
热门标签
热门文章
- 1ModuleNotFoundError: No module named‘ pymysql ‘异常的正确解决方法
- 2一个Boss直聘机器人, 自动回复发简历
- 3毕业设计:基于深度学习的图像分类识别系统 人工智能_深度学习图像识别毕设总体概述
- 4数字逻辑电路复习资料_数字逻辑电路空翻和反转的区别
- 5uniapptabbar的高度是多少_Uniapp-tabbar选择及适配
- 6揭秘爬虫个股投资机会,轻松赚钱!_爬虫炒股有用吗
- 7【无人机编队】基于matlab二阶一致性多无人机协同编队控制(考虑通信半径和碰撞半径)【含Matlab源码 4215期】_多无人机协同任务规划matlab
- 8Dubbo源码(4)-Zookeeper注册中心源码解析_o.a.d.r.zookeeper.zookeeperregistry.unsubscribe -
- 9Adobe Lightroom Classic v13.1 (macOS, Windows) - 桌面照片编辑器_lightroom 13.1
- 10Seagull License Server 9.4 SR3 2781 完美激活(解决不能打印问题)
当前位置: article > 正文
[AIGC] 跳跃表是如何实现的?原理?
作者:AllinToyou | 2024-05-13 17:43:21
赞
踩
[AIGC] 跳跃表是如何实现的?原理?
PS:跳跃表是比较常问的一种结构。
什么是跳跃表
Skip Lists: A Probabilistic Alternative to Balanced Trees
- 跳跃表是一种可以用来代替平衡树的数据结构。
- 跳跃表使用概率平衡,而不是严格强制的平衡,
- 跳跃表中插入和删除的算法比平衡树的等效算法简单得多,速度也快得多
实质上就是一种可以进行二分查找的有序链表。而二分查找的基础就是分层索引。
eg: 论文第二页给的图
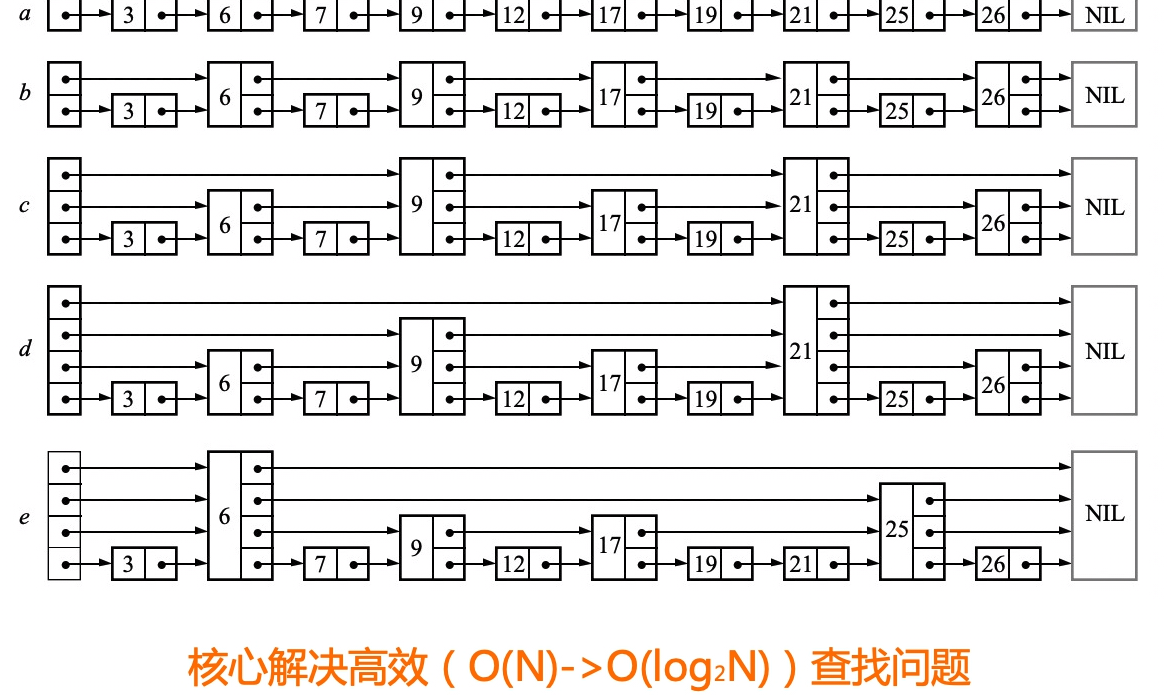

查找流程:

在头领节点的最高楼沿着跨度向前寻找,如果刚好找到所需元素,则直接返回,否则继续往前寻找,知道遇到比寻找的元素大的元素,然后返回一个跨度,并下一层楼寻找。如果在一楼也找不到说明元素不存在。
每个楼层至少有两个元素,跨度和前向指针。
eg: 插入,删除

跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。 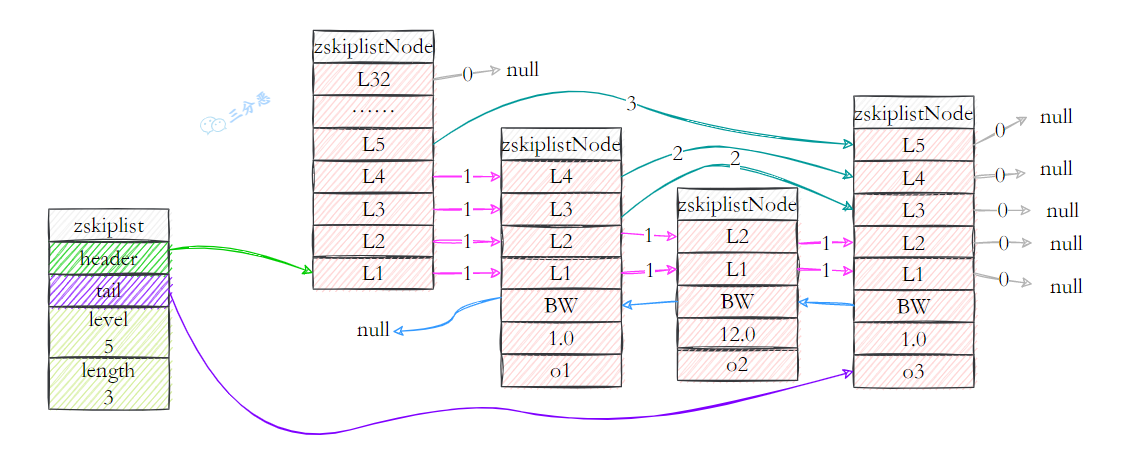
为什么使用跳跃表?
首先,因为 zset 要支持随机的插入和删除,所以它 不宜使用数组来实现,关于排序问题,我们也很容易就想到 红黑树/ 平衡树 这样的树形结构,为什么 Redis 不使用这样一些结构呢?
- 性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部;
- 实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
基于以上的一些考虑,Redis 基于 William Pugh 的论文做出一些改进后采用了 跳跃表 这样的结构。
本质是解决查找问题。
跳跃表是怎么实现的?
跳跃表的节点里有这些元素:
- 层 跳跃表节点的level数组可以包含多个元素,每个元素都包含一个指向其它节点的指针,程序可以通过这些层来加快访问其它节点的速度,一般来说,层的数量越多,访问其它节点的速度就越快。每次创建一个新的跳跃表节点的时候,程序都根据幂次定律,随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”
- 前进指针 每个层都有一个指向表尾的前进指针(level[i].forward属性),用于从表头向表尾方向访问节点。我们看一下跳跃表从表头到表尾,遍历所有节点的路径:
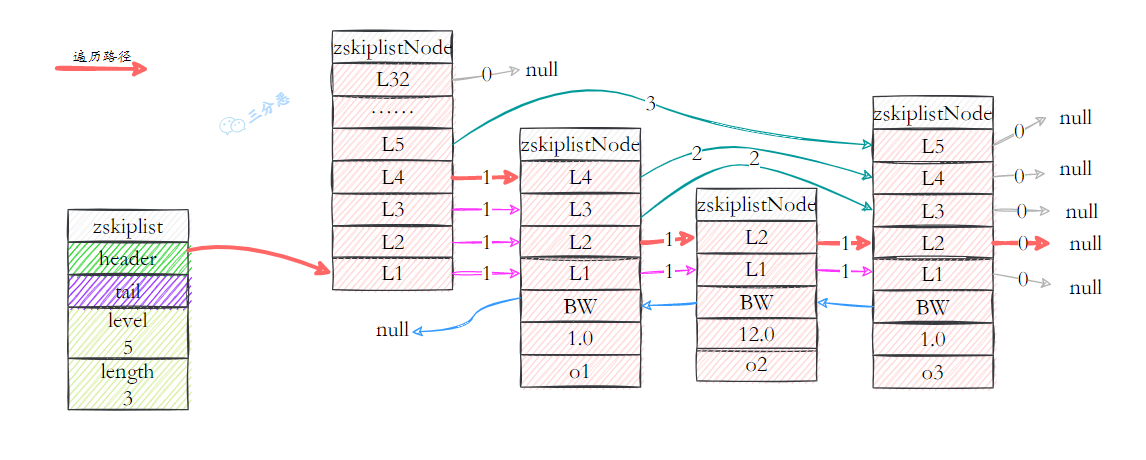
- 跨度 层的跨度用于记录两个节点之间的距离。跨度是用来计算排位(rank)的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。例如查找,分值为3.0、成员对象为o3的节点时,沿途经历的层:查找的过程只经过了一个层,并且层的跨度为3,所以目标节点在跳跃表中的排位为3。
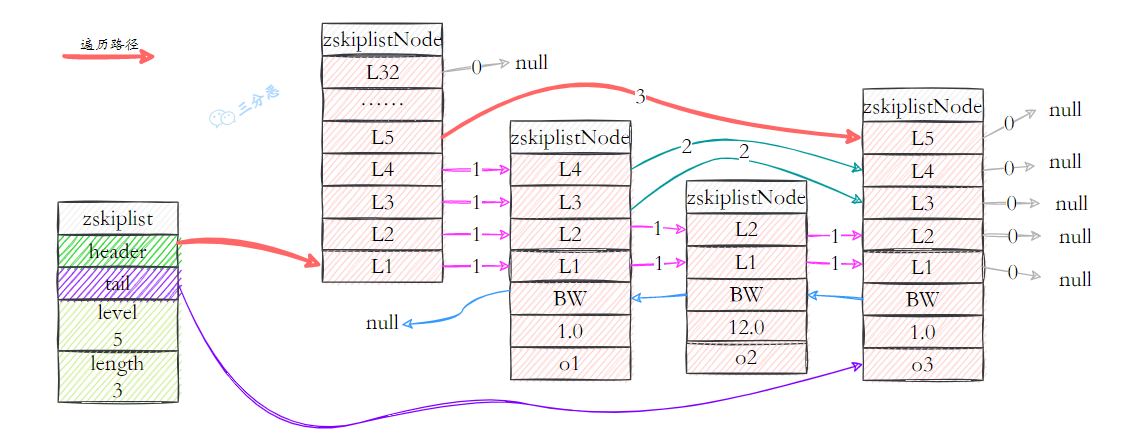
- 分值和成员 节点的分值(score属性)是一个double类型的浮点数,跳跃表中所有的节点都按分值从小到大来排序。节点的成员对象(obj属性)是一个指针,它指向一个字符串对象,而字符串对象则保存这一个SDS值。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/564742
推荐阅读
相关标签

