
- 1MySQL约束(Constraint)_mysql约束名是什么
- 2经典实例分割模型Mask RCNN原理与测试
- 32023-2024年中国人工智能计算力发展评估
- 4Mysql配置_mysql怎么配置
- 5MAGNet:Meta文本音乐生成工具,吉他摇滚、电子音乐都能搞定_meta 唱歌ai
- 6【Python】Python中assert语句的用法
- 7Android13系统导航栏添加隐藏导航栏功能按钮_we may show taskbar on the default display for lar
- 8服务发现:Zookeeper vs etcd vs Consul_consulratelimit kvloader
- 9头歌——一维数组和二维数组全对答案秒过_头歌二维数组右上部分求和
- 10go mod常用命令 以及 常见问题_go.mod already exists
2024年新算法-冠豪猪优化算法(CPO),CPO-RF-Adaboost,CPO优化随机森林RF-Adaboost回归预测-附代码_冠豪猪算法缺点
赞
踩
冠豪猪优化算法(CPO)是一种基于自然界中猪群觅食行为启发的优化算法。该算法模拟了猪群在寻找食物时的集群行为,通过一系列的迭代过程来优化目标函数,以寻找最优解。在这个算法中,猪被分为几个群体,每个群体内的猪会根据当前的最佳解以及群体内部的协作信息来更新自身位置,以期望获得更好的解。
CPO-RF-Adaboost则是将CPO算法应用于随机森林(Random Forest)结合AdaBoost的回归预测问题上的一种方法。随机森林是一种集成学习方法,通过多个决策树的组合来进行预测,而AdaBoost是一种弱分类器集成算法。在CPO-RF-Adaboost中,我们希望通过CPO算法来优化随机森林和AdaBoost中的参数,以获得更好的回归预测性能。
以下是CPO优化随机森林RF-Adaboost回归预测的基本原理:
-
初始化参数: 首先,需要初始化随机森林和AdaBoost的参数,如树的数量、树的深度、学习率等。
-
CPO优化过程: 使用CPO算法进行优化。这涉及到创建和管理多个猪群,每个群体代表一组参数的候选解。这些参数包括随机森林和AdaBoost的参数。在每次迭代中,猪群会根据目标函数的评价结果来调整自身位置,以尝试找到更好的参数组合。
-
评估候选解: 对于每个猪群所代表的参数组合,我们将其应用于随机森林和AdaBoost模型中,并使用交叉验证或其他评估方法来评估。
-
更新最佳解: 在CPO算法的迭代过程中,我们会不断更新全局最优解。如果某个猪群发现了比当前全局最优解更好的解,那么该解将被更新为全局最优解。
-
迭代优化: 重复执行CPO算法的迭代过程,直到达到预先设定的迭代次数或满足停止条件为止。
-
最终模型选取: 在优化完成后,选择具有最佳性能的参数组合作为最终的随机森林和AdaBoost模型。这些模型参数可以用于进行未来的回归预测任务。
结果如下:

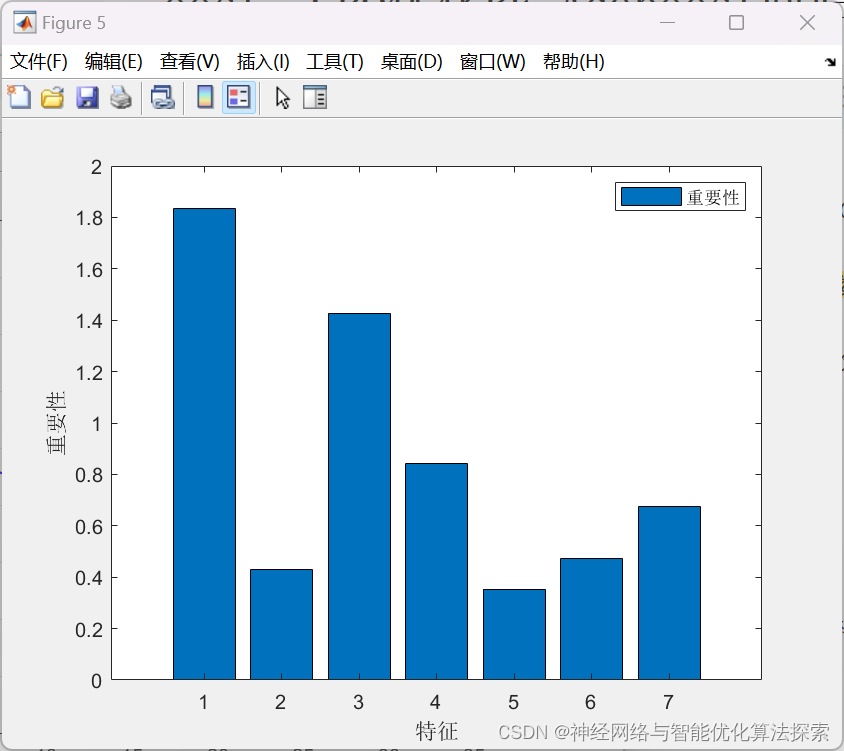
代码获取方式如下:
https://mbd.pub/o/bread/mbd-ZZ2al55y

