
- 1【MATLAB第37期】 #保姆级教程 XGBOOST模型参数完整且详细介绍,调参范围、思路及具体步骤介绍_xgboost matlab
- 2redis.clients.jedis.exceptions.JedisConnectionException
- 3基于FPGA的四则运算_fpga除法的小数
- 4FebHost:什么是挪威.no域名,如何注册?
- 5c语言编程题经典100例——(1~5例)_c语言比赛题目
- 6Java 解决pdfbox转图片显示中文乱码 No glyph for 165 (CID 5752) in font STSong-Light
- 7QGraphicsView实现简易地图8『缓存视口周边瓦片』
- 8Ubuntu系统使用Docker本地部署Android模拟器并实现公网访问_ubuntu docker android
- 9使用apt-mirror做一个本地ubuntu离线apt源
- 10剖析并利用Visual Studio Code在Mac上编译、调试c#程序_怎么在mac的vscode上写c#代码
使用ollama跨平台部署大模型_ollama 停止
赞
踩
Ollama介绍
官方网站:https://ollama.com/
官方Github Repo:https://github.com/ollama/ollama
官方自我介绍:Get up and running with Llama 2, Mistral, Gemma, and other large language models.
Why Ollama
1、有模型仓库,一行命令拉取模型运行
2、llama.cpp加速,支持类llama的大量模型。
3、发布api,便于集成各种web ui
4、多模型并行,便于模型测评与切换
5、支持LLVA视觉模型
6、支持Nvidia、AMD显卡加速
7、adapt加载
缺点
1、必须使用gguf模型,经过量化
2、对于pt,safetensor模型需要进行转化
3、需要使用Modelfile配置chat模板,难以使用call tool
Ubuntu Linux X86平台部署
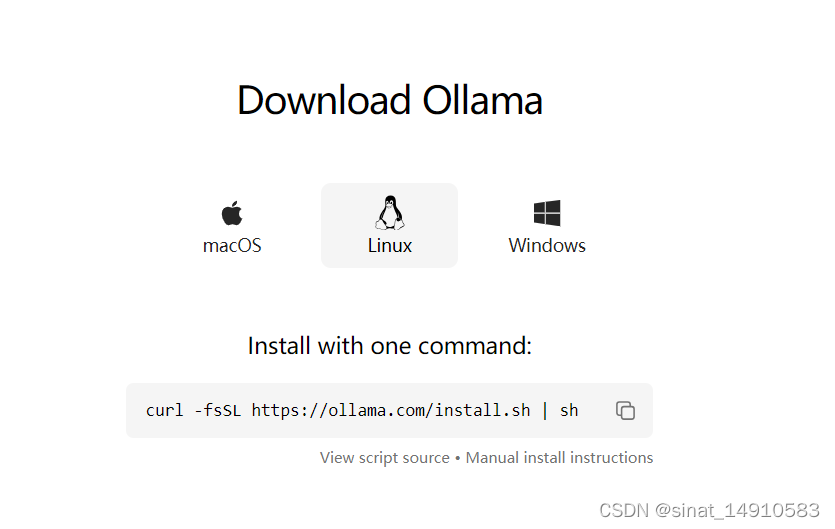
对于Linux平台,通过curl打开install.sh脚本下载。脚本的核心内容是下载ollama二进制文件。脚本文件自动下载bin包,注册ollama系统服务,创建ollama用户,检测显卡驱动。
命令执行完成后即可通过ollama指令操作服务。
$ ollama -h Large language model runner Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model pull Pull a model from a registry push Push a model to a registry list List models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
服务控制:
sudo systemctl stop ollama # 停止服务
sudo systemctl start ollama # 启动服务
# 监听http服务,指定GPU
export OLLAMA_HOST="0.0.0.0:11434"
export CUDA_VISIBLE_DEVICES="0"
ollama serve # 启动
- 1
- 2
- 3
- 4
- 5
- 6
ollama serve后会自动启动一个http服务,可以通过http请求模型服务,但此时还没有注册模型和模型权重,会在后面介绍。
MacOS & Windows系统部署
MacOS与Windows系统都是下载安装文件安装后即完成部署。
Nvidia Jetson部署
ollama通过nvidia-smi命令检测是否安装显卡驱动。Nvidia Jetson的Linux系统和JetPack包中不包含nvidia-smi,因此通过上述install.sh安装后无法实现显卡加速,推理全部使用Arm CPU实现。
1、安装后停止ollama服务
sudo systemctl stop ollama # 停止服务
- 1
2、安装tmux
sudo apt install tmux
- 1
3、使用tmux启动ollama
tmux has-session -t ollama_jetson 2>/dev/null || tmux new-session -d -s ollama_jetson 'LD_LIBRARY_PATH=/usr/local/cuda-11.4/targets/aarch64-linux/lib/stubs ollama serve'
- 1
模型加载
通过pull拉取官方模型
ollama pull mistral # 拉模型
ollama run mistral # 运行模型
- 1
- 2
模型仓库:https://ollama.com/library
ollama的整体设置与指令风格类似于docker
通过Modelfile创建自己的模型
从huggingface上下载gguf格式模型权重
新建Modelfile文件:
FROM {path/to/gguf} # required
PARAMETER # 模型参数
SYSTEM # 系统指令
TEMPLATE # 信息格式
ADAPTER # LORA权重路径,必须为GGML格式
- 1
- 2
- 3
- 4
- 5
modelfile教程:https://github.com/ollama/ollama/blob/main/docs/modelfile.md
ollama create {modelname} -f Modelfile
ollama run {modelname}
- 1
- 2
获取已有模型的Modelfile,基于原modelfile创建新模型(adapter)或调整参数
ollama show {modelname} --modelfile
- 1
更多操作请移步官方Github Repo学习
lora adapter的文件转换
前提:使用lora方式sft后获得的独立lora权重文件:adapter_model.bin, adapter_config.json
使用llama.cpp转换adapter权重
git clone https://github.com/ggerganov/llama.cpp/tree/master
cd llama.cpp
pip install -r reqiurement.txt
python convert-lora-to-ggml.py [path to LORA adapter folder]/adapter_config.json
- 1
- 2
- 3
- 4
脚本执行的输出最后会有转换完成的ggml-adapter-model.bin文件的地址,在modelfile的ADAPTER参数后附上该文件地址即可加载lora
模型使用
官方提供了多种模型使用方法,除了本地命令行、restful api以外还有各种语言的SDK可以使用。

