
- 1Redis中集合set数据类型(增加(添加元素)、获取(获取所有元素)、删除(删除指定元素))_redis删除set中的某一个值
- 2Python实现机器学习(上)— 基础知识介绍及环境部署_信道识别机器学习python
- 3安卓USB调试和无线调试ADB安装apk_无线调试安装apk
- 4《计算机网络》实验七 NAT配置实验_路由器nat的配置实验
- 52024 大数据毕业设计 数据科学与大数据专业毕业设计选题
- 6基于python的情感分析案例-python snownlp情感分析简易demo(分享)
- 7程序员代码规范自我总结_我的代码总结
- 8词向量Word2Vec(深度细致分析)_word2vec词向量
- 9vue实现自定义日历_vue 日历
- 10数学建模十大常用软件(转)_数学建模软件
大模型微调技术——PEFT
赞
踩
大模型高效微调(PEFT)技术
本文主要讲述了大模型的训练和微调成本较高,以及如何通过Prefix Tuning降低大模型微调成本的问题。此外,文中也涉及到大模型的训练难度和微调的复杂性,以及Prefix Tuning的原理和优势。同时,文中还介绍了如何使用Prefix Tuning进行模型微调的具体步骤和注意事项,以及Prefix Tuning在自然语言处理领域的应用前景。
PEFT产生的历史背景
为什么需要微调大模型?
- 预训练成本高,比如LLaMA -65B需要780GB显存
- 提示工程有天花板,具体表现在token上限和推理成本
- 基础模型缺少特定领域数据
- 数据安全和隐私
- 个性化服务需要私有化的微调大模型
目前就大模型这个领域,做得做好的公司可以说是OpenAI。其GPT系列模型迭代采用的技术就是:预训练+微调。
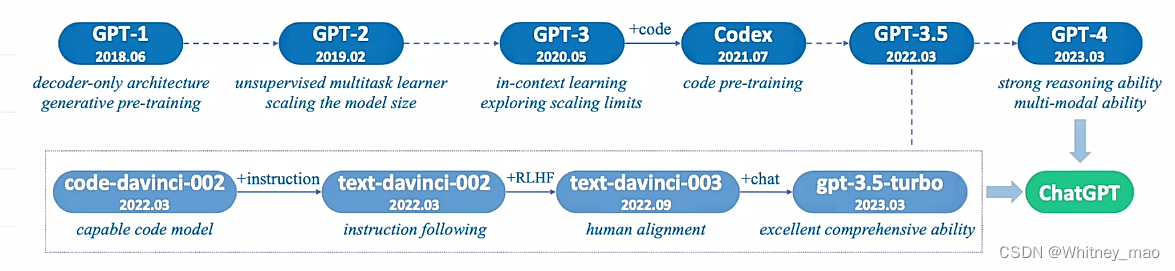
PEFT主流技术方案
——围绕Token做文章:语言模型(PLM)不变
- Prompt Tuning
- Prefix Tuning
- P-Tuning
—— 特定场景任务:训练“本质”的低维模型 - LORA
- QLORA
- AdaLORA
——新思路:少量数据、统一框架 - IA3
- UniPELT
在PEFT之前,大多数研究者以及学者面临的问题:不知道大模型怎么微调?因此,GPT3产生以后引发了广大的反响。它的核心思想是:大模型不需要微调,直接用大模型响应不同的prompt,就可以直接生成很好的结果。这也回复了很多人的疑惑,模型的参数没有变化,调整的是什么?in-context learning学习的内容是什么?其实,in-context learning的主体就是prompt。通过调整Prompt,就可以得到很好的结果。然而,Prompt具有多样性和随机性,导致了prompt模版不能解决较为深度的语义理解问题。因此,采用数据驱动的Prompt方法,让大语言先进行学习,再尝试生成更好的Prompt.
采用该数据驱动学习的变化
–传统的机器学习:通过训练集完成特定任务的训练,再用另外一个训练集完成另外一个任务。整个过程是相互独立的。
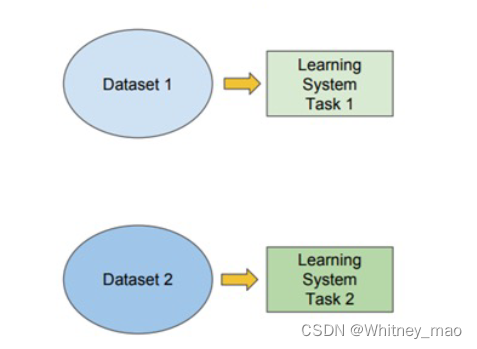
–迁移学习:训练集可以完成一个任务,并将训练的结果形成一种知识存储起来,运用到其它的任务中去,实现了用较少的训练集更快、更准确地完成其它任务。
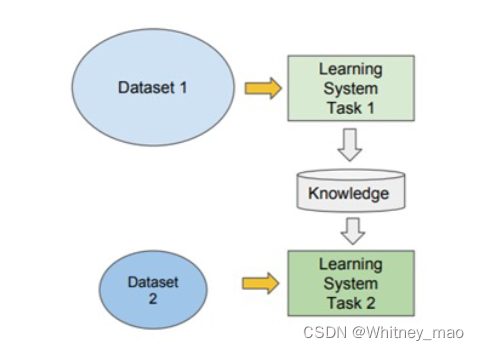
BERT验证可行:预训练+下游任务微调
在2018年,谷歌采用BERT技术,希望能够攻克语义理解的难题,从而解决大模型的天花板,因此放弃了GPT的内嵌下游任务路线。BERT前期采用预训练技术,完成较好的语义理解后,通过下游任务进行微调。
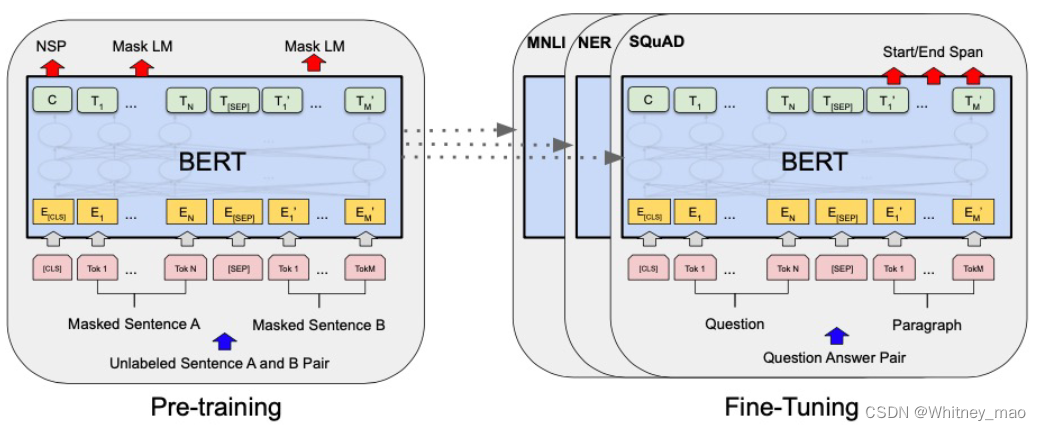
BERT实现后依旧存在两个问题:
- 预训练成本高;
- 新任务需要重新微调。
这些问题引发了新的思考,也奠定了Adapter Tuning技术的研究。
Adapter Tuning:开启大模型PEFT
在2019年的《Parameter-Efficient Transfer Learning for NLP》的论文中,记载了采用Adapter Tuning技术后惊人的试验效果。文章表明,在Adapter 模块中产生一个紧凑且可扩展的模型,这样只需要给特定任务添加少量可训练的参数,新的任务就可以高度共享的参数集。为了证明这个结论,文中采用了26个不同文本类规模化任务进行验证,并以GLUE为基准。
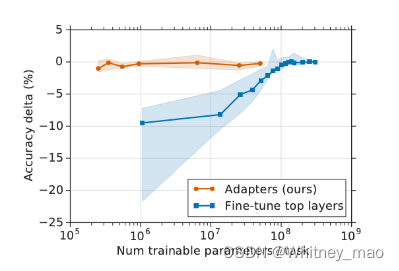
结果表明,基于Adapter Tuning技术在性能上比full fine-tuning低了0.4%,但每个任务只训练了其3.6%的参数。由上图可得,Adapter 与Fine-tune在准确性和每个任务所需参数数量上的关系。明显可以看出基于Adapter的微调可以得到与Fine-tune相似的效果,但是在每个特定任务训练参数的数量上要比Fine-tune少2个数量级。
Adapter核心技术解读
Adapter在Transform的结构上进行改造,具体表现在:
- 在两个FNN层增加Adapter层
- Adapter内部学习降维后特征,减少参数
- 使用skip-connection,最差退化为 identity
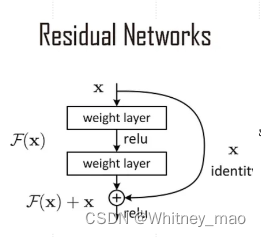
- 采用Residual Networks提升微调效率和稳定性,可复用性增强
下图绿色部分即为需要训练的参数。
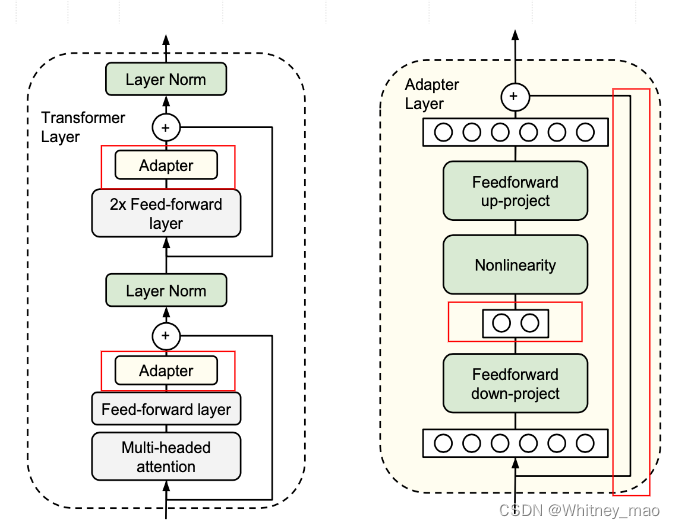
Residual Networks的结构。基于残差的思想,计算权重,这个思想解决了梯度消失问题。
基于这个思想,从训练的图表中也可以看出效果较好。
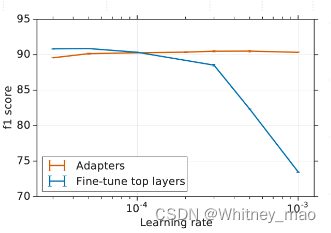
Adapter Tuning实验结果
以第一列作为基准,没有任何微调就执行各种任务,第二列为Fine-tune,参数总量是原来的17倍,执行任务跟原来相同时的平均分为73.7。而最后一列即为Adapters,采用了原来参数总量的1.19%,执行的任务量为原来的1.14%,执行效果的平均分达到了73.3,整体效果可以说是非常好了。
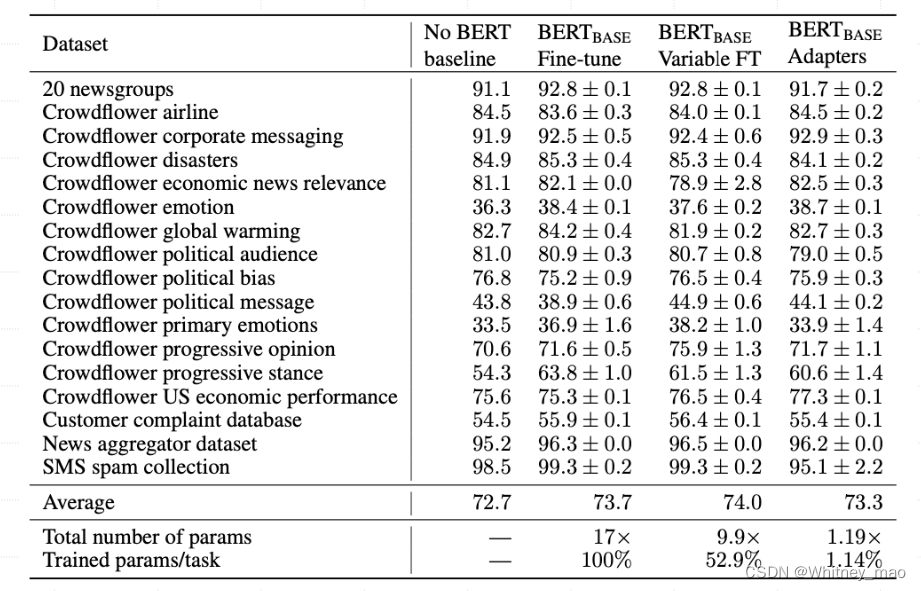
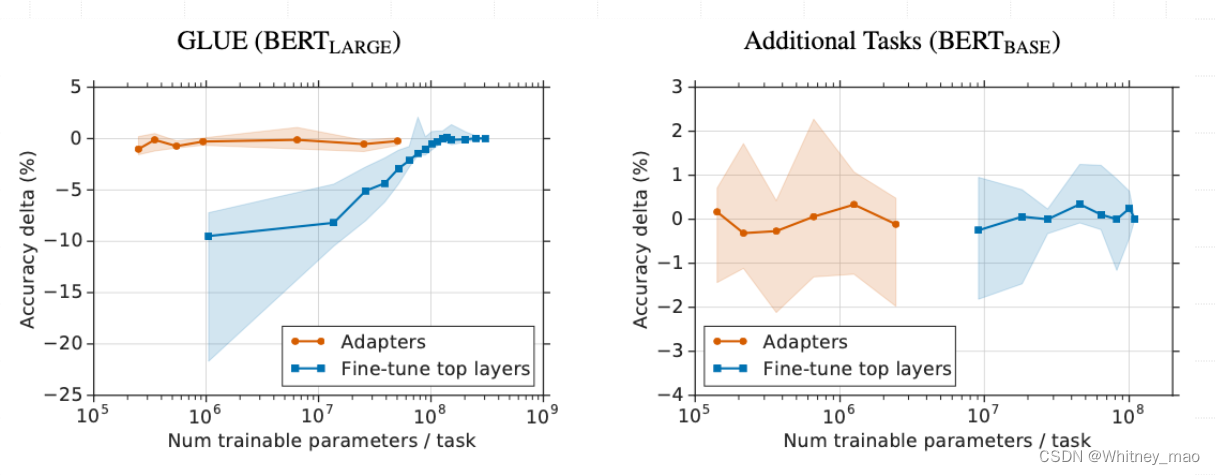
基准测试的评估指标GLUE,即为一个自然语言理解能力的系统性的基准,里面包含了很多小的指标基准。从实验图可以看出Adapters相比较于Fine-tune,具有很多优势,尤其在训练集的模型参数方面具有数量级上的优势。
Prefix Tuning:自动构造Prompts
Prefix Tuning主要目标还是降低大语言模型微调的成本。对此,论文《Prefix-Tuning:Optimizing Continuous Prompts for Generation》提出一个轻量级微调大模型方法。相较而言,Adapters核心思想是在Transformer内嵌入一个Layer,嵌入以后,则让新的小数据集进行微调Adapters局部参数即可,而不调整Transformer经典注意力机制和前馈网络。同时,反观GPT和BERT 在大模型微调时均需要将全量参数加载进来,而Prefix tuning是在Transformer网络之前加入一个特定的任务,在数学上可以理解为特定的特征向量。Prefix tuning无论是使用方式还是任务与其他技术均有差异,该技术基于GPT-2和BART两个模型。其它模型会改变Transformer的计算结果,但是Prefix-tuning不改变Transformer的任何计算,只在网络层前面加了一个前缀prefix,即加了一些特定的任务,再生成新的token,这些生成的token就可以适配特定的任务。
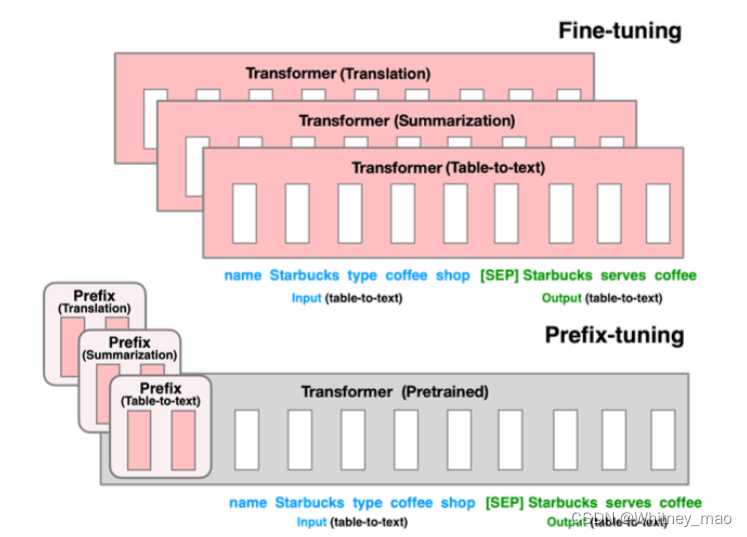
Prefix 嵌入 Transformer 网络:
- 在预训练Transformer 前增加 Prefix 模块
- 仅训练 Prefix,冻结 Transformer 全部参数
- 降低 GPU 算力和训练时间成本
- 特别适合于那些参数数量庞大的模型,如GPT-3,使微调这些模型成为可能。
Prefix: 任务特定的“指令集”,引导模型生成特定任务的输出。
Prefix-Tuning的优势:
- 与Adapters相同,不需要加载全量参数训练Transformer网络中的参数,则可以降低GPU算力和训练时间成本;
- 不需要加载整个大语言模型,而是直接将Transformer网络结构冻结。这意味着Prefix Tuning更适合面向百亿、千亿级别的大模型微调。
下图即为Prefix Tuning的结构。图中的x ,y即为原来Transformer的输入和输出。上层是GPT-2的网络结构,下层即为BART网络结构。

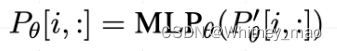
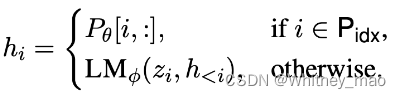
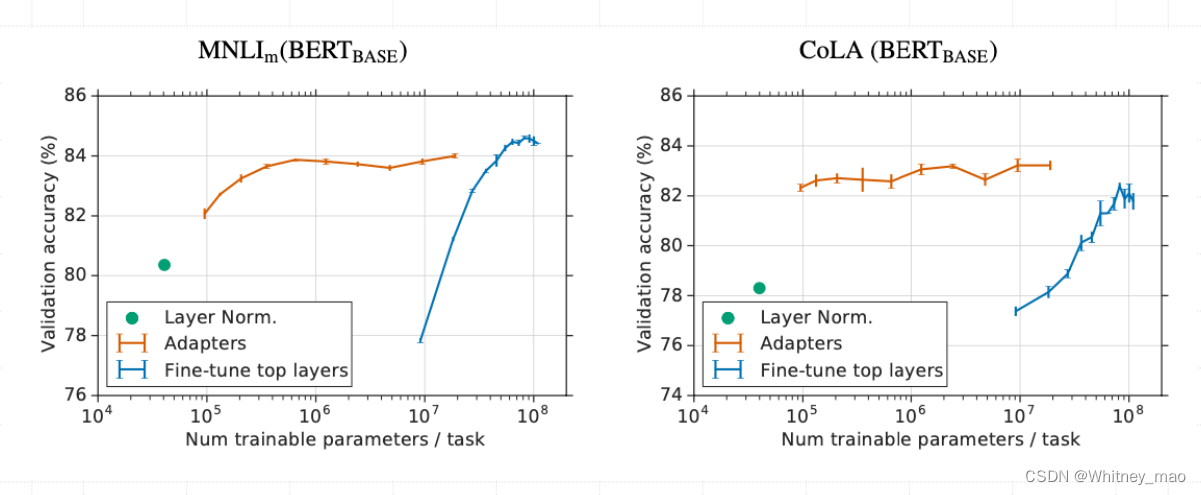
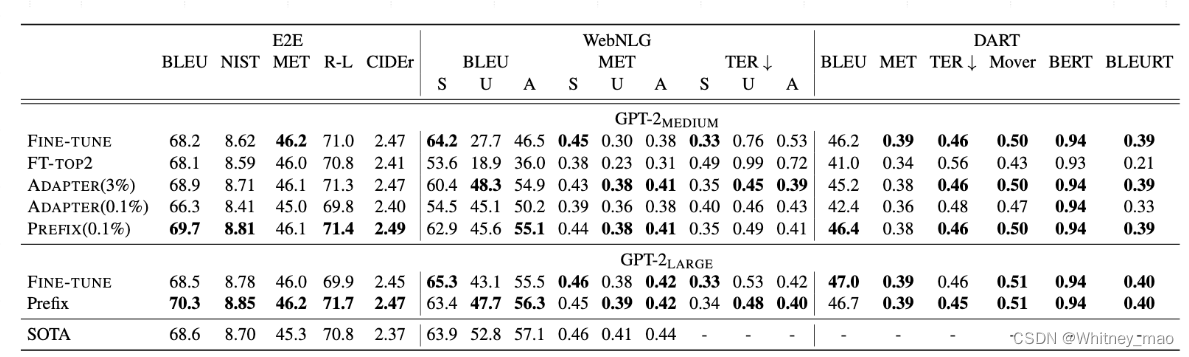
Prefix Tuning实验结果
从测试结果来看,无论是端到端测试还是WebNLG等,Prefix tuning模型在训练的过程中较复杂,因为其在transformer网络前面加了Prefix网络,但训练出来的效果绝大多数都优于Fine-Tune以及SOTA。这意味着在影长场景上,例如表格识别、文本摘要等,Prefix tuning使用较低成本微调模型,达到了较好的效果。
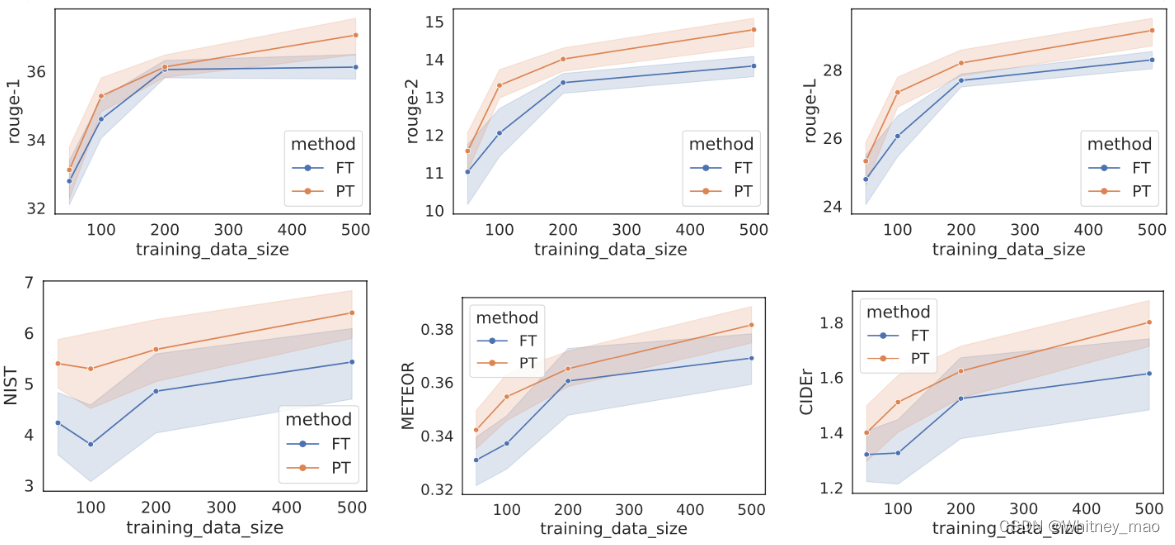
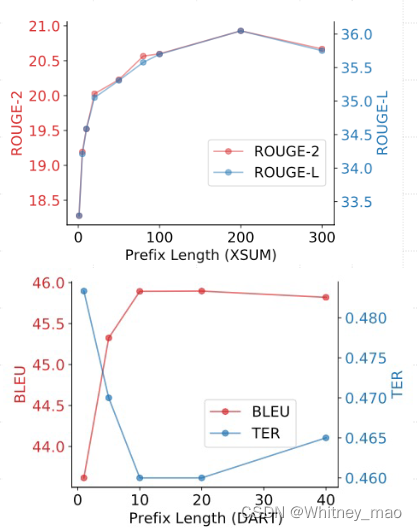
从实验结果的图像来看,不同训练数据的规模,prefix-tuning要优于Fine-tune。
考虑到Prefix-Tuning需要占用token,那么在设置Prompt提示词时不得不考虑Prefix的长度,以防止本身任务的执行。
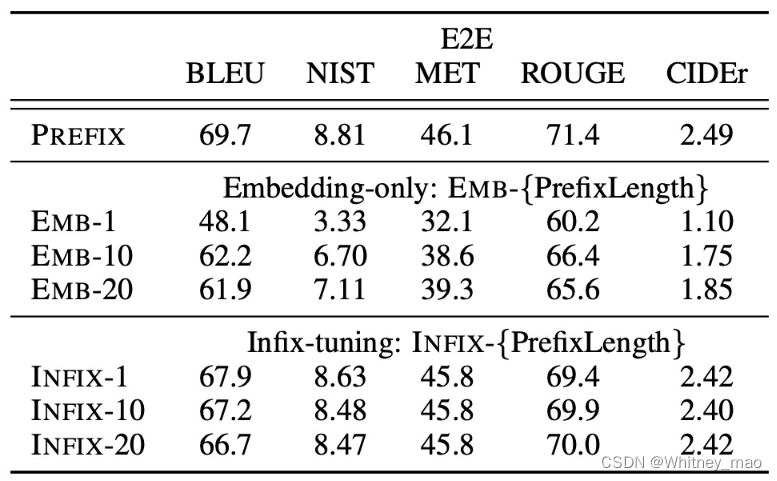
下图1为摘要生成,图2为表格生成。文本摘要生成中占用一定量的token,但是整体上并没有影响太大的效果。
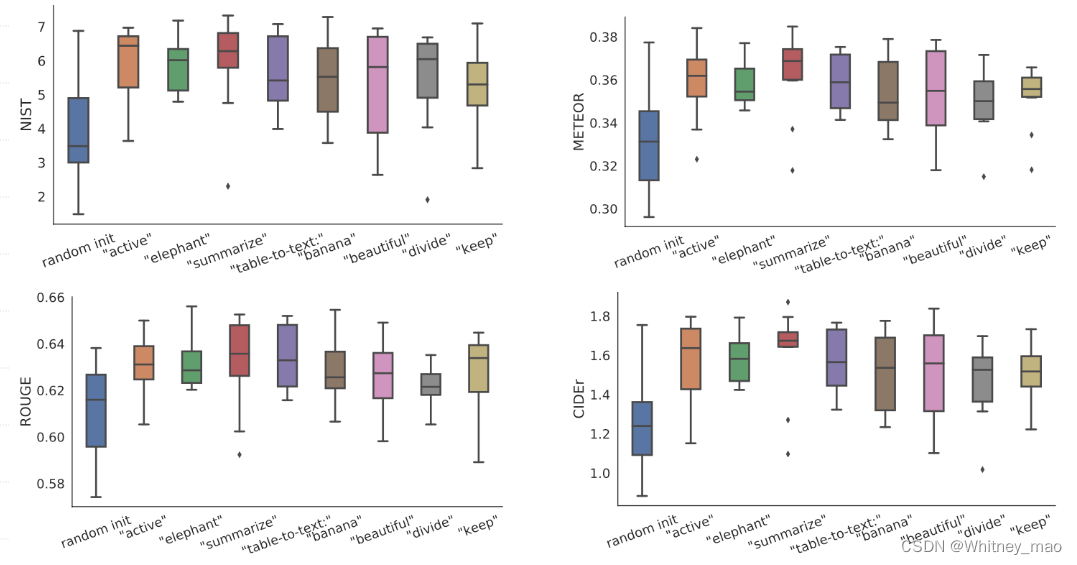
下图为初始化比较,如果提示词前缀增加的是较为明确的词,训练效果会好于随机性、含糊不清的词。
Prompt Tuning:Soft Prompts
Prompt Tuning的思想是基于Prefix tuning的创新。它并不是在Transformer网络前面加入特定的任务,而是在输入的时候加入合适的提示词以及token。
Prompt Tuning 主要贡献:
- 直观性:Prompt tuning 使用直观的语言提示来引导模型,使其更易于理解和操作
- 适用性:这种方法特别适用于那些预训练模型已经掌握了大量通用知识的情况,通过简单的提示就能激发特定的响应;
- 微调成本低:prompt tuning 可以在微调时减少所需的计算资源,同时保持良好的性能。
Prompt Tuning 核心技术解读
task A 可以理解为需要完成的特定任务,那么a1即为完成task A的步骤1的提示词。同理,Task B为另外一个任务,则b1即为完成任务的提示词,例如当Task B为语义理解并生成代码code,那么b1可以为“根据提示生成Python语言的代码”。
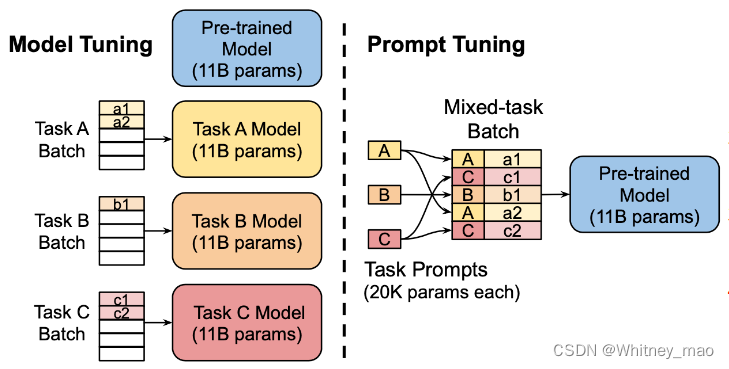
Prompt Tuning 训练方法:
- 设计提示:根据任务选择硬提示(固定文本)或软提示(可训练向量)作为输入。
- 融入输入:硬提示直接加入文本,软提示作为向量加入序列。
- 训练过程:硬提示下全面微调模型;软提示下只调整提示向量,其他参数不变。
- 执行任务:训练后模型用于NLP任务(如问答、摘要),输出由提示引导
Prompt Tuning 实验结果
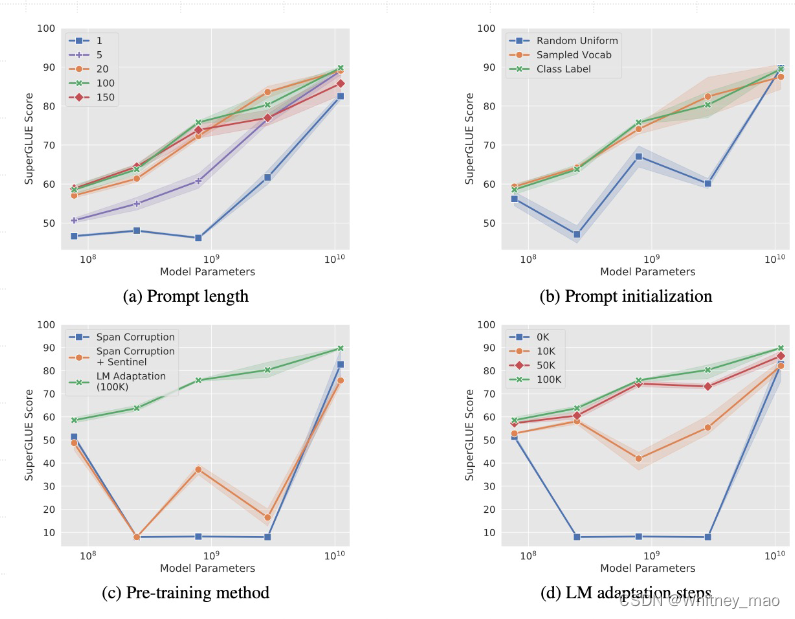
a)Prompt 长度:
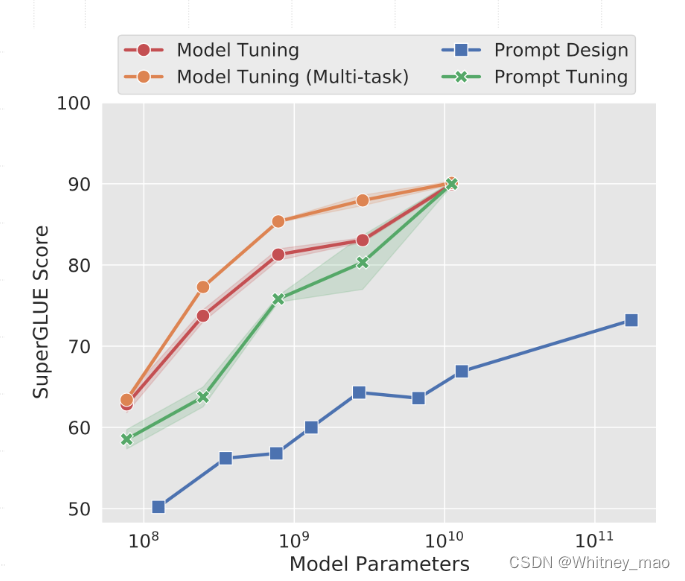
在大模型上,Prompt 长度为 1 也能达到不错的效果,Prompt 长度为 20 性价比
最高。
b)Prompt 初始化:
Random Uniform 明显弱于其他两种。当模型达到一定规模后,方法间几乎无差。
c)预训练方法:
在小模型上,LM Adaptation 效果最好。当模型达到一定规模后,方法间几乎无差。
d)微调步数:
模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,几乎所有模型都能取得不错效果。
Prompt Tuning V1
P-Tuning 的创新之处在于将提示(Prompt)转化为可学习的嵌入层(Embedding Layer),但直接对
嵌入层参数进行优化时面临两大挑战:
1.离散性(Discreteness):已经通过预训练优化过的正常语料嵌入层与直接对输入提示嵌入进行随机
初始化训练相比,可能会导致后者陷入局部最优解。
2.关联性(Association):这种方法难以有效捕捉提示嵌入之间的相互关系。
核心技术解读
考虑到Prompts长度,容易使得Prompt Tuning存在不稳定性,因此在嵌入层加入变量进行调整并可控制Prompts。
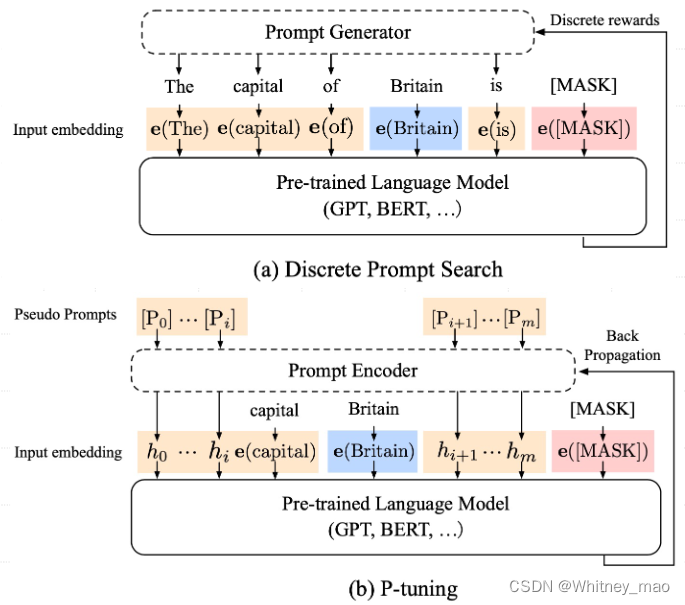
一个关于 “The capital of Britain is [MASK]” 示例:
• 蓝色是上下文 “Britain”
• 红色是目标单词 “[MASK]”,
• 橙色区域是提示词。
传统方式 与 P-Tuning 对比:
• 在(a)中,提示生成器只接收离散奖励;
• 在(b)中,连续的提示嵌入(Prompt Embedding)和提示编码器(Prompt Encoder)以可微的方式进行优化。
P-Tuning 和 Prefix-Tuning 主要区别在于:
• Prefix Tuning 类似于模仿指令,通过在模型开头加入额外的嵌入(embedding),而 P-Tuning的嵌入位置更为灵活。
• Prefix Tuning 在每个注意力层增加前缀嵌入来引入额外参数,并用多层感知机(MLP)进行初始化;相比之下,P-Tuning 仅在输入时加入嵌入,并通过长短期记忆网络(LSTM)加MLP进行初始化。
P-Tuning v1 实验结果
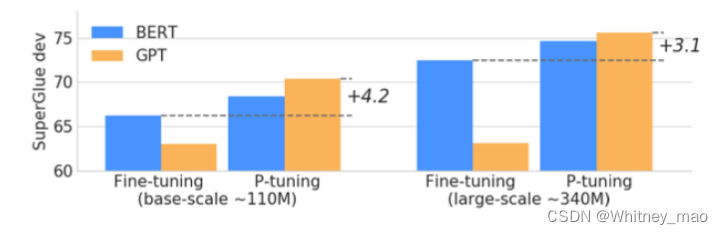
P-Tuning的思想即为将参数或者变量放入Embedding层进行计算,直接得出想要的结果。由下表可得P-tuning 效果优于所有离散型提示性模型基线。
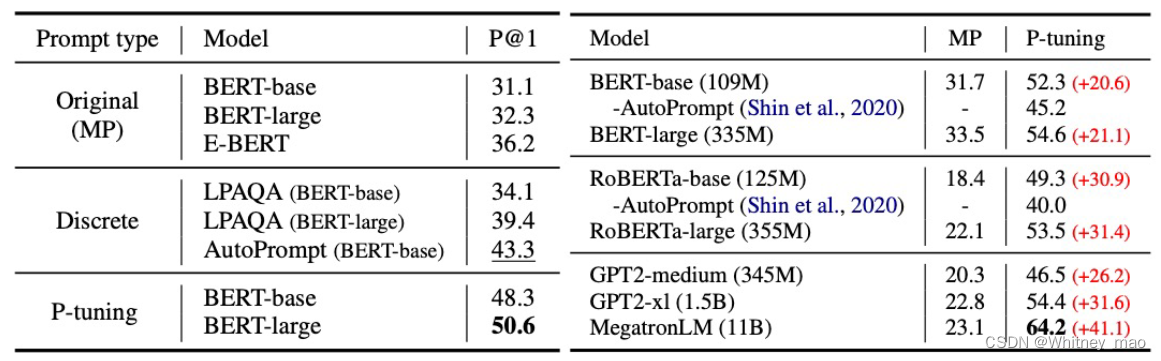
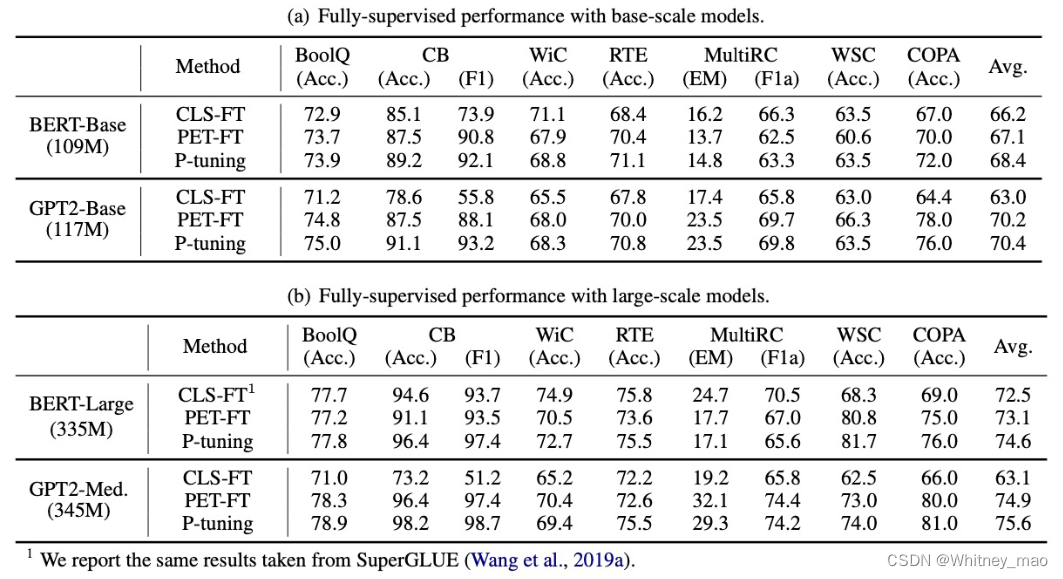
下表为PET、Prompt Tuning和P-tuning 在基于Al BERT 的七项任务中的few-shot性能基准对比。结果表明,与 PET 相比,P-tuning 的few-shot性能可持续提高至少1分以上,与Prompt Tuning相比,可持续提高13 分以上。

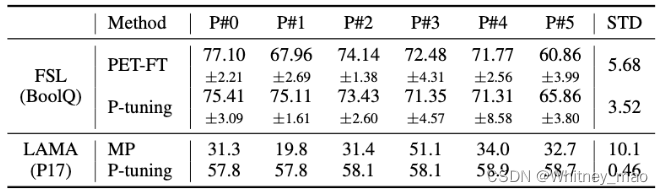
Prompt Tuning V2——提升小模型和多任务微调质量
P-Tuning 在小模型上性能不佳。
P-Tuning v2 旨在使提示调整(Prompt Tuning)在不同规模的预训练模型上,针对各种下游任务都能达到类似全面微调(Fine-tuning)的效果。
之前的方法在以下两方面有所限制:
• 模型规模差异:在大型预训练模型中,Prompt Tuning 和P-Tuning 能取得与全面微调相似的效果,但在参数较少的模型上则表现不佳。
• 任务类型差异:无论是 Prompt Tuning 还是 P-Tuning,在序列标注任务上的表现都较差
P-Tuning v2 核心技术解读
1. 重参数化(Reparameterization):
- 在Prefix Tuning和P-tuning中,多层感知机(MLP)被用来构造可训练的嵌入(embedding)。
- P-Tuning v2的研究发现,针对不同的任务和数据集,这种方法可能产生相反的效果,特别是在自然语言理解领域。
2.提示长度(Prompt Length):
- 不同任务对应的最优提示长度(Prompt Length)是不一样的。
- 例如,在简单的分类任务中,长度为20的提示可能是最佳选择;而对于更复杂的任务,则需要更长的提示长度。
3.多任务学习(Multi-task Learning):
- 对于P-Tuning v2而言,多任务学习是可选的,但它可以提供更好的参数初始化,从而进一步提升模型性能。
4.分类头(Classification Head):
- 在Prompt Tuning中,使用语言模型(LM)头来预测动词是核心思路。
- 然而,P-Tuning v2的研究发现,在完整数据集上这种做法并非必要,且与序列标记任务不兼容。
- 因此,P-Tuning v2采用类似BERT的方式,在第一个token处应用随机初始化的分类头。
实验结果
以下为Super GLUE基准测试结果。当小于10B的模型时,P-tuning v2训练的效果超越了P-tuning和Lester,在不同模型规模上与Fine-tune的性能相匹配。
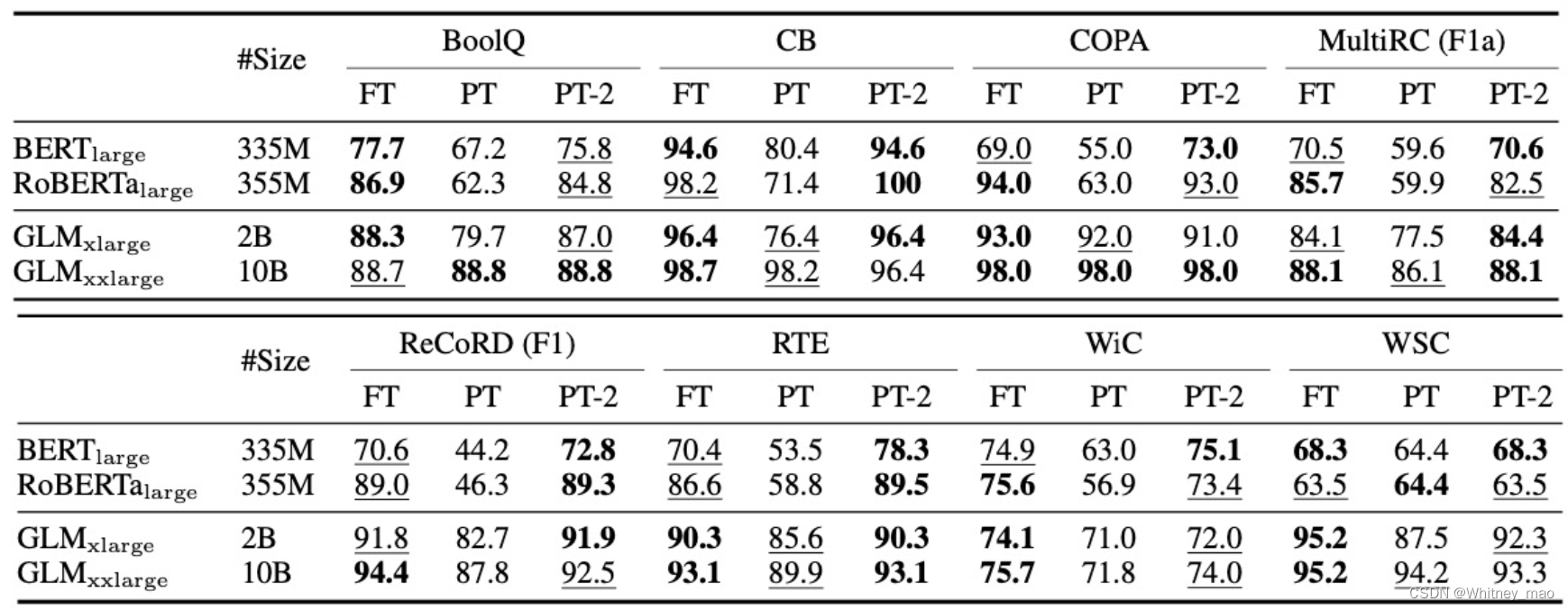
下表为命名实体识别(NER)、问答(提取式 QA)和语义标注(SRL)的结果对比。NER和SRL的所有指标均为micro-f1分值。


