
- 1ChatGPT深度科研应用、数据分析及机器学习、AI绘图与高效论文撰写_人工智能(包括chatgpt)文案编写、自动化编程、数据分析与ai绘画技巧应用实践
- 2[CentOS]离线安装gcc/gcc-c++-_gcc-c++-4.8.5-44 下载
- 3陶哲轩:AI让业余数学家也能做出贡献
- 4NameError: name xxxxxx is not defined
- 5解决nginx到后端服务器Connection: close问题_nginx connection close
- 6PaddleOCR 实现车牌识别----利用PaddleOCR训练车牌识别数据_未完待续_paddleocr车牌识别训练
- 7python编写函数add求和_Python进阶之函数式编程
- 8Java面向对象 - 类与对象_据提示,在右侧编辑器begin-end处补充代码: 声明一个dog类,给dog类添加三个string
- 9达梦数据库安装和实例创建_达梦8如何创建数据库
- 10SQL的主键和外键约束_不能更改列学号用于表1选课的外键约束学号‘’
Python六大基本数据类型_python变量数据类型
赞
踩
摘要
同其它高级语言类似,Python语言提供六大基本数据类型:
- Number(数字类型)
- String(字符串类型)
- Tuple(元组类型)
- List(列表类型)
- Set(集合类型)
- Dictionary(字典类型)
(前三者为不可变数据,后三者为可变数据)
在Python解释器内部,所有的数据类型都采用面向对象方式实现(万物皆对象),所以说,这六大基本类型,其实不过就是6个内置的类。每个类有许许多多的方法,当学习并记忆常用的…(多说一句:变量无类型,对象有类型)
1. 数字类型
Python3中的数字类型包括整数类型(int)、浮点数类型(float)、复数类型(complex)和布尔类型四种。(bool类型因为在python3中加入了True和False两个关键字出现,其实它应该属于数字类型,对应着数字1和0)
整数类型:
整数类型和数学中整数的概念一样,没什么好说的,注意下在python中的不同进制表示即可:
二进制引导符号:0b
八进制引导符号:0o
十六进制引导符:0x
>>>10 #十进制
>10
>>>0b10 #二进制
>2
>>>0o10 #八进制
>8
>>>0x10 #十六进制
>16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
浮点数类型:
浮点数类型对应着数学中的实数,表示带有小数的数值。(为了区分必须带有小数部分)
浮点数有两种表示方法:十进制表示法和科学计数法表示。
科学记数法:用e或E作为幂的符号,以10为基数。
例: 5.6e-3=0.0056 5.6e+3=5600.0
5.6e-3=5.6E-3 5.6e+3=5.6E+3=5.6e3(加号可省略)
浮点数运算的精度问题一般可用decimal库来解决。
复数类型:
复数类型对应着数学中的复数。Python语言中复数的虚数部分用“J”或“j”表示:
如 4j , 11.5+J , 1.23e-4+43j
复数类型中的实数部分和虚数部分的数值都是浮点数类型。对于一个复数a,可以用a.real和a.imag分别获得它的实数和虚数部分。如;
>>>a=3+5j
>>>a.real
>3.0
>>>a.imag
>5.0
- 1
- 2
- 3
- 4
- 5
布尔类型:
布尔类型非常常见,Python中就俩值:True和False。“bool“”一出现给人的感觉就是非常简单,其实不然,与其了解布尔类型,不如了解一下George Boole这个伟大的人物,他所创立的…(Baidu or Google)
布尔类型可以和整数直接相加的:
>>>1+True
>2
>>>6-False
>6
- 1
- 2
- 3
- 4
内置数值运算操作符(共9个)
| 操作符 | 描述 |
|---|---|
| x+y | 和 |
| x-y | 差 |
| x * y | 积 |
| x/y | 商 |
| x//y | 整数商 |
| x%y | 余数,也称模运算 |
| -x | x的负值 |
| +x | x本身 |
| x**y | x的y次幂 |
内置的数值运算函数
内置的运算函数共6个([隶属于Python—68个内置函数])(https://mp.csdn.net/mdeditor/96494142))
| 函数 | 描述 |
|---|---|
| abs(x) | x的绝对值 |
| divmod(x,y) | (整数商,余数)输出元组形式 |
| pow(x,y,z) | (x**y)%z (参数z可省略) |
| round(x,ndigits) | 四舍五入,保留ndigits位小数(该参数可省略,省略则返回整数值) |
| max(x1,x2,x3…,xn) | 返回一个最大值 |
| min(x1,x2,x3…,xn) | 返回一个最小值 |
内置的数字类型转换函数
内置的数字转换函数共3个([隶属于Python—68个内置函数])
| 函数 | 描述 |
|---|---|
| int(x) | 将x转换为整数,x可以是浮点数或字符串 |
| float(x) | 将x转换为浮点数,x可以是整数或字符串 |
| complex(re,im) | 生成一个复数,实部为re,虚部为im,re可以是整数、浮点数或字符串,im可以是整数或浮点数但不能是字符串 |
2. 字符串类型
在python中,字符串就用’str’表示。其实字符串属于序列类型之一,另外俩是元组和列表。(序列类型是一维元素向量,元素之间存在先后关系。)
Python提供了5个字符串的基本操作符:
| 操作符 | 描述 |
|---|---|
| x+y | 连接俩字符串 |
| x* n或 n* | x复制n次字符串 |
| x in s (x not in s) | 判断x是否是s 的子字符串,返回布尔值 |
| str[i] | 索引,返回第i个字符串 |
| str[N:M:L] | 切片 (L为步长,可省略) |
内置字符串处理函数共6个([隶属于Python—68个内置函数])
| 函数 | 描述 |
|---|---|
| len(x) | 返回字符串长度 |
| str(x) | 返回任意类型所对应的字符串形式 |
| chr(x) | 返回Unicode所对应的单字符 |
| ord(x) | 返回单字符对应的Unicode编码 |
| hex(x) | 返回整数x对应十六进制数的小写形式字符串 |
| oct(x) | 返回整数x对应的八进制的小写形式字符串 |
字符串类常用处理方法(共43个,列出常用16个)
| 方法 | 描述 |
|---|---|
| str.lower() | 返回字符串str的副本(指原字符串不改变),全部字符小写 |
| str.upper() | 返回字符串str的副本,全部字符大写 |
| str.islower() | 当字符串都是小写时候,返回True,否则返回False |
| str.isprintable() | 当字符串都是可打印的,返回True,否则返回False |
| str.isnumeric() | 当字符串都是数字时,返回True,否则返回False |
| str.isspace() | 当str所有字符都是空格,返回True,否则返回False |
| str.endswith(a,start,end) | 在[start:end]区间(可省略)以a结尾返回True,否则False |
| str.startswith(a,start,end) | 在[start:end]区间(可省略)以开头返回True,否则False |
| str.split(sep=None,maxsplit=-1) | 返回一个列表,参数1为分隔符,参数2表示分割前maxsplit个字符 |
| str.count(sub,start,end) | 返回str中sub在区间中出现的次数,[start:end]区间可省略 |
| str.replace(old,new,count) | 返回str副本,old-new 替换前count次,count参数可省略 |
| str.center(width,fillchar) | 字符串居中函数,第二个参数为宽度不足填补符号,可省略 |
| str.strip([chars]) | 返回str副本,在其左右两侧去掉chars中列出的字符 |
| str.zfill(width) | 返回str副本,长度为width,不足载气左侧添加0 |
| str.format() | 返回字符串的一种排版格式 |
| str.join(iterable) | 返回一个新的字符串,由组合数据类型iterable变量的每个元素组成,元素箭用str分割 |
下面选出个人觉得不易理解的方法运行示例:
split:分割:分割完返回的是一个列表,提供分割符号,默认以空格分割:
join拼接:相当于split的逆过程一样,不过join不仅仅可以拼接列表类型,只要是符合要求的任意组合类型都可拼接。
>>> str="abd?/dd22/*& 12/ff/00..00"
>>>lis=str.split('/') #以'/'为分割符
>>>lis
>['abd?', 'dd22', '*& 12', 'ff', '00..00'] #分割结果
>>>'$'.join(lis) #组合(组合符号可省略)
>'abd?$dd22$*& 12$ff$00..00'
>>>k=('1','2','3','py','thon00')
>>> '%'.join(k)
>'1%2%3%py%thon00'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
format()方法:
<模板字符串>.format(<逗号分割的参数>)
>>>"圆周率{1}{2}是{0}".format("无理数",3.1415926,"......")
>'圆周率3.1415926......是无理数'
- 1
- 2
上述代码只是一个简单的示例,并未对‘{}’里进行格式控制,“{}”里的格式是用来限定format括号里字符串的输出格式的。(上述模板槽里只有参数序号,无控制信息)
格式控制顺序信息:
| : | <填充> | <对齐> | <宽> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 ,符号前面是参数序号 | 用于填充的单个字符 | < 左对齐 > 右对齐 ^ 居中 | 槽的设定输出宽度 | 数字的千位分隔符,适用于整数和浮点数 | 小数的精度或字符串的输出长度 | 整数类型:b,c,d,o,x,X 浮点数类型:e,E,f,% |
>>> "{:-^20}".format("123456python")
>'----123456python----'
>>>"{0:H^20.2f}".format(12345.6789900)
>'HHHHHH12345.68HHHHHH'
- 1
- 2
- 3
- 4
3.元组类型
元组(tuple)是序列类型中比较特殊的类型,它一旦创建不可修改。
>>>1,2,3
>(1,2,3) #元组
- 1
- 2
序列类型(元组、集合、列表)通用操作符和函数(共10个)
| 操作符(函数) | 描述 |
|---|---|
| x (not)in s | 判断x是否为s中的元素,返回布尔值 |
| s+t | 连接 |
| s* n或n*s | s复制n次 |
| s[i] | 索引 |
| s[i:j:k] | 分片 |
| len(s) | 元素个数 |
| min(s) | 序列s中的最小元素 |
| max(s) | 序列s中的最大元素 |
| s.index(x,i,j) | 序列s从i到j位置中第一次出现元素x的位置(区间可省略) |
| s.count(x) | x在s中出现的次数 |
4.列表类型
列表(list)是包含0个或多个对象引用的有序序列。除了序列类型的通用操作外,列表还含有一些特有的函数和方法:
| 函数或方法 | 描述 |
|---|---|
| ls[i]=x | 把列表ls的第i项替换为x |
| ls[i:j]=lt | 用列表lt替换列表ls中i到j区间的数据(左闭右开) |
| ls[i:j:k]=lt | 用列表lt替换列表ls中i到j区间以k为步数的数据(左闭右开) |
| del ls[i:j] | 删除列表区间数据,相当于ls[i:j]=[] |
| ls.append(lt) | 将列表lt作为一个元素增加到列表ls中 |
| ls.extend(lt)l或ls+=lt | 将列表lt的元素增加到列表ls中 |
| ls*=n | 更新列表ls,其元素重复n次 |
| ls.append(x) | 在列表最后增加x元素 |
| ls.clear() | 删除所有元素 |
| ls.insert(i,x) | 在列表的第i位置增加元素x |
| ls.pop(i) | 将列表中的第i项元素取出并删除该元素 |
| ls.remove(x) | 将列表中出现的第一个元素x删除 |
| ls.reverse() | 将列表ls的元素反转原地保存 |
| ls.sort(reverse=False) | 排序(默认为False表示升序排列) |
>>>ls=[1,2,3]
>>>ls.reverse()
>>>ls
>[3,2,1]
>>>ls[::-1]
>>>ls
>[1,2,3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意追加的两个方法:append和extend,两者在追加单个元素时候,效果一样,在追加序列类型的时候却不同,如下:
>>>a=[1,2]
>>>b=[3,4]
>>>c=[5,6]
>>>a.append(b)
>>>a
>[1, 2, [3, 4]]
>>>a.extend(c)
>>>a
>[1,2,5,6]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
简单来说,append是整体追加的,extend是分开追加的,不仅仅是列表,任何可迭代类型都可以
>>>a=[1,2]
>>>a.append("python")
>>>a
>[1, 2, 'python']
>>>a.extend("hello") #任何可迭代类型都可以,效果如下
>>>a
>[1, 2, 'python', 'h', 'e', 'l', 'l', 'o']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.集合类型
集合类型中的元素无序,不可重复,元素类型只能是固定数据类型(即不可变类型,可哈希),创建一个集合用set()函数。
>>> set({1,2,1,'p','P'})
>{1, 2, 'P', 'p'}
- 1
- 2
集合中有十个操作符,两个集合中的各种运算如数学中一致。
集合类还有以下方法:
| 方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项x不在集合S中,将x增加到S中 |
| S.clear() | 移除S中的所有项(变成了空集合) |
| S.copy() | 返回了S的一个副本 |
| S.pop() | 随机返回S中的一个元素,如果S为空,产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素,不在的话不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素,不在的话报错KeyError |
| S.isdisjoint(T) | 如果集合S与T没有相同的元素,返回True |
| S.update(T) | 同字典的类似,用T更新集合S |
| del S | 彻底删除了S |
还是演示下其中的update()方法:
>>>a={1,2}
>>>b={3,4}
>>> a.update(b)
>>> a
{1, 2, 3, 4}
>>> b
{3, 4}
>>> b.update("python") #后面可以直接跟其它类型,更新时默认转换成set后融合
>>> b
{3, 4, 't', 'p', 'n', 'y', 'h', 'o'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
另:
补概念:可哈希与不可哈希 :简单来说,不可变的对象都是可哈希的,反之,可变的对象是不可哈希的,(集合的元素必须可哈希,字典中的key也必须可哈希)检验一个对象是否可哈希,可以用hash()函数(68个内置函数之一)报错则说明不可哈希,不报错会产生一个哈希值,这些哈希值和哈希前的内容无关,也和这些内容的组合无关。可以说,哈希是数据在另一个数据维度的体现。下图说明集合本身不可哈希:
>>> hash("python")
7542185639614675871 #字符串类型,无报错说明可哈希
>>> a={1,2,'jk'} #创建一个集合
>>> type(a)
<class 'set'>
>>> hash(a) #下面为报错信息
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'set' #unhashable:不可哈希
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们可以通过frozenset()函数(68个内置函数之一)来创造一个特殊的集合(不可变集合),该集合可哈希。如下图所示:
>>> a {1, 2, 'jk'} >>> s frozenset({1, 2, 'jk'}) >>> type(s) <class 'frozenset'> >>> s frozenset({1, 2, 'jk'}) >>> a {1, 2, 'jk'} >>> s=frozenset(a) >>> s frozenset({1, 2, 'jk'}) >>> type(s) <class 'frozenset'> >>> hash(s) 6043468397558573446

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.字典类型
映射类型,高纬,键值对,字典。(字典其实就是包含0个或多个键值对的集合)
键值对之间没有顺序且不能重复(主要指键不能重复,不同键的值可以一样)键和值可以是任意数据类型
>>>D={"北京":"B","郑州":"Z"}
>>>D["北京"] #通过键索引值(也可以直接修改值)
>'B'
- 1
- 2
- 3
字典类的函数和方法(共9个):
| 函数或方法 | 描述 |
|---|---|
| d.keys() | 返回所有的键信息 |
| d.values() | 返回所有的值信息 |
| d.items() | 返回所有的键值对 |
| d.get(key,default) | 键存在则返回值,否则返回默认值 |
| d.pop(key,default) | 键存在则返回值,同时删除键值对,否则返回默认值 |
| d.setdefault(key,default) | 键存在则返回对应值,否则添加该键,值为默认值(无default时默认为None) |
| d.popitem() | 随机从字典取出一个键值对,以二元组形式返回 |
| d.copy() | (浅)拷贝 |
| d.update() | 更新字典(俩字典的融合不可直接相加) |
| d.clear() | 删除所有键值对 |
| del d[key] | 删除字典中的某一个键值对 |
| key in d | 如果键在字典d中返回True,否则返回False |
以下解释下什么是“浅”copy:
简单来说:虽然copy的字典和原字典已经是两个不同的对象(id不同)但是并非毫无关系,看下面一个现象:
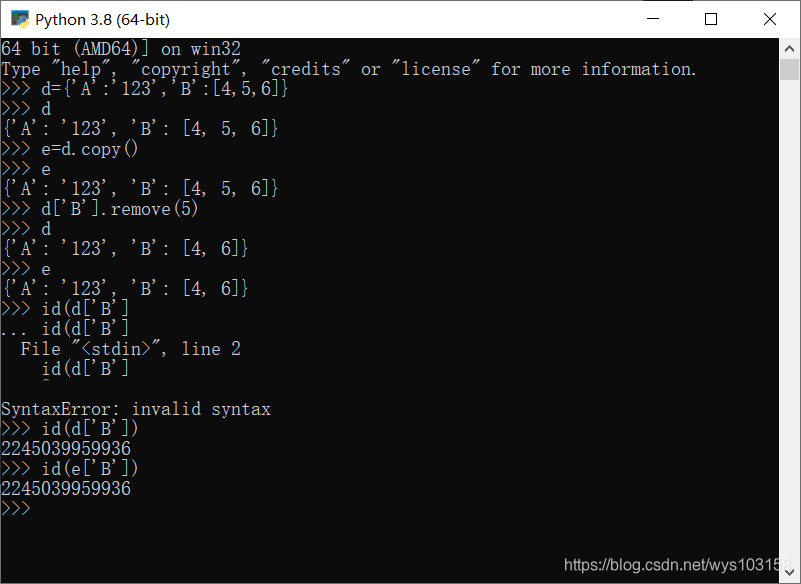
删除了d字典中的某一个元素的某一个值后,没有做操作的e字典也跟着改变了,这是因为字典中作为值的列表,是同样一个对象,这样的copy称之为浅拷贝。我们可以引入copy库,这样就能深拷贝,避免上述现象:

id号已经不同,在进行增删改等操作,两者毫无关联。
以下解释update()函数的使用:
>>> help(dict.update)
Help on method_descriptor:
update(...)
D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
If E is present and has a .keys() method, then does: for k in E: D[k] = E[k]
If E is present and lacks a .keys() method, then does: for k, v in E: D[k] = v
In either case, this is followed by: for k in F: D[k] = F[k]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
帮助信息中解释了update()函数的2种用法:
>>> d1={"A":65,"B":66}
>>> d2={"C":67,"D":68}
>>> d1.update(d2) #第一种用法
>>> d1
{'A': 65, 'B': 66, 'C': 67, 'D': 68} #d1被更新
>>> d2
{'C': 67, 'D': 68} #d2并无改变
- 1
- 2
- 3
- 4
- 5
- 6
- 7
>>> d2
{'C': 67, 'D': 68}
>>> d2.update([('E',69),('F','hello')])
>>> d2
{'C': 67, 'D': 68, 'E': 69, 'F': 'hello'}
- 1
- 2
- 3
- 4
- 5

