
- 1Faiss 简介
- 2Vue数据代理+事件处理+事件修饰符的作用+计算属性的使用,尚硅谷Vue系列教程学习笔记(2)
- 3人工智能 StratifiedKFold_分层采样 sklearn stratifiedkold
- 4chatgpt赋能python:重新配置PyCharm,让你的Python编程更加高效_如何重新设置pycharm
- 5解决问题:ERROR 1049 (42000): Unknown database 'XXX'_error 1049 (42000): unknown database '123456
- 6机器学习如何计算特征的重要性_简介机器学习中的特征工程
- 7Python学习笔记-文件监控watchdog_python watchdog丢失事件
- 8< 数据结构 > 堆的应用 --- 堆排序和Topk问题_堆排序topk问题
- 9哈希法c++_emplace_back哈希
- 10爱发猫AI智能写作程序,让你的写作更高效_人功智能写作的好处
Hive_hive可以实现从hive ql语言到什么程序的映射
赞
踩
Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
- Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
设计特征
Hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的HiveQL 语言实现数据查询,所有Hive 的数据都存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。
- 支持创建索引,优化数据查询。
- 不同的存储类型,例如,纯文本文件、HBase 中的文件。
- 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
- 可以直接使用存储在Hadoop 文件系统中的数据。
- 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
- 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
体系结构
用户接口
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 CLI,Cli 启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server 所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。
其中,CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储
Hive 将元数据存储在数据库中,如 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由地组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 pvs,它在 HDFS 中的路径为:/wh/pvs,其中,wh 是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。
Partition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。例如:pvs 表中包含 ds 和 city 两个 Partition,则对应于 ds = 20090801, city = US 的 HDFS 子目录为:/wh/pvs/ds=20090801/city=US;对应于 ds = 20090801, city = CA 的 HDFS 子目录为;/wh/pvs/ds=20090801/city=CA
Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。将 user 列分散至 32 个 bucket,首先对 user 列的值计算 hash,对应 hash 值为 0 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00000;hash 值为 20 的 HDFS 目录为:/wh/pvs/ds=20090801/ctry=US/part-00020
External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
Table 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除。
External Table 只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在 LOCATION 后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个 External Table 时,仅删除元数据,表中的数据不会真正被删除。
使用Hive的原因
直接使用hadoop所面临的问题
- 人员学习成本太高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive的好处
- 操作接口采用类SQL语法,提供快速开发的能力。
- 避免了去写MapReduce,减少开发人员的学习成本。
- 扩展功能很方便。
Hive的特点
可扩展:Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
容错:良好的容错性,节点出现问题SQL仍可完成执行。
架构图
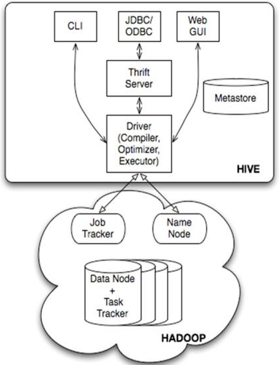
Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据

Hive与传统数据库对比
hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析

Hive的数据存储
-
Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
-
只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
-
Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
DB:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
Table:在hdfs中表现所属db目录下一个文件夹
External Table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表:删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
Partition:在hdfs中表现为table目录下的子目录
Bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
参考文章:
https://baike.baidu.com/item/Hive/67986
https://www.cnblogs.com/huifeidezhuzai/p/9251969.html

