
热门标签
热门文章
- 1省钱!NewBing硬核新玩法;手把手教你训练AI模特;用AI替代同事的指南;B站最易上手AI绘画教程 | ShowMeAI日报_ai绘画教程bilibili
- 2一口气说出 Redis 16 个常见使用场景_redis使用场景
- 3动态规划-思考解决动态规划问题_你的公司老板给了你一张n×n个格子组成的动态规划
- 4B样条曲线优化各种路径规划算法,matlab栅格地图。_b样条优化
- 5three.js流动线_threejs流动线
- 6自然语言处理工具包:NLTKspaCy
- 7超星高级语言程序设计实验作业 (实验01顺序程序设计)_分别输入三个浮点数代表a、b、c的值;如果c的值为0,直接输出-1,否则计算并输出多项
- 8笔记本wifi与台式机、内网服务器共网、共享wifi详细教程_服务器没有网,怎么共享笔记本网络
- 9核函数kernal
- 10Android~获取WiFi MAC地址和IP方法汇总_android 获取本机wlan mac地址
当前位置: article > 正文
重复值处理--Pandas_pandas去除重复行
作者:AllinToyou | 2024-05-05 21:43:46
赞
踩
pandas去除重复行
1. 删除重复行:drop_duplicate()
1.1 函数功能
返回去除重复行的DataFrame,不考虑索引。
1.2 函数语法
DataFrame.drop_duplicates(subset=None, *, keep='first', inplace=False, ignore_index=False)
- 1
1.3 函数参数
| 参数 | 含义 |
|---|---|
| subset | 列标签或列标签组成的列表,默认所有列 |
| keep | 决定保留重复行中的哪个:first:保留重复值的第一个;last:保留重复值的最后一个;False:删除重复值的所有行 |
| inplace | 布尔值,默认False:不修改原来的DataFrame |
| ignore_index | 布尔值,默认False:不改变DataFrame的原有索引标签,否则将修改为0,1,…n-1 |
1.4 实践演示
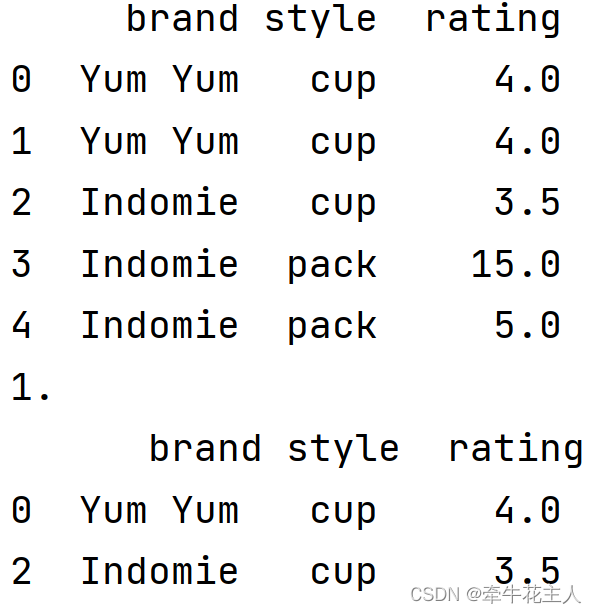
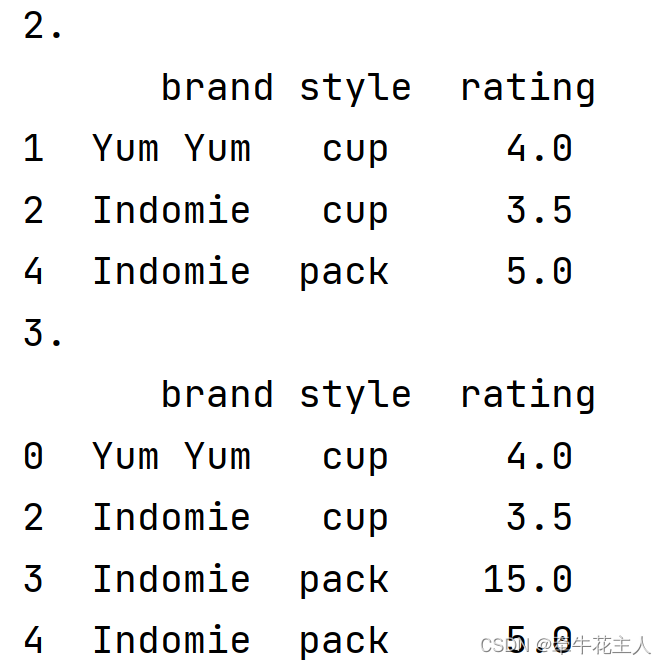
df = pd.DataFrame({ 'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'], 'style': ['cup', 'cup', 'cup', 'pack', 'pack'], 'rating': [4, 4, 3.5, 15, 5]}) print(df) # 删除某一列中的重复值,保留重复值的第一个值 print('1.\n',df.drop_duplicates(subset='brand',keep='first')) # 删除多列中的重复值,保留重复值的最后一个 print('2.\n',df.drop_duplicates(subset=['brand','style'],keep='last')) # 默认删除所有列同时重复的行 print('3.\n',df.drop_duplicates(keep='first')) # 重新标记索引 print('4.\n',df.drop_duplicates(keep='first',ignore_index=True)) # 删除重复行的所有行 print('5.\n',df.drop_duplicates(keep=False,ignore_index=True))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

2. 查找重复行:duplicated()
2.1 函数功能
返回是否为重复行的布尔值Series
2.2 函数语法
DataFrame.duplicated(subset=None, keep='first')
- 1
2.3 函数参数
| 参数 | 含义 |
|---|---|
| subset | 列标签或列标签组成的列表,默认所有列 |
| keep | 决定标记重复行中的哪个:first:标记重复行的第一个之外的为True;last:标记重复行的最后一个之外的为True;False:标记所有的重复行为True |
2.4 实战演练
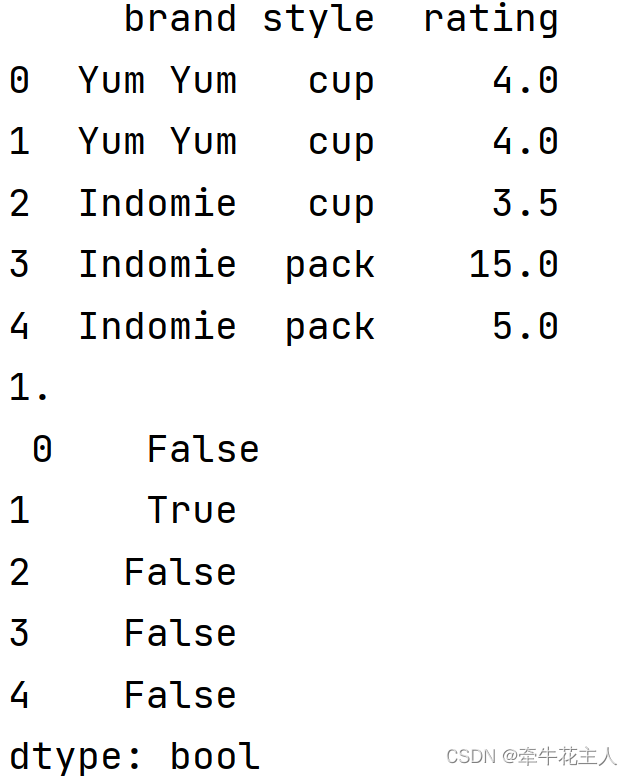
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]})
print(df)
# 标记重复行第一个之外的为True
print('1.\n',df.duplicated(keep='first'))
# 标记重复行最后一个之外的为True
print('2.\n',df.duplicated(keep='last'))
# 标记所有重复行为True
print('3.\n',df.duplicated(keep=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/540965
推荐阅读
相关标签

