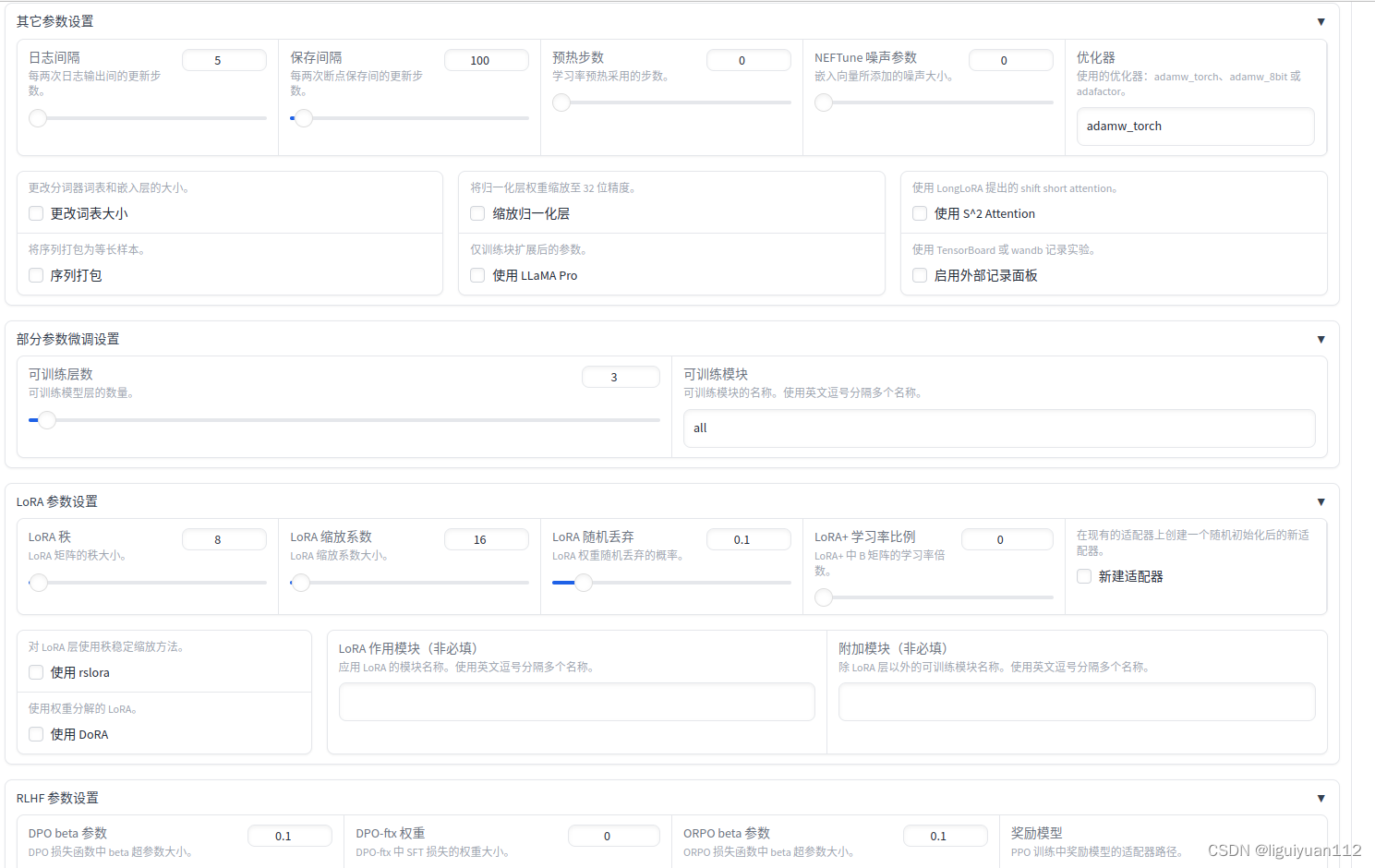
所有的参数都配置好之后,点一下“预览命令”,确认命令没有问题之后,就可以点击“开始”进行训练了。训练的过程中可以看到 loss的变化曲线、训练耗时等。
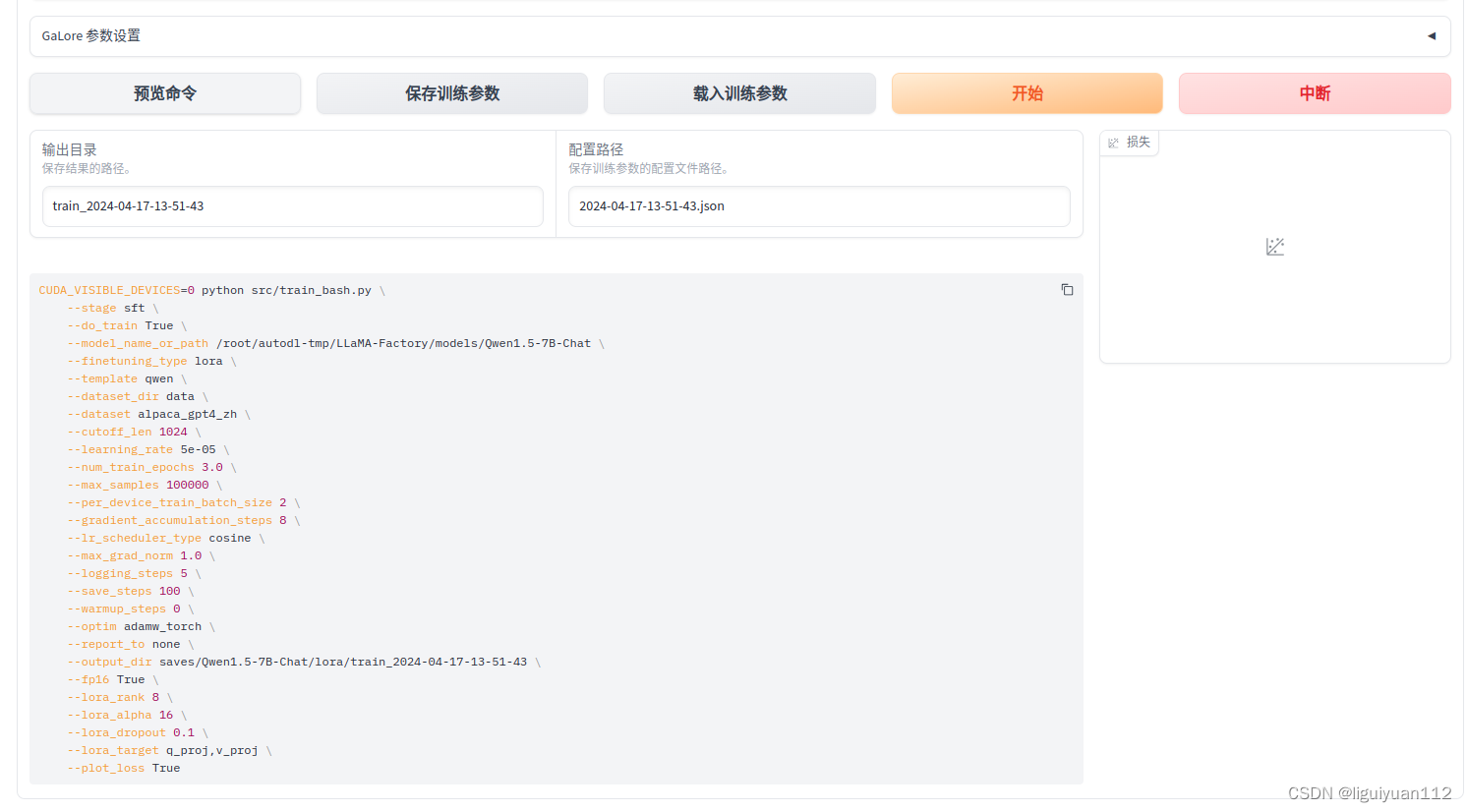
五、模型微调效果测试
微调完成后,我们需要对微调后的模型进行评估,以了解其在实际任务中的性能表现。也可以在web ui 界面直接进行对话体验。
在“模型路径”中输入原始模型路径,然后在“适配器路径”中选择自己微调得到的 adapter 路径,然后点击“加载模型”,就可以开始对话聊天了。

通过终端窗口,可以看到模型成功加载
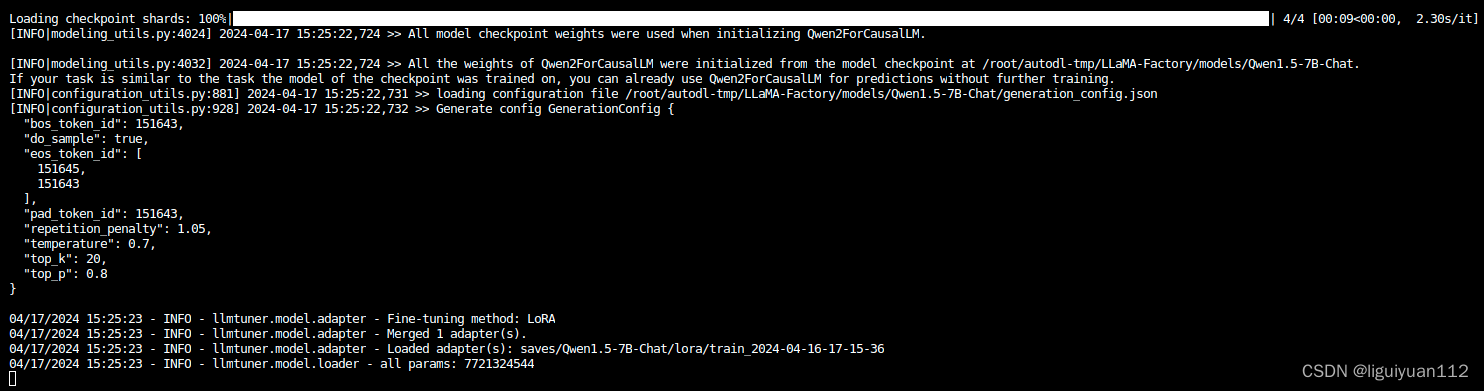
对话聊天:


参考:
1. GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs

