
- 1jei投稿求福_jei期刊
- 2爬虫——有关抖音商品数据的爬取(蝉妈妈数据平台)_抖音爬虫
- 3Springcloud基础运用流程_spring cloud使用流程
- 4VScode上传到git仓库详细教程
- 5基于 shapley-value 的可解释方法及 shap 库实现_shap.deepexplainer
- 6程序员能干到退休吗?写了40年代码的「骨灰级码农」给出了15条建议_java退休
- 72023年软件设计师备考经验(附个人整理资料 全)_软件设计师题目技巧2023
- 8【cv2包如何安装】ModuleNotFoundError: No module named ‘cv2‘_cv2安装包
- 9GitHub: 风靡全球的开源版本控制平台_开源网站github
- 10flask导出Excel报表详解
Point Transformer V2: 分组的矢量注意力+分区池化_pointtransformer v2
赞
踩
[NeurIPS 2022] Point Transformer V2: Grouped Vector Attention and Partition-based Pooling
实验代码: https://github.com/Gofinge/PointTransformerV2
论文地址: https://arxiv.org/abs/2210.05666
Abstract
克服了Point Transformer的局限性。首次提出分组的矢量注意力,更加有效。设计了分组权重编码层,继承了可学习权重编码和多头注意力的优点。额外的位置编码加强了注意力的位置信息。设计了新颖轻量级的基于分区的池化方法,实现更好的空间对其和更高效的采样。
一、Introduction
PTv1将自注意力网络引入到了3D点云理解中。将矢量注意力与UNet风格的编码器-解码器框架相结合。由于PTv1每个channel都计算一个注意力,参数随着channel数目的增加而增加。更具参数效率的分组矢量注意力,在不同channel间共享注意力。多头注意力和矢量注意力都是本文提出的分组矢量注意力的退化情况。向关系向量增加额外的位置编码乘数来加强位置编码机制。设计了结合采样和查询的聚合模块设计范式,将点云分割为互不重叠的分区,直接融合同一分区内的点。本文使用均匀网格作为分区划分器。
贡献:1、分局矢量注意力 2、位置编码 3、分区聚合
二、Related Work
Image transformers. Point cloud understanding. Point cloud transformers.
三、Self-attention Networks
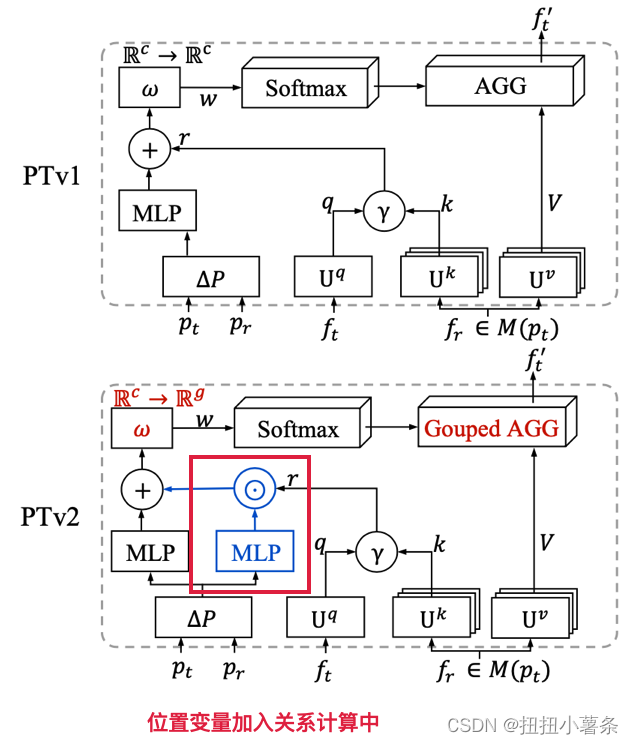
1. Scala Attention & Vector Attention

ω : Rc→ Rc 是一个可学习的权重编码(例如,多层感知机MLP),它通过通道计算注意力向量,以重新对 v j v_{j} vj进行加权聚合。
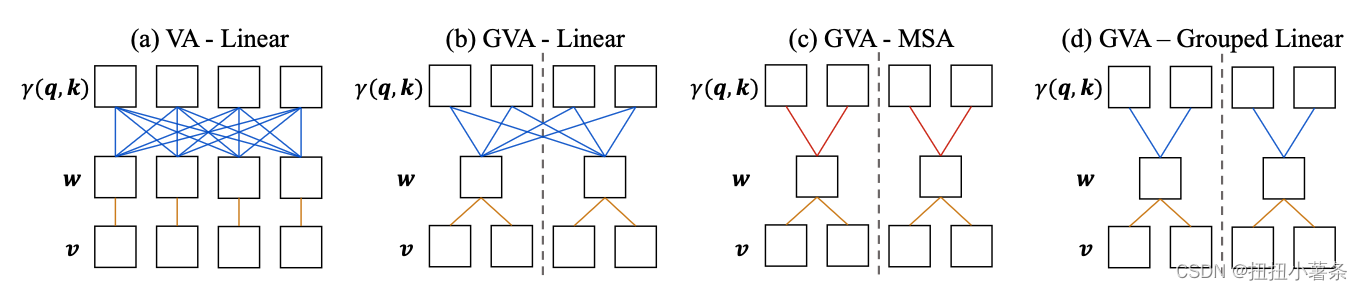
2. Grouped Vector Attention
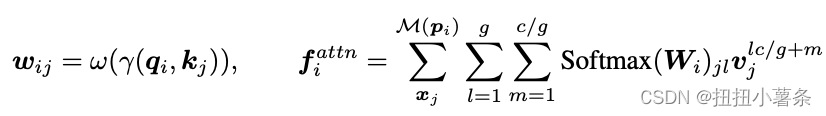
Channel分组,每组分别处理
3. Position Encoding Multipler
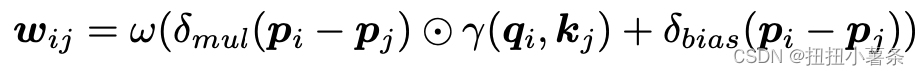
把位置变量添加到关系计算中
4. Partition-based Pooling
在这些基于采样的池化过程中,点的查询集合在空间上不对齐,因为每个查询集合的信息密度和重叠不可控。我们的方式是在空间划分不重叠的网格。
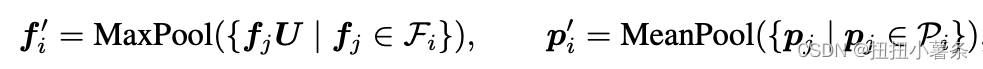
特征最大池化,坐标平均池化
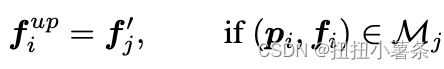
直接进行特征的上采样。
5. Network Architecture
主干结构。在前人的工作[18, 1]的基础上,我们采用了具有跳跃连接的U-Net架构。主干结构包括四个编码器和四个解码器阶段,其块深度分别为[2, 2, 6, 2]和[1, 1, 1, 1]。四个阶段的网格大小倍增器分别为[x3.0, x2.5, x2.5, x2.5],表示相对于前一个池化阶段的扩展比例。
初始特征维度为48,我们首先使用具有6个注意力组的基本块将输入通道嵌入到该维度。然后,每次进入下一个编码阶段时,我们将特征维度和注意力组加倍。对于四个编码阶段,特征维度分别为[96, 192, 384, 384],相应的注意力组为[12, 24, 48, 48]。
四、Experiments
数据集:ScanNet v2 S3DIS ModelNet40
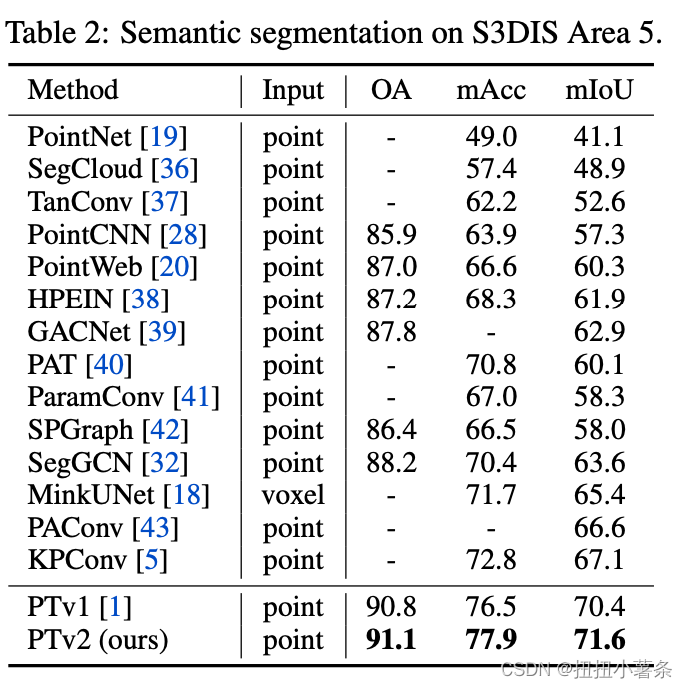
Ablation Study:
注意力类型:GVA比MSA效果好
权重编码方式:分组线性层后面跟着批归一化、激活和线性层最好
池化方式:网格比FPS要更好
参数量和速度的分析:
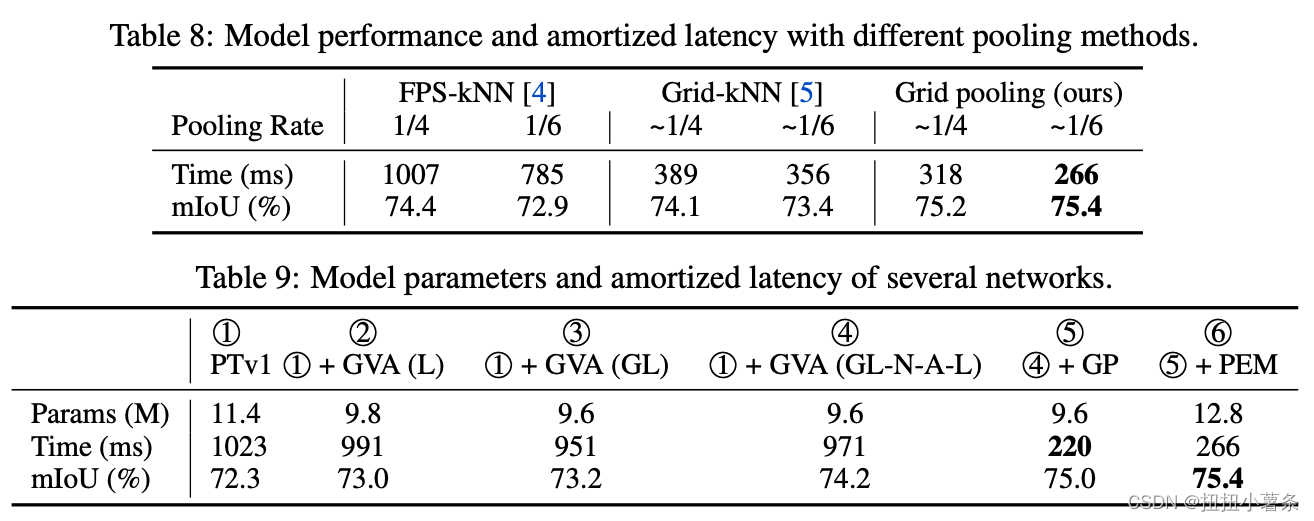
五、Conclusion
分组向量注意力、改进的位置编码和基于分区的池化

