
- 1手把手教你从微软官网上下载系统镜像【保持最新版】_微软系统镜像官网
- 2Git小乌龟的安装及简单使用_git小乌龟安装
- 3【纯手撸】使用PySide6 / pyqt 搭建现代化普通B端系统图形化界面_python pyside6 做资源管理器框架界面
- 4408数据结构笔记整理
- 5区块链技术的应用前景及挑战_一个企业如果要实施区块链技术有哪些挑战
- 6arkTS开发鸿蒙OS个人商城案例【2024最新 新年限定开发案例QAQ】_arkts案例
- 7uni-app 微信小程序之自定义navigationBar顶部导航栏_微信小程序自定义顶部导航栏(兼容适配所有机型)
- 8Java stringbuilder与string相互转换_stringbuilder转string
- 9大模型时代,程序员需要具备哪些技能才能胜任?
- 10HDFS 架构剖析_简述hdfs架构
基于数据驱动的人脸识别课题研究_人脸识别国内外研究现状
赞
踩
摘要
人脸识别技术是指根据人脸的面部特征,对人脸进行识别,通 过人脸识别技术进行身份识别,是一种方便有效的方式,跟其他身 份识别方式相比,具有方便,不宜复制等优点。因此可以广泛用于 门禁识别,安防监控等领域。基于此需求,本文提出了人脸识别技术在住宅小区安全监测中的应用。人脸识别技术的核心问题是识别计算机的能力。它可以促进人工智能、模式识别和计算机视觉等相关领域的发展。它具有一定的理论意义。人脸识别在信息安全、医疗保健、安全监控、人机交互、金融等领域有着广泛的应用。
人脸识别包括人脸检测、预处理、特征提取和人脸检测四个主要步骤。本文对上述步骤进行了研究。主要内容如下:
1、研究了局部二值模式(LBP)人脸特征的表达和提取方法,比较了直方图均衡化、高斯平滑和Sobel边缘提取三种预处理方法对LBP识别率的影响。通过比较发现,不同的预处理方法对LBP算法有不同的影响。其中,LBP算法与索贝尔相结合提高了不同光照条件下人脸图像的识别率。
2、通过实验验证了基于LBP人脸识别方法的块大小对LBP算子性能的影响。实验表明,识别率越高,识别率越高,识别率越低。
3、提出了一种结合LBP特征提取和支持向量机(SVM)分类器的算法,并在FRET人脸库中使用支持向量机分类器和最近邻分类器对实验进行比较。实验表明,支持向量机分类器结合LBP特征提取方法具有较好的分类性能。
最后,对全文的工作进行了总结。
关键词:人脸识别;局部二值模式;预处理;支持向量机。
Abstract
The key issue of face recognition is how to make computer identify the specific person, It can speed up the development of the Artificial Intelligence,Pattern recognition and Computer Vision.and it is very significant in theoretical aspect. At the same time,face recognition is of wide potential applications, such as information security,medical treatment,security monitoring, human-computer interaction, and the finance,and so on.Face recognition mainly consists of four basic steps: face detection,pretreatment,feature extraction and face judgment. The main contents are as follows:
1.Study on the LBP representation and extraction of the facial features,compare the LBP recognition rate with the three kinds of pretreatment methods of histogram equalization, Gaussian smoothing, Sobel edge detection.Experiment found that different pretreatment on the LBP algorithm induces different influence.The recognition rate of LBP algorithm with Sobel under different light conditions increase larger.
2.Experiments validate the face recognition method based on LBP,
observing the block-size effects on the performance of the LBP operator.Experiments show that the more block, the more higher the recognition rate,but blocks too much lead to a fall in the recognition rate.
3.The thesis combin LBP algorithm with classification,through experiment compare the classification result of support vector machine classifier and nearest neighbor classifier.The results show the combination of LBP feature extraction method and support vector machine classifier has a better classification performance.
The last,The thesis make a summary for all of work.
Key Words: face recognition;LBP;pretreatment;SVM
1 项目研究背景
1.1 课题研究背景及意义
人脸识别技术在商业、军事、政府和其他领域中都有着广阔的应用前景。例如信息安全、档案管理、出入口控制、医疗、刑事侦破、保安监视、人机交互系统、视频会议等场合。在经济和电子商务领域,对各种银行卡、储蓄卡的持卡人身份进行验证。在家庭娱乐方面,有智能玩具、家政机器人、真实感虚拟游戏等。主要典型应用有:
①身份鉴定:将采集到的脸部数据进行处理后与人脸数据库中的数据进行实时的对比,按相似度进行排序,给出鉴定的结果或相对应的可信度。可用于计算机、网络安全、金融业务、边境控制、访问控制等领域。例如,2008 年北京奥运会入场检测首次采用了人脸识别技术对入场者进行身份识别;2009 年国庆阅兵武器管理以及天安门广场日常安全监控系统都采用了人脸识别技术。
②身份确认:将实时采集到的人脸数据和存储在智能卡或其他存储设备中的人脸数据进行对比,相似度达到一定程度,则对比成功即可以确定用户身份。身份确认可应用于选民登记、身份证、护照、驾驶执照、工作证、机场安检口身份证检查及结合犯罪嫌疑人识别系统的安检口控制系统等。利用人脸特征识别用户,保护计算机信息,及人脸屏幕保护和文件加密。
③视频监控:人脸识别技术可以用摄像机对人进行连续跟踪和定位,将人脸从背景中分离出来,与监控列表进行比对,具有连续实时性、不被干扰等点。在对图像进行分析时,用到人脸检测、跟踪及识别等技术。该技术可应用于闭路电视监控、交通管理、脸部照片登记系统、事件后分析系统,以及基于Internet 的网上追逃系统等。
1.2 人脸识别国内外研究现状
人脸识别国内外研究现状如下:
目前,国内从事人脸识别技术研究的主要专业机构和相关人员包括:
中国科学院计算所,高文教授和陈熙霖教授带领的研究小组在人脸检测、大型人脸数据 库的建立、人脸识别算法的实用化等方面取得了丰硕成果;
中国科学院自动化所,谭铁牛研究员领导的研究小组提出将人脸特征与其它生物特征相 融合的方法,大幅度改善了单一生物特征识别的效果;
生物特征识别与安全技术研究中心,李子青教授带领的研究小组在近红外人脸识别和中 远距离人脸识别的研究中获得了显著成果,有效降低了光照对人脸识别性能的影响。
国外人脸识别技术的研究主要以美国、欧洲、日本等国家为主。例如:
美国哈佛大学(Harvard University)的 Stone Z 等人提出了一种基于社交语境下的大规模 人脸识别方法;英国格拉斯哥大学(University of Glasgow)的 Mike 教授和斯特林大学(University of Stirling)的 Bruce 教授领导的研究组,主要从事大脑在人脸识别中的作用和人 脸感知方面的研究。
人脸识别技术的发展最早始于上世纪60年代末。它主要经历了三个阶段:第一阶段是1964-1990年,是人脸识别的初级阶段,其主要方法是基于人脸的几何结构特征。以Bertillon、艾伦和帕克为代表,研究了人脸识别所需的人脸特征,计算出各特征点之间的几何距离,并利用最近邻法和其他分类方法对人脸进行识别。识别过程由人工操作完成。这是一个非自动识别过程。在这一阶段,结果很少,实际应用也不多。第二阶段为1991~1997年。人脸识别研究正在迅速发展。这是人脸识别研究的高潮。已经产生了一些代表性的人脸识别算法,并且许多商业操作的人脸识别系统已经诞生,并且美国军方还组织了一个著名的FRET人脸识别算法测试。其中,重要的结果是Turk和Pentland提出的“特征脸”方法,并成为人脸识别性能识别的基准算法。一般来说,线性子空间判别分析、统计外观模型和统计模式识别方法是现阶段的主流技术。在理想条件下,该算法能取得令人满意的结果。第三阶段是从1998到现在。它属于机器识别阶段,用户不合作、不合意的采集条件、光照和姿态等问题逐渐成为研究热点。这一时期的重要成果是基于Georghiades等人提出的光锥模型的人脸识别等。基于Blanz和维特尔提出的基于三维变形模型的人脸识别技术,在姿态变化、光照变化、年龄和表情变化的条件下,提高了人脸识别的性能。以支持向量机为代表的统计学习理论也被应用于人脸识别。
2 图像预处理
从广义上讲,人脸识别过程包括人脸检测、图像预处理、人脸特征提取和人脸识别四个部分。
人脸检测是指任何图像或视频输入判断是否有人脸。如果有人脸,则区分人脸区域和背景,并给出人脸的位置、大小和其他相关信息。它还可以在一系列图像序列或动态视频和人脸跟踪中实时检测人脸。人脸检测主要受光照、噪声、姿态和遮挡等因素的影响。人脸检测作为人脸识别系统的第一步,直接关系到人脸识别的准确性和可行性,影响整个系统的性能。人脸检测与跟踪是人脸识别研究中的一项关键技术,具有很高的学术价值。模型的特点是复杂的,很难找到一个常用的算法来检测,所以在应用中经常会集成很多模式来检测。本章将详细分析图像预处理。
2.1 图像缩放
图像因大小不同,不可以直接使用,需要对图像进行预处理使得图像大小一致。
假如图像的象素矩阵如下图所示(这个原始图把它叫做源图,Source):
234 38 22
67 44 12
89 65 63
这个矩阵中,元素坐标(x,y)是这样确定的,x从左到右,从0开始,y从上到下,也是从零开始,这是图象处理中最常用的坐标系,就是这样一个坐标:
---------------------->X
|
|
|
|
|
∨Y
如果想把这副图放大为 4X4大小的图像,那么该怎么做呢?那么第一步肯定想到的是先把4X4的矩阵先画出来再说,好了矩阵画出来了,如下所示,当然,矩阵的每个像素都是未知数,等待着我们去填充(这个将要被填充的图的叫做目标图,Destination):
? ? ? ?
? ? ? ?
? ? ? ?
? ? ? ?
常用的插值方法有:最近邻插值、双线性插值、三次卷积法。
在进行数字图像处理时,经常会遇到十进制像素坐标值的问题,因此需要根据相邻像素的值插值坐标。例如:地图投影转换,将目标图像中的一个像素坐标变换到对应点上的源图像,变换的坐标是一个十进制,例如,几何校正的图像,也会遇到同样的问题。下面是三种常用的数字图像插值方法。
1、最邻近元法
这是最简单的插值方法。它不需要计算。在像素的四个相邻像素中,像素的最近像素灰度被给予最近像素中的像素。设i+u, j+v(i, j为正整数, u, v为大于零小于1的小数,下同)为待求象素坐标,则待求象素灰度的值 f(i+u, j+v) 如图1.1所示:

图1.1 像素坐标最邻近元法
如果(i+u, j+v)落在A区,即u<0.5, v<0.5,则将左上角象素的灰度值赋给待求象素,同理,落在B区则赋予右上角的象素灰度值,落在C区则赋予左下角象素的灰度值,落在D区则赋予右下角象素的灰度值。
最邻近元法计算量较小,但可能会造成插值生成的图像灰度上的不连续,在灰度变化的地方可能出现明显的锯齿状。
2、双线性内插法
双线性内插法是利用待求象素四个邻象素的灰度在两个方向上作线性内插,如图1.2所示:

图1.2 双线性内插
对于 (i, j+v),f(i, j) 到 f(i, j+1) 的灰度变化为线性关系,则有:
f(i, j+v) = [f(i, j+1) - f(i, j)] * v + f(i, j)
同理对于 (i+1, j+v) 则有:
f(i+1, j+v) = [f(i+1, j+1) - f(i+1, j)] * v + f(i+1, j)
从f(i, j+v) 到 f(i+1, j+v) 的灰度变化也为线性关系,由此可推导出待求象素灰度的计算式如下:
f(i+u, j+v) = (1-u) * (1-v) * f(i, j) + (1-u) * v * f(i, j+1) + u * (1-v) * f(i+1, j) + u * v * f(i+1, j+1)
双线性内插法的计算比最邻近点法复杂,计算量较大,但没有灰度不连续的缺点,结果基本令人满意。它具有低通滤波性质,使高频分量受损,图像轮廓可能会有一点模糊
w

图1.3 最邻近插值放大图片

图1.4 双线型内插值放大图片
2.2 图像灰度化
识别物体,最关键的因素是梯度(现在很多的特征提取,SIFT,HOG等等本质都是梯度的统计信息),梯度意味着边缘,这是最本质的部分,而计算梯度,自然就用到灰度图像了。颜色本身,非常容易受到光照等因素的影响,同类的物体颜色有很多变化。所以颜色本身难以提供关键信息。
将彩色图像转化成为灰度图像的过程成为图像的灰度化处理。彩色图像中的每个像素的颜色有R、G、B三个分量决定,而每个分量有255中值可取,这样一个像素点可以有1600多万(255255255)的颜色的变化范围。而灰度图像是R、G、B三个分量相同的一种特殊的彩色图像,其一个像素点的变化范围为255种,所以在数字图像处理种一般先将各种格式的图像转变成灰度图像以使后续的图像的计算量变得少一些。灰度图像的描述与彩色图像一样仍然反映了整幅图像的整体和局部的色度和亮度等级的分布和特征。图像的灰度化处理可用两种方法来实现。
第一种方法使求出每个像素点的R、G、B三个分量的平均值,然后将这个平均值赋予给这个像素的三个分量。
第二种方法是根据YUV的颜色空间中,Y的分量的物理意义是点的亮度,由该值反映亮度等级,根据RGB和YUV颜色空间的变化关系可建立亮度Y与R、G、B三个颜色分量的对应:Y=0.3R+0.59G+0.11B,以这个亮度值表达图像的灰度值。
2.3 直方图均衡化
如果图像中的像素占据大量灰度并均匀分布,那么这些图像往往具有高对比度和可变灰度。直方图均衡化是一种仅由输入直方图信息自动实现这种效果的变换函数。其基本思想是扩大图像中的像素数,压缩图像中的几个像素的灰度级,从而扩大像素值的动态范围,提高对比度和灰度色调的变化,使图像更加清晰。
图像对比度增强方法可分为两大类:一种是直接对比增强,另一种是间接对比增强。直方图拉伸和直方图均衡是两种最常用的间接对比度增强方法。通过对比度拉伸来拉伸直方图,以扩大前景和背景灰度之间的差异,从而达到增强对比度的目的。这种方法可以通过线性或非线性的方法来实现。利用累加函数对灰度值进行“调整”,实现直方图均衡化。对比增强。
直方图均衡化是在图像处理领域中利用图像直方图进行图像对比度的一种方法。这种方法通常用于增加许多图像的局部对比度,特别是当有用数据的对比度非常接近时。通过这种方法,亮度可以更好地分布在直方图上。这可以用来增强局部对比度而不影响整体对比度,并且直方图均衡可以通过有效地扩展通常亮度来实现。
直方图均衡化的“中心思想”是将原始图像的灰度直方图变换成灰度范围内从相对集中的灰度范围内的均匀分布。直方图均衡化是对图像进行非线性拉伸并重新分配图像的像素值,使得某一灰度级的像素数大致相同。直方图均衡化是给定图像的直方图。分布改变成“均匀”分布直方图分布。
直方图均衡化的基本思想是把原始图的直方图变换为均匀分布的形式,这样就增加了像
灰度值的动态范围可以增强图像的整体对比度。将原始图像的灰度(x,y)设置为f,当改变图像为G时,图像增强方法可以被描述为将灰度f映射到(x,y)到g。灰度直方图均衡过程中的映射函数到图像可以定义为g=eq(f),映射。G函数Eq(f)必须满足两个条件(L是图像的灰度序列):
(1)EQ(f)在0≤f≤L-1范围内是一个单值单增函数。这是为了保证增强处理没有打乱原始图像的灰度排列次序,原图各灰度级在变换后仍保持从黑到白(或从白到黑)的排列。
(2)对于0≤f≤L-1有0≤g≤L-1,这个条件保证了变换前后灰度值动态范围的一致性。
累积分布函数(cumulative distribution function,CDF)即可以满足上述两个条件,并且通过该函数可以完成将原图像f的分布转换成g的均匀分布。此时的直方图均衡化映射函数为:
= EQ( ) = (ni/n) = pf( ) ,
(k=0,1,2,……,L-1)
根据该方程,上述求和区间为K.的0,可以直接从源图像中每个像素的灰度值获得每个像素的灰度值。在实际的处理变换中,对原始图像的灰度情况进行统计分析,计算原始直方图分布,然后根据计算得到的累积直方图分布得到灰度映射关系。在重复上述步骤之后,将源图像的所有灰度映射到目标图像的灰度级,可以根据映射关系通过源图像像素像素的灰度变换完成源图像的直方图均衡化。
直接白地理解直方图均衡化:上述公式不能简单地从数学的角度解释直方图均衡化的计算方法,也不能解释数学公式背后的含义。简而言之,直方图均衡化是寻找对应函数s= f(r),r作为输入信号图像,s作为输出信号的图像。我们的目标是找到F的表达式,想象一个直方图位于小灰度值区域的未处理图像。俗话说,柱状图很窄。我们想把它变成一个非常宽的直方图,所以这需要一个拉伸函数。显然,该函数必须保证图像中像素的大小不能顺序改变,否则将改变原始图像中表达的内容。我们认为此时的累积分布函数。为了便于理解,相反,我们讨论如何找到累积分布函数。首先,一般来说,灰度图像的像素值在0~255之间。然后,如果要在0~255之间尽可能地分布像素,则在灰度分布时,原始图像的灰度值的密度是不同的。例如,图像R的原始像素分布在原始像素的像素值的100-150和140~150之间。此时,如果将原始图像映射到0~255的线性函数(45度直线的起点)是不可行的,则线性函数不能表示原始像素值的密度分布。情况。然而,累积分布函数与原始像素在一定间隔内的分布密切相关。如果原始像素被累加,则发现140~150像素占据累积函数的大部分变化。累积函数仅是表示区间内原始像素的分布规律。它以灰度值表示100-150区间内原始图像中像素的分布。此时,我们使用这个分布乘以255,并且我们将分布扩展到0~255区间。如果将该产品作为像素值来形成新的图像S,则发现原始的窄直方图将被拉伸到0~255,并且在原始图像中像素值分布的分布被良好地保存。上述过程是从输入图像R到输出图像S的过程,这是我们正在寻找的映射函数F。
该方法对背景和前景过于明亮或太暗的图像有很大的帮助,特别是在X射线图像中显示出更好的骨结构显示,并且在曝光过度或曝光不足的情况下能更好地显示细节。这种方法的主要优点之一是它是一种相当直观的技术和可逆操作,并且如果已知平衡函数,则可以恢复原始直方图,并且计算量小。
这种方法的一个缺点是它不选择处理过的数据。它可以增大背景噪声的对比度,减少有用信号的对比度,减少变换后的灰度值,消除一些细节;直方图等图像具有峰值,处理后的对比度自然地过度增强。
第三章 人脸识别
3.1 HOG
梯度直方图(HOG)是计算机视觉和图像处理中用于目标检测的特征描述符。通过计算统计图像局部区域的梯度方向直方图,特征描述符HOG特征。
在一对图像中,可以通过梯度或边缘的方向密度的分布来很好地描述局部目标的图像和形状。本质是梯度的统计信息,梯度主要存在于边缘。
HOG特征和SVM分类器在图像识别中有着广泛的应用,特别是在行人检测中。
1、颜色和伽马归一化
为了减少光照因素的影响,首先需要对整个图像进行归一化处理。在图像的纹理强度中,局部表面曝光的贡献较大,因此这种压缩处理可以有效地减少图像的阴影和光照变化。
2。图像梯度的计算
计算图像的水平坐标和垂直坐标的梯度,并相应地计算每个像素位置的梯度方向值。引导操作不仅可以捕捉轮廓、人体阴影和一些纹理信息,而且可以进一步削弱照明的影响。
最常用的方法是简单地将一维离散差分模板在一个方向上或同时在水平和垂直两个方向上进行图像处理,更具体地说,该方法需要使用滤波器核来滤除图像或C的颜色。收集暴力数据。
三。施工方向直方图
单元单元中的每个像素对基于方向的直方图信道进行投票。投票是一个加权投票,也就是说,每个票都有一个权重值。权重是根据像素点的梯度来计算的。权重值本身或其功能可以用来表示权重。结果表明,利用振幅表示权重值可以获得最佳效果。当然,它也可以选择振幅的函数,如振幅的平方根、振幅的平方、振幅的截断等。单元单元可以是长方形的或星形的。直方图通道均匀分布在01800(NO或0(3600))。在研究的范围内,发现有一个方向)。使用无向梯度和9个直方图通道,可以在行人检测实验中获得最佳结果。
4。将细胞单元结合成大间隔
由于背景光的变化和前景背景的对比,梯度强度变化很大。这需要梯度强度的归一化。归一化可以进一步压缩光、阴影和边缘。
该方法是将每个单元单元组合成一个大的、空间上连接的间隔。以这种方式,HOG描述符成为由每个间隔中的所有单元单元的直方图组成的向量。这些间隔彼此重叠,这意味着每个单元单元的输出多次作用于端部。描述符。
间隔有两个主要的几何形状-矩形间隔(R -猪和环间隔(C)-猪-猪间隔通常是一个正方形格子)。它可以具有三个参数来表征每个间隔中的单元单元的数目、每个单元单元中的像素数目、以及每个单元的直方图通道的数目。眼睛。
5。收集猪的特点
提取的HOG特征被输入到SVM分类器,以找到最优超平面作为决策函数。
当数据量大或数据维数大但样本量小时,在计算过程中可能存在大量的资源消耗或过度学习(过拟合)[39 ] -[ 40 ]。过滤特征筛选方法与样本维数不直接相关,当特征维数较高时,可以有效地过滤特征。过滤方法是基于现有的数据集,并从数据角度选择特征。在这个过程中,特征选择与训练模型没有直接关系。过滤器主要从距离、信息、依赖性和一致性四个角度对[41 ]进行评价。
从信息的角度进行测量是当前研究的一个重要方向。从信息熵的角度出发,提出了提取特征的算法。信息熵理论提出了数据分布,并利用不确定性来评估42个特征间的关系(用最大线性关系)。
信息的测量是多种多样的,例如SNR(方查碧),这是一种广泛使用的测量方法。
信号噪声大,响应数据中的有用信息大,信噪比低。在实际应用中,变量数可能变化较小,不能提供有用的信息,但其存在可能影响算法的运算时间或精度,因此有必要滤除数据中的小变化特性。当数据发生很大变化时,它被认为是有用的信息,而基本不变。它被认为是噪声信号。基于方差阈值的特征选择方法是一种相对简单的特征,它消除了数据方差的方差,并且类似于低通滤波器。然而,由于数据单元的不同,为了避免引入阈值设置,应该进行数据标准化。
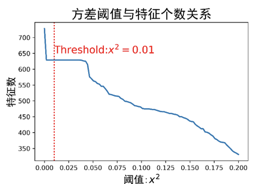
图2-2方差阈值与特征个数关系图
Fig.2-2 The relation graph of variance threshold and characteristic number
方差阈值与特征个数关系图显示,随着阈值的提高,特征个数逐渐降低。因为对数据做归一化处理,使得数据落在(0,1),在数据波动不到1%既认为数据的波动主要来自噪声数据,数据特征是不相关特征。通过方差阈值特征筛选法,将特征数从728维降到479维。
3.2 SVM
支持向量机(SVM)是指支持向量机,这是一种常见的判别方法。在机器学习领域,它是一种有监督的学习模式,它通常是用于模式识别,分类和回归分析。
支持向量机方法是地图样本空间到特征空间(希尔伯特空间)的非线性映射,使得非线性可分的问题在原始样本空间转化为特征空间中的线性可分问题。将样本映射到高维空间。在一般情况下,这会增加计算的复杂度,甚至导致“维数灾难”,所以很少有人问。但作为分类和回归,它是可能的样本集不能在低维样本空间的线性处理,但它可以在高维特征空间,通过。线性超平面是一个线性划分(或回归)。一般的升维会带来复杂的计算。支持向量机方法巧妙地解决了这个问题:利用核函数的展开定理,没有必要知道的非线性映射的显式表达式;因为线性学习机在高兽医空间建立,所以线性学习机是建立。与线性模型相比,它不仅不仅增加了计算的复杂度,又避免了“维数灾难”在一定程度上。这一切都是由于核函数的扩展和计算理论。这是训练分类器建立分类模型的第一步,和训练次数需要在训练阶段分析。根据机组的特点,相应的数据集的一个准确的描述或模型为每个类生成。我们可以使用LIBSVM软件包来训练分类器模型。首先,我们需要写的人脸图像的特征向量为样本文件根据libsvm格式。数据格式是
[label][indexl]:[value1][index2]:[value2]…
其中[label]标识样本类别,通常为整数。[index]为有序的索引,以1开始的整数,可以是不连续的整数,代表特征向量序列。
选择不同的核函数,可以生成不同的SVM,常用的核函数有以下4种:
⑴线性核函数K(x,y)=x·y;
⑵多项式核函数K(x,y)=[(x·y)+1]^d;
⑶径向基函数K(x,y)=exp(-|x-y|2/d2)
⑷二层神经网络核函数K(x,y)=tanh(a(x·y)+b)
4 人脸识别
历史数据包括电梯运行数据、故障原因、维修记录等。由于收集器故障和通信环境的运行环境,原始数据中不存在脏数据。“脏数据”指的是不完整的数据和噪声,影响数据集训练模型的正确性,这使得决策系统产生错误的结果并影响信息服务的质量。良好的数据挖掘结果的前提是数据必须是正确的、一致的、完整的和可靠的。数据预处理在很大程度上决定了用于分析的数据质量,影响了决策的科学性。
在预处理中,实际特征数据与业务背景应有效结合。该方案以电梯数据和电梯营业环境为背景。通过对数据进行预处理,使原始数据更适合于电梯设备的健康评估。
3-1 数据预处理系统
Fig.3-1 Data preprocessing system
4.1 LBP原理
人脸识别是指将一个需要识别的人脸和人脸库中的某个人脸对应起来(类似于指纹识别),目的是完成识别功能,该术语需要和人脸检测进行区分,人脸检测是在一张图片中把人脸定位出来,完成的是搜寻的功能。从OpenCV2.4开始,加入了新的类FaceRecognizer,该类用于人脸识别,使用它可以方便地进行相关识别实验。
原始的LBP算子对于每幅图上每个像素点用其周围3× 3邻域像素值对此像素点进行纹理描述。LBP 算子公式为
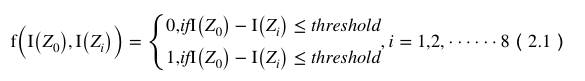
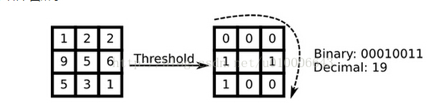
原始的LBP算子定义为在33的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于或等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,33邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理特征。如下图所示:
原始的LBP提出后,研究人员不断对其提出了各种改进和优化。
4.1.1 圆形LBP算子
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,Ojala等对LBP算子进行了改进,将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点,从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子,OpenCV中正是使用圆形LBP算子,下图示意了圆形LBP算子:

4.1.2 旋转不变模式
从LBP的定义可以看出,LBP算子是灰度不变的,但却不是旋转不变的,图像的旋转就会得到不同的LBP值。Maenpaa等人又将LBP算子进行了扩展,提出了具有旋转不变性的LBP算子,即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值。下图给出了求取旋转不变LBP的过程示意图,图中算子下方的数字表示该算子对应的LBP值,图中所示的8种LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的LBP值为15。也就是说,图中的8种LBP模式对应的旋转不变的LBP码值都是00001111。

4.1.3 等价模式
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P2种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个局部二进制模式所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该局部二进制模式所对应的二进制就成为一个等价模式类。如00000000(0次跳变),00000111(含一次从0到1的跳变和一次1到0的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。
通过这样的改进,二进制模式的种类大大减少,模式数量由原来的2P种减少为P(P-1)+2+1种,其中P表示邻域集内的采样点数,等价模式类包含P(P-1)+2种模式,混合模式类只有1种模式。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为59种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
4.2 LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值),如图所示:
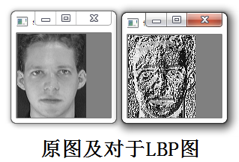
如果将以上得到的LBP图直接用于人脸识别,其实和不提取LBP特征没什么区别,在实际的LBP应用中一般采用LBP特征谱的统计直方图作为特征向量进行分类识别,并且可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述,整个图片就由若干个统计直方图组成,这样做的好处是在一定范围内减小图像没完全对准而产生的误差,分区的另外一个意义在于我们可以根据不同的子区域给予不同的权重,比如说我们认为中心部分分区的权重大于边缘部分分区的权重,意思就是说中心部分在进行图片匹配识别时的意义更为重大。 例如:一幅100100像素大小的图片,划分为1010=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为1010像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有1010个子区域,也就有了1010个统计直方图,利用这1010个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了。
4.3 LBP于SVM相结合
人脸识别的最后一个步骤,就是分类人脸的特征信息,对人脸进行判别。LBP 方法是一个很有效的特征提取方法,很适合人脸表征。但在分类性能上存在一定不足,与后续的学习算法无关,我们尝试将其与分类器结合来提高图像识别率。因此本章要研究的问题就是LBP特征提取与SVM分类器的结合,通过实验来研究LBP特征提取与SVM分类器的关系,并比较SVM和最近邻分类器的性能。
4.3.1 分类器
分类器的设计是模式识别领域的重要内容,对人脸识别来说,分类器的设计是否合适是一个值得研究的重要问题,其分类能力好坏直接决定了系统的性能。在人脸识别过程中,在人脸特征提取之后,可以利用分类器对提取的特征向量进行分类处理。
支持向量机是2世纪90年代提出的基于统计学习理论的学习算法,是近年来非常流行的分类器。其基本原理是以结构风险最小化为原则,通过某种非线性映射把原始数据映射到高维特征空间,在高维空间中构造具有低VC维的最优分类超平面,使其具有最优的推广能力。在人脸识别的分类系统中,一开始就收集到完备的训练样本是很困难的,我们要求分类器能够在使用过程中,从实际测试样本中选择出重要的样本进行主动、增量和长期的学习,不断提高分类器的性能,支持向量机凭借统计学习理论坚实的基础,成为解决小样本、非线性及高维模式识别的有力工具。Guodong 在ORL人脸库上进行实验比较了支持向量机、特征脸和最近邻分类器的分类效果,实验结果表明支持向量机的分类性能要优于特征脸和最近邻分类器。因此我们选择支持向量机作为实验的分类器,观察LBP 特征提取方法和SVM 结合的效果。
4.3.2 非线性支持向量机
线性支持向量机对于许多具有非线性结构的现实问题来说是不适合的。对于非线性问题,如何把线性支持向量机推广到解决非线性模式分类问题?利用一个简单的方法可以解决这个问题,如图4.2所示,利用非线性函数ϕ (x)把数据从低维输入空间Rn映射到一个高维的特征空间H。使得数据在高维空间中具有更好的可分性。在高维特征空间H中求解线性支持向量机的最优分类面,再投影回低维输入空间就是一个非线性的曲面。
4.4 数据驱动
在计算机系统中, 经验通常是以数据的形式存在. 我们将提供给计算机每个类别的许多实例(examples), 它们组成了训练集(training set), 利用学习算法(learning algorithms)从训练集中产生分类器(classifier)}或模型(model). 在面对新情况时(例如看到一张以前未出现的图像), 模型会提供相应的判断. 这个过程, 即本文需要讨论的数据驱动过程.
为了通过摄像头或者其他的摄取人脸设备采集到图像信息,相应的开发板需要安装相应的摄像头驱动程序,以及对摄像头访问的应用程序,需要编写对摄像头的访问程序。通过摄像头所获得的图像信息的数据格式为YUV编码格式,而opencv所支持的图像信息颜色通道顺序为BGR格式,在qt中对图像操作的类是Qimages,该类支持的Qimage支持的颜色通道顺序是RGB,在opencv 中实现颜色通道顺序的转换可使用函数cvCvtColor(const CvArrsrc, CvArr dst,int code)来实现。
第五章 结论
人脸识别在公安部门、安全验证系统、信用卡验证、档案管理、人机交互系统等领域有着广阔的应用前景,已经成为当前模式识别和人工智能领域的一个研究热点。对于机器来说,要快速准确的通过人脸识别出人的身份是很困难的事情,识别率容易受到姿态、光照和表情的影响。经过几十年的发展,各种人脸识别技术相对成熟,各种识别技术各有优缺,本文对纹理描述算子LBP 进行了研究,主要工作有:
1.归纳总结了常用的人脸识别方法,分析人脸识别的主要步骤,介绍了国际上常用的人脸数据库。
2.针对LBP 基本算子和LBP 的演化算子进行深入研究,总结出LBP 的优点。通过实验对传统的LBP 人脸识别方法进行验证,为了提升识别率,对图像进行三种预处理。结果表明经过高斯平滑和Sobel 边缘提取的LBP 算子对于不同光照条件下人脸图像识别率提高幅度较大。分块大小对LBP 算子性能也产生一定的影响,分块越多,识别率相对提高,特征向量维数也越高,花费的时间和存储空间也随之增大。
3.比较了各分类器的优缺,针对SVM 分类器原理进行研究,认为SVM 比较适合解决人脸识别这类小样本、非线性、高维并稀疏的模式识别问题,通过实验证明将SVM 与LBP 结合可以提高LBP 的识别率,SVM 与最近邻分类器相比有更好的分类性能。

