
- 1【AI工程论文解读】03-DevOps for AI-人工智能应用开发面临的挑战_devops ai
- 2c语言实现单链表(数据结构)_c语言单链表实现
- 3STM32固件库详解_一、st公司为stm32微控制器提供了哪些固件库,这些固件库各自的特点是什么
- 4Unicode详解(附UTF-8、UTF-16和UTF-32)_unicode值
- 5基于PRECHIN普中51-实验板学习—蜂鸣器相关学习(2)_普中单片机蜂鸣器
- 6uniapp小程序授权统一处理_uniapp authorize
- 7第18届全国大学生智能汽车竞赛四轮车开源讲解【12】--写在最后_江科大智能小车
- 8商汤杨帆:尺度定律主导AI迭代,降低门槛才能迎来AIGC应用爆发 | 中国AIGC产业峰会...
- 951单片机学习笔记_11 蜂鸣器,识简谱,根据简谱编写蜂鸣器代码_51单片机音律和音符节拍数组
- 10Flink 基础核心概念介绍_flink中的一些核心概念
bilstm+crf中文分词_最新中文NER模型介绍(二)
赞
踩
深度学习时代中文NER出现了LSTM、LSTM+CRF、BERT、BERT+CRF等方法,前期主要单纯基于字信息或词信息(词信息需要更多的训练文本)。基于字的方法很少考虑词,但词又包含了大量的信息,如何有效利用词信息是近两年中文NER的主要工作。
近期融合词信息工作主要可以分为结构融合和数据融合两类。结构融合通过调整模型结构融合词信息,数据融合主要通过多任务学习实现。
- 结构融合
>> Chinese NER Using Lattice LSTM
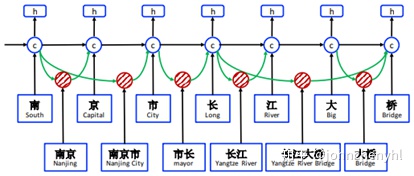
文章通过Lattice-LSTM结构将词信息融合和字信息中。Lattice-LSTM是在LSTM基础上改进而来,它允许节点能接收更远的信息,将模型从链式结构拓展到图式结构,如图1。具体实现,Lattice-LSTM将各种分词结果都引入到模型,词信息可以远程传入到节点中,最终路径通过模型自己探索。例如“桥”字,它有“桥”、“大桥”和“长江大桥”三种可能性,都建模在Lattice-LSTM中,关键实现步骤如图2。
Lattice-LSTM的优势在于能引入先验词信息,所以词信息越多越可能准确,但不足在于对于一些新词未必有效,另外batch size只能为1,所以训练比较慢。
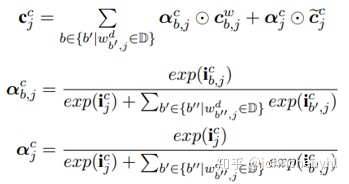
>> An Encoding Strategy Based Word-Character LSTM for Chinese NER
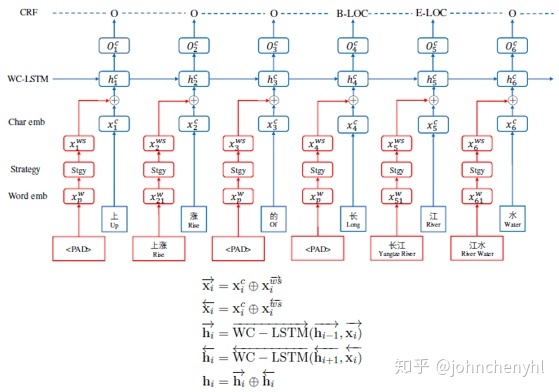
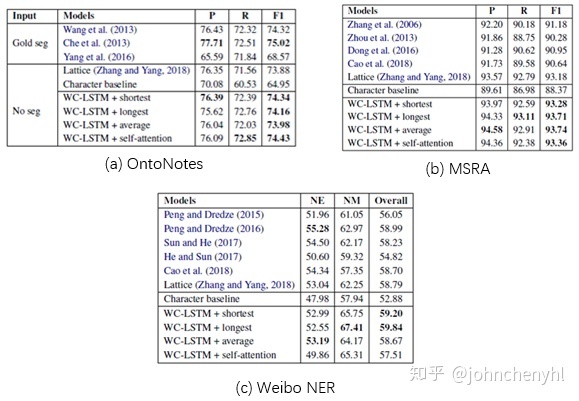
本文提出了WC-LSTM模型,它像是Lattice-LSTM模型的改进版。前面说到Lattice-LSTM有一个重要的不足是不支持batch,WC-LSTM解决了此问题。WC-LSTM也是一种Lattice-LSTM模型,不过它是一种特殊的Lattice-LSTM。Lattice-LSTM是否增加远程信息取决于是否有词信息,一个节点可能有零个或多个远程词信息,而WC-LSTM为每个节点都添加一个且仅一个远程词信息(如有没有分词就以<PAD>替代,如果有多个就以某种策略替代),这样就可以解决Lattice-LSTM因结构不统一不能batch的问题,如图3。WC-LSTM建模词信息有四种策略:Shortest Word First、Longest Word First、Average和Self-Attention。同样,WC-LSTM由于是直接引入词信息理论上应该也不能解决新词问题。从实验结果上看WC-LSTM都要优于Lattice-LSTM(如图4)。
>> A Neural Multi-digraph Model for Chinese NER with Gazetteers
本文利用一个多维图来融合词信息(如图5),它与Lattice-LSTM模型很类似,只不过所用结构不同而已。Lattice-LSTM是通过增加边来融合词信息,它将结构从链式转为图式;多维图模型是通过增加节点和边来融合词信息,它将结构从链式转为了多维图。在多维图模型中,节点有字和虚拟的词起点和终点。构建图后采用GRU的方式进行更新(如图6)。
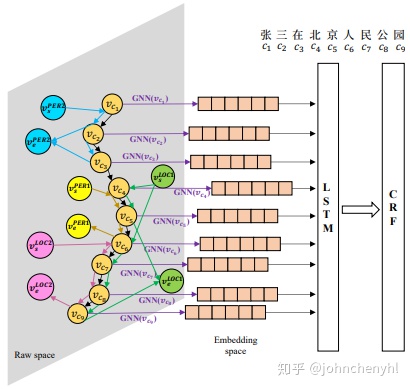
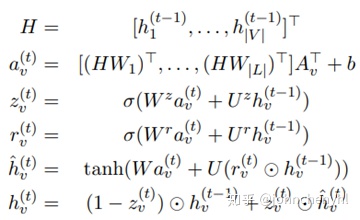
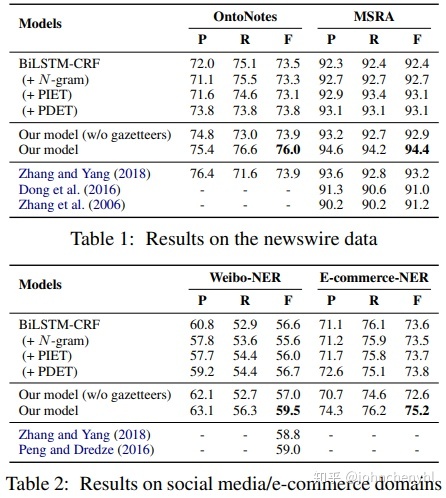
实验结果如图7,可以看到比Lattice-LSTM好一点。好奇的是从结构上没看到多维图模型比Lattice-LSTM有哪点好,只是结构不同以及更新方式不同而已,不知是否是在同一个词信息下做的比较。另外,多维图模型应该也不支持batch。
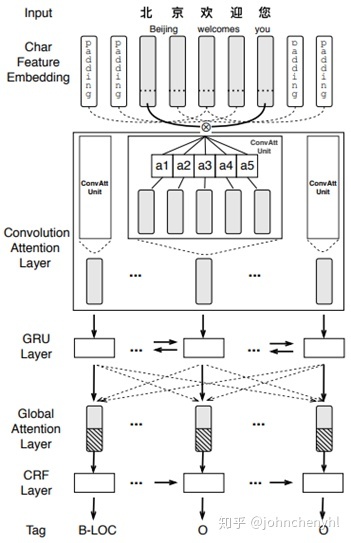
>> CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition
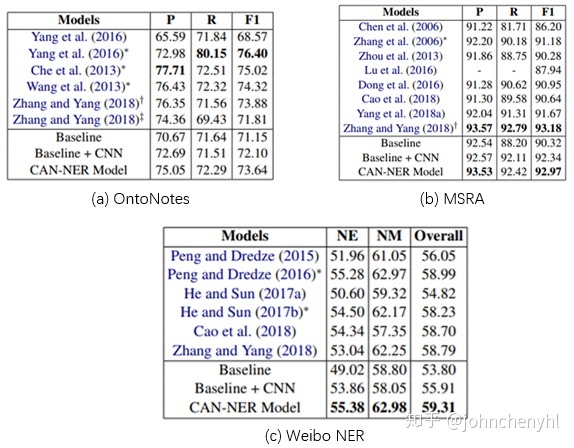
本文提出一个CAN结构来识别NER,如图8,先用Convolution Attention层建模token信息,然后用GRU建模token间关系。本文的重点在于用Convolution Attention和GRU结构建模信息,在融合词信息方面没有什么创新,就是直接concat,token的初始信息包含字信息和词标注信息(POS),然后让Convolution Attention自己探索字和词的信息。实验结果如图9所示,与图4相比,结果还是要弱一些。
- 数据融合
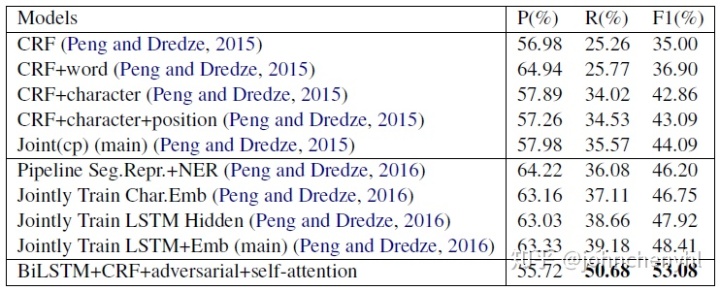
>> Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism
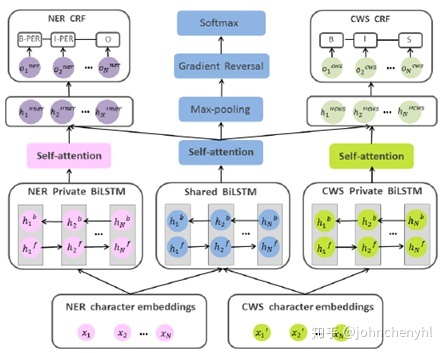
本文提出一个对抗迁移学习模型融合字信息和词信息。如图10,它用3个LSTM结构建模相关信息:一个基于字信息建模用于NER任务,一个基于词信息建模用于分词任务,一个共享结构同时建模字信息和词信息。整个学习过程采用对抗学习方式,本质上是一种多任务学习,在NER过程中融合分词,在分词过程中融合NER。与Lattice-LSTM的区别:1)它是将用于分词的信息融合到NER识别中,而Lattice-LSTM是将词先验信息融合到结构中;2)优点是能某些时候解决新词问题;3)缺点是如果分词信息有误会传导到NER任务中, Lattice-LSTM通过结构让模型自己去选择正确的分词路径。实验结果如图11,结果明显不如图4和图7。结果可以理解,结构融合是直接融合词先验知识,分词信息准确有效,数据融合是模型自己探索分词信息,有一定错误率。
>> Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation
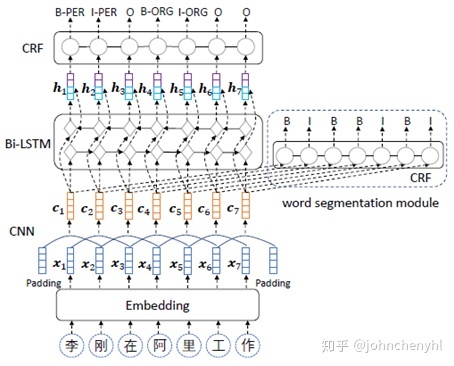
类似于上文对抗迁移学习,CNN-LSTM-CRF也是借助数据融合来提升NER效果,只不过模型结构不同。如图12,CNN-LSTM-CRF是先利用CNN建模字信息,一方面得到CWS输出,一方面往下再利用LSTM建模字之间信息,所以NER与CWS是共享CNN结构的。如果我们将CNN换为LSTM结构就跟上文有点相似了(当然上文模型是有一个单独的共享LSTM模型,而后者都是共享的),两者本质上都是多任务学习,只是具体实现方式不同而已。
参考文献
Chinese NER Using Lattice LSTM
An Encoding Strategy Based Word-Character LSTM for Chinese NER
A Neural Multi-digraph Model for Chinese NER with Gazetteers
CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition
Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism
Neural Chinese Named Entity Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation

