
- 1网络协议与攻击模拟_01winshark工具简介
- 2git rebase和merge区别_git rebase和merge有什么区别
- 3Android FileProvider的基本使用
- 4mysql分区表之三:MySQL分区建索引[转]
- 5超简单白话文机器学习 - 支持向量机SVM(含算法讲解,公式全解,手写代码实现,调包实现)_支持向量机(svm)
- 6leetcode - [30. 串联所有单词的子串]_leetcode 字串的链接
- 7基于招聘网站的大数据专业相关招聘信息建模与可视化分析_招聘可视化文章
- 8wpf自定义路由事件
- 9C#托管类型与非托管类型的字节数组序列化_c# 托管类型
- 10SparkSQL – Catalyst_sparksql 执行计划
Java 开源中文分词器Ansj 学习教程_ansj分词依赖
赞
踩
Java 开源中文分词器Ansj 学习教程
Java有11大开源的中文分词器,分别是:word分词器,Ansj分词器,Stanford分词器,FudanNLP分词器,Jieba分词器,Jcseg分词器,MMSeg4j分词器,IKAnalyzer分词器,Paoding分词器,smartcn分词器,HanLP分词器。
不同的分词器有不同的用法,定义的接口也不一样,至于效果哪个好,那要结合自己的应用场景自己来判断。
这里主要介绍Ansj中文分词器,它是一个开源的Java中文分词工具,基于中科院的ictclas中文分词算法,比其它常用的开源分词工具(如MMseg4j)的分词准确率更高,目前实现了中文分词,中文姓名识别,用户自定义词典,关键字提取,自动摘要,关键字标记等功能,适用于对分词效果要求高的各种项目。
1. 引入依赖:
```java
<!-- 开源中文分词器Ansj -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
```
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注:访问 https://oss.sonatype.org/content/repositories/releases/org/ansj/ansj_seg/ 可查看或下载最新版 ansj_seg/
二、 调用方式
1. 基本分词-BaseAnalysis
基本就是保证了最基本的分词.词语颗粒度最非常小的,所涉及到的词大约是10万左右,
基本分词速度非常快,在macAir上.能到每秒300w字每秒,同时准确率也很高.但是对于新词他的功能十分有限。
代码示例
- 1
- 2
- 3
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
String text = "20个左边的卡罗拉倒车镜! ";
Result analysisedResult = BaseAnalysis.parse(text);
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("基本分词: " + analysisedResult + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果:
基本分词: 20/m,个/q,左边/f,的卡/n,罗/j,拉/v,倒车镜/n,!/w, (1871ms)
- 1
可以看到分词后会在词语的后边加上对应词语的词性
如何不输出词性,仅输出词?
可以在后面加上.toStringWithOutNature()
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
String text = "20个左边的卡罗拉倒车镜! ";
String analysisedText = BaseAnalysis.parse(text).toStringWithOutNature();
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("基本分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出的结果:
精准分词: 20个,左边,的卡,罗拉,倒车镜,!, (1856ms)
- 1
2. 精准分词-ToAnalysis
它在易用性,稳定性.准确性.以及分词效率上.都取得了一个不错的平衡。
如果你初次赏识Ansj如果你想开箱即用.那么就用这个分词方式是不会错的
代码示例:
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
String text = "20个左边的卡罗拉倒车镜! ";
String analysisedText = ToAnalysis.parse(text).toStringWithOutNature();
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("精准分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出结果:
精准分词: 20个,左边,的卡,罗拉,倒车镜,!, (1856ms)
- 1
3. nlp分词-NlpAnalysis
nlp的适用方式:语法实体名抽取.未登录词整理.只要是对文本进行发现分析等工作
简单示例:
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
String text = "20个左边的卡罗拉倒车镜! ";
String analysisedText = NlpAnalysis.parse(text).toStringWithOutNature();
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("nlp分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出的结果:
nlp分词: 20个,左边,的,卡,罗拉,倒车镜,!, (2712ms)
- 1
4. 面向索引的分词-IndexAnalysis
面向索引的分词,顾名思义就是适合在lucene等文本检索中用到的分词。
主要考虑以下两点:
召回率是对分词结果尽可能的涵盖。比如对“上海虹桥机场南路”召回结果是【上海/ns,上海虹桥机场/nt,虹桥/ns,虹桥集成/nz,机场/n,南路/nr】
准确率其实这和召回本身是具有一定冒星星的Ansj的强大之处是很巧妙的避开了这两个的冲突。比如我们常见的歧义句“旅游和服务”->对于一般保证召回。大家会给出的结果是“旅游和服务”,对于Ansj并不存在跨term的分词。意思就是:召回的词只是针对精准分词之后的结果的一个细分。比较好的解决了这个问题
代码示例:
- 1
- 2
- 3
- 4
- 5
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
String text = "20个左边的卡罗拉倒车镜! ";
String analysisedText = IndexAnalysis.parse(text).toStringWithOutNature();
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("面向索引的分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出的结果:
面向索引的分词: 20个,左边,的卡,罗拉,倒车镜,!, (1825ms)
- 1
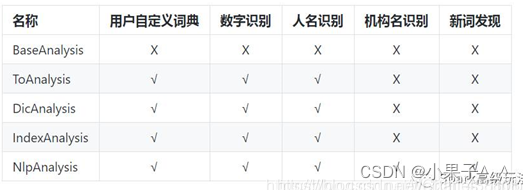
- 四种方式比较
三、停词器
停用词需求是一种及其常见的需求,好处很多很多,令人惊讶的是坏处比好处还多,所以一般情况下不要用这个,比较耗费cpu
第一步实例化停用器
第二步调用过滤:
如下面的三种形式的过滤(用精准分词来举例)
1. 过滤词性(insertStopNatures())
代码示例:
- 1
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
StopRecognition stopRecognition = new StopRecognition();
String text = "20个左边的卡罗拉倒车镜! ";
//剔除标点符号(w)
stopRecognition.insertStopNatures("w");
String analysisedText = ToAnalysis.parse(text).recognition(stopRecognition)
.toStringWithOutNature().replaceAll(","," ");
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("精准分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出结果:
精准分词: 20个 左边 的卡 罗拉 倒车镜 (1974ms)
- 1
从结果可以看到句中的感叹号已经被剔除了
2. 过滤单词(insertStopWords())
代码示例:
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
StopRecognition stopRecognition = new StopRecognition();
String text = "20个左边的卡罗拉倒车镜! ";
//剔除指定的分词
stopRecognition.insertStopWords("20个");
String analysisedText = ToAnalysis.parse(text).recognition(stopRecognition)
.toStringWithOutNature().replaceAll(","," ");
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("精准分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出结果:
精准分词: 左边 的卡 罗拉 倒车镜 ! (2089ms)
- 1
从结果可以看到20个已经被剔除了
3. 支持正则表达式(insertStopRegexes())
代码示例:
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
StopRecognition stopRecognition = new StopRecognition();
String text = "20个左边的卡罗拉倒车镜! ";
//剔除指定的分词
stopRecognition.insertStopRegexes("倒车.*?");
String analysisedText = ToAnalysis.parse(text).recognition(stopRecognition)
.toStringWithOutNature().replaceAll(","," ");
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("精准分词: " + analysisedText + "(" + time + "ms)");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果:
精准分词: 20个 左边 的卡 罗拉 ! (2004ms)
- 1
从结果可以看到“倒车镜”已经被剔除了
转发连接:https://blog.csdn.net/Charles_Timber/article/details/106138102

