
- 1python嵌套列表展示_创建学校演讲比赛复赛入围名单集合输入学生姓名查询该学生在不在入围名单中使
- 27-java连接oracle-Oracle中的事务处理_java取oracle序列需要事务吗
- 3【Flutter 实战】pubspec.yaml 配置文件详解
- 4python编译器安装第三方库,python编译器安装模块_python 编译模块
- 5git仓库迁移_git push --mirror
- 6安装faac-1.28报错 /bin/bash^M: bad interpreter: No such file or directory解决办法_输入bootstrap后no such
- 7oracle 19c CDB容器数据库监听和tns文件配置_oracle 19c listener.ora
- 8Java接入支付宝支付超级详细教程——从入门到精通_java接入支付宝自动扣费
- 9python:求素数_python求素数
- 10ERROR:node with name “rabbit“ already running on “XXX“_error: node with name "rabbit" already running on
Python课程设计项目-基于机器学习的糖尿病风险预警分析系统_机器学习风险预测毕业设计
赞
踩
这个东西是我大二时候做的,做的挺一般的,当时也没想着搭建界面啥的,测试的也不够,就是单纯的分享一下吧,不足之处大家多多指正,我会把所有的代码和数据在文章最后都放出来,喜欢的话点个赞吧!
[摘 要] 糖尿病是一种全球性的流行性疾病,随着经济生活的高速发展,其患病率急剧增高,已成为威胁人类健康的第三大杀手。糖尿病目前尚不能根治,一旦发生,将终身相伴。糖尿病注重细节管理,尤其是在饮食方面有严格要求,为此,患者将会失去很多生活乐趣和行动自由;糖尿病的慢性并发症具有高度致残性,严重者会对患者的生活和工作造成不利影响;来自于健康和经济的双重压力,给患者本人及其家属造成巨大的精神负担,据统计,糖尿病患者中心理障碍(如抑郁症)的发病率可高达30%-50%,上述种种情况,使患者的生活质量大大降低。为帮助解决糖尿病给患者带来的巨大痛苦,建立起联防预警机制,及时筛查出具有患病风险的高危人群,本系统选取了皮马印第安人糖尿病数据集,利用Python中的随机森林、决策树、逻辑回归等多种机器学习算法,构建起糖尿病风险预警系统,用户可将自身信息输入到系统中,系统会自动分析是否具有糖尿病的风险,为用户和医生进行健康筛查提供帮助。
基于机器学习的糖尿病风险预警分析系统
引言
世界卫生组织近日发布报告称,糖尿病患者的数量正以惊人的速度增长,目前全球每年约有320万人死于糖尿病导致的并发症。高血糖本身并不可怕,真正可怕的是糖尿病所致的各种并发症。如果控制不好的话,患者从头到脚、由内到外、从肉体到精神几乎无一幸免,其对患者的影响是多方面的、严重的和终身性的,与之相伴的还有长期高额的医疗支出,但最终患者还是难逃致残和早亡的结局,说糖尿病是“百病之源”可谓实至名归。
第一章 项目意义
1.1 项目背景
1.1.1 糖尿病发展现状
世界卫生组织近日发布报告称,糖尿病患者的数量正以惊人的速度增长,目前全球每年约有320万人死于糖尿病导致的并发症。报告指出,在大部分发展中国家,每10名35-64岁的成年人中至少有1人死于糖尿病,糖尿病已经成为大多数国家居民早逝的主要死因之一。据统计,糖尿病可使患者平均寿命缩短10年。
糖尿病目前尚不能根治,一旦发生,将终身相伴;糖尿病注重细节管理,尤其是在饮食方面有严格要求,为此,患者将会失去很多生活乐趣和行动自由;糖尿病的慢性并发症具有高度致残性,严重者会对患者的生活和工作造成不利影响;来自于健康和经济的双重压力,给患者本人及其家属造成巨大的精神负担,据统计,糖尿病患者中心理障碍(如抑郁症)的发病率可高达30%-50%。上述种种情况,使患者的生活质量大大降低。
1.1.2 糖尿病危害
糖尿病给各国政府和人民带来了沉重的经济负担。以美国为例,1987年用于治疗糖尿病的花费是240亿美元,1998年为980亿,2002年上升至1320亿美元。糖尿病患者的年人均医疗消费是10071美元,而非糖尿病患者人均花费则为2699美元。在中国,2002年17省会城市调查显示,糖尿病治疗费188.2亿人民币,约占卫生事业费占4%;普通糖尿病患者每人每年平均花费3726元,有并发症的糖尿病患者每人每年平均花费高达13897元。
在糖尿病的早期阶段,患者除了血糖偏高以外,可能没有任何症状,但如果因此而满不在乎、放松治疗,持续的高血糖可能在不知不觉中,侵蚀您全身的大、小血管及神经,引起体内各个组织器官的病变,导致各种急、慢性并发症,严重者可致残、致死。
1、急性并发症
以糖尿病酮症酸中毒和非酮症高渗性昏迷最为常见,前者多见于1型糖尿病及处于应激状态(如急性感染、急性脑卒中、精神刺激、外伤、手术、暴饮暴食)的2型糖尿病,后者多见于老年患者。急性并发症往往来势汹汹,如果不能及时救治,病死率很高。随着现代医疗水平的提高,尤其是胰岛素的广泛应用,急性并发症的发病率及病死率较以往显著下降。
2、慢性并发症
与急性并发症相比,如今慢性并发症发生率越来越高,已成为糖尿病患者致残、致死的首要因素。
(1)心脏病变。糖尿病可引起冠状动脉硬化、狭窄和堵塞,导致冠心病(心绞痛、心肌梗死)、糖尿病心肌病,甚至猝死。糖尿病引起的心脏病尽管病情较重但症状却往往不典型,无痛性心肌梗死较为多见。糖尿病心肌病最常见的症状是心脏扩大及心律失常,后期则出现心力衰竭。糖尿病患者发生心肌梗死的危险比非糖尿病患者高3-4倍。
(2)脑血管病变。主要是脑血栓,脑出血则相对少见。轻者出现半身麻木或活动不灵,重则导致瘫痪、神志不清、深昏迷,危及生命。糖尿病患者发生脑卒中者的危险是非糖尿病患者的2-4倍。
(3)肾脏损害。是糖尿病最常见的微血管并发症之一。在早期阶段,患者症状常不明显,尿微量白蛋白排泄率增加是其唯一表现,很容易被忽略,以后随着肾小球滤过率下降,体内代谢废物不能排出,血肌酐及尿素氮开始升高,并出现临床症状,病情进一步发展可导致尿毒症。
有资料显示,微量白蛋白尿的出现率在病程10年和20年后可分别达到10%-30%和40%,且20年后有5%-10%的患者进展为尿毒症,糖尿病患者发生尿毒症的危险性是非糖尿病患者的17倍,在接受透析的终末期肾病患者中有一半是糖尿病患者。
(4)视网膜病变和白内障。视网膜病变最为多见,早期可无任何症状,随着病情进展,导致眼底反复出血、视力明显减退,严重时可导致失明。糖尿病致失明的危险性为非糖尿病患者的25倍。我国资料报道,病程在10年的糖尿病患者有50%发生视网膜病变,病程15年以上者有80%发生视网膜病变,而2%的患者将完全失明。
(5)神经损害。神经病变神经病变患病率在糖尿病病程为5年、10年、20年后分别可达到30%-40%、60%-70%和90%。感觉神经受损,患者可出现四肢麻木疼痛、感觉丧失、无痛性心肌梗死;自主神经受损可出现静息心率增快、直立性低血压、出汗异常、胃轻瘫、膀胱尿潴留、便秘、腹泻等症状。
(6)糖尿病足。由于长期高血糖造成下肢血管病变及神经损害,并在此基础上合并感染,导致下肢溃疡及坏疽,病情严重者需要截肢。据统计,因糖尿病足坏疽而截肢者为非糖尿病患者的20倍。据美国相关资料统计,成年截肢患者当中,有40%是糖尿病足坏疽所致,危害性极大。
(7)各种感染。糖尿病患者由于抵抗力差,容易并发呼吸道及泌尿道感染、肺结核、皮肤黏膜感染及牙周炎。
(8)对孕产妇及胎儿的损害。如果血糖控制不好,糖尿病孕妇易出现流产、胎儿发育畸形、死胎、新生儿低血糖等妊娠并发症,母亲及胎儿死亡率均较高。
1.2 项目意义与目标
我国的糖尿病患者初诊时约80%已出现慢性并发症,而无并发症的患者约 75%以上尚未被明确诊断,未能做到早期诊断、早期治疗。资料显示 ,由于我国患者病情控制差,绝大部分病人临床诊断时已经出现并发症,因肾、眼、心脑血管、足等病变的致残率及死亡率,均明显高于国外。其中缺乏糖尿病风险预警机制是主要原因之一。
如果开展有效的糖尿病风险预警机制,让患者及时了解自己的身体状况,及时就医,那么大部分患者可以获得早期治疗。现在的许多研究已经证实:有效的病情控制 ,可以减少或延缓并发症的发生、发展,降低致残率,提高患者的生活质量,延长患者的寿命。因此,有效的糖尿病风险预警机制,可取得巨大的社会效益。
本研究在充分调研的前提下,利用皮马印第安人糖尿病数据集,利用Python中的随机森林、决策树、逻辑回归等多种机器学习算法,构建起糖尿病风险预警系统,用户可将自身信息输入到系统中,系统会自动分析是否具有糖尿病的风险,为用户和医生进行健康筛查提供帮助。
第二章关键技术与方法
2.1随机森林算法
作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。
随机森林其本质就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,其实这也是随机森林的主要思想——集成思想的体现。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
随机森林作为一种很灵活实用的方法,它有如下几个特点:
1.在当前所有算法中,具有极好的准确率;
2.能够有效地运行在大数据集上;
3.能够处理具有高维特征的输入样本,而且不需要降维;
4.能够评估各个特征在分类问题上的重要性;
5.在生成过程中,能够获取到内部生成误差的一种无偏估计;
6.对于缺省值问题也能够获得很好得结果。
2.2决策树算法
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构建决策树来进行分析的一种方式,是一种直观应用概率分析的一种图解法。决策树,顾名思义需要构建树的结构来进行决策(分类);其实决策树的工作过程和人的思考过程是比较类似的,人类在决策过程中,会基于一系列的判别标准,来对某一事务做出最终的决定。决策树正是基于这一思想,在对数据进行分类的时候,判别标准就是数据的特征,最终的决定就是数据的类别。
首先介绍信息熵(entropy)的概念,信息熵主要用来衡量样本集合的“混乱程度”,度量事物的不确定性。信息熵越大代表样本集合越混乱,不确定性越高,其计算方式如下:
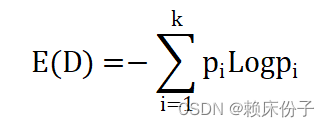
D代表样本集合;样本集合中数据可以分为k个类别,每个类别的概率为Pi。样本集合中,如果所有的样本均属于同一类别,那么此时“混乱程度”最低,信息熵为0,取到最小值;样本集合中,如果所有类别的样本概率相同,那么此时“混乱程度”最高,信息熵为logk,取到最大值。
2.3逻辑回归算法
逻辑回归虽然带有回归两字,但实际上是做分类任务的,并且是一个经典的二分类算法。在选择使用机器学习算法的时候,通常考虑的就是逻辑回归算法,再去考虑另外复杂的算法,也就是说能用简单的还是用简单的算法。在机器学习中,算法不是越复杂越好,而是要简单、高效、通俗易懂。
逻辑回归其实是一个分类算法而不是回归算法。通常是利用已知的自变量来预测一个离散型因变量的值(像二进制值0/1,是/否,真/假)。简单来说,它就是通过拟合一个逻辑函数(logit fuction)来预测一个事件发生的概率。所以它预测的是一个概率值,自然,它的输出值应该在0到1之间。
逻辑回归算法原理可以概括为以下几个方面:
- 找一个合适的预测函数(Andrew Ng的公开课中称为hypothesis),一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程时非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
- 构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
逻辑回归算法公式为:
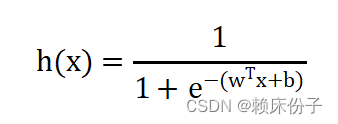
假设有N个样本,样本标签只有0和1两类可以用极大似然估计法估计模型参数,从而得到逻辑回归模型。设yi=1的概率为pi, yi=0的概率为1-pi,那么观测的概率为:
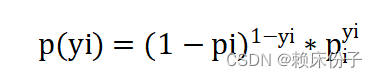
概率由逻辑回归的公式求解,那么带进去得到极大似然函数:
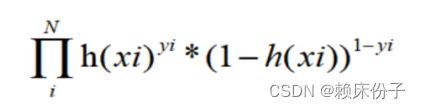
最终导数变为:
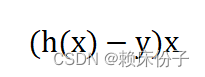
逻辑回归具有以下优点:
1.形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
2.模型效果好。在工程上是可以接受的,如果特征工程做的好,效果不会太差,并且特征工程可以并行开发,大大加快开发的速度。
3.训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型。
4.资源占用小,尤其是内存。因为只需要存储各个维度的特征值。
5.方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果。
2.4 KNN算法
KNN最邻近分类算法的实现原理为:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
KNN算法的关键:
1.样本的所有特征都要做可比较的量化,若是样本特征中存在非数值的类型,必须采取手段将其量化为数值
2.样本特征要做归一化处理,样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些 scale 处理,最简单的方式就是所有特征的数值都采取归一化处置。
3.需要一个距离函数以计算两个样本之间的距离,通常使用的距离函数有:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
2.5 神经网络算法(Neural Network)
神经网络模型是模拟人类神经网络工作原理进行自我学习和演化的一种数据工作方法。神经网络在系统辨识、模式识别、智能控制等领域应用广泛,尤其在智能控制中被视为解决自动控制中控制器适应能力这个难题的关键钥匙之一。
神经网络理论是巨量信息并行处理和大规模平行计算的基础,是高度非线性动力学系统,又是自适应组织系统,可用来描述认知、决策及控制的智能行 为.它的中心问题是智能的认知和模拟,更重要的是它具有“认知”、“意识”和“感情”等高级大脑功能。它再一次拓展了计算概念的内涵,使神经计算、进化计算成为新的学科,神经网络的软件模拟得到了广泛的应用。
2.6 XGBoost算法
XGBoost是2014年2月诞生的专注于梯度提升算法的机器学习函数库,此函数库因其优良的学习效果以及高效的训练速度而获得广泛的关注。XGBoost不仅学习效果很好,而且速度也很快,相比梯度提升算法在另一个常用机器学习库scikit-learn中的实现,XGBoost的性能经常有十倍以上的提升。XGBoost算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
第三章 项目设计与实现
3.1 项目总体设计
在本次系统的开发过程中,首先要先获取到源数据集,根据数据集中的信息对数据进行清洗与降维处理,保证数据的完整性与一致性;在完成数据集的处理后,就可以在PyCharm中设计机器学习算法模型了,本着对患者负责的心态以及保证分析结果的准确性的目的,在系统中设计了多个算法同时进行预测,并进行多维分析验证;最后设计用户主界面,使用户可以在此界面输入个人身体信息,系统会将信息传递到后台的算法模型当中进行分析,最后给出预测结论。

图3.1-1:项目总体设计
3.2 数据获取
在本次系统设计中采用的数据集来自阿里天池数据集,数据来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=88343,这个数据集的原始数据来自国家糖尿病消化和肾病机构。数据集的目的是基于数据集中确定的诊断测量指标来预测一个患者是否患有糖尿病。在从更大的数据库中选择这些实例时受到了一些限制。特别是,所有收录于数据集的患者都是至少21周岁的皮马印第安女性。数据集包括多个医学预测变量和一个目标变量。预测变量包括患者的怀孕次数,她们的BMI指数,胰岛素水平,年龄等。
3.3 数据清洗
数据清洗概念就是去重,检查数据一致性,处理无效值和缺失值等,删除重复信息,纠正存在的错误。就是缺失值进行清洗、确定缺失值范围(对每个字段都计算其缺失值比例,然后按照缺失值比例和字段重要性,分别制定策略)、去除不需要的字段(清洗每做一步时都备份一下,或者在小规模数据上试验成功再处理全量数据)填充缺失内容(以业务知识或经验推测填充缺失值、以同一指标的计算结果(均值,中位数,众数等)填充缺失值)、重新取数(如果某些指标非常重要又缺失率高,需要和数据获取人员了解,是否有其他渠道取到相关数据)。
首先将目标数据集导入到程序中,查看数据的基本情况,这里采用了Pandas中的read.csv()方法将数据导入,并打印出数据所有记录。在查看的过程中发现Glucose、BloodPressure、SkinThickness、Insulin、BMI这5个维度存在缺失现象,对于数据的缺失情况,程序中采用了中值补全的方式,将数据的缺失值补全。
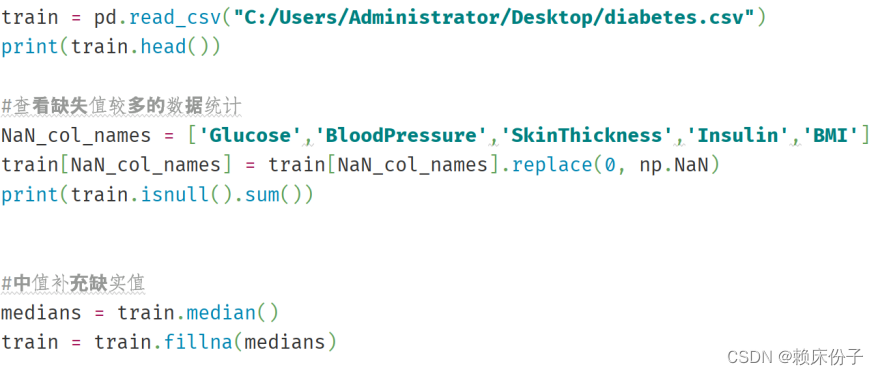
图3.3-1:缺失值补全代码展示
在完成补全操作以后,程序中还引入了sklearn中的StandardScaler库对数据进行数据标准化操作,最后将文件保存到电脑上,至此完成数据清洗操作。
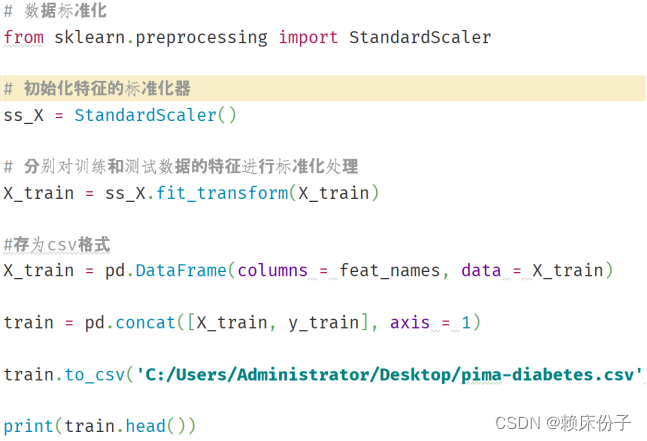
图3.3-2:数据标准化代码设计
3.4 机器学习算法实现
首先,根据所要根据前面选择的算法挑选第三方库,在这里先要导入numpy、pandas等基础库作为基础支撑,其次随机森林、决策树、逻辑回归、KNN、神经网络算法需要在sklearn中进行引入操作,对于xgboost算法模型则需要单独安装和引入。
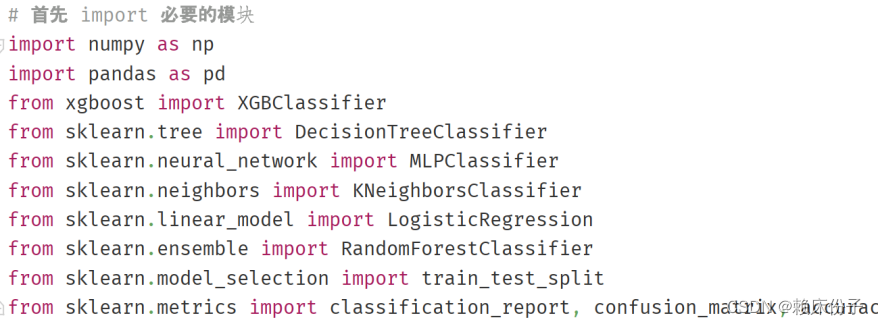
3.4.1 随机森林算法实现
在随机森林算法的实现过程中首先算法所需的变量进行赋值,并划分训练集与测试集。由于数据集较小,共有768条记录,所以在这里选取了738条记录作为训练集,30条记录作为测试集。在拿到训练集后需要调用RandomForestClassifier()随机森林分类器对数据进行训练,系统在完成训练后会导入测试集对算法模型进行测试,输出随机森林算法的算法准确率以及对算法预测结构与真实结果之间的对比,给出算法评分,具体代码如图3.4.1-1所示。

图3.4.1-1:随机森林算法代码展示
代码运行后可以看到随机森林算法的准确率在90%左右,具有较高的准确性,应用于糖尿病预警分析中具有良好效果。
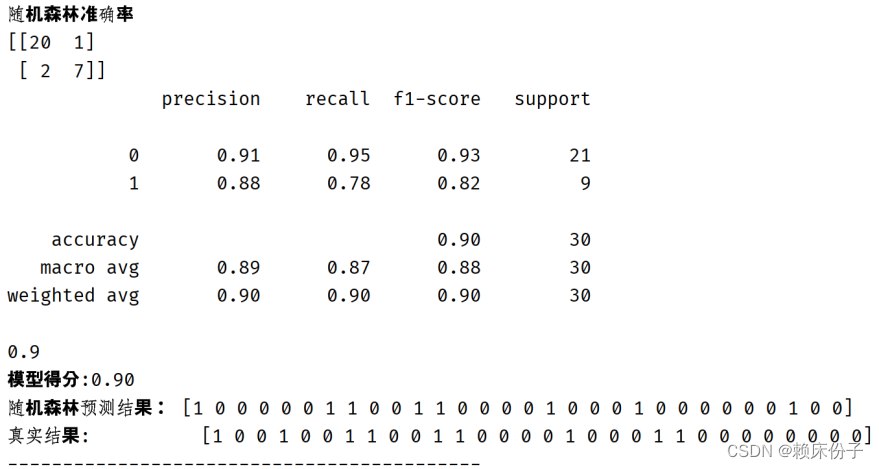
图3.4.1-2:随机森林算法结构展示
3.4.2 决策树算法实现
决策树的代码实现于前面随机森林的设计过程类似,不同之处在于算法训练中使用了DecisionTreeClassifier()决策树分类器,其余部分大同小异本文不再过多赘述,将中心集中于算法所实现的结果展示,决策树代码如图3.4.2-1所示。
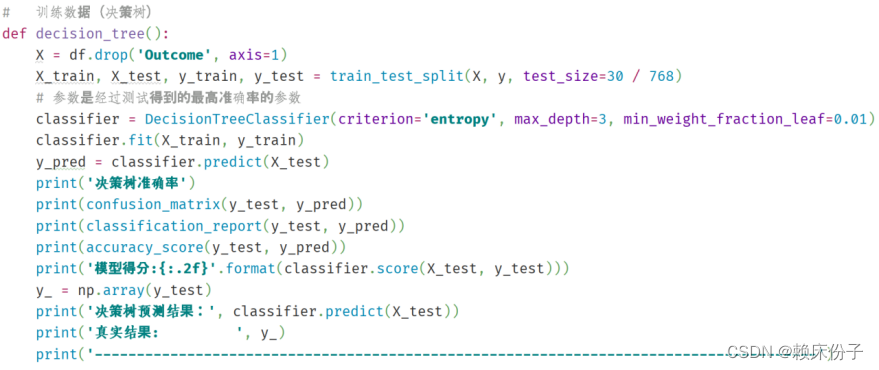
图3.4.2-1:决策树代码展示
对于决策树算法最终得分为0.77,从整体上来看算法准确率偏低,在糖尿病的研究中并不适用。
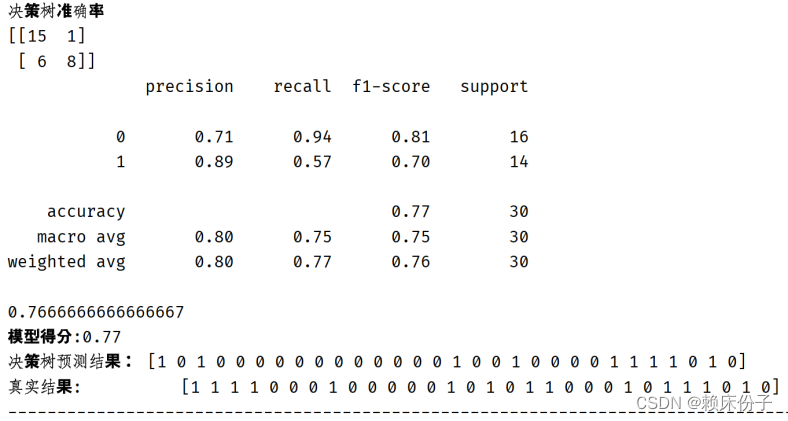
图3.4.2-2:决策树算法实现
3.4.3逻辑回归算法实现
就逻辑回归算法的实现结果来看,算法准确率达到了0.93,在算法评级中属于较高的水平,在诊断预测上可以作为重要的参考依据。
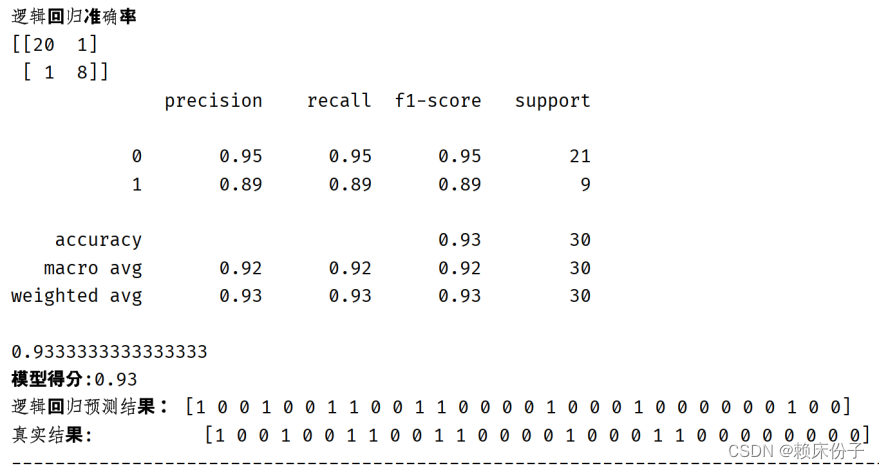
图3.4.3-1:逻辑回归算法实现
3.4.4 KNN算法实现
在KNN算法对数据集的预测分析中,由于无法在一开始就确定K取何值时准确率最高,所以在程序中采用了循环遍历的方式寻找K值,共遍历14次(K值取1-15),如图3.4.4-1所示。

图3.4.4-1:KNN算法程序设计
经过测试以后可以看到KNN算法在K=1时,算法准确率为0.8,为KNN算法在训练中准确率的最小值,如图3.4.4-2所示;而当K=14时,KNN算法的准确率达到了0.9,为KNN算法在训练中的最大值,如图3.4.4-3所示。可见KNN算法准确率受K值影响较大,需要多次进行拟合测试。
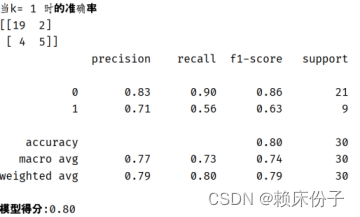
图3.4.4.2:k=1时KNN算法准确率
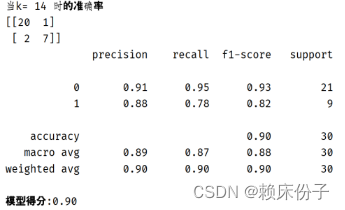
图3.4.4-3:k=14时KNN算法准确率
3.4.5神经网络算法实现
从图3.4.5-1中可知神经网络模型的准确率为0.77,与决策树算法相差不大。
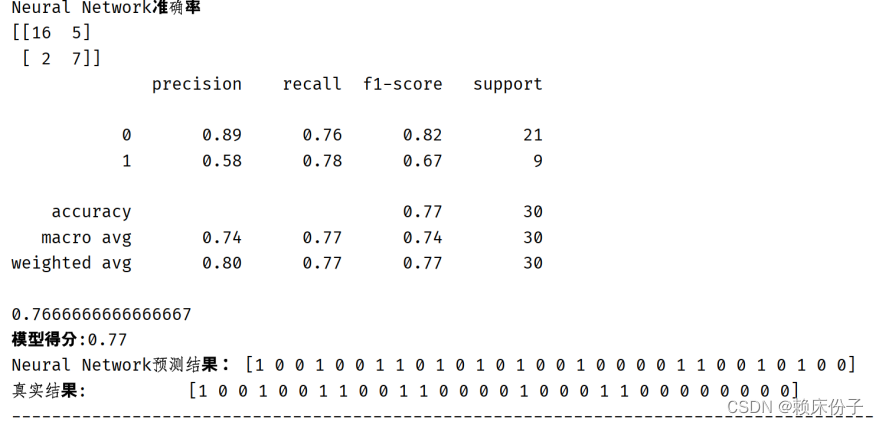
图3.4.5-1:神经网络算法实现
3.4.6 XGBoost算法实现
对于XGBoost算法而言,其算法准确率达到了0.93,如图3.4.6-1所示。XGBoost算法在糖尿病预警分析系统的算法选择以及权重分配上无疑要居于首位。
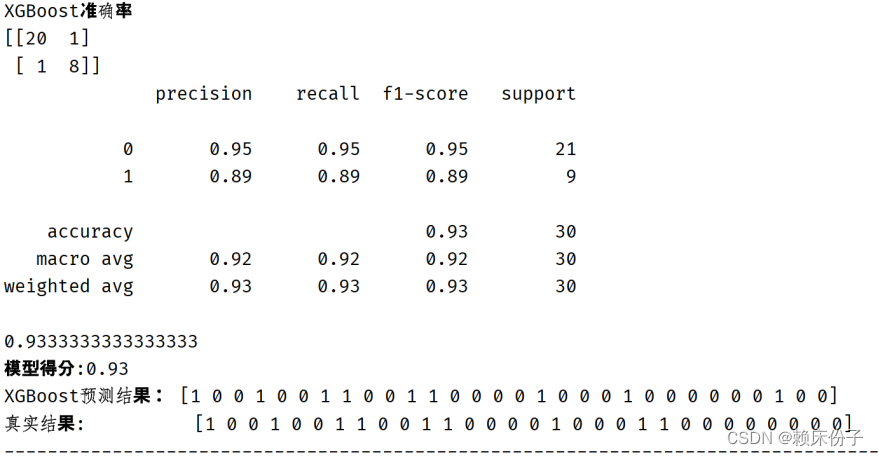
图3.4.6-1:XGBoost算法结果展示
3.5主程序设计
根据系统需求分析,用户在打开系统界面时,首先要在主界面输入自己的身体信息,系统会检测输入信息,如果出现信息缺失或其他异常因素时,系统会给出提升并让用户重新输入信息。在接收到正确的信息后,系统会将用户信息传递到后台变量上,交给算法模型进行分析,最后给出用户的糖尿病风险情况。

图3.5-1:主程序设计
3.6系统测试
在系统开发的最后,在程序中追加了糖尿病风险预警程序,当用户输入身体信息,后台算法模型训练结束后,风险预警程序默认为当算法模型给出算法准确率大于0.8时,则认为该用户有患上糖尿病的风险。在系统测试中,选取了源数据集中的第一条数据进行系统测试。

图3.6-1:系统测试
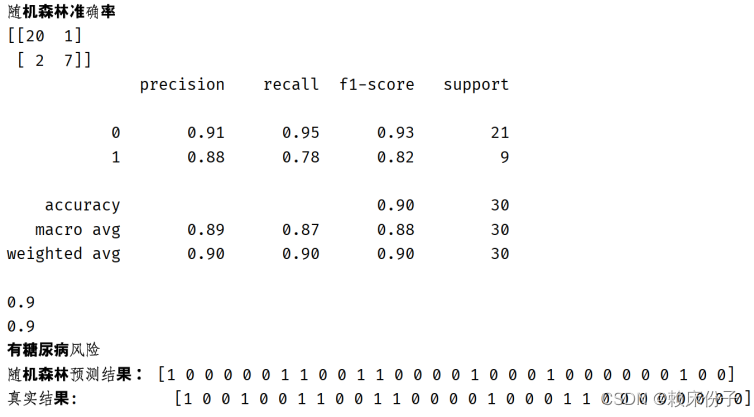
图3.6-2:随机森林算法测试
剩下的大家自己测吧...
结论
由于社会公众缺乏对糖尿病的认识和预防意识,他们不知道如何预防糖尿病,得了糖尿病又不能及时检查和治疗。此外,糖尿病是一种慢性终身性疾病,需要坚持长期的治疗。病因的复杂性、治疗措施的综合性和个体化都需要得到患者的主动参与,提高糖尿病患者的自觉性和主动配合,以达到良好的代谢控制,才能避免和延缓糖尿病慢性并发症的发生与发展,也可降低医疗费用。因此,提取做好糖尿病的筛查与预警尤为重要,本系统基于机器学习算法,为用户提供了一个可以自行筛查糖尿病的预警系统,可以让用户早发现,早治疗,避免诸多糖尿病以及并发症的困扰,提高每一位患者的生活质量。
数据来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=88343
一代源代码
- # 首先 import 必要的模块
- import numpy as np
- import pandas as pd
- from xgboost import XGBClassifier
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.neural_network import MLPClassifier
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.linear_model import LogisticRegression
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
-
- pd.set_option('display.max_rows', 10)
- pd.set_option('display.max_columns', 10)
- pd.set_option('display.width', 1000)
-
- # 导入csv数据
- df = pd.read_csv("C:/")
-
- # x为可能导致糖尿病的因素
- x = df.drop('Outcome', axis=1)
- # y为诊断结果,1为确诊,2为未确诊
- y = df['Outcome']
-
-
- # 训练数据(随机森林)
- def random_forest():
- # 将数据标准化
- X = df.drop('Outcome', axis=1)
- # 一共768个数据738个作为训练集,30个作为测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- # 若数值过大可以标准化,这里数值不算大,标准化后准确值较低,所以注释掉了不进行标准化
- classifier = RandomForestClassifier(criterion='entropy', n_estimators=1000, max_depth=None, min_samples_split=10,
- min_weight_fraction_leaf=0.02)
- classifier.fit(X_train, y_train)
- y_pred = classifier.predict(X_test)
- print('随机森林准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- print('模型得分:{:.2f}'.format(classifier.score(X_test, y_test)))
- y_ = np.array(y_test)
- print('随机森林预测结果:', classifier.predict(X_test))
- print('真实结果: ', y_)
- print('-------------------------------------------')
-
-
- # 训练数据(决策树)
- def decision_tree():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768)
- # 参数是经过测试得到的最高准确率的参数
- classifier = DecisionTreeClassifier(criterion='entropy', max_depth=3, min_weight_fraction_leaf=0.01)
- classifier.fit(X_train, y_train)
- y_pred = classifier.predict(X_test)
- print('决策树准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- print('模型得分:{:.2f}'.format(classifier.score(X_test, y_test)))
- y_ = np.array(y_test)
- print('决策树预测结果:', classifier.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 训练数据(逻辑回归)
- def logistic_regression():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- lr = LogisticRegression(random_state=0, max_iter=1000)
- lr.fit(X_train, y_train)
- y_pred = lr.predict(X_test)
- print('逻辑回归准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- print('模型得分:{:.2f}'.format(lr.score(X_test, y_test)))
- y_ = np.array(y_test)
- print('逻辑回归预测结果:', lr.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 训练数据(KNN)寻找最佳的k值
- def k_nn():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- error = []
- # 由于一开始并不清楚K取多少准确率最高,所以写了一个K为1-14的for循环,通过检查误差值来判断最合适的K值
- for k in range(1, 15):
- classifier = KNeighborsClassifier(n_neighbors=k)
- classifier.fit(X_train, y_train)
- y_prediction = classifier.predict(X_test)
- error.append(np.mean(y_prediction != y_test))
- print('当k=', k, '时的准确率')
- print(confusion_matrix(y_test, y_prediction))
- print(classification_report(y_test, y_prediction))
- print('模型得分:{:.2f}'.format(classifier.score(X_test, y_test)))
- print('--------------------------------------------------------------------------------------')
-
-
- def n_n():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- mlp = MLPClassifier(random_state=0, max_iter=5000)
- mlp.fit(X_train, y_train)
- y_pred = mlp.predict(X_test)
- print('Neural Network准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- print('模型得分:{:.2f}'.format(mlp.score(X_test, y_test)))
- y_ = np.array(y_test)
- print('Neural Network预测结果:', mlp.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- def xgb():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- xgb = XGBClassifier(gamma=0, use_label_encoder=False, learning_rate=0.01, max_depth=10, n_estimators=10000, random_state=34, reg_lambda=6, reg_alpha=3, verbosity=0)
- xgb.fit(X_train, y_train)
- y_prediction = xgb.predict(X_test)
- print('XGBoost准确率')
- print(confusion_matrix(y_test, y_prediction))
- print(classification_report(y_test, y_prediction))
- print(accuracy_score(y_test, y_prediction))
- print('模型得分:{:.2f}'.format(xgb.score(X_test, y_test)))
- y_ = np.array(y_test)
- print('XGBoost预测结果:', xgb.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 主菜单
- def main_menu():
- print('-' * 11, '糖尿病诊断预测', '-' * 11)
- print('|{:20}|{:20}|'.format('1.输入指标', '2.退出系统'))
-
-
- # 选择模型菜单
- def option_menu():
- print('-' * 11, '训练模型选择', '-' * 11)
- print('|{:20}|{:20}|'.format('1.所有模型', '2.随机森林'))
- print('|{:20}|{:20}|'.format('3.决策树', '4.逻辑回归'))
- print('|{:23}|{:20}|'.format('5.KNN', '6.连接模型'))
- print('|{:23}|'.format('7.XGBoost'))
-
-
- # 登出
- def logout():
- print('感谢使用')
-
- if __name__ == '__main__':
- while True:
- main_menu()
- key = input('请输入你的选择: ')
- if key == '1':
- try:
- Pregnancy = float(input('输入怀孕指数:'))
- Glu = float(input('输入葡萄糖指数:'))
- BP = float(input('输入血压:'))
- ST = float(input('输入皮肤厚度:'))
- Ins = float(input('输入胰岛素指数:'))
- BMI = float(input('输入体质指数:'))
- DBF = float(input('输入糖尿病谱系功能指数:'))
- Age = float(input('输入年龄:'))
- except:
- print("不符合输入要求,请重新输入")
- continue
- # 将输入的值放在一个列表中
- indices = [Pregnancy, Glu, BP, ST, Ins, BMI, DBF, Age]
- l = []
- for index in indices:
- l.append(index)
-
- empty_indices = {"Pregnancies": l[0], "Glucose": l[1], "BloodPressure": l[2], "SkinThickness": l[3], "Insulin": l[4], "BMI": l[5], "DiabetesPedigreeFunction": l[6], "Age": l[7]}
- data = pd.DataFrame(empty_indices, index=[0])
- data = data.set_index('Pregnancies')
- data.to_csv("new.csv")
- df_1 = pd.read_csv("new.csv")
- s = df_1.iloc[0]
- # 选择模型菜单
- option_menu()
- option = input('请选择模型:')
- # 显示所有的训练模型结果
- if option == '1':
- random_forest()
- decision_tree()
- logistic_regression()
- k_nn()
- n_n()
- xgb()
- elif option == '2':
- random_forest()
- elif option == '3':
- decision_tree()
- elif option == '4':
- logistic_regression()
- elif option == '5':
- k_nn()
- elif option == '6':
- n_n()
- elif option == '7':
- xgb()
- else:
- print('无效输入')
- continue
- elif key == '2':
- logout()
- break
- else:
- print('无效输入')

改进源代码
- import numpy as np
- import pandas as pd
- from xgboost import XGBClassifier
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.neural_network import MLPClassifier
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.linear_model import LogisticRegression
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
-
- pd.set_option('display.max_rows', 10)
- pd.set_option('display.max_columns', 10)
- pd.set_option('display.width', 1000)
-
- # 导入csv数据
- df = pd.read_csv("C:/")
-
- # x为可能导致糖尿病的因素
- x = df.drop('Outcome', axis=1)
- # y为诊断结果,1为确诊,2为未确诊
- y = df['Outcome']
-
-
- # 训练数据(随机森林)
- def random_forest():
- # 将数据标准化
- X = df.drop('Outcome', axis=1)
- # 一共768个数据738个作为训练集,30个作为测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- # 若数值过大可以标准化,这里数值不算大,标准化后准确值较低,所以注释掉了不进行标准化
- classifier = RandomForestClassifier(criterion='entropy', n_estimators=1000, max_depth=None, min_samples_split=10,
- min_weight_fraction_leaf=0.02)
- classifier.fit(X_train, y_train)
- y_pred = classifier.predict(X_test)
- print('随机森林准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- a = format(classifier.score(X_test, y_test))
- print(a)
- if float(a) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
- y_ = np.array(y_test)
- print('随机森林预测结果:', classifier.predict(X_test))
- print('真实结果: ', y_)
- print('-------------------------------------------')
-
-
- # 训练数据(决策树)
- def decision_tree():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768)
- # 参数是经过测试得到的最高准确率的参数
- classifier = DecisionTreeClassifier(criterion='entropy', max_depth=3, min_weight_fraction_leaf=0.01)
- classifier.fit(X_train, y_train)
- y_pred = classifier.predict(X_test)
- print('决策树准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- b = format(classifier.score(X_test, y_test))
- print(b)
- if float(b) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
- print(format(classifier.score(X_test, y_test) < 0.8))
- y_ = np.array(y_test)
- print('决策树预测结果:', classifier.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 训练数据(逻辑回归)
- def logistic_regression():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- lr = LogisticRegression(random_state=0, max_iter=1000)
- lr.fit(X_train, y_train)
- y_pred = lr.predict(X_test)
- print('逻辑回归准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- c = format(lr.score(X_test, y_test))
- print(c)
- if float(c) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
- y_ = np.array(y_test)
- print('逻辑回归预测结果:', lr.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 训练数据(KNN)寻找最佳的k值
- def k_nn():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- error = []
- # 由于一开始并不清楚K取多少准确率最高,所以写了一个K为1-14的for循环,通过检查误差值来判断最合适的K值
- for k in range(1, 15):
- classifier = KNeighborsClassifier(n_neighbors=k)
- classifier.fit(X_train, y_train)
- y_prediction = classifier.predict(X_test)
- error.append(np.mean(y_prediction != y_test))
- print('当k=', k, '时的准确率')
- print(confusion_matrix(y_test, y_prediction))
- print(classification_report(y_test, y_prediction))
- d = format(classifier.score(X_test, y_test))
- print(d)
- if float(d) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
-
- # 训练数据(Neural Networks)
- def n_n():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- mlp = MLPClassifier(random_state=0, max_iter=5000)
- mlp.fit(X_train, y_train)
- y_pred = mlp.predict(X_test)
- print('Neural Network准确率')
- print(confusion_matrix(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- print(accuracy_score(y_test, y_pred))
- e = format(mlp.score(X_test, y_test))
- print(e)
- if float(e) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
- y_ = np.array(y_test)
- print('Neural Network预测结果:', mlp.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- #训练数据(XGBoost)
- def xgb():
- X = df.drop('Outcome', axis=1)
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=30 / 768, random_state=0)
- xgb = XGBClassifier(gamma=0, use_label_encoder=False, learning_rate=0.01, max_depth=10, n_estimators=10000, random_state=34, reg_lambda=6, reg_alpha=3, verbosity=0)
- xgb.fit(X_train, y_train)
- y_prediction = xgb.predict(X_test)
- print('XGBoost准确率')
- print(confusion_matrix(y_test, y_prediction))
- print(classification_report(y_test, y_prediction))
- print(accuracy_score(y_test, y_prediction))
- f = format(xgb.score(X_test, y_test))
- print(f)
- if float(f) >= 0.8:
- print("有糖尿病风险")
- else:
- print("无糖尿病风险")
- y_ = np.array(y_test)
- print('XGBoost预测结果:', xgb.predict(X_test))
- print('真实结果: ', y_)
- print('--------------------------------------------------------------------------------------')
-
-
- # 主菜单
- def main_menu():
- print('-' * 11, '糖尿病诊断预测', '-' * 11)
- print('|{:20}|{:20}|'.format('1.输入指标', '2.退出系统'))
-
-
- # 选择模型菜单
- def option_menu():
- print('-' * 11, '训练模型选择', '-' * 11)
- print('|{:20}|{:20}|'.format('1.所有模型', '2.随机森林'))
- print('|{:20}|{:20}|'.format('3.决策树', '4.逻辑回归'))
- print('|{:23}|{:20}|'.format('5.KNN', '6.连接模型'))
- print('|{:23}|'.format('7.XGBoost'))
-
-
- # 登出
- def logout():
- print('感谢使用')
-
- if __name__ == '__main__':
- while True:
- main_menu()
- key = input('请输入你的选择: ')
- if key == '1':
- try:
- Pregnancy = float(input('输入怀孕指数:'))
- Glu = float(input('输入葡萄糖指数:'))
- BP = float(input('输入血压:'))
- ST = float(input('输入皮肤厚度:'))
- Ins = float(input('输入胰岛素指数:'))
- BMI = float(input('输入体质指数:'))
- DBF = float(input('输入糖尿病谱系功能指数:'))
- Age = float(input('输入年龄:'))
- except:
- print("不符合输入要求,请重新输入")
- continue
- # 将输入的值放在一个列表中
- indices = [Pregnancy, Glu, BP, ST, Ins, BMI, DBF, Age]
- l = []
- for index in indices:
- l.append(index)
-
- empty_indices = {"Pregnancies": l[0], "Glucose": l[1], "BloodPressure": l[2], "SkinThickness": l[3], "Insulin": l[4], "BMI": l[5], "DiabetesPedigreeFunction": l[6], "Age": l[7]}
- data = pd.DataFrame(empty_indices, index=[0])
- data = data.set_index('Pregnancies')
- data.to_csv("new.csv")
- df_1 = pd.read_csv("new.csv")
- s = df_1.iloc[0]
- # 选择模型菜单
- option_menu()
- option = input('请选择模型:')
- # 显示所有的训练模型结果
- if option == '1':
- random_forest()
- decision_tree()
- logistic_regression()
- k_nn()
- n_n()
- xgb()
- elif option == '2':
- random_forest()
- elif option == '3':
- decision_tree()
- elif option == '4':
- logistic_regression()
- elif option == '5':
- k_nn()
- elif option == '6':
- n_n()
- elif option == '7':
- xgb()
- else:
- print('无效输入')
- continue
- elif key == '2':
- logout()
- break
- else:
- print('无效输入')
数据清洗
- import numpy as np
- import pandas as pd
-
- train = pd.read_csv("C:/Users/Administrator/Desktop/diabetes.csv")
- print(train.head())
-
- #查看缺失值较多的数据统计
- NaN_col_names = ['Glucose','BloodPressure','SkinThickness','Insulin','BMI']
- train[NaN_col_names] = train[NaN_col_names].replace(0, np.NaN)
- print(train.isnull().sum())
-
-
- #中值补充缺实值
- medians = train.median()
- train = train.fillna(medians)
-
- print(train.isnull().sum())
-
-
- # get labels
- y_train = train['Outcome']
- X_train = train.drop(["Outcome"], axis=1)
-
- #用于保存特征工程之后的结果
- feat_names = X_train.columns
-
- # 数据标准化
- from sklearn.preprocessing import StandardScaler
-
- # 初始化特征的标准化器
- ss_X = StandardScaler()
-
- # 分别对训练和测试数据的特征进行标准化处理
- X_train = ss_X.fit_transform(X_train)
-
- #存为csv格式
- X_train = pd.DataFrame(columns = feat_names, data = X_train)
-
- train = pd.concat([X_train, y_train], axis = 1)
-
- train.to_csv('C:/Users/Administrator/Desktop/pima-diabetes.csv',index = False,header=True)
-
- print(train.head())
看到这里就点个赞吧(@-@)

