
云原生 Amazon Aurora分布式RPC应用_aws 支持的rpc框架
赞
踩
一、云原生亚马逊数据存储
介绍
Amazon RDS——无需配置、部署,即可快速使用的云原生关系数据库
对于传统数据库而言,虽然经过几年的迭代发展,也经过几轮优胜劣汰,传统数据库满足了当前互联网的需求。
但传统数据库的配置和部署,是需要人力和对文档的基本了解,需要耗费的资源和时间巨大,而且需要自己提供服务器运营,成本尚不可观。
而企业级数据库,最关注的是数据稳定性和可靠性,一旦面临宕机和数据泄露,对企业来说将是一次沉重的代价。
如果考虑云原生,就不需要考虑这些额外的代价,因为云生态提供自动维护,而且安全性高、可靠性也高。
参与云生态开发时,一对一服务已经成为过去式,当今互联网流量巨大,每天成万甚至上亿的流量是很正常的。
为此,分布式架构的项目环境,配合云生态数据库开发,将是一次领先尝试。
高性能和高可扩展性
最高为 MySQL 吞吐量的 5 倍,PostgreSQL 吞吐量的 3 倍
根据 SysBench 等标准基准进行的测试表明,其吞吐量最高可达到存储 MySQL 的 5 倍,在类似硬件上运行时,其吞吐量是类似硬件上运行的原版 PostgreSQL 9.6 的 3 倍。Amazon Aurora 使用各种不同的软件和硬件技术来确保数据库引擎能够充分利用可用计算、内存和联网。I/O 运算使用 Quorum 等分布式系统技术来提高性能一致性。
完全托管
1. 易于使用
可以十分轻松地开始使用 Amazon Aurora。只需使用 Amazon RDS 管理控制台或一个 API 调用或 CLI 即可启动新的 Amazon Aurora 数据库实例。Amazon Aurora 数据库实例为您所选择的数据库实例类预配置了合适的参数和设置集。您在几分钟之内即可启动数据库实例并连接应用程序,而无需其他配置。数据库参数组可以提供对数据库的精细控制和微调功能。
2. 数据库的启动/停止
只需几次点击即可手动停止和启动 Amazon Aurora 数据库。从而可以轻松、经济地将 Aurora 用于无需数据库始终运行的开发和测试环境。停止数据库不会删除数据。有关详细信息,请参阅启动/停止文档。
3. 无服务器配置
Amazon Aurora Serverless 是一种面向 Aurora 的按需自动扩缩配置,其中的数据库将根据应用程序的需求自动启动、关闭以及扩展或缩减容量。在云中运行数据库,而无需管理任何数据库实例。
二、分布式架构
分布式架构项目引入云原生亚马逊数据存储,不仅缩短开发周期,也减少了人力和物力成本。
目前开发了一种基于Nacos的RPC分布式框架,无依赖其他主流框架,目前可以轻松集成springboot框架、关系型和非关系型主流数据库以及云原生存储数据库。
介绍
一个分布式微服务RPC框架 | 英文说明文档

1. 服务提供
- 负载均衡策略
- 序列化策略
- 自动发现和注销服务
- 注册中心
2. 安全策略
- 心跳机制
- 信息摘要
3. 设计模式
- 单例模式
- 动态代理
- 静态工厂
- 建造者
- 策略模式
- Future(观察者)
亮点
1. 信息摘要算法的应用
对于信息摘要算法的使用,其实并不难,在数据包中添加 String 类型的成员变量 checkCode 用来防伪的就可以实现。
- 原理
发送端把原信息用HASH函数加密成摘要,然后把数字摘要和原信息一起发送到接收端,接收端也用HASH函数把原消息加密为摘要,看两个摘要是否相同,若相同,则表明信息的完整.否则不完整。
- 实现
客户端在发出 请求包,服务端会在该请求包在请求执行的结果的内容转成字节码后,使用 MD5 单向加密成为 唯一的信息摘要(128 比特,16 字节)存储到响应包对应的成员变量 checkCode 中,所以客户端拿到响应包后,最有利用价值的地方(请求要执行的结果被改动),那么 checkCode 将不能保证一致性,这就是信息摘要的原理应用。
安全性再增强
考虑到这只是针对客户需求的结果返回一致性,并不能确保请求包之间存在相同的请求内容,所以引入了请求 id。
每个包都会生成唯一的 requestId,发出请求包后,该包只能由该请求发出的客户端所接受,就算两处有一点被对方恶意改动了,客户端都会报错并丢弃收到的响应包,不会拆包后去返回给用户。
如果不是单单改动了返回结果,而是将结果跟信息摘要都修改了,对方很难保证修改的内容加密后与修改后的信息摘要一致,因为要保证一致的数据传输协议和数据编解码。
2. 心跳机制
心跳机制的 RPC 上应用的很广泛,本项目对心跳机制的实现很简单,而且应对措施是服务端强制断开连接,当然有些 RPC 框架实现了服务端去主动尝试重连。
- 原理
对于心跳机制的应用,其实是使用了 Netty 框架中的一个 handler 处理器,通过该 处理器,去定时发送心跳包,让服务端知道该客户端保持活性状态。
- 实现
利用了 Netty 框架中的 IdleStateEvent 事件监听器,重写userEventTriggered() 方法,在服务端监听读操作,读取客户端的 写操作,在客户端监听写操作,监听本身是否还在活动,即有没有向服务端发送请求。
如果客户端没有主动断开与服务端的连接,而继续保持连接着,那么客户端的写操作超时后,也就是客户端的监听器监听到客户端没有的规定时间内做出写操作事件,那么这时客户端该处理器主动发送心跳包给服务端,保证客户端让服务端确保自己保持着活性。
3. IO 异步非阻塞
IO 异步非阻塞 能够让客户端在请求数据时处于阻塞状态,而且能够在请求数据返回时间段里去处理自己感兴趣的事情。
- 原理
使用 java8 出世的 CompletableFuture 并发工具类,能够异步处理数据,并在将来需要时获取。
- 实现
数据在服务端与客户端之间的通道 channel 中传输,客户端向通道发出请求包,需要等待服务端返回,这时可使用 CompletableFuture 作为返回结果,只需让客户端读取到数据后,将结果通过 complete()方法将值放进去后,在将来时通过get()方法获取结果。
快速开始
/** * 自定义对象头 协议 16 字节 * 4 字节 魔数 * 4 字节 协议包类型 * 4 字节 序列化类型 * 4 字节 数据长度 * * The transmission protocol is as follows : * +---------------+---------------+-----------------+-------------+ * | Magic Number | Package Type | Serializer Type | Data Length | * | 4 bytes | 4 bytes | 4 bytes | 4 bytes | * +---------------+---------------+-----------------+-------------+ * | Data Bytes | * | Length: ${Data Length} | * +---------------+---------------+-----------------+-------------+ */

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.依赖
1.1 直接引入
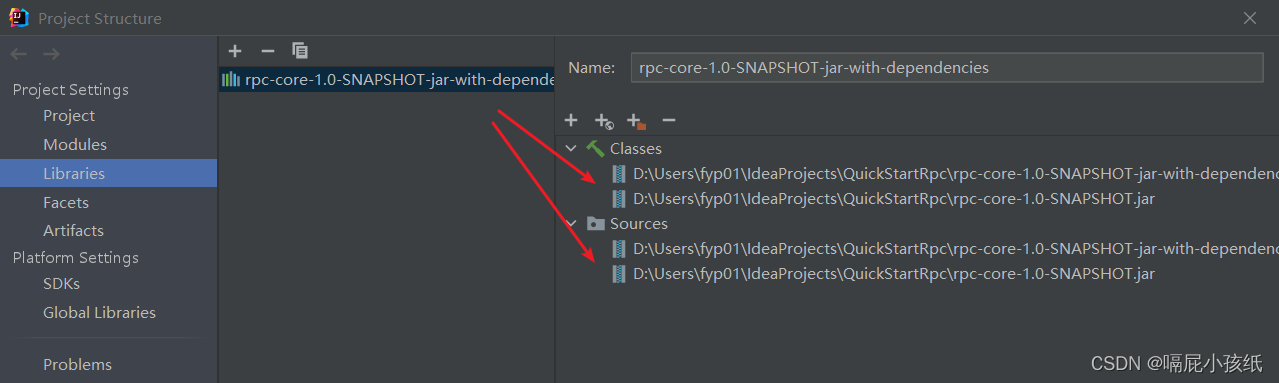
首先引入两个jar包文件rpc-core-1.0.0.jar 和 rpc-core-1.0.0-jar-with-dependencies.jar
jar包中包括字节码文件和java源码,引入后会自动把class和sources一并引入,源码可作为参考
1.2 maven引入
引入以下maven,会一并引入rpc-common与默认使用的注册中心nacos-client相关依赖
<dependency>
<groupId>cn.fyupeng</groupId>
<artifactId>rpc-core</artifactId>
<version>1.0.6.RELEASE</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
2. 启动 Nacos
-m:模式,standalone:单机
命令使用:
startup -m standalone
- 1
注意:开源RPC 默认使用 nacos 指定的本地端口号 8848
官方文档:https://nacos.io/zh-cn/docs/quick-start.html
Nacos 启动效果:

3. 提供接口
public interface HelloService {
String sayHello(String message);
}
- 1
- 2
- 3
4. 启动服务
- 真实服务
@Service
public class HelloServiceImpl implements HelloService {
@Override
public String sayHello(String message) {
return "hello, here is service!";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 服务启动器
@ServiceScan
public class MyServer {
public static void main(String[] args) {
try {
NettyServer nettyServer = new NettyServer("127.0.0.1", 5000, SerializerCode.KRYO.getCode());
nettyServer.start();
} catch (RpcException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意:增加注解
cn.fyupeng.Service和cn.fyupeng.ServiceScan才可被自动发现服务扫描并注册到 nacos
5. 启动客户端
初始化客户端时连接服务端有两种方式:
- 直连
- 使用负载均衡
public class MyClient {
public static void main(String[] args) {
RoundRobinLoadBalancer roundRobinLoadBalancer = new RoundRobinLoadBalancer();
NettyClient nettyClient = new NettyClient(roundRobinLoadBalancer, CommonSerializer.KRYO_SERIALIZER);
RpcClientProxy rpcClientProxy = new RpcClientProxy(nettyClient);
HelloService helloService = rpcClientProxy.getProxy(HelloService.class);
String result = helloService.sayHello("hello");
System.out.println(result);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5. 额外配置
5.1 配置文件
- 项目方式启动
在 resources 中加入 resource.properties
主机名使用localhost或127.0.0.1指定
cn.fyupeng.nacos.register-addr=localhost:8848
- 1
Jar方式启动
,兼容springboot的外部启动配置文件注入,需要在Jar包同目录下新建config文件夹,在config中与springboot一样注入配置文件,只不过springboot注入的配置文件默认约束名为application.properties,而rpc-netty-framework默认约束名为resource.properties。
目前可注入的配置信息有:
cn.fyupeng.nacos.register-addr=localhost:8848
- 1
5.2 日志配置
在 resources 中加入 logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!--%date{HH:mm:ss.SSS} %c -->
<pattern>%date{HH:mm:ss.SSS} %c [%t] - %m%n</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console"/>
</root>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
除此之外,框架还提供了 Socket 方式的 Rpc 服务
6. 场景应用
- 支持 springBoot 集成
为了支持springBoot集成logback日志,继承rpc-netty-framework使用同一套日志,抛弃nacos-client内置的slf4j-api与commons-loging原有Jar包,因为该框架会导致在整合springboot时,出现重复的日志绑定和日志打印方法的参数兼容问题,使用jcl-over-slf4j-api可解决该问题;
在springboot1.0和2.0版本中,不使用它默认版本的spring-boot-starter-log4j,推荐使用1.3.8.RELEASE;
springboot简单配置如下
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <!-- 排除 springboot 默认的 logback 日志框架 --> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> <!-- 排除 springboot 默认的 commons-logging 实现(版本低,出现方法找不到问题) --> <exclusion> <groupId>org.springframework</groupId> <artifactId>spring-jcl</artifactId> </exclusion> </exclusions> </dependency> <!-- 与 logback 整合(通过 @Slf4j 注解即可使用) --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.10</version> </dependency> <!--引入log4j日志依赖,目的是使用 jcl-over-slf4j 来重写 commons logging 的实现--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-log4j</artifactId> <version>1.3.8.RELEASE</version> </dependency> </dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
7. 异常解决
- ServiceNotFoundException
抛出异常ServiceNotFoundException
堆栈信息:service instances size is zero, can't provide service! please start server first!
正常情况下,一般的错误从报错中可以引导解决。
解决真实服务不存在的情况,导致负载均衡中使用的策略出现异常的情况,修复后会强制抛出ServiceNotFoundException,或许大部分情况是服务未启动。
当然,推荐真实服务应该在服务启动器的内层包中,同层可能会不起作用。
除非使用注解注明包名@ServiceScan("com.fyupeng")
其他情况下,如出现服务端无反应,而且服务已经成功注册到注册中心,那么你就得检查下服务端与客户端中接口命名的包名是否一致,如不一致,也是无法被自动发现服务从注册中心发现的,这样最常见的报错也是service instances size is zero。
- ReceiveResponseException
抛出异常data in package is modified Exception
信息摘要算法的实现,使用的是String类型的equals方法,所以客户端在编写Service接口时,如果返回类型不是八大基本类型 + String 类型,也就是复杂对象类型,那么要重写toString方法。
不使用Object默认的toString方法,因为它默认打印信息为16位的内存地址,在做校验中,发送的包和请求获取的包是需要重新实例化的,说白了就是深克隆,必须 重写Object原有toString方法。
为了避免该情况发生,建议所有PoJo、VO类必须重写toString方法,其实就是所有真实业务方法返回类型的实体,必须重写toString方法。
如返回体有嵌套复杂对象,所有复杂对象均要重写toString只要满足不同对象但内容相同的toString方法打印信息一致,数据完整性检测才不会误报。
- RegisterFailedException
抛出异常Failed to register service Exception
原因是注册中心没有启动或者注册中心地址端口指定不明,或者因为防火墙问题,导致Nacos所在服务器的端口访问失败。
- NotSuchMethodException
抛出异常java.lang.NoSuchMethodError: org.slf4j.spi.LocationAwareLogger.log
出现该异常的原因依赖包依赖了jcl-over-slf4j的jar包,与springboot-starter-log4j中提供的jcl-over-slf4j重复了,建议手动删除rpc-core-1.0.0-jar-with-dependenceies.jar中org.apache.commons包
- DecoderException
抛出异常:com.esotericsoftware.kryo.KryoException: Class cannot be created (missing no-arg constructor): java.lang.StackTraceElement
主要是因为Kryo序列化和反序列化是通过无参构造反射创建的,所以使用到Pojo类,首先必须对其创建无参构造函数,否则将抛出该异常,并且无法正常执行。
- InvocationTargetException
抛出异常:Serialization trace:stackTrace (java.lang.reflect.InvocationTargetException)
主要也是反射调用失败,主要原因还是反射执行目标函数失败,缺少相关函数,可能是构造函数或者其他方法参数问题。
- AnnotationMissingException
抛出异常:cn.fyupeng.exception.AnnotationMissingException
由打印信息中可知,追踪AbstractRpcServer类信息打印
cn.fyupeng.net.AbstractRpcServer [main] - mainClassName: jdk.internal.reflect.DirectMethodHandleAccessor
- 1
如果mainClassName不为@ServiceScan注解标记所在类名,则需要到包cn.fyupeng.util.ReflectUtil下修改或重写getStackTrace方法,将没有过滤的包名加进过滤列表即可,这可能与JDK的版本有关。
- OutOfMemoryError
抛出异常java.lang.OutOfMemoryError: Requested array size exceeds VM limit
基本不可能会抛出该错误,由于考虑到并发请求,可能导致,如果请求包分包,会出现很多问题,所以每次请求只发送一个请求包,如在应用场景需要发送大数据,比如发表文章等等,需要手动去重写使用的序列化类的serialize方法
例如:KryoSerializer可以重写serialize方法中写缓存的大小,默认为4096,超出该大小会很容易报数组越界异常问题。
/**
* bufferSize: 缓存大小
*/
Output output = new Output(byteArrayOutputStream,100000))
- 1
- 2
- 3
- 4
8. 版本追踪
1.0版本
[ #1.0.1 ]:解决真实分布式场景下出现的注册服务找不到的逻辑问题;
[ #1.0.2 ]:解耦注册中心的地址绑定,可到启动器所在工程项目的资源下配置resource.properties文件;
[ #1.0.4.RELEASE ]:修Jar方式部署项目后注册到注册中心的服务未能被发现的问题,解耦Jar包启动配置文件的注入,约束名相同会覆盖项目原有配置信息;
[ #1.0.5 ]:将心跳机制打印配置默认级别为trace,默认日志级别为info,需要开启到logback.xml启用。
[ #1.0.6 ]:默认请求包大小为4096字节,扩容为100000字节,满足日常的100000字的数据包,不推荐发送大数据包,如有需求看异常OutOfMemoryError说明。

