
- 1灵魂讲师分享的:po是什么?自动化测试po分层如何实现?-带po详细源代码_po层
- 2openwrt 之 NC 指令_openwrt nc命令
- 3使用git fetch和git rebase处理多人开发同一分支的问题_.同一个分支可以用git rebase吗
- 4从入门到精通全套学习路线整理,3000字《软件测试》零基础入门_软件测试学习
- 5github双重身份验证登录记录_we tried delivering an sms to that number, but the
- 6排序算法1
- 7EBAZ4205 ZYNQ 7Z010 裸机程序NAND固化 JTAG调试方法_smc时序
- 8自定义标签(带属性)_自定义标签老师热
- 9Ubuntu20.04配置ORBSLAM2并在kitti数据集序列进行实验_orb-slam2运行 ubantu 20.4
- 10简单的Spring Security实例(自定义登录验证)_spring security怎么做一个假登录
一文看懂Linux内核页缓存(Page Cache)_linux pagecache
赞
踩
我们知道文件一般存放在硬盘(机械硬盘或固态硬盘)中,CPU 并不能直接访问硬盘中的数据,而是需要先将硬盘中的数据读入到内存中,然后才能被 CPU 访问。
由于读写硬盘的速度比读写内存要慢很多(DDR4 内存读写速度是机械硬盘500倍,是固态硬盘的200倍),所以为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用 页缓存(Page Cache) 机制来对文件中的数据进行缓存。
本文使用的 Linux 内核版本为:Linux-2.6.23
什么是页缓存
为了提升对文件的读写效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 页缓存)与文件中的数据块进行绑定。如下图所示:
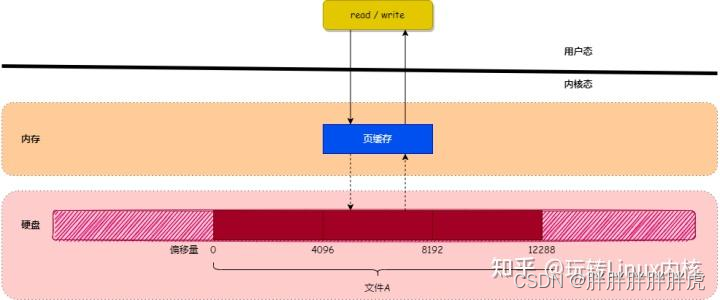
如上图所示,当用户对文件进行读写时,实际上是对文件的 页缓存 进行读写。所以对文件进行读写操作时,会分以下两种情况进行处理:
当从文件中读取数据时,如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户。
当向文件中写入数据时,如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把新数据写入到页缓存中。对于被修改的页缓存,内核会定时把这些页缓存刷新到文件中。
页缓存的实现
前面主要介绍了页缓存的作用和原理,接下来我们将会分析 Linux 内核是怎么实现页缓存机制的。
- address_space
在 Linux 内核中,使用 file 对象来描述一个被打开的文件,其中有个名为 f_mapping 的字段,定义如下:
struct file {
...
struct address_space *f_mapping;
};
- 1
- 2
- 3
- 4
从上面代码可以看出,f_mapping 字段的类型为 address_space 结构,其定义如下:
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
rwlock_t tree_lock; /* and rwlock protecting it */
...
};
- 1
- 2
- 3
- 4
- 5
- 6
address_space 结构其中的一个作用就是用于存储文件的 页缓存,下面介绍一下各个字段的作用:
- host:指向当前 address_space 对象所属的文件 inode 对象(每个文件都使用一个 inode 对象表示)。
- page_tree:用于存储当前文件的 页缓存。
- tree_lock:用于防止并发访问 page_tree 导致的资源竞争问题。
从 address_space 对象的定义可以看出,文件的 页缓存 使用了 radix树 来存储。
radix树:又名基数树,它使用键值(key-value)对的形式来保存数据,并且可以通过键快速查找到其对应的值。内核以文件读写操作中的数据 偏移量 作为键,以数据偏移量所在的 页缓存 作为值,存储在 address_space 结构的 page_tree 字段中。
下图展示了上述各个结构之间的关系:
如果对 radix树 不太了解,可以简单将其看成可以通过文件偏移量快速找到其所在 页缓存 的结构,有机会我会另外写一篇关于 radix树 的文章。
- 读文件操作
现在我们来分析一下读取文件数据的过程,用户可以通过调用 read 系统调用来读取文件中的数据,其调用链如下:
read()
└→ sys_read()
└→ vfs_read()
└→ do_sync_read()
└→ generic_file_aio_read()
└→ do_generic_file_read()
└→ do_generic_mapping_read()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
从上面的调用链可以看出,read 系统调用最终会调用 do_generic_mapping_read 函数来读取文件中的数据,其实现如下:
void do_generic_mapping_read(struct address_space *mapping, struct file_ra_state *_ra, struct file *filp, loff_t *ppos, read_descriptor_t *desc, read_actor_t actor) { struct inode *inode = mapping->host; unsigned long index; struct page *cached_page; ... cached_page = NULL; index = *ppos >> PAGE_CACHE_SHIFT; ... for (;;) { struct page *page; ... find_page: // 1. 查找文件偏移量所在的页缓存是否存在 page = find_get_page(mapping, index); if (!page) { ... // 2. 如果页缓存不存在, 那么跳到 no_cached_page 进行处理 goto no_cached_page; } ... page_ok: ... // 3. 如果页缓存存在, 那么把页缓存的数据拷贝到用户应用程序的内存中 ret = actor(desc, page, offset, nr); ... if (ret == nr && desc->count) continue; goto out; ... readpage: // 4. 从文件读取数据到页缓存中 error = mapping->a_ops->readpage(filp, page); ... goto page_ok; ... no_cached_page: if (!cached_page) { // 5. 申请一个内存页作为页缓存 cached_page = page_cache_alloc_cold(mapping); ... } // 6. 把新申请的页缓存添加到文件页缓存中 error = add_to_page_cache_lru(cached_page, mapping, index, GFP_KERNEL); ... page = cached_page; cached_page = NULL; goto readpage; } out: ... }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
do_generic_mapping_read 函数的实现比较复杂,经过精简后,上面代码只留下最重要的逻辑,可以归纳为以下几个步骤:
- 通过调用 find_get_page 函数查找要读取的文件偏移量所对应的页缓存是否存在,如果存在就把页缓存中的数据拷贝到应用程序的内存中。
- 否则调用 page_cache_alloc_cold 函数申请一个空闲的内存页作为新的页缓存,并且通过调用 add_to_page_cache_lru 函数把新申请的页缓存添加到文件页缓存和 LRU 队列中(后面会介绍)。
- 通过调用 readpage 接口从文件中读取数据到页缓存中,并且把页缓存的数据拷贝到应用程序的内存中。
从上面代码可以看出,当页缓存不存在时会申请一块空闲的内存页作为页缓存,并且通过调用 add_to_page_cache_lru 函数把其添加到文件的页缓存和 LRU 队列中。我们来看看 add_to_page_cache_lru 函数的实现:
int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
// 1. 把页缓存添加到文件页缓存中
int ret = add_to_page_cache(page, mapping, offset, gfp_mask);
if (ret == 0)
lru_cache_add(page); // 2. 把页缓存添加到 LRU 队列中
return ret;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
add_to_page_cache_lru 函数主要完成两个工作:
- 通过调用 add_to_page_cache 函数把页缓存添加到文件页缓存中,也就是添加到 address_space 结构的 page_tree 字段中。
- 通过调用 lru_cache_add 函数把页缓存添加到 LRU 队列中。LRU 队列用于当系统内存不足时,对页缓存进行清理时使用。
总结
本文主要介绍了 页缓存 的作用和原理,并且介绍了在读取文件数据时对页缓存的处理过程。
![【Linux】服务器时区 [ CST | UTC | GMT | RTC ]_linux上服务器时区](https://img-blog.csdnimg.cn/img_convert/7ca7738362d74dc0867c0c0ec139a490.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)


