
- 1one piece_娜美_01_one piece hentai
- 2CrossOver软件2023破解激活码_crossover-wine注册
- 3Spring Boot(四):Thymeleaf 使用详解_spring thymeleaf
- 4NX+Ubuntu18.04+ROS Realsense(RealSenseD435i )的安装与使用_realsense安装
- 5记录:rosdep update
- 6js通过a标签的方式下载文件并对其重命名的完整方案_a标签下载文件重命名
- 7JavaScript中的Array.prototype.forEach()方法(简介+重写)_js array.prototype.foreach
- 8leetcode 94 二叉树的中序遍历(java)_lecode中树的输入root = [1,null,3,2,4,null,5,6]是怎么转化成节点的
- 9R语言入门笔记2.1
- 10c#--正则表达式(项目常用)_c# 正则表达式 数字
基于TensorFlow和Keras的图像识别
赞
踩
来源:深度学习爱好者
简介
TensorFlow和Keras最常见的用途之一是图像识别/分类。通过本文,您将了解如何使用Keras达到这一目的。
定义
如果您不了解图像识别的基本概念,将很难完全理解本文的内容。因此在正文开始之前,让我们先花点时间来了解一些术语。
TensorFlow/Keras
TensorFlow是Google Brain团队创建的一个Python开源库,它包含许多算法和模型,能够实现深度神经网络,用于图像识别/分类和自然语言处理等场景。TensorFlow是一个功能强大的框架,通过实现一系列处理节点来运行,每个节点代表一个数学运算,整个系列节点被称为“图”。
Keras是一个高级API(应用程序编程接口),支持TensorFlow(以及像Theano等其他ML库)。其设计原则旨在用户友好和模块化,尽可能地简化TensorFlow的强大功能,在Python下使用无需过多的修改和配置
图像识别(分类)
图像识别是指将图像作为输入传入神经网络并输出该图像的某类标签。该标签对应一个预定义的类。图像可以标记为多个类或一个类。如果只有一个类,则应使用术语“识别”,而多类识别的任务通常称为“分类”。
图像分类的子集是对象检测,对象的特定实例被识别为某个类如动物,车辆或者人类等。
特征提取
为了实现图像识别/分类,神经网络必须进行特征提取。特征作为数据元素将通过网络进行反馈。在图像识别的特定场景下,特征是某个对象的一组像素,如边缘和角点,网络将通过分析它们来进行模式识别。
特征识别(或特征提取)是从输入图像中拉取相关特征以便分析的过程。许多图像包含相应的注解和元数据,有助于神经网络获取相关特征。
神经网络如何学习识别图像
直观地了解神经网络如何识别图像将有助于实现神经网络模型,因此在接下来的几节中将简要介绍图像识别过程。
使用滤波器进行特征提取
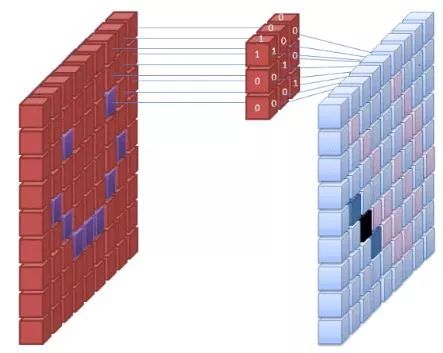
图片来源:commons.wikimedia.org
神经网络的第一层接收图像的所有像素。当所有的数据传入网络后,将不同的滤波器应用于图像,构成图像不同部分的表示。这是特征提取,它创建了“特征映射”。
从图像中提取特征的过程是通过“卷积层”完成的,并且卷积只是形成图像的部分表示。由卷积的概念延伸出卷积神经网络(CNN)这一术语,它是图像分类/识别中最常用的神经网络类型。
如果您无法想象特征映射是如何创建的,可以试想将手电筒照在暗室图片的景象。当光束滑过图片时,您正在学习图像的特征。在这个比喻中,手电筒发射的光束就是滤波器,它被网络用于形成图像的表示。
光束的宽度控制着一次扫过的图像的区域大小,神经网络具有类似的参数,即滤波器的大小。它影响一次扫过的图像的像素数。CNN中常见的滤波器尺寸为3,这包括高度和宽度,因此所扫描的像素区域大小为3×3。

图片来源:commons.wikimedia.org
虽然滤波器的尺寸覆盖其高度和宽度,同时也需要明确滤波器的深度。
2D图像如何具有深度?
数字图像被渲染为高度、宽度和一些定义像素颜色的RGB值,因此被跟踪的“深度”是图像具有的颜色通道的数量。灰度(非彩色)图像仅包含1个颜色通道,而彩色图像包含3个颜色通道。
这意味着对于应用于全彩色图像的尺寸为3的滤波器,其规模为3×3×3。对于该滤波器覆盖的每个像素,神经网络将滤波器的值和像素本身的值相乘以获取像素的数值表示。然后,对整个图像完成上述过程以实现完整的表示。根据参数“步幅”,滤波器在图像的其余部分滑动。该参数定义了在计算当前位置的值之后,滤波器要滑动的像素数。CNN的默认步幅取值为2。
通过上述计算,最终将获取特征映射。此过程通常由多个滤波器完成,这有助于保持图像的复杂性。
激活函数
当图像的特征映射创建完成之后,表示图像的值将通过激活函数或激活层进行传递。受卷积层的影响,激活函数获取的表示图像的值呈线性,并且由于图像本身是非线性的,因此也增加了该值的非线性。
尽管偶尔会使用一些其他的激活函数,线性整流函数(Rectified Linear Unit, ReLU)是最常用的。
池化层
当数据被激活之后,它们将被发送到池化层。池化对图像进行下采样,即获取图像信息并压缩,使其变小。池化过程使网络更加灵活,更擅长基于相关特征来识别对象/图像。
当观察图像时,我们通常不关心背景信息,只关注我们关心的特征,例如人类或动物。
类似地,CNN的池化层将抽象出图像不必要的部分,仅保留相关部分。这由池化层指定的大小进行控制。
由于池化层需要决定图像中最相关的部分,所以希望神经网络只学习真正表示所讨论对象的部分图像。这有助于防止过度拟合,即神经网络很好地学习了训练案例,并无法类推到新数据。
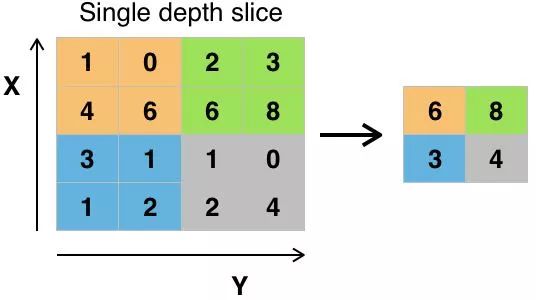
图片来源:commons.wikimedia.org
池化值的方式有多种,最大池化(max pooling)是最常用的。最大池化获取单个滤波器中像素的最大值。假设使用卷积核大小为2×2的滤波器,将会丢失3/4的信息。
使用像素的最大值以便考虑可能的图像失真,并且减小图像的参数/尺寸以便控制过度拟合。还有一些其他的池化类型,如均值池化(average pooling)和求和池化(sum pooling),但这些并不常用,因为最大池化往往精确度更高。
压平(Flattening)
CNN的最后一层,即稠密层,要求数据采用要处理的矢量形式。因此,数据必须“压平”。值将被压缩成向量或按顺序排列的列。
全连接层
CNN的最后一层是稠密层,或人工神经网络(ANN)。ANN主要用于分析输入特征并将其组合成有助于分类的不同属性。这些层基本上形成了代表所讨论对象的不同部分的神经元集合,并且这些集合可能代表狗松软的耳朵或者苹果的红色。当足够的神经元被激活用于响应输入图像时,该图像将被分类为某个对象。
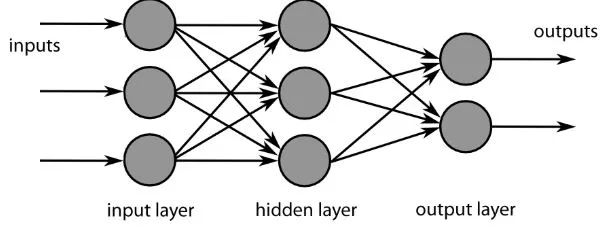
图片来源:commons.wikimedia.org
数据集中计算值和期望值之间的误差由ANN进行计算。然后网络经过反向传播,计算给定神经元对下一层神经元的影响并对其进行调整。如此可以优化模型的性能,然后一遍又一遍地重复该过程。以上就是神经网络如何训练数据并学习输入特征和输出类之间的关联。
中间的全连接层的神经元将输出与可能的类相关的二进制值。如果有四个不同的类(例如狗,汽车,房子以及人),神经元对于图像代表的类赋“1”,对其他类赋“0”。
最终的全连接层将接收之前层的输出,并传递每个类的概率,总和为1。如果“狗”这一类别的值为0.75,则表示该图像是狗的确定性为75%。
至此图像分类器已得到训练,并且可以将图像传入CNN,CNN将输出关于该图像内容的猜想。
机器学习的工作流
在开始训练图像分类器的示例之前,让我们先来了解一下机器学习的工作流程。训练神经网络模型的过程是相当标准的,可以分为四个不同的阶段。
数据准备
首先,需要收集数据并将其放入网络可以训练的表中。这涉及收集图像并标记它们。即使下载了其他人准备好的数据集,也可能需要进行预处理,然后才能用于训练。数据准备本身就是一门艺术,包括处理缺失值,数据损坏,格式错误的数据,不正确的标签等。
创建模型
创建神经网络模型涉及各种参数和超参数的选择。需要确定所用模型的层数,层输入和输出的大小,所用激活函数的类型,以及是否使用dropout等。
训练模型
创建模型后,只需创建模型实例并将其与训练数据相匹配即可。训练模型时,一个重要的因素即训练所需时间。您可以通过指定训练的epoch数目来指定网络的训练时长。时间越长,其性能就越高,但是epoch次数过多将存在过度拟合的风险。
您可以适当地设置训练时的epoch数目,并且通常会保存训练周期之间的网络权重,这样一旦在训练网络方面取得进展时,就无需重新开始了。
模型评估
评估模型有多个步骤。评估模型的第一步是将模型与验证数据集进行比较,该数据集未经模型训练过,可以通过不同的指标分析其性能。
评估神经网络模型的性能有各种指标,最常见的指标是“准确率”,即正确分类的图像数量除以数据集中的图像总和。
在了解模型性能在验证数据集上的准确率后,通常会微调参数并再次进行训练,因为首次训练的结果大多不尽人意,重复上述过程直到对准确率感到满意为止。
最后,您将在测试集上测试网络的性能。该测试集是模型从未用过的数据。
也许您在想:为什么要用测试集呢?如果想了解模型的准确率,采用验证数据集不就可以了吗?
采用网络从未训练过的一批数据进行测试是有必要的。因为所有参数的调整,结合对验证集的重新测试,都意味着网络可能已经学会了验证集的某些特征,这将导致无法推广到样本外的数据。
因此,测试集的目的是为了检测过度拟合等问题,并且使模型更具实际的应用价值。
英文原文:https://stackabuse.com/image-recognition-in-python-with-tensorflow-and-keras/
END
欢迎加入Imagination GPU与人工智能交流2群

入群请加小编微信:eetrend77
(添加请备注公司名和职称)
推荐阅读
对话Imagination中国区董事长:以GPU为支点加强软硬件协同,助力数
【白皮书下载】Imagination如何完成系统开发流程通过ASIL-D认证
Imagination Technologies 是一家总部位于英国的公司,致力于研发芯片和软件知识产权(IP),基于Imagination IP的产品已在全球数十亿人的电话、汽车、家庭和工作 场所中使用。获取更多物联网、智能穿戴、通信、汽车电子、图形图像开发等前沿技术信息,欢迎关注 Imagination Tech!


