
深度学习——循环神经网络RNN_循环神经网络是什么
赞
踩
活动地址:CSDN21天学习挑战赛
目录
什么是循环神经网络
循环神经网络(Recurrent Neural Network)简称RNN,是一种专门用来处理序列数据的神经网络,能够深度挖掘序列数据中的时序信息和语义信息。
在百度百科中,对其定义如下:
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络。
解释:
以序列数据为输入:表示RNN的数据输入要求是序列化的数据,不能再是CNN所输入的单独且彼此之间毫无关系的图片;
在序列的演进方向上进行递归:这个演进方向是指序列化数据的序列前进方向,比如视频的下一帧、下一秒,语音或者文本的下一词、下一句话等等。进行递归则是指下图的递进,而这恰好构成一条处理链:
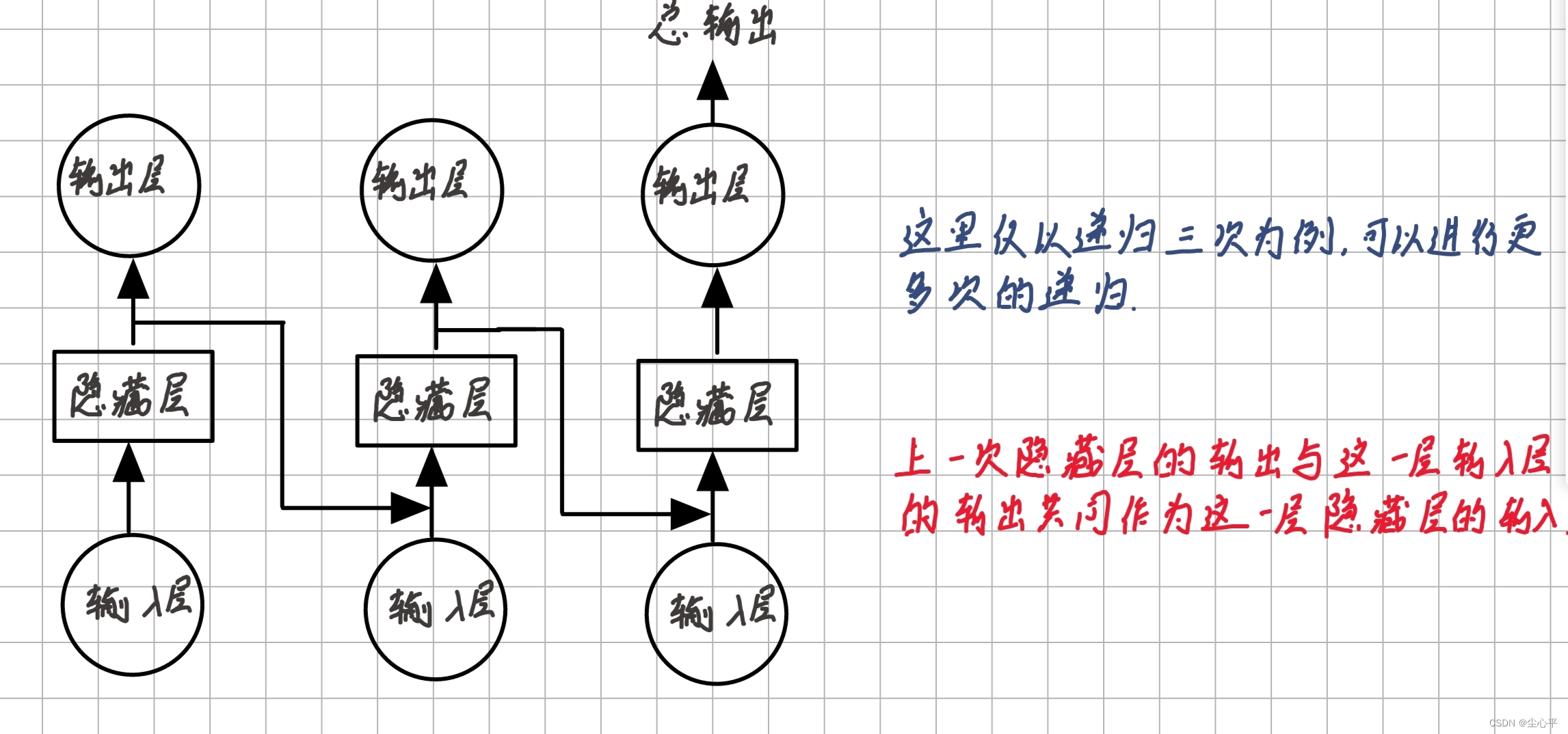
RNN模型
为什么需要RNN
传统神经网络只能处理相对孤立的数据集,比如之前用卷积神经网络CNN所解决的MNIST手写数字识别、天气识别等计算机视觉问题(CV)
但是在日常应用中,我们常常还需要处理一些序列信息(序列信息即信息之间有明显的上下文关系、顺序关系的数据集)比如段落、语音、视频、股票等连续性较强的数据集,所以循环神经网络应运而生
RNN的这种特点,使得它在解决语音识别、文本识别以及情感分析等NLP领域的问题时很有效果,也可以和CNN相结合解决一些连续性的CV问题
RNN网络结构
传统神经网络的结构如下,而RNN网络结构与之不同的是在隐含层处添加了递归输入
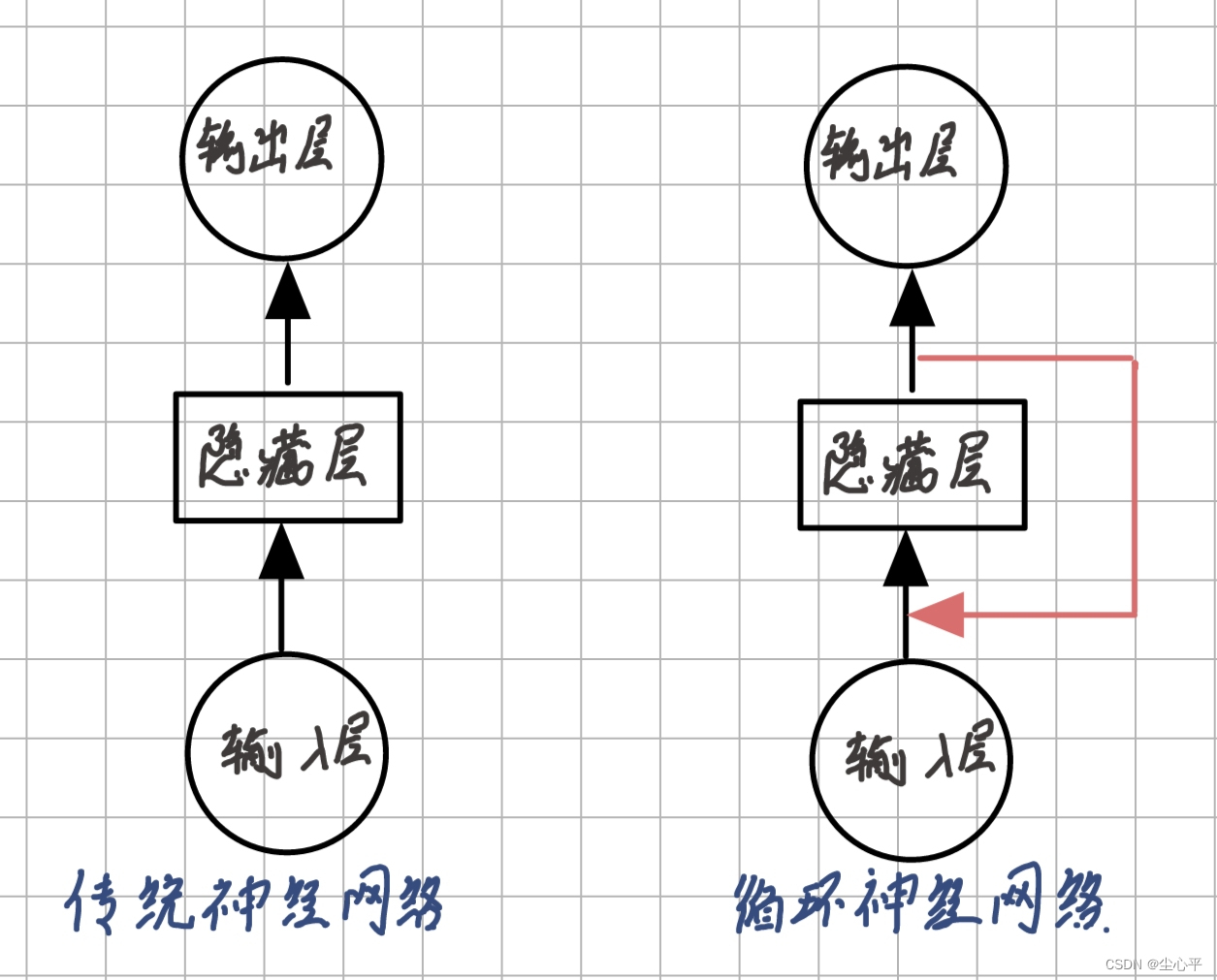
传统神经网络与循环神经网络模型对比图 将RNN的网络结构展开如下:
RNN模型
RNN的分类
按输入输出的结构分类
- N输入—N输出
N输入即输入序列长度为N
N输出即每一次隐藏层处理后的输出层的输出均为最后输出结果的一部分
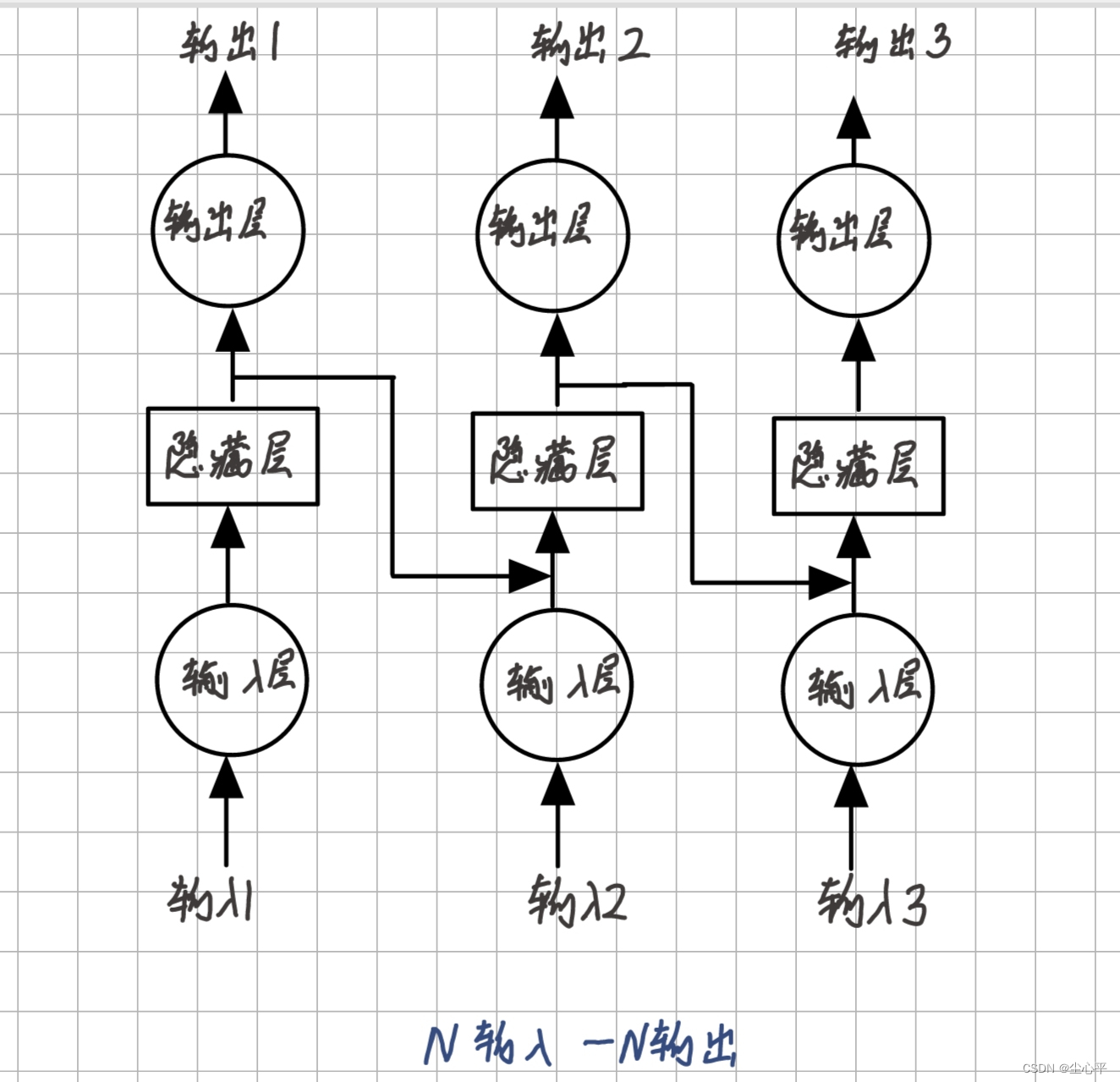
N输入——N输出示意图
- N输入—1输出
N输入仍为网络模型每次递归的输入均为序列的不同部分,序列长n
1输出即只取网络模型最后一次递归的输出层的输出为整个模型的输出
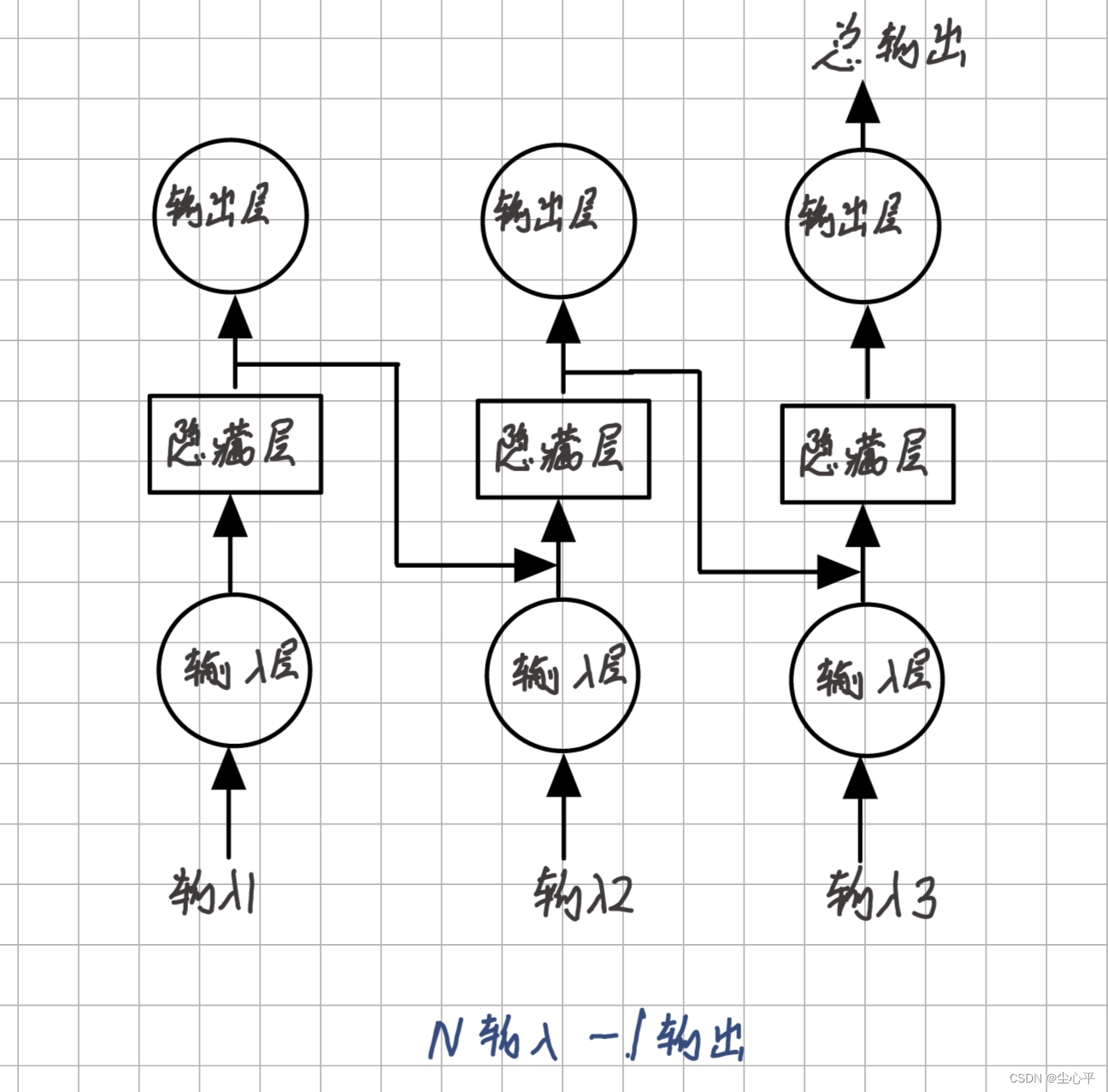
N输入——1输出示意图
- 1输入—N输出
1输入即网络模型每次递归共用同一个输入
N输出即每一次隐藏层处理后的输出层的输出均为最后输出结果的一部分
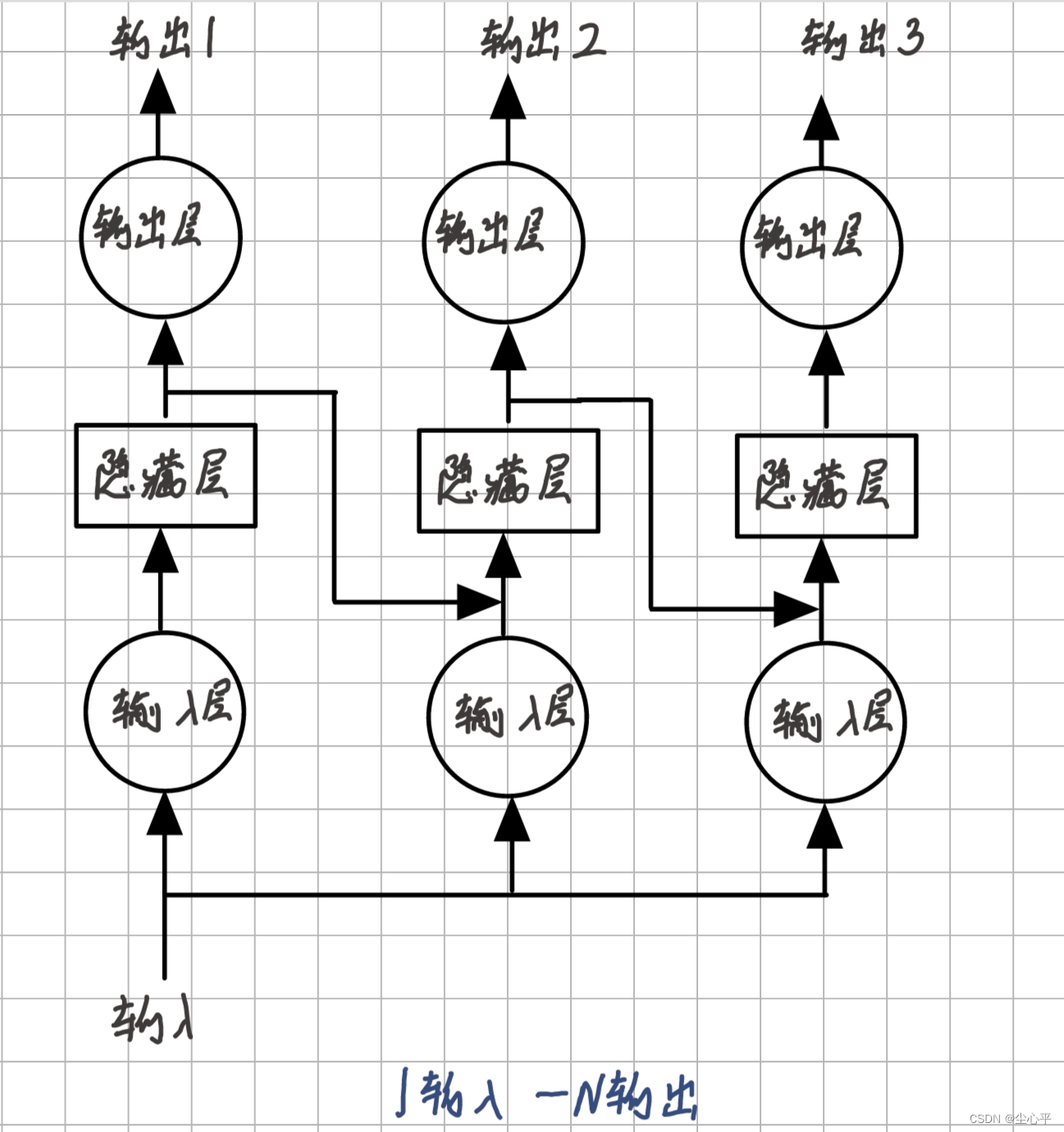
1输入——N输出示意图
- N输入—M输出
N输入—M输出型网络模型是 N输入—1输出模型 与 1输入—N输出模型 的结合
这种模型的适用程度更加广泛,但相应也更加复杂
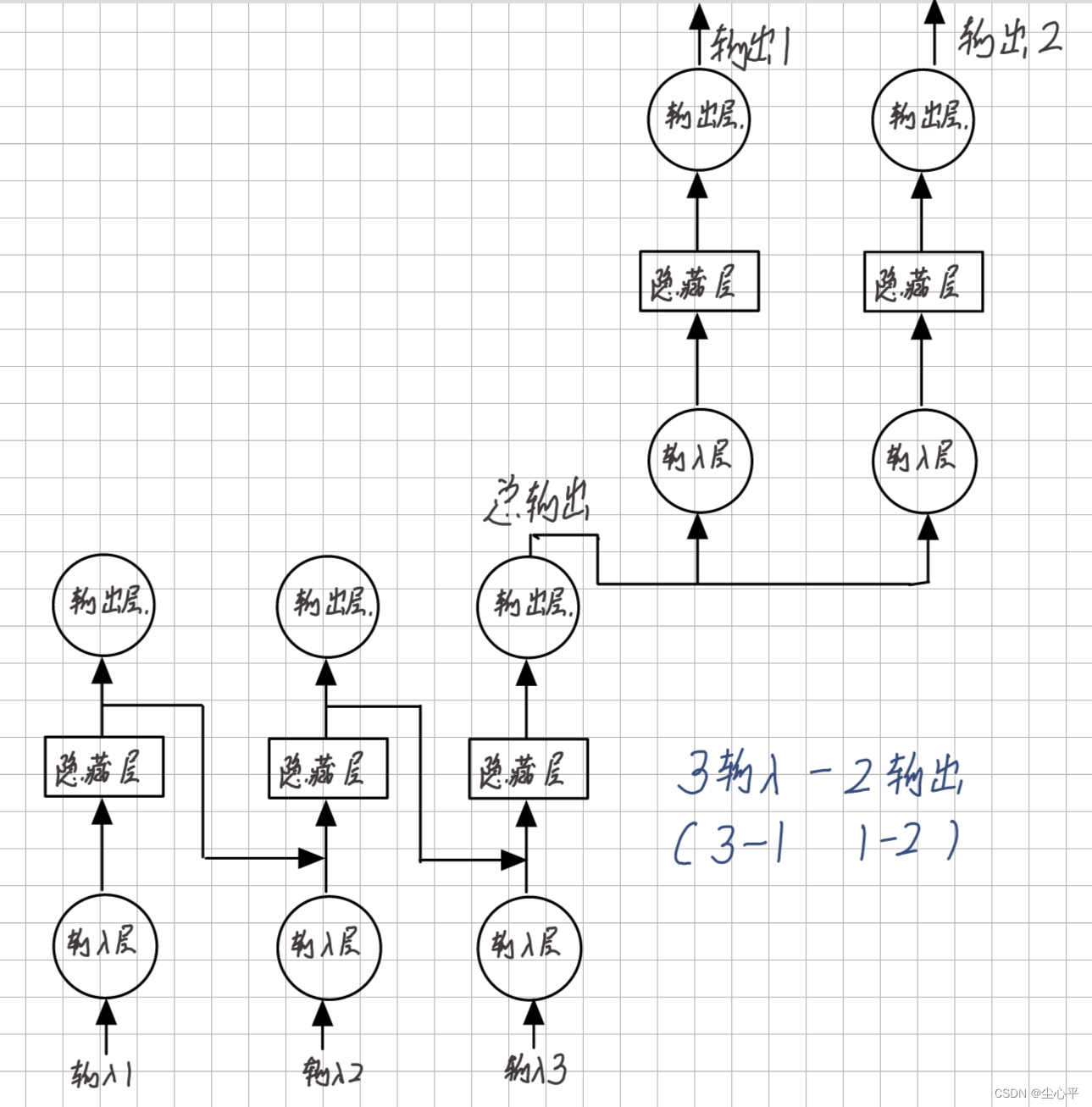
N输入——M输出示意图
按网络内部结构分类
传统RNN
传统RNN的内部结构图:
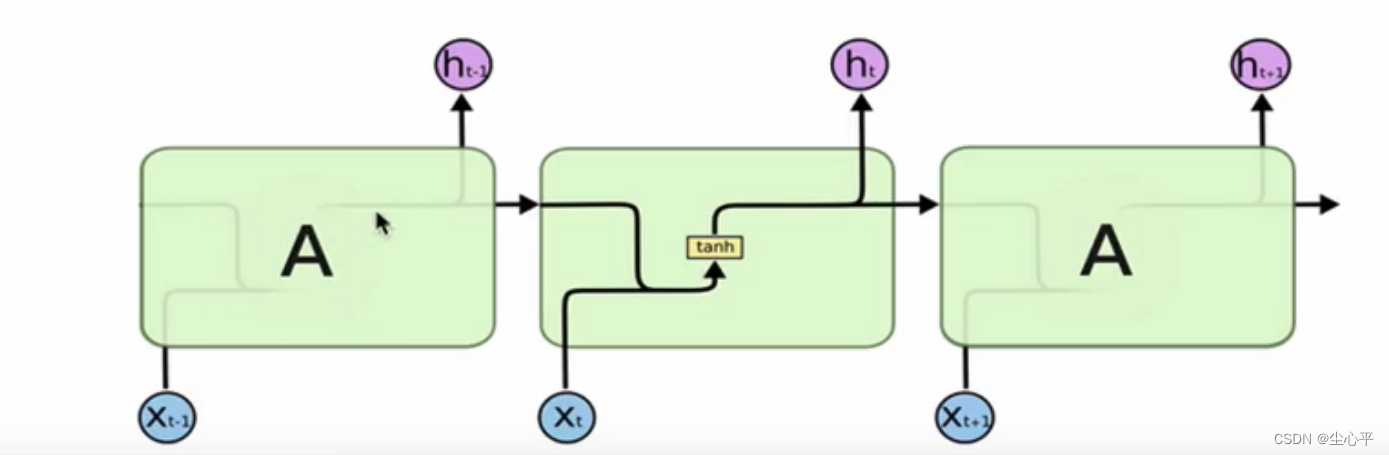
传统RNN内部结构 以中间的递归为例进行分析,输出
是由上一层的输出
与这一层的输入
合并连接后在 tanh激活函数(tanh激活函数可以将值压缩至-1~1之间)的作用下生成的,具体公式如下:其中
表示连接的意思
tensorflow搭建传统RNN:
仍与CNN类似,网络的搭建仍在models.Sequential([ ]) 中
传统RNN所使用的搭建函数主要是 layers.SimpleRNN(),具体参数介绍如下:
参数 units正整数,输出空间的维度,一般为2的n次幂 activation激活函数,默认值:双曲正切( tanh),功能为压缩值在-1~1范围内use_biasbool型,默认值为 True,表示使用偏置参数。kernel_initializer权重矩阵的初始化器,默认值是 glorot_uniform。recurrent_initializer用于递归时权重矩阵的初始化器,默认值是 orthogonal。bias_initializer偏置参数的初始化器。默认值是 zeros。kernel_regularizerkernel权重矩阵的正则化器,可以减小过拟合。默认值:None。recurrent_regularizerrecurrent_kernel权重矩阵的正则化器。默认值:None。bias_regularizer偏置参数的正则化器。默认值: None。activity_regularizer正则化功能应用于图层的输出(其“激活”)。默认值: None。kernel_constraint约束函数应用于 kernel权重矩阵。默认值:None。recurrent_constraint约束函数应用于 recurrent_kernel权重矩阵。默认值:None。bias_constraint约束函数应用于偏置参数。默认值: None。dropout在 0 和 1 之间的浮点数,用于线性转换输入的单位的分数。默认值:0。 recurrent_dropout浮动值在 0 和 1 之间,对于递归状态的线性转换,要下降的单位分数。默认值:0。 return_sequences布尔值。是返回输出序列中的最后一个输出还是完整序列。默认值: False,表示返回完整的序列。最后一次的RNN层一般需要为false,之前的truereturn_state布尔值。除输出外,是否返回最后一个状态。默认值: False,表示不返回最后一个状态go_backwardsBoolean(默认为False)。如果为True,则对输入序列进行逆向处理,并返回相反的序列。 statefulBoolean(默认为False)。如果为True,则一批中索引i的每个样本的最后一个状态将作为下一批索引i的样本的初始状态。 unrollBoolean(默认为False)。如果为True,网络将被取消滚动,否则将使用符号循环。Unrolling可以加快RNN的速度,尽管它往往更耗费内存。Unrolling只适用于短序列。

优缺点:
传统RNN相较于LSTM与GRU,模型较为简单,参数较少,在短序列任务上表现优异
但是,在长序列任务上,传统RNN进行反向传播时,容易发生梯度爆炸,效果较差
一般在使用SimpleRNN函数时必须要指定的参数是:units,return_sequences。其他的默认参数可以根据需要进行修改
LSTM
- 定义:
LSTM全称 “Long short term memory”,译为长短时记忆结构。它是一种特殊的RNN模型,缓解了传统RNN在长序列训练时的梯度爆炸、梯度消失的现象
- LSTM内部结构
LSTM的内部结构较传统RNN更为复杂,其核心结构可以分为4个部分进行分析:遗忘门、输入门、细胞状态和输出门。
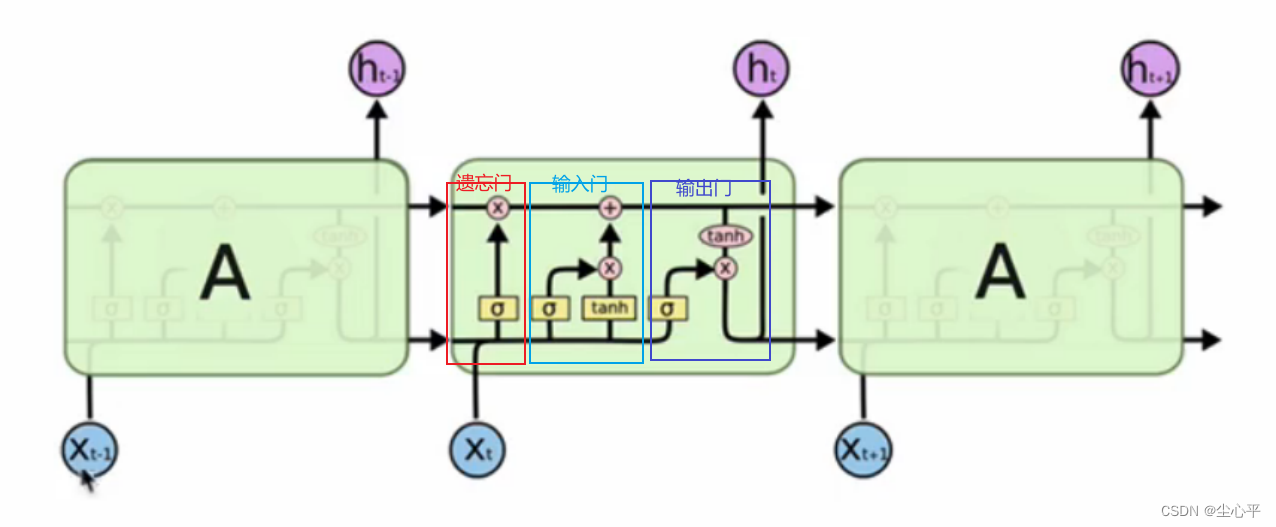
LSTM内部结构示意图 遗忘门:
遗忘门所起的作用类似于我们在阅读文章时,会不可避免的遗忘掉之前所读的部分内容 遗忘门做的是计算遗忘门门值
,遗忘门门值的计算用的是sigmoid函数(压缩值到0~1之间)
遗忘门门值将在之后作用于上一层的细胞状态,表示遗忘多少上一层的细胞状态,也就是说:当前阶段的输入
与上一阶段的隐藏状态
输入门:
输入门包括两步:计算输入门门值以及计算未更新的当前的细胞状态
输入门值的计算与遗忘门门值的计算相类似,主要是参数的不同,均是合并
未更新的细胞状态的计算的输入仍是合并
细胞状态的更新:
细胞状态的更新并未用到任何函数,是根据遗忘门计算的遗忘门值以及输入门计算的输入门值和未更新的细胞状态进行计算,计算公式如下:
输出门:
输出门与输入门类似也需要计算输出门门值,再根据输出门门值计算输出
输出门门值的计算仍是合并
而输出值的计算是:
- tensorflow搭建LSTM
和layers.SimpleRNN的构造函数相比较,多了以下两个参数:
recurrent_activation:指定门值计算时的激活函数,默认采用sigmoid函数
unit_forget_bias:bool类型值,默认为True,表示在初始化时将1加到遗忘门的偏置上
代码示例:



Bi—LSTM
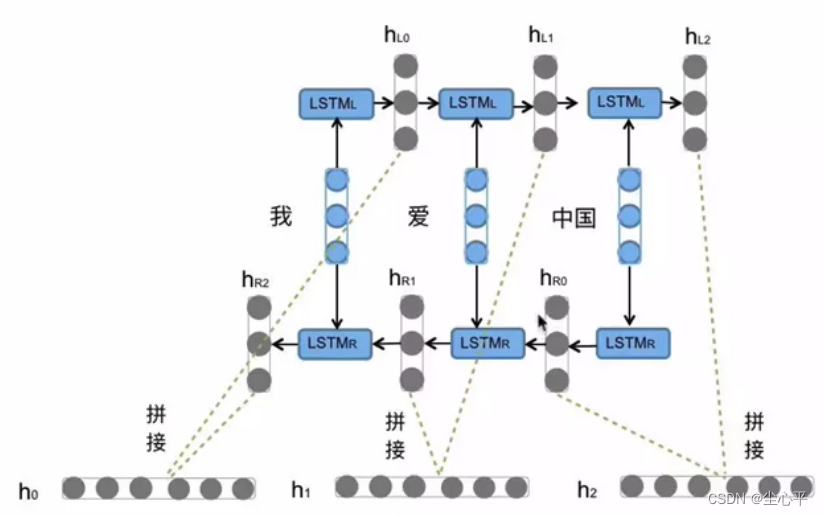
双向LSTM的内部结构仍和LSTM一致,它的诞生是因为存在一些序列,它的上下文互相影响,所以双向LSTM是在序列的正向演进方向上使用一次LSTM,再在序列的逆向演进方向上使用一次LSTM,最后将两次LSTM对应的输出合并作为最后的输出
下图是以“我爱中国”为例的Bi—LSTM的分析图:
GRU
- 定义
GRU全称“Gated Recurrent Unit”,译为门控制循环单元结构。
GRU也是传统RNN的一个变体,结合了传统RNN参数少以及LSTM在长序列上缓解梯度消失和梯度爆炸的优点,较LSTM更有优势
- 内部结构分析
GRU的核心内部结构可以分为两部分:更新门和重置门,具体结构示意图如下:
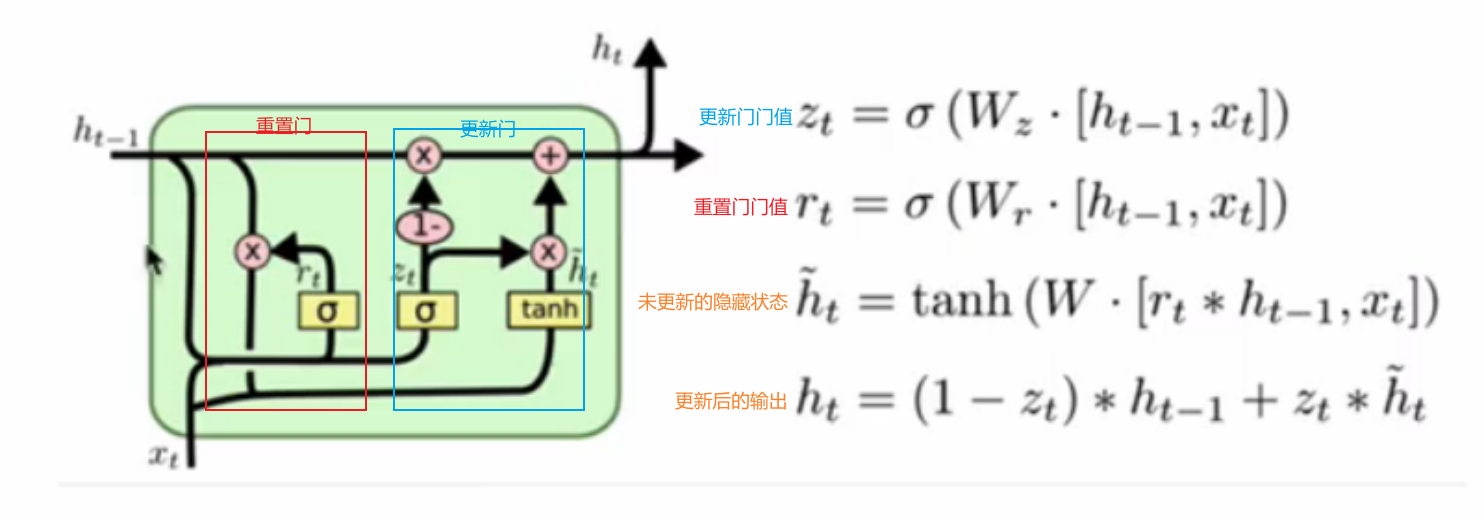
GRU内部结构示意图 与LSTM类似,更新门和重置门也有其相对应的门值,首先需要计算出这些门值
两种门值的计算都采用sigmoid函数,具体计算公式见示意图
然后需要计算出未更新的隐藏状态,该计算需要用tanh函数,且输入是重置门的输出与当前阶段输入的合并,即
![\bar{h_t}=tanh(W[h_{t-1}\times r_t,x_t])](https://latex.csdn.net/eq?%5Cbar%7Bh_t%7D%3Dtanh%28W%5Bh_%7Bt-1%7D%5Ctimes%20r_t%2Cx_t%5D%29)
更新门门值主要是决定保存多少比例的当前状态作为最后的输出,1-更新门门值即是选择记住多少比例的之前的隐参状态,即
- tensorflow实现
与layers.LSTM构造函数相比较,少了 unit_forget_bias 参数,多了reset_after参数
reset_after:bool类型,默认为False,这个参数是GRU惯例(是否在矩阵乘法之后或之前应用重置门)。False="之前",True="之后"(默认和cuDNN兼容)。
- Bi—GRU
双向GRU模型类似于双向LSTM模型,核心内部结构仍为GRU的结构,只是在序列的正向演进方向上使用一次GRU,在序列的逆向演进方向上使用一次GRU,最后将两次GRU相对应的输出状态合并即可

