
- 1ICode国际青少年编程竞赛- Python-1级训练场-基础训练2_国际青少年编程基础训练二答案
- 2谷歌(Google)技术面试——在线评估问题(四)
- 3Android Studio 多渠道打包(二) ---meta-data_android studio meta-data
- 4java socket 读取为空_JAVA服务端 Socket接收iOS发送的报文为空字符串?
- 52024 前端面试题_2024前端面试题
- 6漏洞扫描工具Acunetix安装使用
- 7揭秘python程序性能:统计程序运行时长的重要性与实操
- 8电脑重装系统虚拟机安装xp的教程_vm16安装xp
- 9蔬菜水果店做配送分销小程序的作用是什么
- 10js的条件控制-if判断-switch语句-以及三元表达式(详解)_js中if的三个条件如何写
KMP算法之基础思想篇_kmp 模式匹配算法的基本思想。
赞
踩
KMP算法是快速求字符串P 是不是字符串S的子串的一个算法,具体案例呢,可以看力扣的28题.实现 strStr(),题意也很简单,就是找出P在S中出现的第一个位置。实际上就是找子串。
这种最简单的方法就是暴力,直接两层for循环,O(n*m)的复杂度,比较耗时,相比之下,KMP算法要快很多,要理解KMP算法,就一定要知道,前缀和后缀的概念,举个例子,对于字符串abc,前缀有a和ab,后缀有bc和c。清楚了这个概念之后,一起看下KMP算法的实现。
首先,先理解KMP算法的思想,然后再去将其转换成代码逻辑。先看看KMP算法的思想。为了看的更清楚,这里画图说明,且用一个比较长的串,从而可以更好的看清楚规律。

需要判断串P是否为S的子串,为了方便后续写作,也为了让看过其他文章的小伙伴比较好的阅读此文章,我们将P称为模式串。下面绿色的就都是P,橙色都是S,为了方便讲解,就把图上的名字S和P去掉了。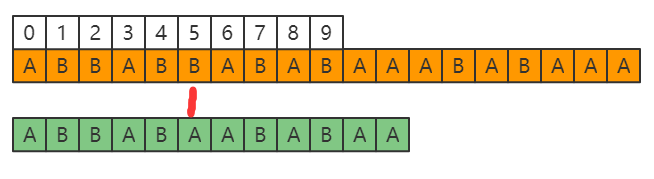
可以看到当下标为5时,两个串发生了不匹配的情况。此时先求一下P串前5个字符的前缀和后缀。注意这里是前5个,因为第6个已经不相等了,所以肯定是要对前面相等的5个做处理。
前缀有:A、AB、ABB、ABBA。
后缀有:B、AB、BAB、BBAB。
可以看到,前缀和后缀有相同的部分AB,且AB为最长的相同部分,我们这里就是要找最长的相同部分,那么,P[0]是不是就可以移动到P[3]的位置?注意,这里的前提是,P和S的前面5个字符是相等的,而P[0]~P[1] 和 P[3]~P[4]又是相等的,所以一定是可以移动的,移动之后,直接从下标为5的地方接着比较,前面的因为有公共前后缀作保障,所以肯定是相等的。

针对S来说,肯定是关注下标为5的地方,因为是从这个地方开始在进行比较的,而针对于P来说,则是向右移动了3位,即P[0]到了P[3]的位置,到这里,肯定有天赋异禀的小伙伴可以悟出些规律了,没有想到也没有关系,毕竟这才是第一步,我们接着往下看。针对上面这张图,可以看到,第一次移动之后,到了下标为9的地方,又出现了不一致的情况。
这个时候按照刚刚的逻辑,先找P的前6个字符的前缀和后缀公共部分(这里其实就可以总结出第一步的要干的事情,即当P[j]和S[i]不相等时,要先找P[0]-P[j-1]的前后缀最大的公共部分)。此时最大的公共部分很遗憾只有一个A,则P[0]要移动到P[5],即P[0]要从上图和S[3]对应的位置,移动到下图和S[8]对应的位置。这里其实有个规律,就是当前主串S要比较的位,对应的就是P[前后缀最长公共部分]位,也就是说S[9](当前要比较的位)对应P[1] (上面求出来的P[0]-P[6]的前后缀最长公共部分A的长度),再结合上面的图,S[5]对应P[2],是不是更可以推出这个结论,如果觉得例子还是太少的话,下面还会在继续举例说明。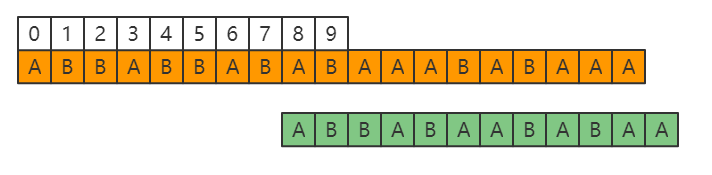 这里做个特别说明,因为这边举例是按照下标为0开始举例的,如果是下标为1的话,那么规律自然就变成了对应P[前后缀最长公共部分+1]位。这个加不加一和数组下标是不是从0开始有关系,不代表规律本身有问题。
这里做个特别说明,因为这边举例是按照下标为0开始举例的,如果是下标为1的话,那么规律自然就变成了对应P[前后缀最长公共部分+1]位。这个加不加一和数组下标是不是从0开始有关系,不代表规律本身有问题。
此时从S[8]开始的字符串长度已经小于P的长度了,只能遗憾的宣告没有匹配成功,我认为到这里已经可以足够说明思想了,大家觉得意犹未尽可以自行的加字符,在接着推论。
OK,其实KMP算法关注的一直都是模式串P,可以看到我们根本没有对S做什么操作,只是拿来判断用的,而对于P,每当S[i]和P[j]不相等时,就要不断的去关注P[0]~P[j-1]的前后缀的最长公共部分,然后向右移动这个长度即可。
如果是这样,那么每次不相等的时候都要去找前后缀最长的公共部分,那代码写起来也挺麻烦,所以可以用到预处理的思想,假设在P的每一位上都有可能发生不相等的情况,先把值全部计算出来,如下图。下图中的P0,P1含义为P[0],P[1],加括号就不好看了,所以这么写,其他的P3,P4,P5同理。

如果A和S[i]就不相同了,那么直接P[0](A)和主串的下一位S[i+1]比,如果到B不相同的,即P[1]和S[1]不相同,它前面的A都不存在前后缀,肯定是要从头比的,即P[0]对S[1]了,也就是图中写的,P[0]与主串的当前位比较。如果是P[2]和s[2]不一致,对于AB,没有相同的前后缀,还是一样要从头来,对于P[3]和S[3]不一致,ABA有相同的前后缀为A,则直接P[1]在对S[3]就好了,依次类推,可以推出上图的数据。而我们仔细再看一下上图又可以得出,只有当P[0]和S[0]不相同的时候,才需要和主串下一位比较,不然都是和主串当前位进行比较,所以对于A,我把这个0改成-1,表示这个是需要跟下一位比较的,其他的原封不对,然后把数字保留下来,就成了下图的样子。
而这其实就是next数组的由来了,next数组的含义也很清楚了,即当P[j]和S[i]不相等的时候,应该从哪个P[x](x必定小于j)和S[i]接着比较,也表示为P[0]-P[j-1]中最长的前后缀公共部分的长度。而数据结构的书上讲的下标回退,以及非常多的人喜欢讲的回溯,实际上就是指P[j]到P[x]的这么一个过程,本来已经比到P[j]了,但是你要我回到P[x]重新比较,实际上就是回溯了一段。看到这里,对于这些词语一脸懵逼的同学,应该也可以恍然大悟了。暴力做法是P[j]回溯到P[0],KMP是P[j]回溯到P[x],所以KMP快在哪里一目了然。
到这里可能还有同学会有疑问,我看源码对于next的构建,不是每次都去找前后缀最长公共部分的写法呀!关于next数组的构建,下个文章再详解是怎么通过j=next[j],这么简单的一句代码,就可以构建出next数组的。符个链接构建next数组

