
- 1MIPS架构:一种计算机体系结构解析
- 2xgboost-GPU版本安装_conda安装支持 gpu 的 xgboost 版本
- 3Python Flask 构建微电影视频网站
- 4刷题打卡day 21 : 530.二叉搜索树的最小绝对差、 501.二叉搜索树中的众数 、236. 二叉树的最近公共祖先
- 5测试新人能少走弯路就别倔强_敏捷测试&testops构建
- 6gitee+picgo出现 upload error、404 Not Found_plugin picgo-plugin-gitee-uploader loaderror
- 7uniapp - 微信小程序报错[ project.config.json 文件内容错误]project.config.json: libVersion 字段需为 string,string(env:_project.config.json: libversion 字段需为 string, strin
- 8不用动手术的肝脏清洗法_肝胆净化要做几次才会清理干净啊。
- 9【脚本免费】天翼云Socks5多IP(10IP/20IP)服务器完整搭建教程_天翼云搭建socks5教程多ip
- 10Android shape属性_android shape angle
【MySQL故障】主从延迟越来越大_seconds_behind_master:延迟特别高
赞
踩
问题背景
研发执行了一个批量更新数据的操作,操作的表是个宽表,大概有90多个字段,数据量有800多w,但是研发是根据ID按行更新。更新开始后,该集群的主从延迟越来越大。
问题现象
1 从库应用binlog基本无落后,sql_thread 无落后。
2 从库落后主库很多个binlog
3 从库的io_thread一直处于 Queueing master event to the relay log 状态
4 Seconds_Behind_Master数值越来越大
问题分析
出现主从延迟后,首先分析是io_thread(拉取日志然后写中继日志) 还是 sql_thread(应用中级日志)。
另外需要明确 Seconds_Behind_Master是从库本地时间 - 主库binlog event的时间
sql_thread延迟的原因大概有
- 大事务 ,执行时间长
- DDL,执行时间长
- 元数据锁,主库完成变更后,在从库上应用的时候,从库刚好有个该表的长查询。造成该表所有的更新都被堵塞等待元数据锁
- 延迟从库,
- 并行复制,有无开启,并发度等
- 表上无主键
- 从库上备份,一般备份工具在备份非InnoDB 存储引擎的时候都会执行FTWRL
io_thread延迟的原因大概有
- 网络问题,网卡流量大,造成的网络拥塞
- 磁盘IO瓶颈
排查过程
首先确认落后是在 IO_thread(拉取binlog日志) 还是在 SQL_thread(应用binlog日志)
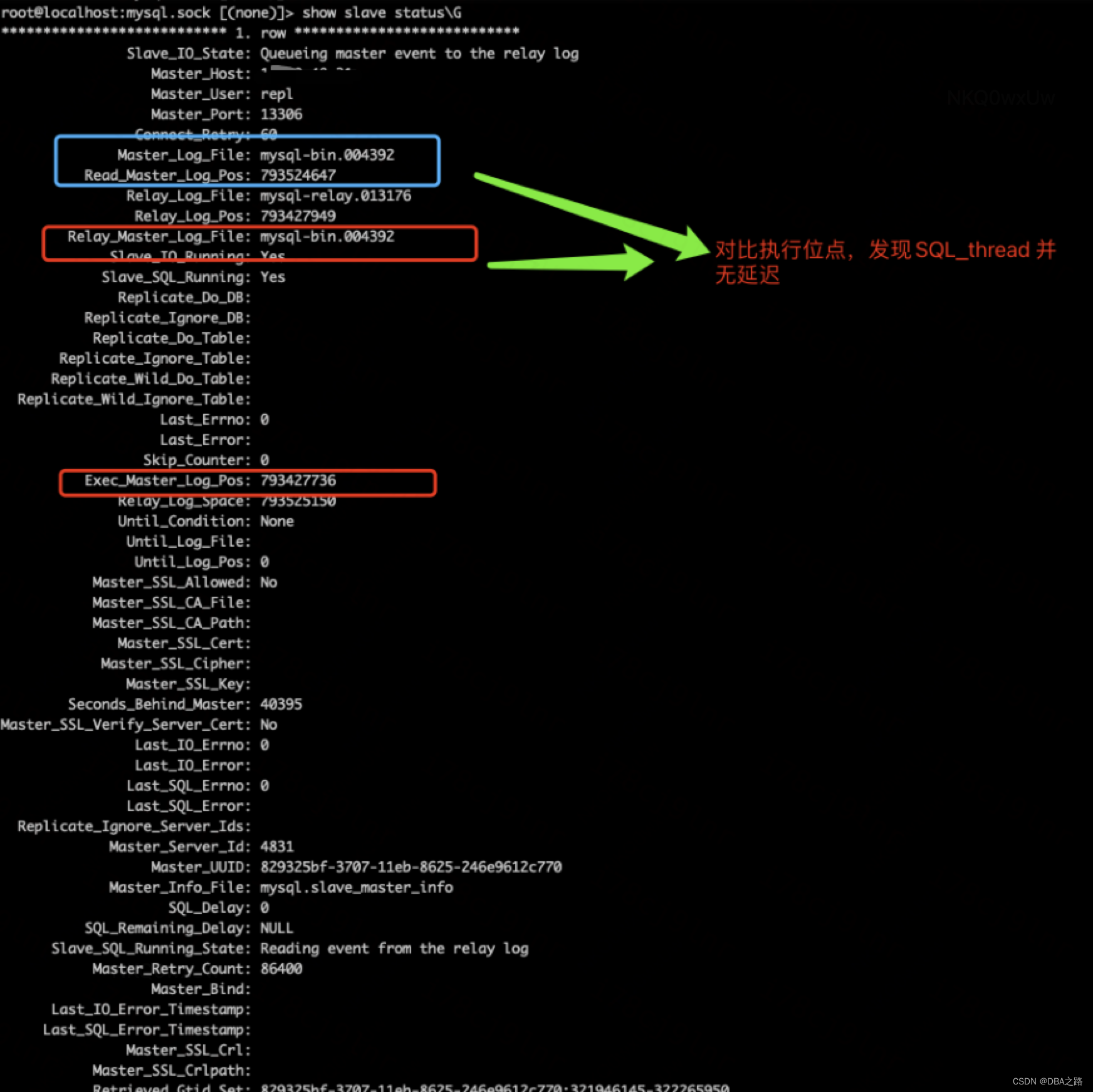
对比执行的文件和位点
Master_Log_File 与 Read_Master_Log_Pos (读取到的主库的binlog文件和位点)
Relay_Master_Log_File 与 Exec_Master_Log_Pos(sql_thread 应用的relay_log对应主库文件和位点)
发现文件编号基本一直,位点也相差无几,说明sql_thread 并无落后
再次确认,查看主库上有无大事务,DDL, 从库上有无长查询阻塞DDL,从库上备份等。该表有无主键,逐个排查并没有发现以上问题。
查看主库的此刻binlog 编号 与 从库获取到的标号,发现落后很多。
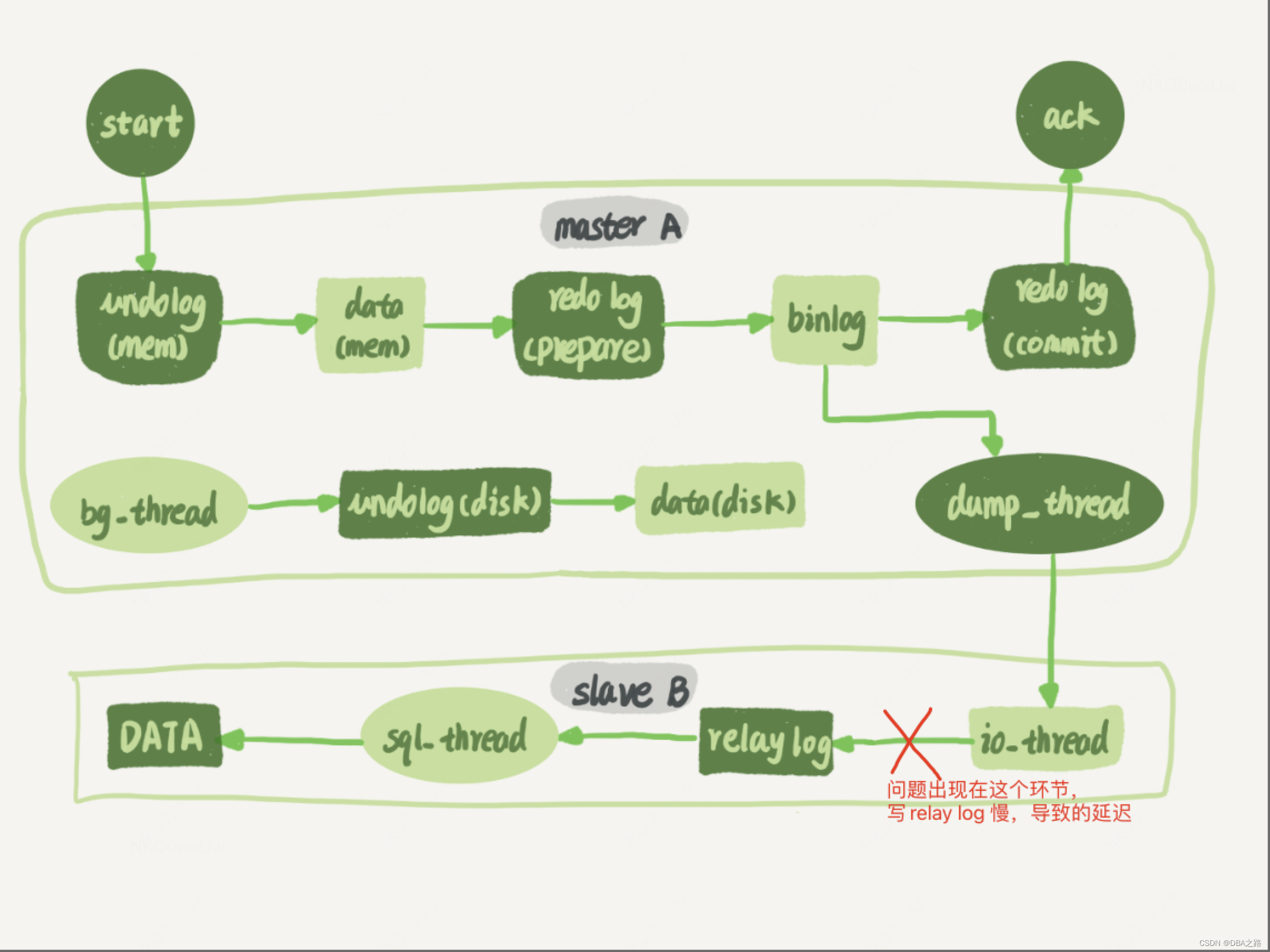
应该是IO_thread 拉取 然后 转写为 relay_log 的过程比较慢,这个过程主要设计到网络 和 磁盘IO的问题

在从库上查看会话 ,有个会话一直处于 Queueing master event to the relay log,查看官方文档 ,
The thread has read an event and is copying it to the relay log so that the SQL thread can process it. 该线程读取binlog中的 event 然后复制为中继日志,以便sql thread 可以应用这些event.
从官方文档中可以看到 该会话一直在将主库的event 写成从库的relay log

在服务器上通过IOTOP 命令查看磁盘IO状况
发现有个线程IOwait 一直很高 ,保持在70% 到 80%

通过查询 服务器上该线程ID 刚好 对应 数据库中写relay log的会话id.

此刻基本定位到是写relay 很慢,应该是和该表是宽表,
修改relay log的落盘参数,sync_relay_log 原来设置的是1 ,该大一些
set global sync_relay_log=100000;
监控图

总结
参考
类似问题:
https://www.cnblogs.com/zping/p/10861902.html
主从延迟原因
https://www.cnblogs.com/ivictor/p/17331981.html
官方文档 I/O Thread States
MySQL :: MySQL 5.7 Reference Manual :: 8.14.6 Replication Replica I/O Thread States

