
- 1图片转excel技术在医疗领域的应用探讨
- 2spring boot整合Knife4j_springboot集成knife4j
- 3git submodule---同步最新的内容_git 如何把子模块也同步到某个提交
- 4Java面试之异常,java高级程序员面试
- 5C++通过mysql的c api和通过mysql的Connector C++ 1.1.3操作mysql的两种方式_mysql c++ connector sample
- 6【VUE+Elemet 】最全正则验证 + 表单验证 + 注意事项_vue rules 正则
- 7华硕 ROG PG27UQR 电竞显示器参数 华硕 ROG PG27UQR 评测_pg27uqr 工厂模式
- 8【IDEA】java 项目启动偶现Kotlin 版本问题 error:Kotlin:module was_error:kotlin: module was compiled with an incompat
- 9Hadoop集群安装
- 10南京理工大学计算机科学与技术学院 毕业生名单,信息学部 计算机与信息学院...
SpringBoot实现图片识别文字的四种方式_springboot ocr
赞
踩
SpringBoot实现图片识别文字
文末含有案例地址哦!!!
SpringBoot 整合 Tess4J 实现
Tesseract是一个开源的光学字符识别(OCR)引擎,它可以将图像中的文字转换为计算机可读的文本。支持多种语言和书面语言,并且可以在命令行中执行。它是一个流行的开源OCR工具,可以在许多不同的操作系统上运行。
Tess4J是一个基于Tesseract OCR引擎的Java接口,可以用来识别图像中的文本,说白了,就是封装了它的API,让Java可以直接调用。
1、引入tess4j依赖
<!-- tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
2、yml配置
把训练数据的目录路径配置在yml里,后续可以扩展到配置中心。
server:
port: 8888
# 训练数据文件夹的路径
tess4j:
datapath: E:/gitee/OCR/tess4j_data
- 1
- 2
- 3
- 4
- 5
- 6
Tesseract OCR库通过训练数据来学习不同语言和字体的特征,以便更好地识别图片中的文字。
在安装Tesseract OCR库时,通常会生成一个包含多个子文件夹的训练数据文件夹,其中每个子文件夹都包含了特定语言或字体的训练数据。
比如我这里是下载后放到了D盘的tessdata目录下,如图所示,其实就是一个.traineddata为后缀的文件,大小约2M多。
训练数据,官方下载地址:https://digi.bib.uni-mannheim.de/tesseract/
GitHub官网地址:https://github.com/tesseract-o
3、编写配置类
@Configuration public class TesseractOcrConfig { @Value("${tess4j.dataPath}") private String dataPath; @Bean public Tesseract tesseract() { Tesseract tesseract = new Tesseract(); // 设置训练数据文件夹路径 tesseract.setDatapath(dataPath); // 设置为中文简体 tesseract.setLanguage("chi_sim"); return tesseract; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4、编写业务实现类
@Service public class OcrServiceImpl implements OcrService { private final Tesseract tesseract; public OcrServiceImpl(Tesseract tesseract) { this.tesseract = tesseract; } /** * * @param imageFile 要识别的图片 * @return */ @Override public String recognizeText(MultipartFile imageFile) throws IOException, TesseractException { // 转换 InputStream sbs = new ByteArrayInputStream(imageFile.getBytes()); BufferedImage bufferedImage = ImageIO.read(sbs); // 对图片进行文字识别 return tesseract.doOCR(bufferedImage); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5、编写测试接口
@RestController @RequestMapping("/api") @Slf4j public class OcrController { private final OcrService ocrService; public OcrController(OcrService ocrService) { this.ocrService = ocrService; } @PostMapping(value = "/recognize", consumes = MediaType.MULTIPART_FORM_DATA_VALUE) public String recognizeImage(@RequestParam("file") MultipartFile file) throws TesseractException, IOException { log.info(ocrService.recognizeText(file)); // 调用OcrService中的方法进行文字识别 return ocrService.recognizeText(file); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
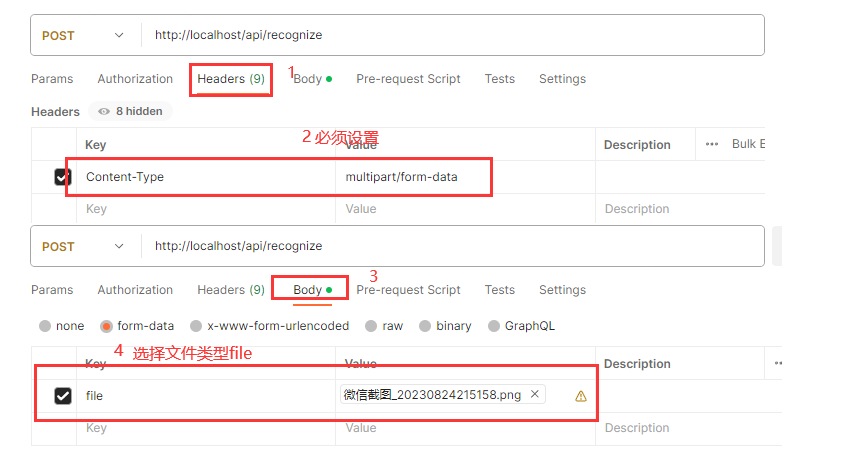
postman配置:
效果:
此方法的识别精准度差,不建议使用。
案例完整代码:https://github.com/rookiesnewbie/OCR
整合百度智能云实现
官网文档:https://ai.baidu.com/ai-doc/OCR/dk3iqnq51
1、根据官方文档创建应用
2、引入依赖
<!--百度ocr-->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.16.10</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
3、编写yml配置文件
server:
port: 8090
baidu:
APP_ID: #应用的appid
API_KEY: #你的app_key
SECRET_KEY: #你的secret_key
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4、创建一个配置类来初始化百度OCR的客户端
@Setter
@Configuration
@ConfigurationProperties(prefix = "baidu")
public class baiduOcrConfig {
private String APP_ID;
private String API_KEY;
private String SECRET_KEY;
@Bean
public AipOcr aipOcr() {
return new AipOcr(APP_ID, API_KEY, SECRET_KEY);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5、编写controller
@RestController @Slf4j @RequestMapping("/api") public class BaiduOcrController { @Autowired private AipOcr aipOcr; @PostMapping(value = "/process",consumes = MediaType.MULTIPART_FORM_DATA_VALUE) public String processImage(@RequestParam("file") MultipartFile file) { HashMap<String, String> options = new HashMap<String, String>(); options.put("detect_direction", "true"); options.put("probability", "true"); try { byte[] imageBytes = file.getBytes(); JSONObject result = aipOcr.basicGeneral(imageBytes, options); // 解析百度OCR的识别结果 StringBuilder sb = new StringBuilder(); result.getJSONArray("words_result").forEach(item -> { JSONObject word = (JSONObject) item; sb.append(word.getString("words")).append("\n"); }); return sb.toString(); } catch (IOException e) { e.printStackTrace(); return "Error processing image"; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
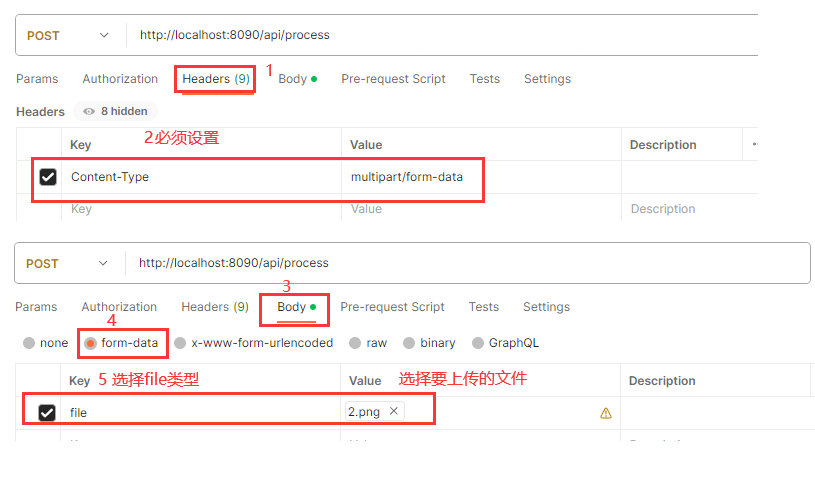
6、使用postm测试
效果:
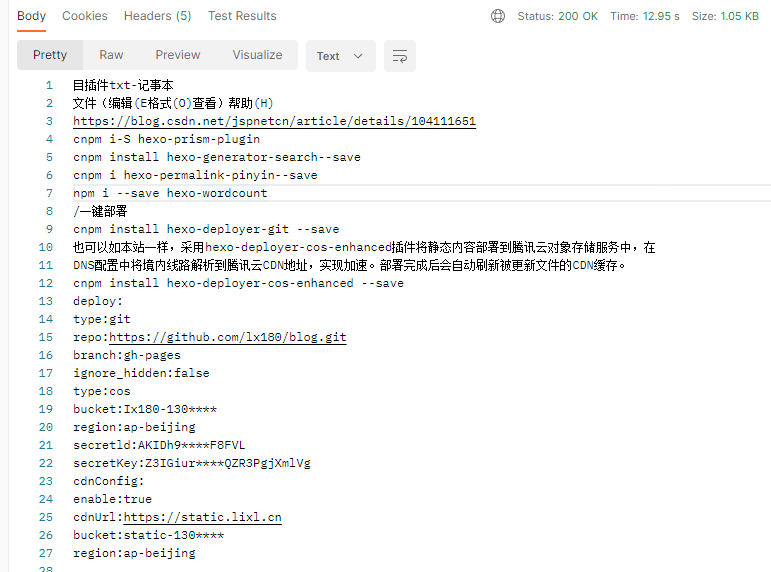
精准度很高,推荐使用,而且还有很多的精准度选择
常用API:
https://ai.baidu.com/ai-doc/OCR/Nkibizxlf
-
通用文字识别
官网文档:https://ai.baidu.com/ai-doc/OCR/Nkibizxlf#%E9%80%9A%E7%94%A8%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB
-
//image为图片的二进制字节数组,options为传入可选参数调用接口 basicGeneral(byte[] image, HashMap<String, String> options)- 1
- 2
-
//image为图片的存放路径,options为传入可选参数调用接口 basicGeneral(String image, HashMap<String, String> options)- 1
- 2
-
//image为图片的存放在服务器的路径,options为传入可选参数调用接口 basicGeneralUrl(String url, HashMap<String, String> options)- 1
- 2
-
-
通用文字识别(高精度版)
官网文档:https://ai.baidu.com/ai-doc/OCR/Nkibizxlf#%E9%80%9A%E7%94%A8%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB%EF%BC%88%E9%AB%98%E7%B2%BE%E5%BA%A6%E7%89%88%EF%BC%89
-
//image为图片的二进制字节数组,options为传入可选参数调用接口 basicAccurateGeneral(byte[] image, HashMap<String, String> options)- 1
- 2
-
//image为本地图片的存放路径,options为传入可选参数调用接口 basicAccurateGeneral(String image, HashMap<String, String> options)- 1
- 2
-
-
通用文字识别(含位置信息版)
官网文档:https://ai.baidu.com/ai-doc/OCR/Nkibizxlf#%E9%80%9A%E7%94%A8%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB%EF%BC%88%E5%90%AB%E4%BD%8D%E7%BD%AE%E4%BF%A1%E6%81%AF%E7%89%88%EF%BC%89
-
//image为图片的二进制字节数组,options为传入可选参数调用接口 general(byte[] image, HashMap<String, String> options)- 1
- 2
-
//image为图片的存放路径,options为传入可选参数调用接口 general(String image, HashMap<String, String> options)- 1
- 2
-
//image为图片的存放在服务器的路径,options为传入可选参数调用接口 generalUrl(String url, HashMap<String, String> options)- 1
- 2
-
-
通用文字识别(含位置高精度版)
官网文档:https://ai.baidu.com/ai-doc/OCR/Nkibizxlf#%E9%80%9A%E7%94%A8%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB%EF%BC%88%E5%90%AB%E4%BD%8D%E7%BD%AE%E9%AB%98%E7%B2%BE%E5%BA%A6%E7%89%88%EF%BC%89
-
//image为图片的二进制字节数组,options为传入可选参数调用接口 accurateGeneral(byte[] image, HashMap<String, String> options)- 1
- 2
-
//image为图片的存放路径,options为传入可选参数调用接口 accurateGeneral(String image, HashMap<String, String> options)- 1
- 2
-
-
通用文字识别(含生僻字版)
官网文档:https://ai.baidu.com/ai-doc/OCR/Nkibizxlf#%E9%80%9A%E7%94%A8%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB%EF%BC%88%E5%90%AB%E7%94%9F%E5%83%BB%E5%AD%97%E7%89%88%EF%BC%89
-
enhancedGeneral(byte[] image, HashMap<String, String> options)- 1
-
enhancedGeneral(String image, HashMap<String, String> options)- 1
-
enhancedGeneralUrl(String url, HashMap<String, String> options)- 1
-
整合阿里云阿里云
官方文档:https://next.api.aliyun.com/api-tools/sdk/ocr-api?spm=a2c4g.442247.0.0.40933e8eQ3GZIX&version=2021-07-07&language=java-tea&tab=primer-doc
https://next.api.aliyun.com/api/ocr-api/2021-07-07/RecognizeAdvanced?spm=api-workbench.SDK%20Document.0.0.2e7652e95jnhKE&tab=DOC&sdkStyle=dara&lang=JAVA
1、引入依赖
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>ocr_api20210707</artifactId>
<version>1.2.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
2、编写yml配置文件
server:
port: 8099
aliyun:
KeyId: #你的KeyId
KeySecret: #你的KeySecret
endpoint: ocr-api.cn-hangzhou.aliyuncs.com
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、编写配置类
@Setter @Component @ConfigurationProperties(prefix = "aliyun") public class AliyunOcrConfig { private String KeyId; private String KeySecret; private String endpoint; @Bean public Client ocrClient(){ try { Client client = new Client(new Config().setAccessKeyId(KeyId).setAccessKeySecret(KeySecret).setEndpoint(endpoint)); return client; } catch (Exception e) { throw new RuntimeException(e); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4、编写测试接口
@RestController @RequestMapping("/api") @Slf4j public class AliyunOcrController { @Resource private Client client; @PostMapping(value = "ocr",consumes = MediaType.MULTIPART_FORM_DATA_VALUE) public String OcrTest(@RequestParam("file")MultipartFile file) throws IOException { RecognizeGeneralRequest request = new RecognizeGeneralRequest(); request.setBody(file.getInputStream()); try { RecognizeGeneralResponse response = client.recognizeGeneral(request); String json = new Gson().toJson(response.getBody()); String[] split = json.split(","); return split[1].split(":")[1].replace("\\",""); // return json; } catch (TeaException error) { Common.assertAsString(error.message); } catch (Exception e) { TeaException error = new TeaException(e.getMessage(), e); // 如有需要,请打印 error Common.assertAsString(error.message); } return null; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
5、使用postman测试
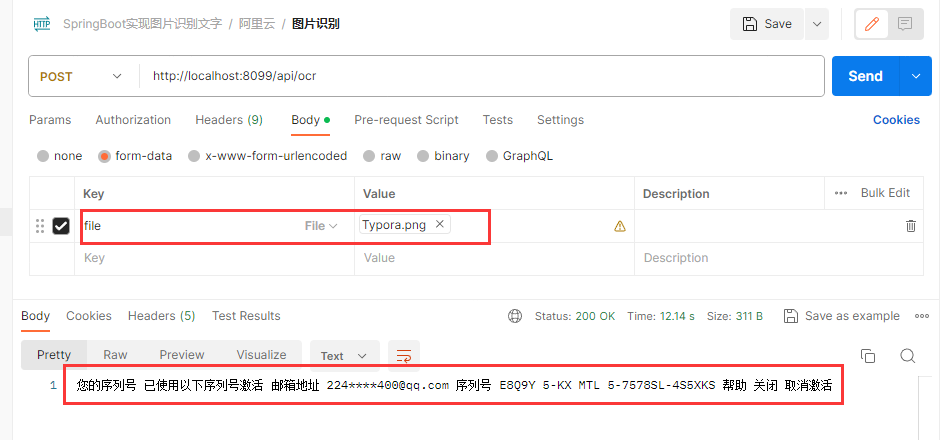
整合腾讯云实现
官网文档:https://cloud.tencent.com/document/product/866
官网API:https://cloud.tencent.com/document/api/866/33515
官网参数说明与在线调试:https://console.cloud.tencent.com/api/explorer?Product=ocr&Version=2018-11-19&Action=GeneralHandwritingOCR
1、获取密钥:
https://console.cloud.tencent.com/cam/capi
2、引入依赖
<dependency>
<groupId>com.tencentcloudapi</groupId>
<artifactId>tencentcloud-sdk-java</artifactId>
<version>3.1.909</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
3、编写yml配置文件
server:
port: 9090
tencent:
SecretId: #你的SecretId
SecretKey: #你的SecretKey
- 1
- 2
- 3
- 4
- 5
- 6
4、编写配置类
@Setter
@Configuration
@ConfigurationProperties(prefix = "tencent")
public class TencentOcrConfig {
private String SecretId;
private String SecretKey;
@Bean
public Credential credential(){
return new Credential(SecretId,SecretKey);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
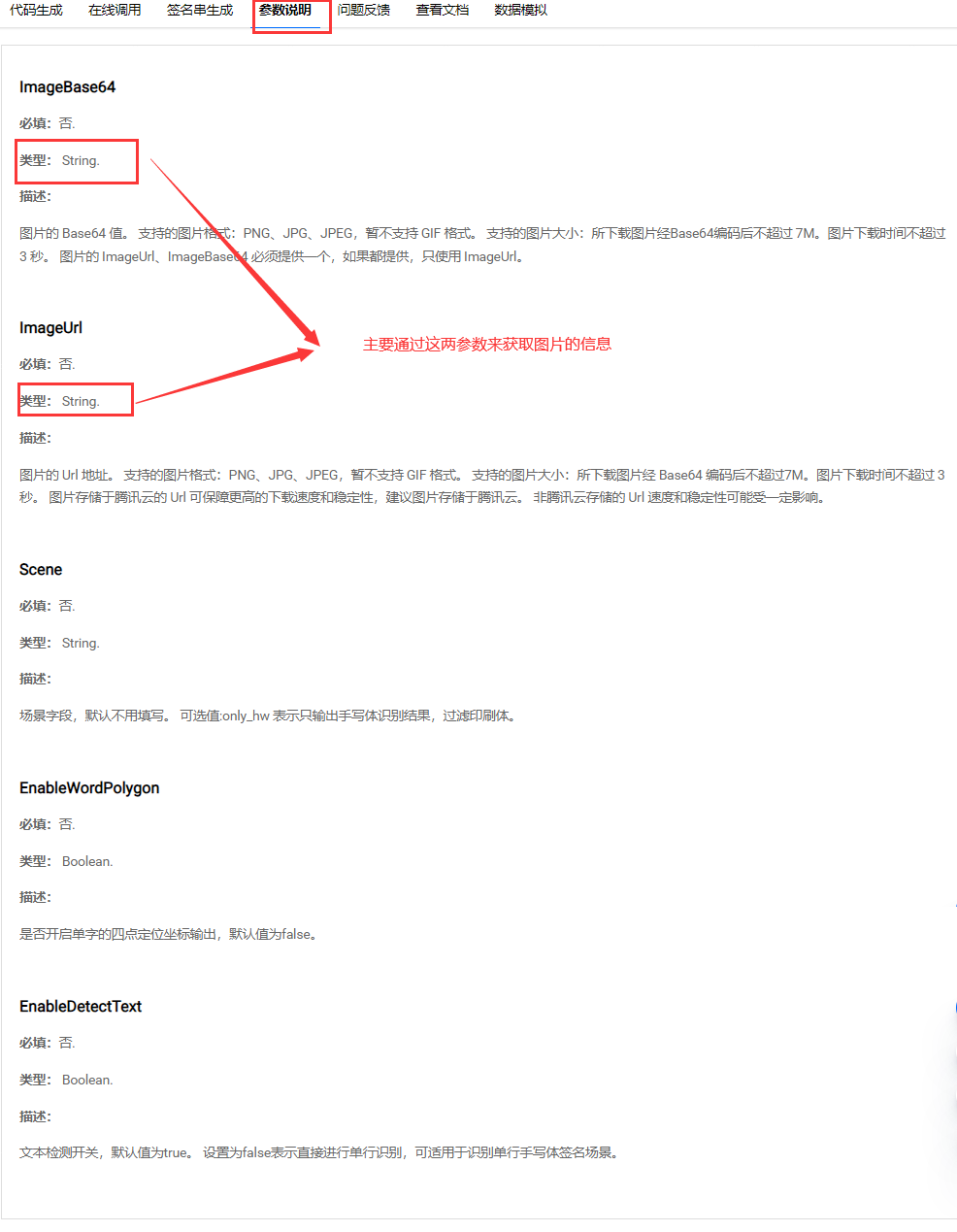
5、编写将文件转换成Base64编码的工具类
由于腾讯云OCR的API接收的参数如下图,所以要编写将文件转码成Base64的工具类:
public class ByteToBase64Converter {
public static String encodeBytesToBase64(byte[] bytes) {
return Base64.getEncoder().encodeToString(bytes);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
6、编写接口测试
@RestController @RequestMapping("/api") @Slf4j public class TencentOcrController { @Resource private Credential credential; @PostMapping(value = "/tencent",consumes = MediaType.MULTIPART_FORM_DATA_VALUE) public String TencentOCR(@RequestParam("file")MultipartFile file) throws TencentCloudSDKException, IOException { // 实例化一个http选项,可选的,没有特殊需求可以跳过 HttpProfile httpProfile = new HttpProfile(); httpProfile.setEndpoint("ocr.tencentcloudapi.com"); // 实例化一个client选项,可选的,没有特殊需求可以跳过 ClientProfile clientProfile = new ClientProfile(); clientProfile.setHttpProfile(httpProfile); // 实例化要请求产品的client对象,clientProfile是可选的 OcrClient client = new OcrClient(credential, "ap-guangzhou", clientProfile); //将上传的文件转换成base64编码 String encodeBytesToBase64 = ByteToBase64Converter.encodeBytesToBase64(file.getBytes()); // 实例化一个请求对象,每个接口都会对应一个request对象 GeneralBasicOCRRequest req = new GeneralBasicOCRRequest(); req.setImageBase64(encodeBytesToBase64); // req.setImageUrl("https://ltmyblog.oss-cn-shenzhen.aliyuncs.com/myBlog/article/image-20230924213423855.png"); // 返回的resp是一个GeneralBasicOCRResponse的实例,与请求对象对应 GeneralBasicOCRResponse resp = client.GeneralBasicOCR(req); GeneralBasicOCRResponse.toJsonString(resp); // 输出json格式的字符串回包 System.out.println(GeneralBasicOCRResponse.toJsonString(resp)); return GeneralBasicOCRResponse.toJsonString(resp); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
7、使用postman测试
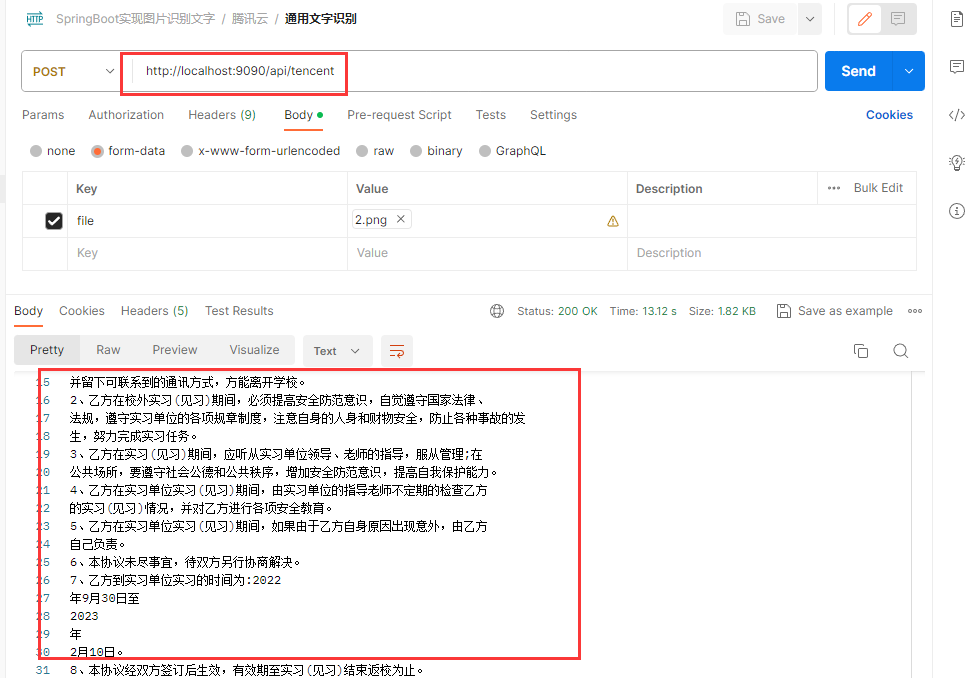
本文的全部案例:https://github.com/rookiesnewbie/OCR

