
- 1Vue3中使用History模式引发刷新页面出现404的问题_vue3 history 404
- 2在Jupyter上运行spacy中文模型_jupyter安装spacy包
- 3AI标注神器 X-AnyLabeling-v2.3.0 发布!支持YOLOv8旋转目标检测、EdgeSAM、RTMO等热门模型!
- 4AI大模型探索之路-训练篇24:ChatGLM3微调实战-多卡方案微调步骤详解_chatglm微调方法图
- 5自动化测试面试题(含答案)_自动化测试的面试题
- 6RabbitMQ如何保证消息的顺序性【重点】
- 7Vue中组件之间的通信有哪些方法
- 8git仓库中增加子仓库_git 添加子仓库
- 9Springboot2.x和1.5.x的区别_spring cloud 1.5和2.x区别
- 10推荐系统摘要_基于用户喜好推荐商品摘要
多角度解析自动驾驶芯片_tops tflops
赞
踩
主要是从以下几个关键点进行自动驾驶芯片的解析:
-
芯片的四大算力单位(OPS、MACS、FLOPS、DMIPIS);
-
两大典型AI控制器的算力如何计算(FSD和Xavier);
-
解释专用处理器的定义(FSD中的NNU、Xavier中的DLA等);
-
解释为什么Xavier中30 TOPS作为主要量化指标;
-
对汽车界大明星——英飞凌的TriCore™的计算力进行直观解释。
-
高算力芯片需求的背后:智能汽车E/E架构的发展
-
智能汽车AI芯片大集锦
前几年,各大车厂和自动驾驶运营商好像一直将2020年看成是自动驾驶汽车发展的一个分水岭,一度把L3级自动驾驶汽车落地量产当成2020年的目标。
虽然现实距离理想总是有一段距离,但在2020年,活跃在PPT中的自动驾驶汽车无疑离人们更近了一步。
所以,在今天,解决自动驾驶问题的关键是在于单点的技术,单点技术做到极致,并超越人类,这项技术才是可用的。比如对于车道线、对于交通指示牌的识别等,而这其中需要强大的计算能力做支持。硬件和软件算法向来是躯体和灵魂,密不可分。市场对自动驾驶芯片的算力和性能提出了新的要求。自动驾驶芯片成为新的角逐点。
1. 芯片算力如何计算?
咱们先学习下算力单位的基本概念:
OPS(Operations Per Second):每秒完成操作的数量,乘操作算一个OP,加操作算一个OP。1TOPS表示每秒进行1万亿次操作。OPS主要是深度学习的算力单位。
MACS:表示每秒可执行的定点乘累加操作次数,用于衡量自动驾驶计算平台定点数据运算处理能力。1GMACS等同每秒10亿次的定点乘累加运算。Ops/s(每秒完成的操作数量)指的是通过每秒可以完成多少个MAC(每次乘法和累加各被认为是1个operation,因此MAC实际上是 2 个 OP)得到,即1 MAC=2 OPS。
FLOPS(Floating-Point Operations Per Second):每秒可执行的浮点运算次数的字母缩写,它用于衡量计算机浮点运算处理能力。浮点运算,包括了所有涉及小数的运算。浮点运算比整数运算更复杂、更精确、更耗费时间。
DMIPIS:是测量处理器运算能力的最常见基准程序之一,常用于处理器的整型运算性能的测量。MIPS:每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。
2. 特斯拉 FSD 芯片144 TOPS 如何计算的

特斯拉在抛弃Mobileye和NVIDIA之后,开始自研AI芯片,于2019年发布了首款自动驾驶芯片(FSD)。FSD 芯片采用了 14 nm FinFET CMOS 工艺制造,尺寸为 260 mm,具有 60 亿个晶体管和 2.5 亿个逻辑门。这款SoC芯片的基本组成部分,包括CPU(12核A72,主频为2.2GHz),GPU,各种接口,片上网络。芯片中最重要的部分是自研的Neural Network Processor(NNP),支持 32 位和 64 位浮点运算的图形芯片。
每颗芯片有两个NNP,每个NNP有一个96x96个MAC的矩阵,32MB SRAM,主频是2GHz。所以一个NNP的处理能力是96x96x2(OPs)x2(GHz)=36.864TOPS,单芯片的计算力是72TOPS,板卡144TOPS。

3. NVIDIA GPU芯片TFLOPS 如何计算
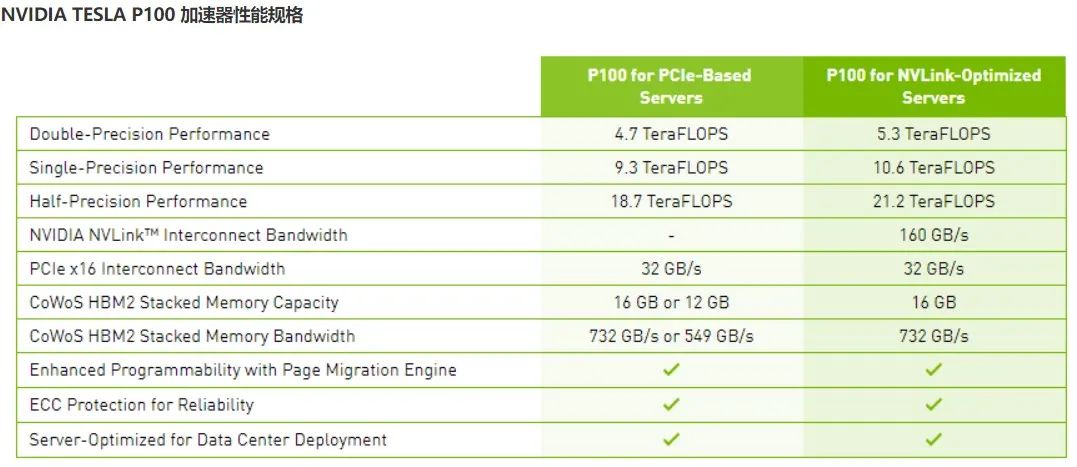
GPU的浮点计算理论峰值能力测试跟CPU的计算方式基本一样:
理论峰值 = GPU芯片数量*GPU Boost主频*核心数量*单个时钟周期内能处理的浮点计算次数。
对于浮点计算来说,CPU可以同时支持不同精度的浮点运算,但在GPU里针对单精度和双精度就需要各自独立的计算单元。一般在GPU里支持单精度运算的Single Precision ALU称之为FP32 core或简称core,而把用作双精度运算的Double Precision ALU称之为DP unit或者FP64 core,在Nvidia不同架构不同型号的GPU之间,这两者数量的比例差异很大。
在第五代的GPU Pascal架构里,FP64 core:FP32 core=1:2。
所以在P100中:
双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.48GHz * 2 = 10.6 TFlops
因为P100还支持在一个FP32里同时进行2次FP16的半精度浮点计算,所以对于半精度的理论峰值更是单精度浮点数计算能力的两倍也就是达到21.2TFlops 。
4. 解析NVIDIA Xavier 最负盛名的自动驾驶控制器

Xavier芯片主要由NVIDIA自研的Carmel架构8核64位CPU和Volta架构512 CUDA处理器GPU这两大模块组成,这两部分电路占据了芯片的大部分空间。
8个CPU核心被平均分配为4个集群,每个集群都有一个独立的时钟平面,并在2个CPU核心之间共享2MB L2缓存,在其之上,4个集群共享4MB L3缓存。Carmel架构是之前Denver架构的继任者,其设计特点是强大的动态代码优化能力。NVIDIA对外表示Carmel是一个10宽度的超标量架构(10个执行端口,非10宽度解码),并且支持ARMv8.2+RAS指令集。

Xavier的GPU源于Volta架构,内部结构被划分为4个TPC(纹理处理集群),每个TPC具有2个SM(流式多处理器),每个SM集成64个CUDA核心(即流处理器),共计512个CUDA核心,其单精度浮点运算性能为2.8TFLOPS,双精度为1.4TFLOPS。此外Xavier还从Volta那里继承了Tensor Core,其8bit运算性能为22.6Tops,16bit运算性能为11.3TFLOPS。
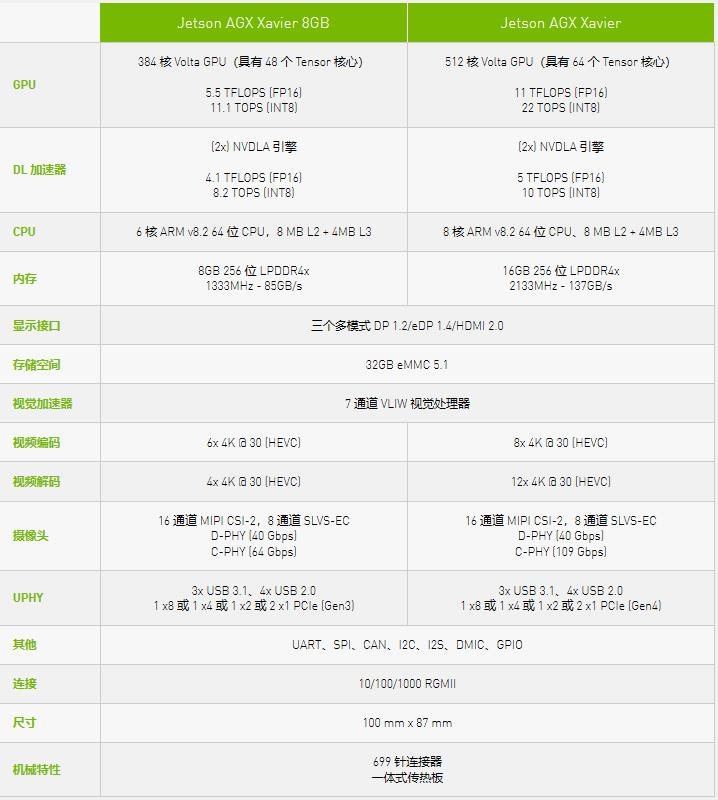
总结:Xavier内有六种不同的处理器:ValtaTensorCore GPU,八核ARM64 CPU,双NVDLA深度学习加速器,图像处理器,视觉处理器和视频处理器。
各类处理器的性能参数:
深度学习加速器(DLA):5 TOPS (FP16) | 10 TOPS (INT8)
VoltaGPU:512 CUDA cores | 20 TOPS(INT8) | 1.3 TFLOPS (FP32)
视觉处理器:1.6 TOPS
立体声和光流引擎(SOFE):6 TOPS
图像信号处理器(ISP):1.5 Giga Pixels/s
视频编码器:1.2 GPix/s
视频解码器:1.8 GPix/s
说到这里,可能会有疑问,为什么没有30TOPS出现呐?
其实30TOPS仅仅是Xavier中GPU在深度学习的计算力。
那就又存在疑问了,那经常各大供应商在宣传自己的自动驾驶控制器或者在选择Xavier时,会将30TOPS作为主要的参考指标呐?
其实也没错,因为在自动驾驶的算法中,吃算力的感知算法的确离不开机器学习和深度学习。如果能满足感知算法的算力要求,满足自动驾驶的传感器处理、测距、定位和绘图、视觉和激光感知等,那么从算力角度是可以当成自动驾驶芯片进行使用和开发。
5. 解析NVIDIA Orion自动驾驶控制器

2019年12月英伟达发布了新一代面向自动驾驶和机器人领域Orin芯片和计算平台。具有ARM Hercules CPU内核和英伟达下一代GPU架构。Orin SoC包含170亿晶体管,晶体管的数量几乎是Xavier SoC的两倍,具有12个ARM Hercules内核,将集成Nvidia下一代Ampere架构的GPU,提供200 TOPS@INT8性能,接近Xavier SoC的7倍,Orin SOC将在2021年提供样片,2022年正式面向车厂量产。
2020年5月GTC上,英伟达介绍了即将发布的新一代自动驾驶Drive AGX Orin平台,它可以搭载两个Orin SoC和两块NVIDIA Ampere GPU,可以实现从入门级ADAS解决方案到L5级自动驾驶出租车(Robotaxi)系统的全方位性能提升,平台最高可提供2000TOPS算力。未来L4/L5级别的自动驾驶系统将需要更复杂、更强大的自动驾驶软件框架和算法,借助强劲的计算性能,Orin计算平台将有助于并发运行多个自动驾驶应用和深度神经网络模型算法。
作为一颗专为自动驾驶而设计的车载智能计算平台,Orin可以达到ISO 26262 ASIL-D 等级的功能安全标准。
借助于先进的7nm制程工艺,Orin拥有非常出色的功耗水平。在拥有200TOPS的巨大算力时,TDP仅为50W。NVIDIA Orin处理器功能模块图

6. 解析NVIDIA Thor自动驾驶控制器

NVIDIA DRIVE Thor 是NVIDIA新一代集中式车载计算平台,可在单个安全、可靠的系统上运行高级驾驶员辅助应用和车载信息娱乐应用。DRIVE Thor 超级芯片借助我们新的 CPU 和 GPU 突破,可提供出色的 2000 万亿次浮点运算性能,同时降低总体系统成本,计划于2025年开始量产。
可以看到三域开始变两域了,智驾和座舱统一了,一统天下看来指日可待了,就需要利用安全技术解决最后一个车控MCU就可以了。
DRIVE Thor 还在深度神经网络准确性方面实现了令人难以置信的飞跃。Transformer 引擎是NVIDIA GPU Tensor Core的新组件。Transformer 网络将视频数据作为单个感知帧进行处理,使计算平台能够随着时间的推移处理更多数据。
该SoC能够进行多域计算,这意味着它可以划分自动驾驶和车载信息娱乐的任务。这种多计算域隔离可以让并发的时间关键进程不间断地运行。在一台计算机上,车辆可以同时运行Linux、QNX和Android。通常,这些类型的功能由分布在车辆各处的数十个电子控制单元控制。制造商现在可以利用 DRIVE Thor 隔离特定任务的能力来整合车辆功能,而不是依赖这些分布式ECU。

7. 处理器为什么起的名字都不一样
刚第一次看到上面Xavier中,存在各类处理器,有点小晕。这边汽车人参照网上资料,浅显解释一下,就可以很好理解。
其实这些各类处理器就是专用处理器。专用处理器就是针对特定应用或者领域的处理器,类似于是我们经常说的Domain Specific Architecture的概念。
最为通用的处理器当然是CPU(比如intel的桌面CPU,ARM的嵌入式CPU),可以运行任何程序,处理各种数据。但问题是CPU对某些应用效率太低(处理能力不够,无法实时处理,或者是能耗太大)。比如,处理图像不行,于是出现了GPU;信号处理不行,于是出现了DSP。GPU可以做图像处理,也可以做DNN的training和inference,但是在处理某些DNN应用的时候效率不高,于是有了专用针对这些应用处理器,也就是像上面说的DLA处理器。
8. 英飞凌 TriCore™ 算力分析
英飞凌 TriCore™在业界也是屡获殊荣,基于统一的RISC/MCU/DSP处理器内核,拥有强大的计算能力。
TriCore™特性:
位和位段的寻址和操作、快速上下文切换(4个周期)和低中断延迟16位和32位指令、双16位乘法器累加器,每个时钟的两个16x16 MAC的持续吞吐量等。
那么以275为例,主频为200MHz,包含3个TriCore™核心CPU。
则英飞凌中AURIX家族的TC 275峰值处理能力=16x16x2(OPs)x2x200(Mhz)x3=614400 OPS=0.61TOPS。
9. 高算力芯片需要的背后:智能汽车E/E架构的发展
引用一句大家都熟悉的话,目前E/E 构架设计面临4大挑战:功能安全、实时性、带宽瓶颈、算力黑洞。
具体解释就是:在功能复杂度持续提升的情况下满足功能安全的等级要求,包括ISO26262、SOTIF和RSS;在复杂的架构和功能框架下满足实时性的保证;指数级增长的传感器数据和爆炸式的网联数据造成的带宽瓶颈;满足软件持续升级所需要的算力黑洞。
因此,智能汽车E/E架构正从分布式走向集中式,其终极形态是超级计算机。
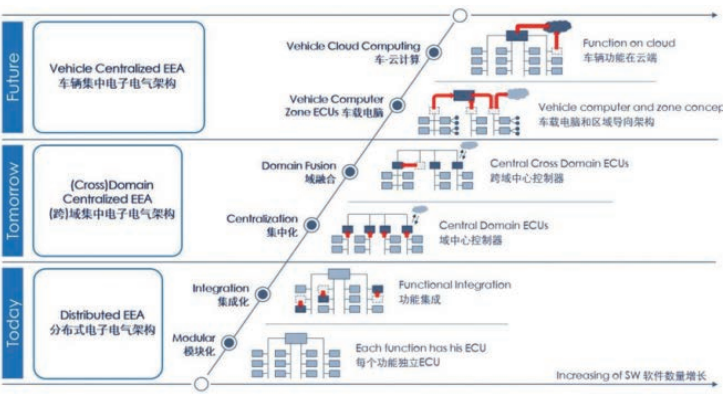
博世的渐进式路线是目前E/E架构发展的典型路径。从图中可以看出,整体的发展趋势是计算集中化。
伴随着计算集中化的产生,存在一个新的概念。图中可以看出,在域融合的下一阶段,是“车载电脑和区域导向结构”。区域导向结构的关键在于配合车载电脑,完成执行器 、传感器 、诊断以及传统I/O 的连接汇总,顺利完成高级决策功能,其类似于PC中的南北桥。
在这种情况下,拿军事打个比方。域概念就像是按照职能划分海陆空三军(车身域、底盘域、娱乐域、安全域),并且有独立的作战权。那么车载电脑和区域导向结构概念则是按照战区进行组织划分 ,与中央计算机形成了联合作战司令部+战区的概念。这样,中央计算机进行统筹兼顾、作出重大决策,对控制器的算力要求显著提升。
另一方面,在未来,OEM交付的汽车将不是一个功能固化的产品,而是一个持续进化的机器人,在汽车整个生命周期内,硬件平台需要持续支持软件迭代升级,这意味着必须打造一个开放的、工具链完善的、拥有强大算力保障的计算平台,提供高达1000 TOPS的算力,为各种软件功能提供充足的算力储备。
智能汽车E/E架构的发展势必导致对高算力芯片的需求。我们一直强调说,软件定义汽车,其实AI芯片何尝不是由软件定义。本质上讲,芯片和构架是手段和载体,软件是目的和灵魂。软硬件一起做 ,可以让手段和目的高度统一。
只有硬件俯下身来去适配软件的时候,才能够使晶体管所发挥的效能大幅度增加。处理器构架的创新是一个非常高的壁垒,需要对软件有深刻理解。这样的整体解决方案决定了数据转化为决策/服务的效率和质量,是时代真正呼唤的硬科技,满足汽车对芯片高算力且低功耗的要求。
10. 智能汽车AI芯片大集锦
| 公司 名称 | 产 品 | 产品参数 | 应用 |
| 百度 | 云端全功能AI芯片 | 内存带宽:512 GBps; 算力:峰值260 Tops算力; 功耗:150w; 计算速度:推理速度比传统 GPU/FPGA 加速模型快 3 倍。 | 支持包括大规模人工智能计算在内的多种功能,例如搜索排序、语音识别、图像处理、自然语言处理、 自动驾驶和 PaddlePaddle等深度学习平台。 |
| 地 平 线 | 征 程 | 架构:自研BPU 算力:4TOPS 功耗:2W | 自动驾驶中对车辆、行人和道路环境等目标的感知,类似MobileyeQ系列芯片; Matrix2平台,基于Journey征程2芯片,算力达到16Tops |
| 旭 日 | 面向智能摄像头 | ||
| 华 为 | 昇 腾 310 | 算力:16 TOPS; 功耗:8W; 能效: 2 TOPS/W 集成了FPGA和ASIC两款芯片的优点,包括ASIC的低功耗以及FPGA的可编程、灵活性高等特点。 | MDC300:由华为昇腾Ascend310芯片、华为鲲鹏芯片、Infineon的TC397组成;算力为64Tops。 MDC600:基于8颗昇腾310 AI芯片,同时还整合了CPU和相应的ISP模块,算力高达352 TOPS。 |
| 寒 武 纪 | Cam bricon-1M | int 8(8位运算)效能比:5Tops/W; 提供了2Tops、4Tops、8Tops三种尺寸的处理器内核。 | 支持CNN、RNN、SVM、k-NN等多种深度学习模型与机器学习算法的加速,能够完成视觉、语音、自然语言处理等任务 |
| 云端 智能 芯片 Cam bricon MLU 100 | 平衡模式(主频 1Ghz):128万亿次定点运算;功耗80w。 高性能模式(主频1.3GHz):166.4万亿次定点运算,功耗110w。 | ||
| 黑 芝 麻 | 华山 二号 A1000 | 8个CPU核; NN算力:40 ~70TOPS, 功耗:8-10W | 适用于低等级级ADAS辅助驾驶;单颗A1000芯片适用于L2+自动驾驶;双A1000芯片互联组成的域控制器可支持L3级别自动驾驶;四颗A1000芯片叠加可用于未来L4级别自动驾驶。 A1000L适用于ADAS,计算力为16TOPS ,功耗为5W; A1000适用于 L2+, 计算力为70TOPS 功耗为10W; A1000*2适用于 L3, 计算力为140TOPS, 功耗为25w; A1000*4适用于l3/L4 ,计算力为280TOPS,功耗为 60W。 |
| Xilinx赛 灵 思 | MP SoC 系列 | 双核/四核 ARM Cortex A53 (达1.5Ghz) 速率高达 600Mhz的四核 ARM Cortex-R5 MPCore 频率高达 667Mhz的GPU ARM,支持 H.264-H.265的视频编解码器 | 经被包括戴姆勒奔驰在内的29个汽车品牌以及Aptiv、Autoliv、博世和大陆集团等顶级零部件供应商广泛使用 |
| 特 斯 拉 | FSD | 配备了两个神经网络处理器(NNP) 算力:144 TOPS; 功耗:72W; 能效比: 2TOPS/W | |
| NVI DIA | Xavier | 8核ARM64架构; GPU采用512颗CUDA的Volta; 支持FP32/ FP16/INT8; 20W功耗下单精度浮点性能1.3TFLOPS; Tensor核心性能20TOPs,解锁到30W后可达30TOPS. | |
| Orin | 170亿个晶体管; 搭载NVDIA下一代GPU(即基于Ampere架构的GPU)和Arm Hercules CPU核心; 可以提供200TOPS是运算能力,是上一代Xavier SOC的7倍; 功耗45W; 2022年交付. | ||
| Mobil eye | EyeQ系列 | 最高的EyeQ4的算力2.5 TOPS; 功耗:3W; 能效: 0.83 TOPS/W | |
| EyeQ5 | 计算力:24TOPS; 功耗:10W;芯片能效是Xavier的2.4倍。EyeQ5芯片将装备8枚多线程CPU内核,同时还会搭载18枚Mobileye的下一代视觉处理器 | 全视觉方案 |

