
- 1Redis-主从复制(一)_redis主节点ping从节点
- 2Redis基本数据类型,redis官网
- 3git删除远程分支_git 删除远程分支
- 4基于PHP宿舍管理系统设计与实现 开题报告_宿舍管理系统开题报告
- 5Docker 安装 MySQL(Mac电脑M芯片)
- 6delphi opencv 物品数量识别_delphi opencv 货物识别
- 7mysql索引、慢查询和优化分析_访问磁盘的成本大概是访问内存成本的多少倍
- 8大语言模型智能体简介_langroid
- 9Flink CDC 将MySQL的数据写入Hudi实践_scan.incremental.snapshot.enabled
- 10设计模式 六大原则之开放封闭原则
BF,KMP算法(万字图文详解)_bf算法和kmp算法
赞
踩
目录
前言(很重要)
大家好,这里是小张,已经很久没有更新了,距上次更新已有快有一个月了。现在学校已经放暑假了,时间相对来说比较充裕,所以我觉得是时候继续写博客了。然后今天的内容是数据结构中BF算法,KMP算法的详解,并在里面加入了些我个人的理解和解释,希望能够给大家带来帮助。
另外有很多小伙伴们在学习算法的时候,只去学习一些关于算法理论的知识,并不知道自己的代码实战能力如何,也不清楚到底对该算法的了解有多深,所以在这里小张给大家推荐一个很棒的平台,在这里有很多的面试和算法题,也有很多的面试和求职的机会,大家可以点击下方链接进入牛客网刷算法真题,提高自己代码实战能力,早日拿到满意的offer!
BF算法定义
首先给大家带来的是BF算法,那么什么是BF算法,为什么要先从BF算法说起,不从KMP算法说起呢?
BF算法:BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
为什么先从BF算法说起:是因为BF算法可以说是KMP算法的基础,熟悉了BF算法之后就能够更快的去理解KMP算法内容,所以我们就先从BF算法说起。
BF算法的图文解释

在该图中有两个串,一个是串S另外一个是串T,其中串S我们称它为主串,串T我们称它为子串,i指向主串S的第一个元素(a),j指向子串T的第一个元素(a)。
现在我们开始进行串的匹配操作,从主串的第一个字符开始与我们子串的第一个字符进行比较 ,此时我们根据图示可以发现主串中i所对应的元素与子串中j所对应的元素都是a,既然相等,我们就可以使i,j的位置往后移动。此时i指向主串的第二个元素,j指向子串的第二个元素,我们根据图示可以发现主串中i所对应的元素与子串中j所对应的元素还是a,那么我们继续使i,j的位置往后移动。此时i指向主串的第三个元素,j指向子串的第三个元素,我们根据图示可以发现主串中i所对应的元素与子串中j所对应的元素还是a,那么我们继续使i,j的位置往后移动。
此时i指向主串的第四个元素,j指向子串的第四个元素,我们根据图示可以发现主串中i所对应的元素是a,但是子串j对应的元素为b,此时发生了不匹配的情况,这时我们就要进行“回溯”操作,主串S进行回溯操作,使i指向主串S的第二个元素,而此时j指向子串T的第一个元素然后再次进行匹配操作。
我们再进行如上的操作,我们会发现依旧是到了第四个元素匹配失败,那么我们此时再对S进行回溯操作,使i指向主串S的第三个元素,使j指向子串T的第一个元素之后再次进行匹配操作。
我们这时发现主串与字串的每个元素都匹配成功了,此时结束匹配。
BF算法的灵魂——回溯
刚刚在BF算法的图文解释中我们多次提到了“回溯操作”,那么什么是回溯呢。回溯是BF算法的灵魂,但同时也是BF算法中比较难理解的地方,下面来细说说回溯操作!
回溯:在什么时候要进行回溯操作呢,没错,在主串中的元素和子串中的元素发生不匹配的情况时要进行回溯操作,回溯操作是针对于主串来说的, 我们还以上图来进行解释,此时我们的主串中的的a与子串中的b发生了不匹配的操作,满足了回溯的条件,那么我们此时的主串就要进行回溯操作。
回溯操作有一个公式:i=i-j+2;这个公式是怎么来的呢,我们来根据下图来进行解释,此时我们的i的位置4,j的位置也是4,但是我们的i此时实际上并没有移动四次,只移动了三次,是因为本来我们的i就已经指向了1。所以说该公式i=i-j+2可以分解为两部分,第一部分是i-j+1。意为我们此时用主串的i减去子串的j时,本来只移动了三个间隔我们却减去了四个间隔,我们此时是多减去了一个间隔,所以我们现在应该在把这个多减去的间隔加回来,所以此时就是i-j+1。第二部分是(i-j+1)+1,即在第一部分的基础上我们又加了一个1,是因为我们既然前一个位置的元素开始已经匹配失败了,那么我们就要使主串的位置++,从而找到一个新的位置再次进行匹配操作。而对于子串中的j的话,每次一旦执行回溯操作的话,我们子串中的j都要置为1,意为从子串第一个元素开始重新进行串的匹配操作。
综上,回溯的公式就为:i=i-j+2。
BF算法代码实现
第一种:在数组中第一个元素置为0,从数组下标为1开始(符合上方规律的一种)
- #include<iostream>
- #include<string.h>
- using namespace std;
- //BF算法函数
- int BF(char*S, char*T)
- {
- //主串的长度
- int lenS = strlen(S)-1;
- //子串的长度
- int lenT = strlen(T)-1;
- //定义i,j分别作为主串和子串的指示器
- int i = 1, j = 1;
- //当主串和子串没有匹配完全时执行该while语句
- while (i <= lenS && j <= lenT)
- {
- //如果此时主串和子串的元素匹配成功
- if (S[i] == T[j])
- {
- //就让它们指向后一个元素继续进行匹配操作
- i++;
- j++;
- }
- //如果匹配不成功的话就要进行回溯操作
- //主串回溯。子串的j指向0
- else
- {
- i = i - j + 2;
- j = 1;
- }
- }
- //如果此时j的值大于等于子串的长度说明已经匹配成功
- if (j >= lenT)
- {
- //返回匹配成功的位置
- //因为我们此时是从下标0开始的
- //所以我们往后加了一个1返回的是子串在主串中的位置
- return i - lenT;
- }
- //匹配不成功
- else
- {
- return 0;
- }
-
- }
-
- int main()
- {
- char S[100], T[100];
- while (1)
- {
- cout << "请输入主串,第一个元素请置为0" << endl;
- cin >> S;
- cout << "请输入子串,第一个元素请置为0" << endl;
- cin >> T;
- int ret = BF(S, T);
- if (ret == 0)
- {
- cout << "很抱歉,匹配失败,未在主串中找到子串的相关信息" << endl;
- }
- else
- {
- cout << "匹配成功" << endl << "匹配成功的位置为" << ret << endl;
- }
- }
- return 0;
- }
运行结果展示:
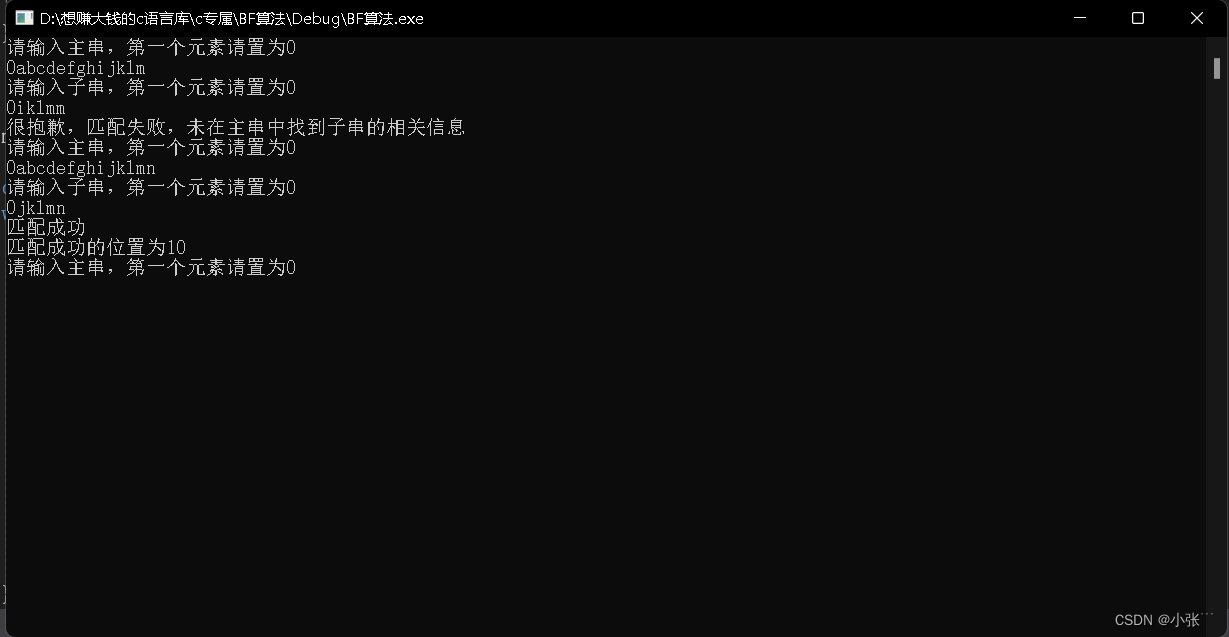
第二种:数组第一个元素不置为1(仅供参考,不建议使用)
- #include<iostream>
- #include<string.h>
- using namespace std;
-
- //BF算法函数
- int BF(char*S, char*T)
- {
- //主串的长度
- int lenS = strlen(S);
- //子串的长度
- int lenT = strlen(T);
- //定义i,j分别作为主串和子串的指示器
- int i = 0, j = 0;
- //当主串和子串没有匹配完全时执行该while语句
- while (i < lenS && j < lenT)
- {
- //如果此时主串和子串的元素匹配成功
- if (S[i] == T[j])
- {
- //就让它们指向后一个元素继续进行匹配操作
- i++;
- j++;
- }
- //如果匹配不成功的话就要进行回溯操作
- //主串回溯。子串的j指向0
- else
- {
- i = i - j + 1;
- j = 0;
- }
- }
- //如果此时j的值大于等于子串的长度说明已经匹配成功
- if (j >= lenT)
- {
- //返回匹配成功的位置
- //因为我们此时是从下标0开始的
- //所以我们往后加了一个1返回的是子串在主串中的位置
- return i - lenT + 1;
- }
- //匹配不成功
- else
- {
- return 0;
- }
-
- }
-
- int main()
- {
- char S[100], T[100];
- while (1)
- {
- cout << "请输入主串" << endl;
- cin >> S;
- cout << "请输入子串" << endl;
- cin >> T;
- int ret = BF(S, T);
- if (ret == 0)
- {
- cout << "很抱歉,匹配失败,未在主串中找到子串的相关信息" << endl;
- }
- else
- {
- cout << "匹配成功" << endl << "匹配成功的位置为" << ret << endl;
- }
- }
- return 0;
- }
运行结果展示: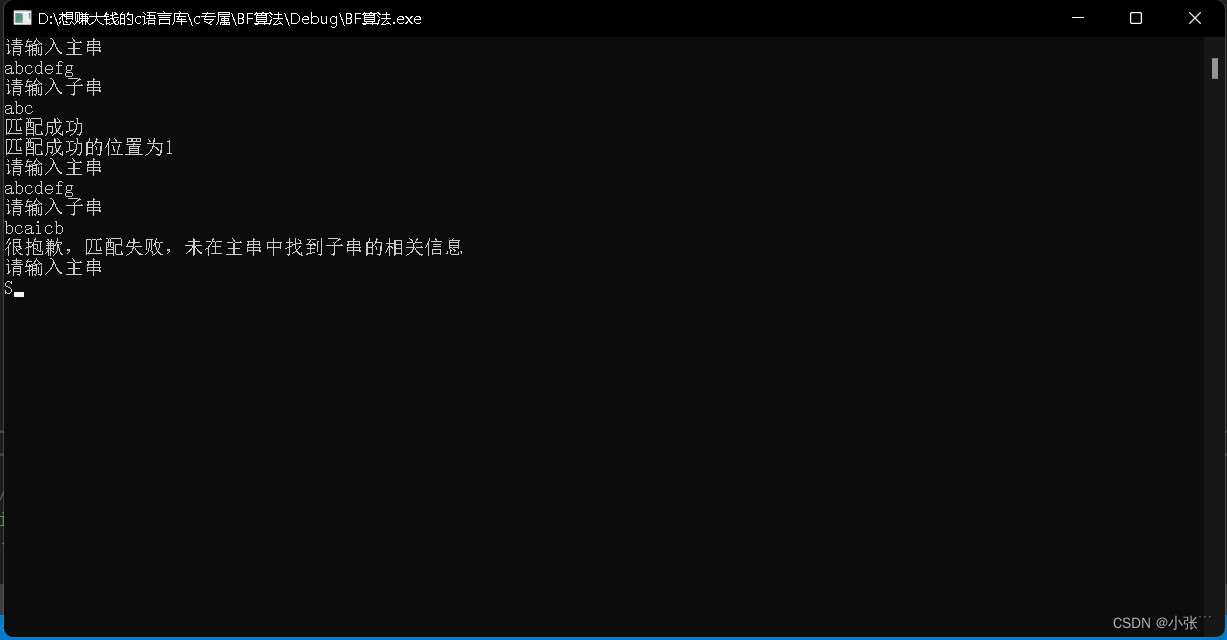
BF算法的时间复杂度
在匹配成功的情况下,应考虑两种情况:
1.最好情况下,每趟不成功的匹配都发生在模拟串的第一个字符与主串中相应字符的比较。
设主串的长度为 n ,子串的长度为 m,假设从主串的第 i 个位置开始与模拟串匹配成功,则在前 i-1 趟匹配中字符总共比较了 i-1 次;若第 i 趟成功的字符比较次数为 m , 则总比较次数为 i-1+m 。对于匹配成功的主串,其起始位置由 1 到 n-m+1 ,假定这 n-m+1 个起始位置上的匹配成功概率相等,则最好情况下匹配成功的平均比较次数为 (n+m)/2,则最好情况下的平均时间复杂度为 O(n+m)
2.最坏情况下,每趟不成功的匹配都发生在模拟串的最后一个字符与主串中相应字符的比较。假设从主串的第 i 个位置开始与模拟串匹配成功,则在前 i-1趟匹配中字符总共比较(i-1)*m 次;若第 i 趟成功的字符比较次数为 m ,则总比较次数 i*m 。 所以最坏情况下匹配成功的平均比较次数为 m*(n-m+2)/2,最坏情况下的平均时间复杂度为O(n*m)
KMP算法的定义
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息。
KMP算法和BF算法的区别
在上面我们说过的BF算法中我们知道了回溯是BF算法的灵魂,每次进行回溯操作的时候,主串和子串都要进行移动。而KMP算法中的主串是不用进行移动的,而子串的会也不用再移动到第一个元素的位置上了,子串的话会移动到特定的位置上,而这个特定的位置就是该位置上next数组中存储子串要移动位置的下标。
Next数组
Next数组是KMP算法最重要的一块,在求next之前我们应该知道next数组中存储的是什么。next数组中存储的是子串需要进行回退的下标,即当我们的主串和子串在某个位置匹配失败的时候,我们的子串就可以根据next数组对应的值进行回退到最合适的位置之后再次进行串的匹配操作。
Next数组的求法(手算)
在网上的一些资料中对next数组的求法主流的有两种,第一种next[0]=-1,next[1]=0。第二种next[0]=0,next[1]=1。虽然说next数组的前两个值不相同,但是思想和求法却是大同小异,只是在代码实现上有些许差异,所以我们这里以第一种为主。
如果我们现在要求next数组的第三个元素,则从next数组第三个元素开始,求next数组的方法是从第一个元素到该元素前一个元素之间寻找最长前缀以及最长后缀,最长的那个串就是next数组中的值。只有干巴巴的结论不具有说服性,下面我们来进行举例说明:
假设现在有个串为abcabc,我们来求它的next数组
首先我们可以快速写出它的数组中第一个元素和第二个元素的值,分别是-1和0。
第三个元素为c,我们此时来求它的next数组,在c前面的的元素为ab,此时在c前面以a开始b结束的串不存在,所以此时的next数组的值就为0。
再来看第四个元素a,在a前面的元素为abc,此时在a前面以a开头c结尾的串不存在,所以此时的next数组的值就为0。
接着是第五个元素b,在b前面的元素为abca,此时在b前面以a开头a结尾的串存在,就是开头的a,和结束的a,长度为1,所以此时的next数组的值就为1。
最后是第六个元素c,在b前面的元素为abcab,此时在c前面以a开头b结尾的串存在,分别为开头的ab,和结束时的ab,长度为2,所以此时的next数组的值就为2。
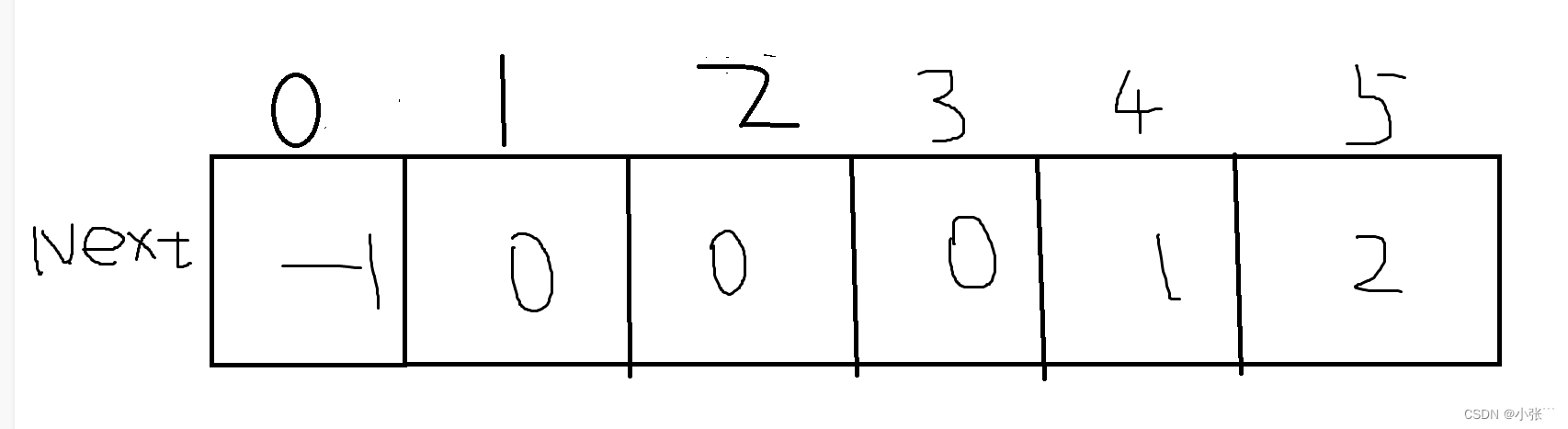
此时的next数组对应的值如图所示
Next数组的求法(代码)
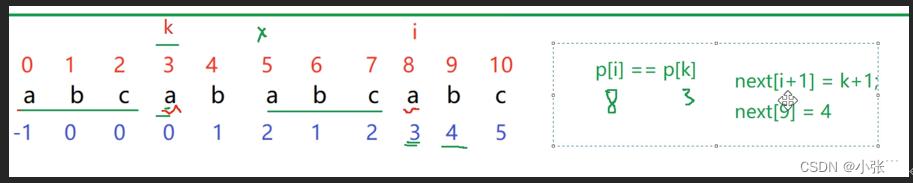
我相信通过上方的练习大家现在应该已经会求next数组了,那么此时串abcababcabc 对应的next数组在这里就不进行解释了,大家可以自行求解然后和这个进行对照一下。
假设我们在下标为8对应的元素这里匹配失败了,我们这时就要进行回退操作,此时主串的i不动,子串回退到此时匹配失败元素下标对应的next数组即next[8]中储存的元素,我们由图可得此时next[8]=3的此时子串应该回退到下标为3的主串位置进行比较。此时的p[i]==p[k],而且我们也不难发现next[i+1]=k+1即next[9]=4,那么我们此时就可以书写一部分求next数组的代码了,代码如下:
- if(sub[i-1]==sub[k])//这里之所以是i-1是因为我们前两个next数组的值是已经知道的
- //我们此时是从第三个元素开始的,所以这里的i就相当于i+1,i-1相等=当于i
- {
- next[i]=k+1;
- i++;
- k++;
- }
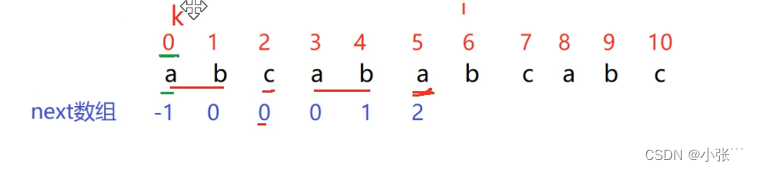
如果我们出现了 这种情况即p[i-1]!=p[k],一个是a一个是c,那么我们就需要连续回退,去找p[i-1]==p[k]的情况再执行以上操作就可以了,代码如下:
- if(k==-1sub[i-1]==sub[k])//这里之所以是i-1是因为我们前两个next数组的值是已经知道的
- //我们此时是从第三个元素开始的,所以这里的i就相当于i+1,i-1相等=当于i
- //这里的k==-1是为了防止数组越界
- {
- next[i]=k+1;
- i++;
- k++;
- }
- else
- {
- k=next[k];//进行连续回退直到找到sub[i-1]==sub[k]
- }
KMP算法代码
- //KMP算法
- #include<iostream>
- #include<assert.h>
- #include<string.h>
- #include<stdlib.h>
- using namespace std;
-
- void GetNext(char*sub, int*next)
- {
- int lenSub = strlen(sub);
- next[0] = -1;
- next[1] = 0;
- //子串下一项的i值
- int i = 2;
- //前一项即next[1]对应的k值,即回退的下标
- int k = 0;
-
- //next数组还没遍历完
- while (i < lenSub)
- {
- if (k == -1 || sub[k] == sub[i - 1])
- {
- next[i] = k + 1;
- i++;
- k++;
- }
- else
- {
- k = next[k];
- }
- }
- }
-
- //KMP算法函数
- int KMP(char*str, char*sub, int pos)
- {
- //断言判断主串和子串是否为空串
- assert(str != NULL && sub != NULL);
- //主串长度
- int lenStr = strlen(str);
- //子串长度
- int lenSub = strlen(sub);
-
- if (lenStr == 0 || lenSub == 0)
- {
- return -1;
- }
-
- //判断寻找的位置是否合理
- if (pos < 0 || pos >= lenStr)
- {
- return -1;
- }
-
- //在堆区开辟一个next数组
- int *next = (int*)malloc(sizeof(int)*lenSub);
- //断言判断内存是否申请成功
- assert(next != NULL);
- //获取next数组
- GetNext(sub, next);
-
- //i用来遍历主串
- int i = pos;
- //j用来遍历子串
- int j = 0;
- while (i < lenStr&&j < lenSub)
- {
- if (j == -1 || str[i] == sub[j])
- {
- i++;
- j++;
- }
- else
- {
- //进行回退操作
- j = next[j];
- }
- }
- //此时已遍历完成
- //如果j已经遍历完子串,说明匹配成功,可以返回匹配成功的位置
- if (j >= lenSub)
- {
- return i - j + 1;
- }
- else
- {
- return -1;
- }
- }
-
- int main()
- {
- char S[100], t[100];
- while (1)
- {
- cout << "请输入主串" << endl;
- cin >> S;
- cout << "请输入子串" << endl;
- cin >> t;
- int ret = KMP(S, t, 0);
- if (ret == -1)
- {
- cout << "很抱歉,匹配失败,在主串中未找到相关的子串" << endl;
- }
- else
- {
- cout << "找到了,它的位置为:" << ret << endl;
- }
- }
- return 0;
- }
运行结果展示
Next数组的优化——Nextval数组
只要我们next数组会求了,那么nextval数组就是手到擒来。nextval数组的第一个是和next数组的第一个是相同的即nextval[0]=-1。
从第二个开始,只要我们回退的位置是和当前位置的元素一样,就写回退位置的那个nextval值。
要是我们回退的位置是和当前位置的元素是不一样的,就写字符当前的这个next数组值。下面进行举例验证:
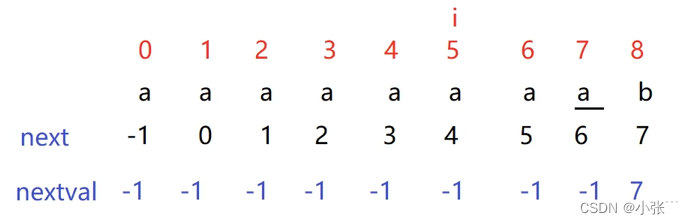
首先我们先求出next数组的值,然后 从第二个开始发现我们回退的位置和当前位置的元素一样,就写回退位置的那个nextval值即-1,然后一直往后推直到到了i=8我们发现它回退到7的位置是和当前位置的元素是不一样的,那么就写字符当前的这个next数组值,即就写7就行。

这里是一个求nextval数组的例子,大家可以自行练习,然后对照一下答案看看求得对不对,要是有什么不理解得地方可以随时私信或者在评论区留言给小张。
KMP算法时间复杂度
KMP算法的时间复杂度为O(m+n)
结束语
到这里关于BF算法和KMP算法的内容就已经全部结束了,若文章中有什么出错的地方的话,还请希望大家可以多多指正,小张在这里感谢大家的支持了!

