
热门标签
热门文章
- 1PostgreSQL物化视图相关操作,materialized view 不阻塞刷新_refresh materialized view
- 2【Spark编程基础】实验一Spark编程初级实践(附源代码)_spark实验一
- 3华为2288H V5 找不到本地启动项,进不了raid配置界面_2288hv5启动项
- 4MATLAB基于领航追随法的车辆编队控制,领航追随者与人工势场法的简单融合实现避障_领航跟随法车辆编队
- 5程序员感情生活大揭秘,想脱单的进......
- 6JSON parse error: Cannot deserialize value of type `java.lang.String` from Object value (token `Json
- 7【定位问题】chan算法、chan-Taylor算法移动基站(不同数量基站)无源定位【含Matlab源码 3148期】_chan定位算法
- 8c++图形界面开发中,Qt和MFC谁更胜一筹?_qt和mfc哪个界面开发更好
- 9深度解析 Spring 源码:三级缓存机制探究_spring 三级缓存源码解析
- 10将voc数据集划分为训练集测试集_voc 切分训练集
当前位置: article > 正文
简单介绍AudioLM
作者:AllinToyou | 2024-05-21 15:59:11
赞
踩
audiolm
主要介绍AudioLM,学习资料为知乎文章。这里只介绍核心思想和模块。
AudioLM
基本信息
AudioLM: a Language Modeling Approach to Audio Generation
pdf: https://arxiv.org/pdf/2209.03143.pdf
参考资料:https://zhuanlan.zhihu.com/p/637196330
模型结构和原理(语音到语音)
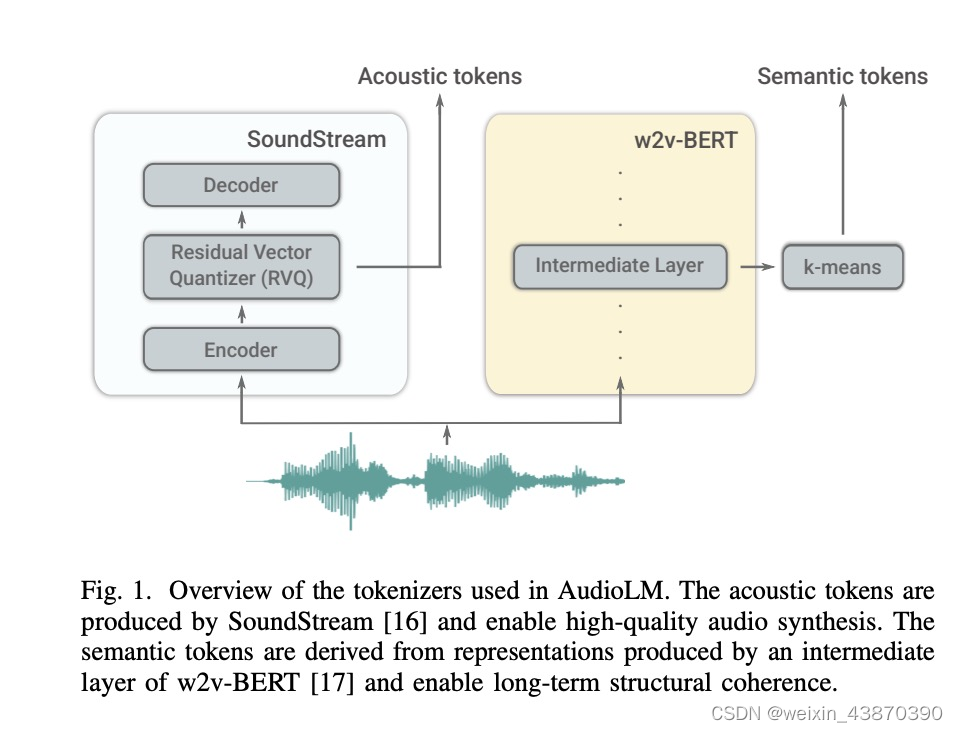
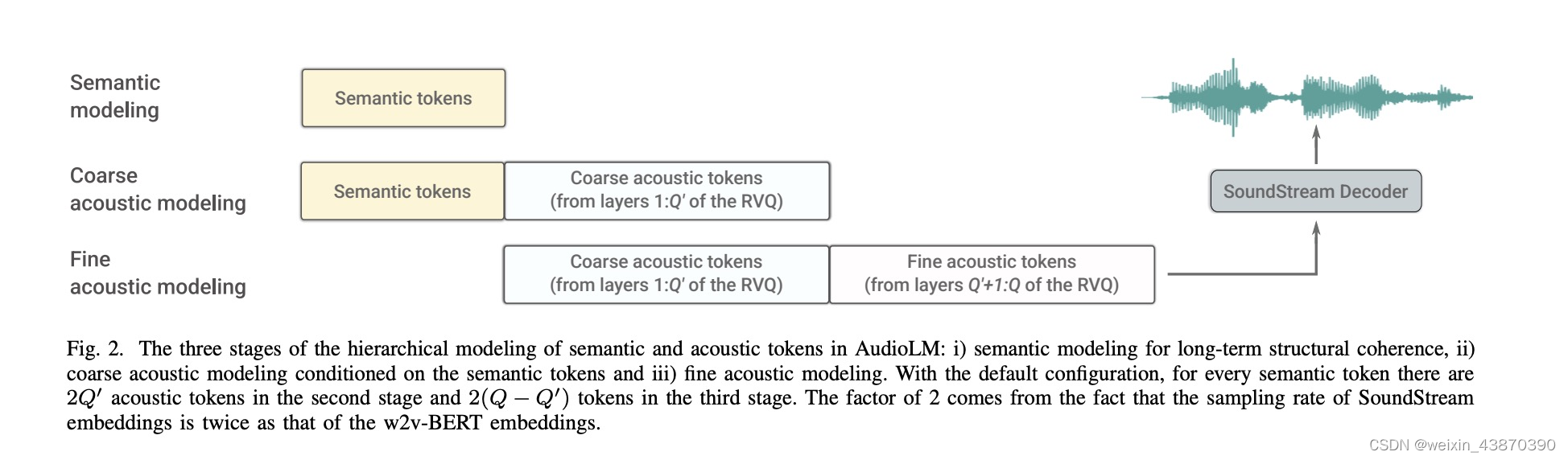


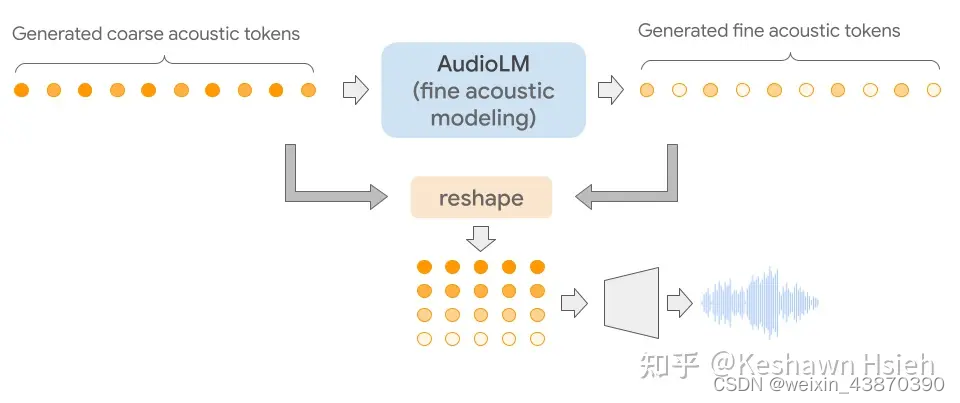
- 整体思路,语音到语音,语音续写。
- 两个前处理模块:第一张图中将一个语音处理成semantic tokens(w2v-bert)以及acoustic tokens(soundstream前部分模块)
- 三个核心模块:即最后三张图。Semantic modeling用于将语义信息进一步生成,生成新的语义,可以理解成续写的内容;Coarse acoustic modeling用于语音信息的生成,它的输入结合了前面生成的语义信息,生成新的语音信息包含了语义信息;Fine acoustic modeling模块将语音信息进一步精修,生成新的语音信息;精修的语音信息和精修之前的语音信息合在一起进行进行decoder,解码为wav。
- 上面第二张图,是论文中的原图,展示了三个模块和数据流向,看完最后三个图再理解这个图就很容易懂了。
适合任务
适合任务1:自由生成。随机输入一些semantic tokens。
适合任务2:语音续写。
适合任务3:钢琴曲学写。
适合任务4:speaker转换。也就是保持说的内容是given的,然后生成不同说话人音色的音频。
外接gpt模型t5,让audiolm具有tts的能力。
inference阶段
- unconditional generation
这里可以理解为就是生成随机的内容,也不控制speaker音色。
这里的输入描述是we sample unconditionally all semantic tokens。
我的理解就是随机给一些semantic tokens作为输入,来启动semantic transformer的自回归输出
不过这里没有提到第二阶段要用到的acoustic tokens这个输入从哪里来?
- 1
- 2
- 3
- 4
知乎中这段文字,我理解acoustic tokens也来自随机。
- acoustic generation
semantic tokens这次直接由某个固定的wav过w2v-bert得到。
这样可以实现合成和这个wav同样的内容但是音色和风格不同的其他说话人的语音。
相对第一种模式,这个模式下感觉就不需要用到semantic modeling这个过程了。
但是还是存在一个疑问,就是coarse acoustic modeling的过程中,acoustic tokens这个输入从哪里来?
- 1
- 2
- 3
- 4
知乎中这段文字,我理解acoustic tokens是来自外部给定的wav,可以参考这个wav的风格生成语音。
- generating continuations
这个模式是相对比较符合实际应用的,这个模式下会给定一个wav的prompt。
然后从prompt可以得到semantic tokens和acoustic tokens。
分别被用在第一阶段和第二阶段,最后可以实现一个语音续写的效果。
不过续写的内容是来自模型本身产生,无法人为控制。
- 1
- 2
- 3
- 4
备注:由于没有看原始论文,所以没太理解训练的时候的具体细节,每个模型有没有初始化,模型训练任务怎么设计的,以及loss是什么。
相关待学:soundstream、Vall-e、HifiGan、Vits、GPT-SoVITs、encodec
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/603421
推荐阅读
- [详细] -->
赞
踩
相关标签

