- 1【华为OD机试】手机App防沉迷系统(贪心算法—Java&Python&C++&JS实现)_手机app防沉迷系统华为od
- 2如何保证分布式文件系统的数据一致性
- 3RabbitMQ 笔记_x-delayed-message
- 432单片机 C语言 寄存器(四)_使用c语言判断单片机寄存器数据位
- 5Linux下的CentOS7连接不上外网,yum失败_yum install rpm 无法联网失败
- 6测试用例设计方法_等价类划分法(游戏向)_请简述一下等价类划分法设计测试用例的方法。
- 7当AI遇见现实:数智化时代的人类社会新图景
- 8MySQL安装配置教程-win10_mysql5.6安装
- 9揭秘游戏行业遭遇大规模DDoS攻击后的影响和真相丨阿里云河南_游戏公司被黑客攻击的影响
- 10【人工智能基础】GAN与WGAN实验
散列存储理解、哈希表知识点总结
赞
踩
修改转载自https://blog.csdn.net/misayaaaaa/article/details/71780483
散列(hashing)是一种重要的存储方法,也是一种常见的查找方法。
基本思想:以结点的关键字k为自变量,通过一个确定的函数关系f,计算出对应的函数值,吧这个函数值解释为结点的存储地址,将结点存入到f(k)所指示的存储位置上,在查找时再根据要查找的关键字,用同样的函数计算地址,然后到相应的单元中读取。散列法又被成为关键字——地址转换法。
顺序表的特点是:寻址容易,插入和删除困难; 而链表的特点是:寻址困难,插入和删除容易。Hash表综合两者优点,既寻址容易又插入和删除容易。
哈希表:用散列法存储的线性表被称为哈希表,使用的函数被称为散列函数或者哈希函数,f(k)被称为散列地址或者哈希地址。通常情况下,散列表的存储空间是一个一维数组,而其哈希地址为数组的下标
哈希函数的选择原则:
1、若哈希函数是一个一一对应的函数,则在查找时,只需要根据哈希函数对给定关键字的某种运算得到待查找结点的存储位置,无需进行比较
2、一般情况下,散列表的空间要比结点的集合大,虽然浪费了一部分空间但是却提高了查找的效率,散列表空间为m,填入表中结点数为n,则比值n/m成为哈希表的装填因子,一般取0.65~0.9之间
3、哈希函数应当尽量简单,其值域必须在表长的范围之内,尽量不要产生“冲突”(两个关键字得到相同的哈希地址)
哈希表的优缺点:
Hash表存在的优点显而易见,能够在常数级的时间复杂度上进行查找,并且插入数据和删除数据比较容易。但是它也有某些缺点,比如不支持排序,一般比用线性表存储需要更多的空间,并且记录的关键字不能重复。
哈希函数的构造方法:
直接定址法
取关键字或者关键字的某个线性函数为Hash地址,即address(key)=a*key+b;如知道学生的学号从2000开始,最大为4000,则可以将address(key)=key-2000作为Hash地址。
平方取中法
对关键字进行平方运算,然后取结果的中间几位作为Hash地址。假如有以下关键字序列{421,423,436},平方之后的结果为{177241,178929,190096},那么可以取{72,89,00}作为Hash地址。
折叠法
将关键字拆分成几部分,然后将这几部分组合在一起,以特定的方式进行转化形成Hash地址。假如知道图书的ISBN号为8903-241-23,可以将address(key)=89+03+24+12+3作为Hash地址。
除留取余法
如果知道Hash表的最大长度为m,可以取不大于m的最大质数p,然后对关键字进行取余运算,address(key)=key%p。
在这里p的选取非常关键,p选择的好的话,能够最大程度地减少冲突,p一般取不大于m的最大质数。
哈希函数构造方法有:
直接定址法,数字分析法,折叠法,平方取中法,乘余取整法
减去法,基数转换法,除留余数法,随机乘数法,字符串数值哈希法,旋转法,伪随机数法
"冲突"的解决,通常情况下有2种解决办法:
开放定址法
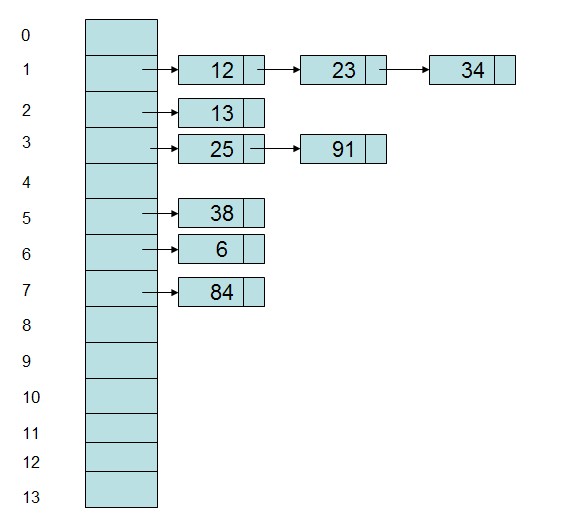
即当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。比较常用的探测方法有线性探测法,比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为14,Hash函数为address(key)=key%11,当插入12,13,25时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1依次往下探测(探测步长可以根据情况而定),直到探测到地址4,发现为空,则将23插入其中。
链地址法
采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。如上述例子中,采用链地址法形成的Hash表存储表示为: